Monitorare i flussi di dati
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Al termine della compilazione e del debug del flusso di dati è necessario definire l'esecuzione del flusso di dati in base a una pianificazione nel contesto di una pipeline. È possibile pianificare la pipeline usando i trigger. Per testare e eseguire il debug del flusso di dati da una pipeline, è possibile usare il pulsante Debug sulla barra multifunzione della barra degli strumenti o l'opzione Trigger Now (Attiva adesso) di Pipeline Builder per eseguire un'esecuzione a esecuzione singola per testare il flusso di dati all'interno del contesto della pipeline.
Quando si esegue la pipeline, è possibile monitorarla insieme a tutte le attività che contiene, inclusa l'attività Flusso di dati. Selezionare l'icona di monitoraggio nel pannello dell'interfaccia utente a sinistra. È possibile visualizzare una schermata simile a quella seguente. Le icone evidenziate consentono di esaminare più in dettaglio le attività nella pipeline, tra cui l'attività Flusso di dati.
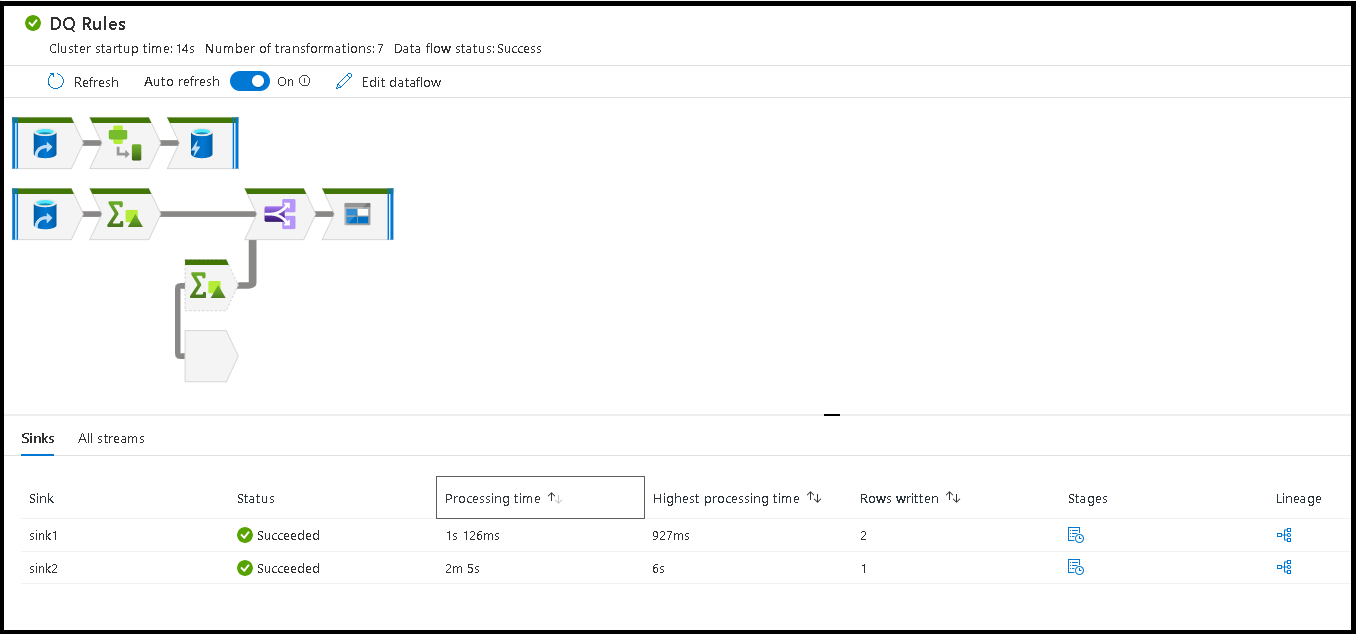
A questo livello vengono visualizzate anche le statistiche, insieme alle tempistiche e allo stato di esecuzione. L'ID esecuzione a livello di attività è diverso da quello a livello di pipeline. L'ID esecuzione al livello precedente è per la pipeline. La selezione del simbolo a forma di occhiali consente la visualizzazione di ulteriori dettagli sull'esecuzione del flusso di dati.

Durante la visualizzazione grafica di monitoraggio dei nodi, è possibile osservare una versione semplificata di tipo solo visualizzazione del grafico del flusso di dati. Per visualizzare la visualizzazione dei dettagli con nodi del grafo più grandi che includono etichette della fase di trasformazione, usare il dispositivo di scorrimento zoom sul lato destro dell'area di disegno. È anche possibile usare il pulsante di ricerca sul lato destro per trovare parti della logica del flusso di dati nel grafico.
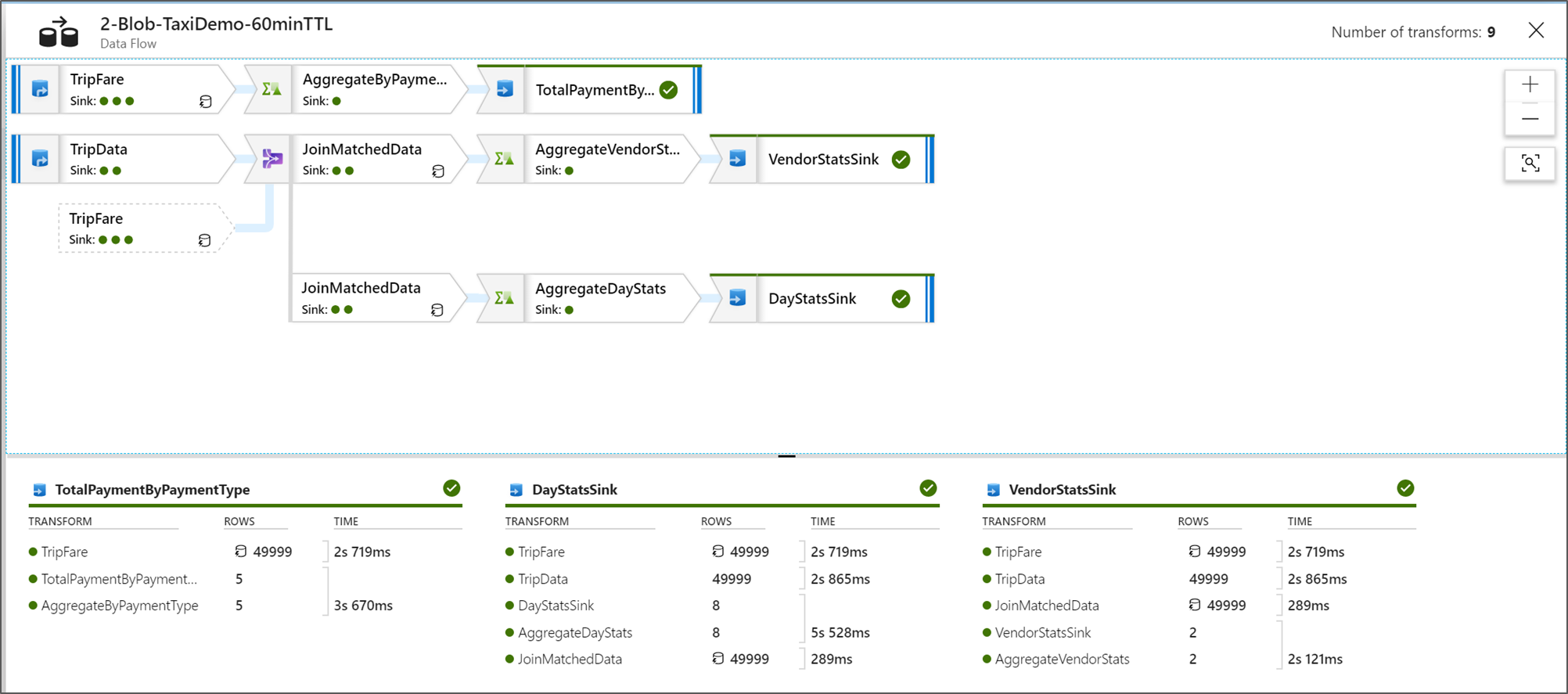
Visualizzare i piani di esecuzione del flusso di dati
Quando il Flusso di dati viene eseguito in Spark, il servizio determina percorsi di codice ottimali in base all'intero flusso di dati. Inoltre, i percorsi di esecuzione possono verificarsi in nodi e partizioni di dati con scalabilità orizzontale diversi. Di conseguenza, il grafico di monitoraggio rappresenta la progettazione del flusso, tenendo conto del percorso di esecuzione delle trasformazioni. Quando si selezionano singoli nodi, è possibile visualizzare le "fasi" che rappresentano il codice eseguito insieme nel cluster. I tempi e i conteggi visualizzati rappresentano tali gruppi o fasi anziché i singoli passaggi della progettazione.
Quando si seleziona l'area aperta nella finestra di monitoraggio, le statistiche nel riquadro inferiore mostrano le tempistiche e i numeri di righe per ogni sink e le trasformazioni che hanno generato i dati sink per la derivazione della trasformazione.
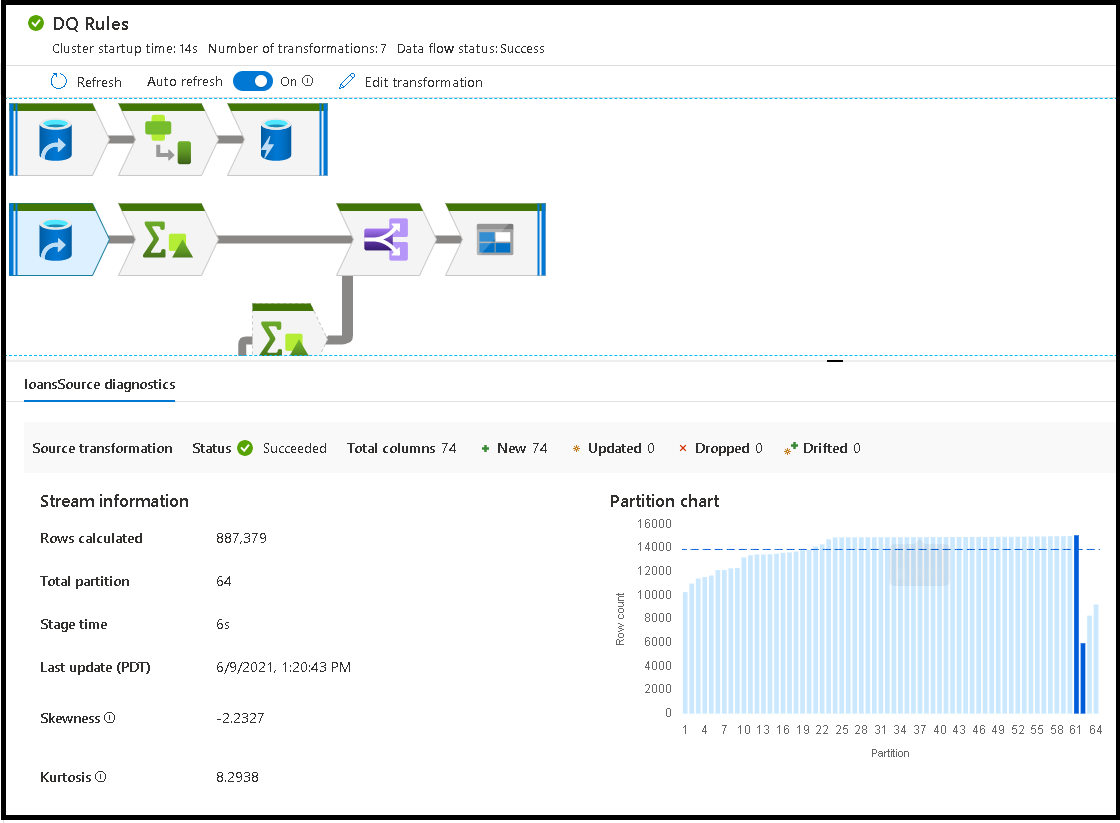
Quando si selezionano singole trasformazioni, si riceve un feedback aggiuntivo nel pannello di destra che mostra le statistiche delle partizioni, i conteggi delle colonne, l'asimmetria (in modo uniforme i dati distribuiti tra le partizioni) e la curtosi (come sono i dati).
L'ordinamento in base al tempo di elaborazione consente di identificare le fasi del flusso di dati più tempo.
Per individuare quali trasformazioni all'interno di ogni fase hanno richiesto più tempo, ordinare il tempo di elaborazione più elevato.
Anche le *righe scritte sono ordinabili come modo per identificare quali flussi all'interno del flusso di dati scrivono la maggior parte dei dati.
Quando si seleziona il sink nella visualizzazione del nodo, viene visualizzata la derivazione della colonna. Esistono tre metodi diversi in cui vengono accumulate le colonne lungo il flusso di dati per raggiungere il sink. Sono:
- Calcolato: la colonna viene usata per l'elaborazione condizionale o all'interno di un'espressione nel flusso di dati, ma non viene inserita nel sink
- Derivata: la colonna è una nuova colonna generata nel flusso, ovvero non è presente nell'origine
- Mappato: la colonna ha origine dall'origine e la si esegue il mapping a un campo sink
- Stato del flusso di dati: stato corrente dell'esecuzione
- Tempo di avvio del cluster: tempo necessario per acquisire l'ambiente di calcolo JIT Spark per l'esecuzione del flusso di dati
- Numero di trasformazioni: numero di passaggi di trasformazione eseguiti nel flusso

Tempo di elaborazione totale del sink e tempo di elaborazione della trasformazione
Ogni fase di trasformazione include un tempo totale per il completamento di tale fase con ogni tempo di esecuzione della partizione totale totale. Quando si seleziona il sink, viene visualizzato "Tempo di elaborazione sink". Questo tempo include il totale del tempo di trasformazione più il tempo di I/O necessario per scrivere i dati nell'archivio di destinazione. La differenza tra il tempo di elaborazione sink e il totale della trasformazione è il tempo di I/O per scrivere i dati.
È anche possibile visualizzare tempi dettagliati per ogni passaggio di trasformazione della partizione se si apre l'output JSON dall'attività del flusso di dati nella visualizzazione di monitoraggio della pipeline. Il codice JSON contiene i millisecondi di tempo per ogni partizione, mentre la visualizzazione di monitoraggio dell'esperienza utente è una tempistica aggregata delle partizioni aggiunte insieme:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Tempo di elaborazione sink
Quando si seleziona un'icona di trasformazione sink nella mappa, il pannello diapositiva a destra mostra un punto dati aggiuntivo denominato "tempo di post-elaborazione" nella parte inferiore. Questo è il tempo impiegato per l'esecuzione del processo nel cluster Spark dopo il caricamento, la trasformazione e la scrittura dei dati. Questa volta può includere la chiusura dei pool di connessioni, l'arresto del driver, l'eliminazione di file, l'unione di file e così via. Quando si eseguono azioni nel flusso, ad esempio "spostare i file" e "output in un singolo file", è probabile che si verifichi un aumento del valore del tempo di post-elaborazione.
- Durata della fase di scrittura: tempo per scrivere i dati in un percorso di gestione temporanea per Synapse SQL
- Durata SQL dell'operazione di tabella: tempo impiegato per lo spostamento dei dati dalle tabelle temporanee alla tabella di destinazione
- Durata pre-SQL e durata post SQL: tempo impiegato per l'esecuzione di comandi SQL pre/post
- Durata dei comandi pre-comando e durata dei comandi post: tempo impiegato per l'esecuzione di qualsiasi operazione preliminare/post per origini/sink basati su file. Ad esempio, spostare o eliminare i file dopo l'elaborazione.
- Durata unione: il tempo impiegato per unire il file, i file di unione vengono usati per i sink basati su file durante la scrittura in un singolo file o quando viene usato "Nome file come dati di colonna". Se in questa metrica viene impiegato tempo significativo, è consigliabile evitare di usare queste opzioni.
- Tempo fase: tempo totale impiegato all'interno di Spark per completare l'operazione come fase.
- Stabile temporanea di staging: nome della tabella temporanea usata dai flussi di dati per la gestione temporanea dei dati nel database.
Righe di errore
L'abilitazione della gestione delle righe degli errori nel sink del flusso di dati verrà riflessa nell'output di monitoraggio. Quando si imposta il sink su "Segnala esito positivo in caso di errore", l'output di monitoraggio mostra il numero di righe riuscite e non riuscite quando si seleziona il nodo di monitoraggio sink.
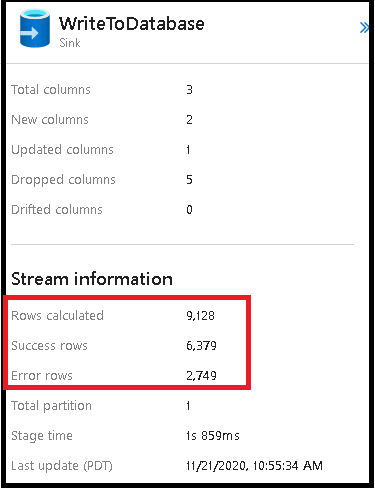
Quando si seleziona "Segnala errore in caso di errore", lo stesso output viene visualizzato solo nel testo di output del monitoraggio delle attività. Ciò è dovuto al fatto che l'attività del flusso di dati restituisce un errore per l'esecuzione e la visualizzazione di monitoraggio dettagliata non è disponibile.
Icona di monitoraggio
Questa icona indica che i dati della trasformazione sono già stati memorizzati nella cache del cluster e di conseguenza le tempistiche e il percorso di esecuzione sono già stati presi in considerazione:
Nella trasformazione vengono anche visualizzate alcune icone a forma di cerchio verde. Questa rappresentano un conteggio del numero di sink in cui vengono trasmessi i dati.