Ottimizzazione delle origini
Per ogni origine ad eccezione di database SQL di Azure, è consigliabile usare il partizionamento corrente come valore selezionato. Quando si legge da tutti gli altri sistemi di origine, i flussi di dati partiziona automaticamente i dati in modo uniforme in base alle dimensioni dei dati. Viene creata una nuova partizione per circa 128 MB di dati. Man mano che le dimensioni dei dati aumentano, il numero di partizioni aumenta.
Qualsiasi partizionamento personalizzato si verifica dopo che Spark legge i dati e influisce negativamente sulle prestazioni del flusso di dati. Poiché i dati vengono partizionati in modo uniforme in lettura, non è consigliabile a meno che non si comprenda prima la forma e la cardinalità dei dati.
Nota
Le velocità di lettura possono essere limitate dalla velocità effettiva del sistema di origine.
database SQL di Azure origini
database SQL di Azure dispone di un'opzione di partizionamento univoca denominata partizionamento 'Source'. L'abilitazione del partizionamento di origine può migliorare i tempi di lettura da database SQL di Azure abilitando le connessioni parallele nel sistema di origine. Specificare il numero di partizioni e come partizionare i dati. Usare una colonna di partizione con cardinalità elevata. È anche possibile immettere una query che corrisponda allo schema di partizionamento della tabella di origine.
Suggerimento
Per il partizionamento di origine, l'I/O di SQL Server è il collo di bottiglia. L'aggiunta di troppe partizioni può saturare il database di origine. In genere quattro o cinque partizioni è ideale quando si usa questa opzione.
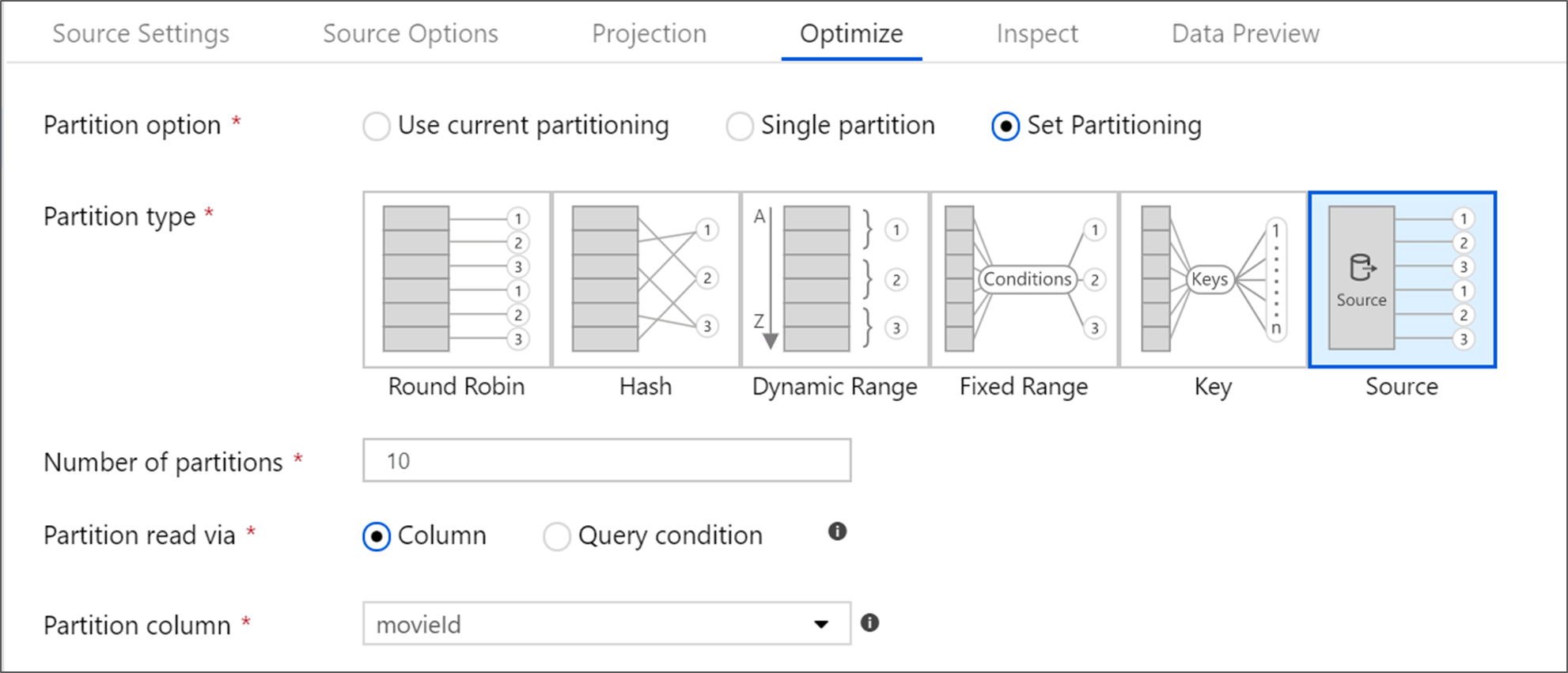
Livello di isolamento
Il livello di isolamento della lettura in un sistema di origine SQL di Azure influisce sulle prestazioni. La scelta di "Read uncommitted" offre le prestazioni più veloci e impedisce eventuali blocchi del database. Per altre informazioni sui livelli di isolamento SQL, vedere Informazioni sui livelli di isolamento.
Leggere con la query
È possibile leggere da database SQL di Azure usando una tabella o una query SQL. Se si esegue una query SQL, la query deve essere completata prima dell'avvio della trasformazione. Le query SQL possono essere utili per eseguire il push delle operazioni che potrebbero essere eseguite più velocemente e ridurre la quantità di dati letti da SQL Server, ad esempio istruzioni EDIZIONE STANDARD LECT, WHERE e JOIN. Quando si esegue il push delle operazioni, si perde la possibilità di tenere traccia della derivazione e delle prestazioni delle trasformazioni prima che i dati entrino nel flusso di dati.
Origini di Azure Synapse Analytics
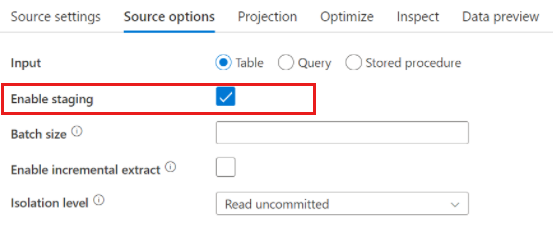
Quando si usa Azure Synapse Analytics, nelle opzioni di origine è presente un'impostazione denominata Abilita gestione temporanea . Ciò consente al servizio di leggere da Synapse usando Staging, migliorando notevolmente le prestazioni di lettura usando la funzionalità di caricamento bulk più efficiente, ad esempio CETAS e COPY. Per abilitare Staging è necessario specificare un percorso di gestione temporanea di Archiviazione BLOB di Azure o Azure Data Lake Archiviazione gen2 nelle impostazioni dell'attività del flusso di dati.
Origini basate su file
Parquet e testo delimitato
Mentre i flussi di dati supportano vari tipi di file, è consigliabile usare il formato Parquet nativo spark per tempi di lettura e scrittura ottimali.
Se si esegue lo stesso flusso di dati in un set di file, è consigliabile leggere da una cartella usando percorsi con caratteri jolly o leggendo da un elenco di file. Una singola esecuzione di attività del flusso di dati può elaborare tutti i file in batch. Altre informazioni su come configurare queste impostazioni sono disponibili nella sezione Trasformazione origine della documentazione del connettore di Archiviazione BLOB di Azure.
Se possibile, evitare di usare l'attività For-Each per eseguire flussi di dati su un set di file. Ciò fa sì che ogni iterazione di for-each spin up il proprio cluster Spark, che spesso non è necessario e può essere costoso.
Set di dati inline e set di dati condivisi
I set di dati ADF e Synapse sono risorse condivise nelle factory e nelle aree di lavoro. Tuttavia, quando si legge un numero elevato di cartelle e file di origine con testo delimitato e origini JSON, è possibile migliorare le prestazioni dell'individuazione dei file del flusso di dati impostando l'opzione "Schema proiettato dall'utente" all'interno della proiezione | Finestra di dialogo Opzioni schema. Questa opzione disattiva l'individuazione automatica dello schema predefinito di Azure Data Factory e migliora notevolmente le prestazioni dell'individuazione dei file. Prima di impostare questa opzione, assicurarsi di importare la proiezione in modo che ADF abbia uno schema esistente per la proiezione. Questa opzione non funziona con la deriva dello schema.
Contenuto correlato
- Panoramica delle prestazioni del flusso di dati
- Ottimizzazione dei sink
- Ottimizzazione delle trasformazioni
- Uso dei flussi di dati nelle pipeline
Sono disponibili altri articoli relativi alle prestazioni dei flussi di dati: