Ottimizzazione dei sink
Quando i flussi di dati scrivono in sink, qualsiasi partizionamento personalizzato avviene immediatamente prima della scrittura. Analogamente all'origine, nella maggior parte dei casi è consigliabile mantenere l'opzione Usa partizionamento corrente come opzione di partizione selezionata. I dati partizionati scrivono molto più velocemente dei dati non partizionati, anche la destinazione non è partizionata. Di seguito sono riportate le singole considerazioni per vari tipi di sink.
sink database SQL di Azure
Con database SQL di Azure, il partizionamento predefinito dovrebbe funzionare nella maggior parte dei casi. È possibile che il sink abbia troppe partizioni da gestire per il database SQL. Se si esegue questa operazione, ridurre il numero di partizioni restituite dal sink database SQL.
Procedura consigliata per l'eliminazione di righe nel sink in base alle righe mancanti nell'origine
Ecco una procedura dettagliata video su come usare i flussi di dati con esistono, modificare le trasformazioni di righe e sink per ottenere questo modello comune:
Impatto della gestione delle righe degli errori sulle prestazioni
Quando si abilita la gestione delle righe degli errori ("continua in caso di errore") nella trasformazione sink, il servizio esegue un passaggio aggiuntivo prima di scrivere le righe compatibili nella tabella di destinazione. Questo passaggio aggiuntivo presenta una piccola riduzione delle prestazioni che può essere nell'intervallo del 5% aggiunto per questo passaggio con un riscontro di prestazioni aggiuntivo ridotto aggiunto anche se si imposta l'opzione per scrivere anche le righe incompatibili in un file di log.
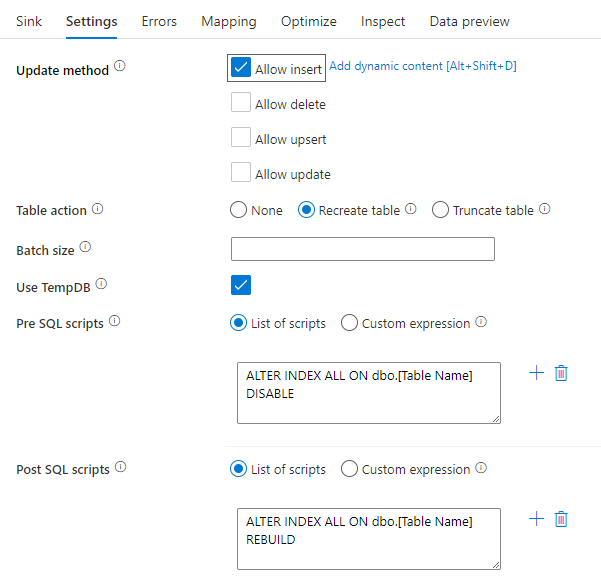
Disabilitazione degli indici tramite uno script SQL
La disabilitazione degli indici prima di un carico in un database SQL può migliorare notevolmente le prestazioni di scrittura nella tabella. Eseguire il comando seguente prima di scrivere nel sink SQL.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Al termine della scrittura, ricompilare gli indici usando il comando seguente:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Queste operazioni possono essere eseguite in modo nativo usando script pre e post-SQL all'interno di un sink di database SQL di Azure o Synapse nei flussi di dati di mapping.
Avviso
Quando si disabilitano gli indici, al momento il flusso di dati assume il controllo di un database e le query non riescono. Di conseguenza, molti processi ETL vengono attivati durante la notte per evitare questo conflitto. Per altre informazioni, vedere Le informazioni sui vincoli di disabilitazione degli indici SQL
Aumento delle prestazioni del database
Pianificare un ridimensionamento di Azure SLQ DB e DW di origine e sink prima dell'esecuzione della pipeline per aumentare la velocità effettiva e ridurre al minimo la limitazione di Azure quando si raggiungono i limiti di DTU. Al termine dell'esecuzione della pipeline, ridimensionare nuovamente i database fino alla frequenza di esecuzione normale.
Sink di Azure Synapse Analytics
Quando si scrive in Azure Synapse Analytics, assicurarsi che l'opzione Abilita gestione temporanea sia impostata su true. In questo modo il servizio può scrivere usando il comando SQL COPY, che carica effettivamente i dati in blocco. È necessario fare riferimento a un account Azure Data Lake Archiviazione gen2 o Archiviazione BLOB di Azure per lo staging dei dati quando si usa staging.
Oltre alla gestione temporanea, le stesse procedure consigliate si applicano ad Azure Synapse Analytics come database SQL di Azure.
Sink basati su file
Mentre i flussi di dati supportano vari tipi di file, è consigliabile usare il formato Parquet nativo spark per tempi di lettura e scrittura ottimali.
Se i dati vengono distribuiti uniformemente, usare il partizionamento corrente è l'opzione di partizionamento più veloce per la scrittura di file.
Opzioni di nomi di file
Quando si scrivono file, è possibile scegliere opzioni di denominazione che hanno un effetto sulle prestazioni.
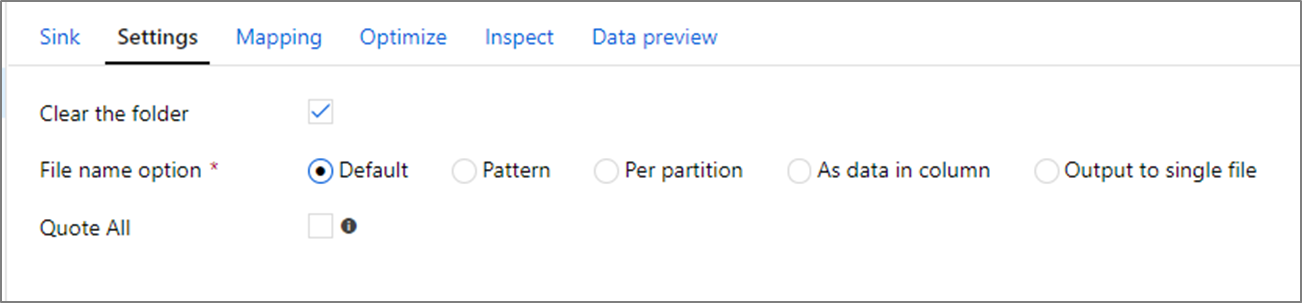
Se si seleziona l'opzione Predefinito , si scrive il più veloce. Ogni partizione equivale a un file con il nome predefinito di Spark. Ciò è utile se si sta leggendo solo dalla cartella dei dati.
L'impostazione di un criterio di denominazione rinomina ogni file di partizione in un nome più descrittivo. Questa operazione viene eseguita dopo la scrittura ed è leggermente più lenta rispetto alla scelta dell'impostazione predefinita.
Per partizione è possibile assegnare manualmente un nome a ogni singola partizione .
Se una colonna corrisponde alla modalità di output dei dati, è possibile selezionare Nome file come dati di colonna. In questo modo i dati vengono ridistribuiti e possono influire sulle prestazioni se le colonne non vengono distribuite in modo uniforme.
Se una colonna corrisponde alla modalità di generazione dei nomi delle cartelle, selezionare Cartella nome come dati di colonna.
L'output in un singolo file combina tutti i dati in una singola partizione. Ciò comporta tempi di scrittura lunghi, soprattutto per set di dati di grandi dimensioni. Questa opzione è sconsigliata a meno che non esista un motivo aziendale esplicito per usarla.
Sink di Azure Cosmos DB
Quando si scrive in Azure Cosmos DB, la modifica della velocità effettiva e delle dimensioni batch durante l'esecuzione del flusso di dati può migliorare le prestazioni. Queste modifiche diventano effettive solo durante l'esecuzione dell'attività del flusso di dati e torneranno alle impostazioni originali della raccolta dopo la conclusione.
Dimensioni batch: in genere, a partire dalle dimensioni batch predefinite è sufficiente. Per ottimizzare ulteriormente questo valore, calcolare le dimensioni approssimative degli oggetti dei dati e assicurarsi che le dimensioni dell'oggetto * batch siano inferiori a 2 MB. In caso affermativo, è possibile aumentare le dimensioni del batch per ottenere una velocità effettiva migliore.
Velocità effettiva: impostare un'impostazione di velocità effettiva più elevata qui per consentire ai documenti di scrivere più velocemente in Azure Cosmos DB. Tenere presente i costi di UR più elevati in base a un'impostazione di velocità effettiva elevata.
Budget per la velocità effettiva di scrittura: usare un valore inferiore rispetto alle UR totali al minuto. Se si dispone di un flusso di dati con un numero elevato di partizioni Spark, l'impostazione di una velocità effettiva del budget consente un bilanciamento maggiore tra tali partizioni.
Contenuto correlato
- Panoramica delle prestazioni del flusso di dati
- Ottimizzazione delle origini
- Ottimizzazione delle trasformazioni
- Uso dei flussi di dati nelle pipeline
Sono disponibili altri articoli relativi alle prestazioni dei flussi di dati: