Trasformare i dati con le pipeline
Questo articolo descrive come usare DLT per dichiarare trasformazioni nei set di dati e specificare il modo in cui i record vengono elaborati tramite la logica di query. Contiene anche esempi di modelli di trasformazione comuni per la creazione di pipeline DLT.
È possibile definire un set di dati su qualsiasi query che restituisca un dataframe. È possibile usare le operazioni predefinite di Apache Spark, le funzioni definite dall'utente, la logica personalizzata e i modelli MLflow come trasformazioni nella pipeline DLT. Dopo che i dati sono stati immessi nella pipeline DLT, è possibile definire nuovi set di dati contro le fonti upstream per creare nuove tabelle di streaming, viste materializzate e viste.
Per informazioni su come eseguire in modo efficace l'elaborazione con stato con DLT, vedere Ottimizzare l'elaborazione con stato in DLT con filigrane.
Quando usare viste, viste materializzate e tabelle di streaming
Quando si implementano le query della pipeline, scegliere il tipo di set di dati migliore per assicurarsi che siano efficienti e gestibili.
Prendere in considerazione l'uso di una visualizzazione per eseguire le operazioni seguenti:
- Suddividere una query di grandi dimensioni o complessa in query più facili da gestire.
- Convalidare i risultati intermedi usando le aspettative.
- Ridurre i costi di archiviazione e calcolo per i risultati che non è necessario rendere persistenti. Poiché le tabelle sono materializzate, richiedono risorse di calcolo e archiviazione aggiuntive.
È consigliabile usare una vista materializzata quando:
- Le query downstream multiple utilizzano la tabella. Poiché le viste vengono calcolate su richiesta, vengono ricalcolate ogni volta che la vista viene interrogata.
- Altre pipeline, processi o query usano la tabella. Poiché le viste non sono materializzate, è possibile usarle solo nella stessa pipeline.
- Si desidera visualizzare i risultati di una query durante lo sviluppo. Poiché le tabelle sono materializzate e possono essere visualizzate e sottoposte a query all'esterno della pipeline, l'uso di tabelle durante lo sviluppo consente di convalidare la correttezza dei calcoli. Dopo la convalida, convertire le query che non richiedono la materializzazione in viste.
Prendere in considerazione l'uso di una tabella di streaming quando:
- Una query è definita rispetto a un'origine dati in continua o graduale crescita.
- I risultati delle query devono essere calcolati in modo incrementale.
- La pipeline richiede un'elevata velocità di trasmissione e bassa latenza.
Nota
Le tabelle di streaming vengono sempre definite in base alle origini di streaming. È anche possibile usare fonti di streaming con APPLY CHANGES INTO per applicare gli aggiornamenti dai feed CDC. Consulta le API DI APPLY CHANGES: semplificare l'acquisizione dati modificati con DLT.
Escludere tabelle dallo schema di destinazione
Se è necessario calcolare le tabelle intermedie non destinate all'utilizzo esterno, è possibile impedire la pubblicazione in uno schema usando la parola chiave TEMPORARY. Le tabelle temporanee archiviano ed elaborano i dati in base alla semantica DLT, ma non devono essere accessibili all'esterno della pipeline corrente. Una tabella temporanea persiste per l'intera durata della pipeline che la crea. Usare la sintassi seguente per dichiarare le tabelle temporanee:
SQL
CREATE TEMPORARY STREAMING TABLE temp_table
AS SELECT ... ;
Pitone
@dlt.table(
temporary=True)
def temp_table():
return ("...")
Combinare tabelle di streaming e viste materializzate in una singola pipeline
Le tabelle di streaming ereditano le garanzie di elaborazione di Apache Spark Structured Streaming e sono configurate per elaborare le query da origini dati a sola accodamento, in cui le nuove righe vengono sempre inserite nella tabella sorgente anziché modificate.
Nota
Anche se, per impostazione predefinita, le tabelle di streaming richiedono origini dati di sola accodamento, quando un'origine di streaming è un'altra tabella di streaming che richiede aggiornamenti o eliminazioni, è possibile eseguire l 'override di questo comportamento con il flag skipChangeCommits.
Un modello di streaming comune prevede l'inserimento di dati di origine per creare i set di dati iniziali in una pipeline. Questi set di dati iniziali sono comunemente denominati tabelle bronze e spesso eseguono trasformazioni semplici.
Al contrario, le tabelle finali in una pipeline, comunemente denominate tabelle gold, richiedono spesso aggregazioni complesse o letture da destinazioni di un'operazione di APPLY CHANGES INTO. Poiché queste operazioni creano intrinsecamente aggiornamenti anziché accodamenti, non sono supportati come input per le tabelle di streaming. Queste trasformazioni sono più adatte per le viste materializzate.
Combinando le tabelle di streaming e le viste materializzate in una singola pipeline, è possibile semplificare la pipeline, evitare costose re-inserimento o rielaborazione di dati non elaborati e avere la piena potenza di SQL per calcolare aggregazioni complesse su un set di dati codificato e filtrato in modo efficiente. Nell'esempio seguente viene illustrato questo tipo di elaborazione mista:
Nota
Questi esempi usano il caricatore automatico per caricare file dall'archiviazione cloud. Per caricare i file con Auto Loader in una pipeline abilitata per il Catalogo Unity, è necessario usare percorsi esterni. Per altre informazioni sull'uso di Unity Catalog con DLT, vedere Usare il catalogo Unity con le pipeline DLT.
Pitone
@dlt.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://path/to/raw/data")
)
@dlt.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return spark.readStream.table("streaming_bronze").where(...)
@dlt.table
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return spark.readStream.table("streaming_silver").groupBy("user_id").count()
SQL
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM STREAM read_files(
"abfss://path/to/raw/data",
format => "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM streaming_silver GROUP BY user_id
Altre informazioni sull'uso di caricatore automatico per caricare in modo incrementale file JSON da archiviazione di Azure.
join statici di Stream
I join statici di flusso rappresentano una scelta ottimale per la denormalizzazione di un flusso continuo di dati di sola accodamento con una tabella delle dimensioni principalmente statica.
Con ogni aggiornamento della pipeline, i nuovi record del flusso vengono uniti con lo snapshot più recente della tabella statica. Se i record vengono aggiunti o aggiornati nella tabella statica dopo l'elaborazione dei dati corrispondenti dalla tabella di streaming, i record risultanti non vengono ricalcolati a meno che non venga eseguito un aggiornamento completo.
Nelle pipeline configurate per l'esecuzione attivata, la tabella statica restituisce i risultati al momento dell'avvio dell'aggiornamento. Nelle pipeline configurate per l'esecuzione continua, viene eseguita una query sulla versione più recente della tabella statica ogni volta che la tabella elabora un aggiornamento.
Di seguito è riportato un esempio di join flusso-statico:
Pitone
@dlt.table
def customer_sales():
return spark.readStream.table("sales").join(spark.readStream.table("customers"), ["customer_id"], "left")
SQL
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(sales)
INNER JOIN LEFT customers USING (customer_id)
Calcolare le aggregazioni in modo efficiente
È possibile usare le tabelle di streaming per calcolare in modo incrementale aggregazioni semplici come count, min, max o sum e aggregazioni algebriche come deviazione media o standard. Databricks consiglia l'aggregazione incrementale per le query con un numero limitato di gruppi, ad esempio una query con una clausola GROUP BY country. Solo i nuovi dati di input vengono letti con ogni aggiornamento.
Per ulteriori informazioni sulla scrittura di query DLT che eseguono aggregazioni incrementali, vedere Eseguire aggregazioni finestrate con filigrane.
Utilizzare modelli MLflow in una pipeline DLT
Nota
Per usare i modelli MLflow in una pipeline abilitata per Unity Catalog, la pipeline deve essere configurata per l'uso del canale preview. Per usare il canale current, è necessario configurare la pipeline per la pubblicazione nel metastore Hive.
È possibile usare modelli addestrati con MLflow nelle pipeline DLT. I modelli MLflow vengono considerati trasformazioni in Azure Databricks, ovvero agiscono su un input dataframe Spark e restituiscono risultati come dataframe Spark. Poiché DLT definisce i set di dati in dataframe, è possibile convertire i carichi di lavoro Apache Spark che usano MLflow in DLT con poche righe di codice. Per altre informazioni su MLflow, vedere MLflow per l'agente di intelligenza artificiale generativa e il ciclo di vita del modello di apprendimento automatico.
Se si dispone già di un notebook Python che chiama un modello MLflow, è possibile adattare questo codice a DLT usando l'elemento decorator @dlt.table e verificando che le funzioni siano definite per restituire i risultati della trasformazione. DLT non installa MLflow per impostazione predefinita, quindi verificare di aver installato le librerie MLFlow con %pip install mlflow e di aver importato mlflow e dlt nella parte superiore del notebook. Per un'introduzione alla sintassi DLT, vedere Sviluppare codice della pipeline con Python.
Per usare i modelli MLflow in DLT, completare i passaggi seguenti:
- Ottenere l'ID di esecuzione e il nome del modello MLflow. L'ID di esecuzione e il nome del modello vengono usati per costruire l'URI del modello MLflow.
- Usare l'URI per definire una UDF di Spark per caricare il modello MLflow.
- Chiama l'UDF nelle definizioni della tabella per utilizzare il modello MLflow.
L'esempio seguente illustra la sintassi di base per questo modello:
%pip install mlflow
import dlt
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dlt.table
def model_predictions():
return spark.read.table(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
Come esempio completo, il codice seguente definisce una UDF Spark denominata loaded_model_udf che carica un modello MLflow addestrato sui dati di rischio prestito. Le colonne di dati usate per eseguire la previsione vengono passate come argomento alla funzione definita dall'utente. La tabella loan_risk_predictions calcola le stime per ogni riga in loan_risk_input_data.
%pip install mlflow
import dlt
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dlt.table(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return spark.read.table("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
Conservare le eliminazioni o gli aggiornamenti manuali
DLT consente di eliminare o aggiornare manualmente i record da una tabella ed eseguire un'operazione di aggiornamento per ricompilare le tabelle downstream.
Per impostazione predefinita, DLT ricompila i risultati della tabella in base ai dati di input ogni volta che una pipeline viene aggiornata, quindi è necessario assicurarsi che il record eliminato non venga ricaricato dai dati di origine. L'impostazione della proprietà della tabella pipelines.reset.allowed su false impedisce l'aggiornamento della tabella, ma non impedisce le scritture incrementali nelle tabelle o ai nuovi dati di fluire nella tabella.
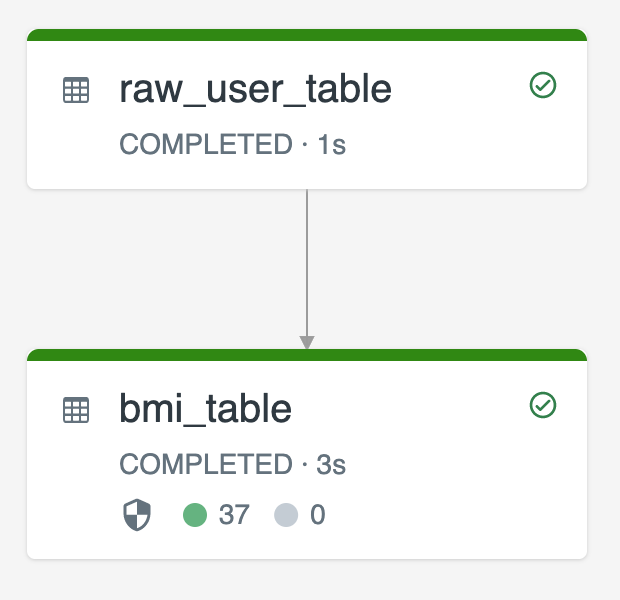
Il diagramma seguente illustra un esempio che usa due tabelle di streaming:
-
raw_user_tableinserisce dati utente non elaborati da un'origine. -
bmi_tablecalcola in modo incrementale i punteggi BMI usando peso e altezza daraw_user_table.
Vuoi eliminare o aggiornare manualmente i record utente dal raw_user_table e ricalcolare il bmi_table.
Nel codice seguente viene illustrata l'impostazione della proprietà della tabella pipelines.reset.allowed su false per disabilitare l'aggiornamento completo per raw_user_table in modo che le modifiche previste vengano mantenute nel tempo, ma le tabelle downstream vengono ricalcolate quando viene eseguito un aggiornamento della pipeline:
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM STREAM read_files("/databricks-datasets/iot-stream/data-user", format => "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(raw_user_table);