Guida alle prestazioni e all'ottimizzazione dei flussi di dati per mapping
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
I flussi di dati per mapping nelle pipeline di Azure Data Factory e Synapse offrono un'interfaccia senza codice per progettare, distribuire ed eseguire le trasformazioni di dati su larga scala. Se non si ha familiarità con i flussi di dati per mapping, vedere la panoramica del flusso di dati per mapping. Questo articolo illustra diversi modi per ottimizzare i flussi di dati in modo che soddisfino i benchmark delle prestazioni.
Guardare il video seguente per visualizzare alcuni intervalli di temporizzazione di esempio che trasformano i dati con i flussi di dati.
Monitoraggio delle prestazioni dei flussi di dati
Dopo aver verificato la logica di trasformazione usando la modalità di debug, eseguire il flusso di dati end-to-end come attività in una pipeline. I flussi di dati vengono operativi in una pipeline usando l'attività esegui flusso di dati. L'attività del flusso di dati ha un'esperienza di monitoraggio univoca rispetto ad altre attività che visualizzano un piano di esecuzione dettagliato e un profilo di prestazioni della logica di trasformazione. Per visualizzare informazioni dettagliate sul monitoraggio di un flusso di dati, selezionare l'icona degli occhiali nell'output dell'esecuzione dell'attività di una pipeline. Per altre informazioni, vedere Monitoraggio dei flussi di dati per mapping.

Quando si monitorano le prestazioni del flusso di dati, esistono quattro possibili colli di bottiglia da cercare:
- Ora di avvio del cluster
- Lettura da un'origine
- Tempo di trasformazione
- Scrittura in un sink
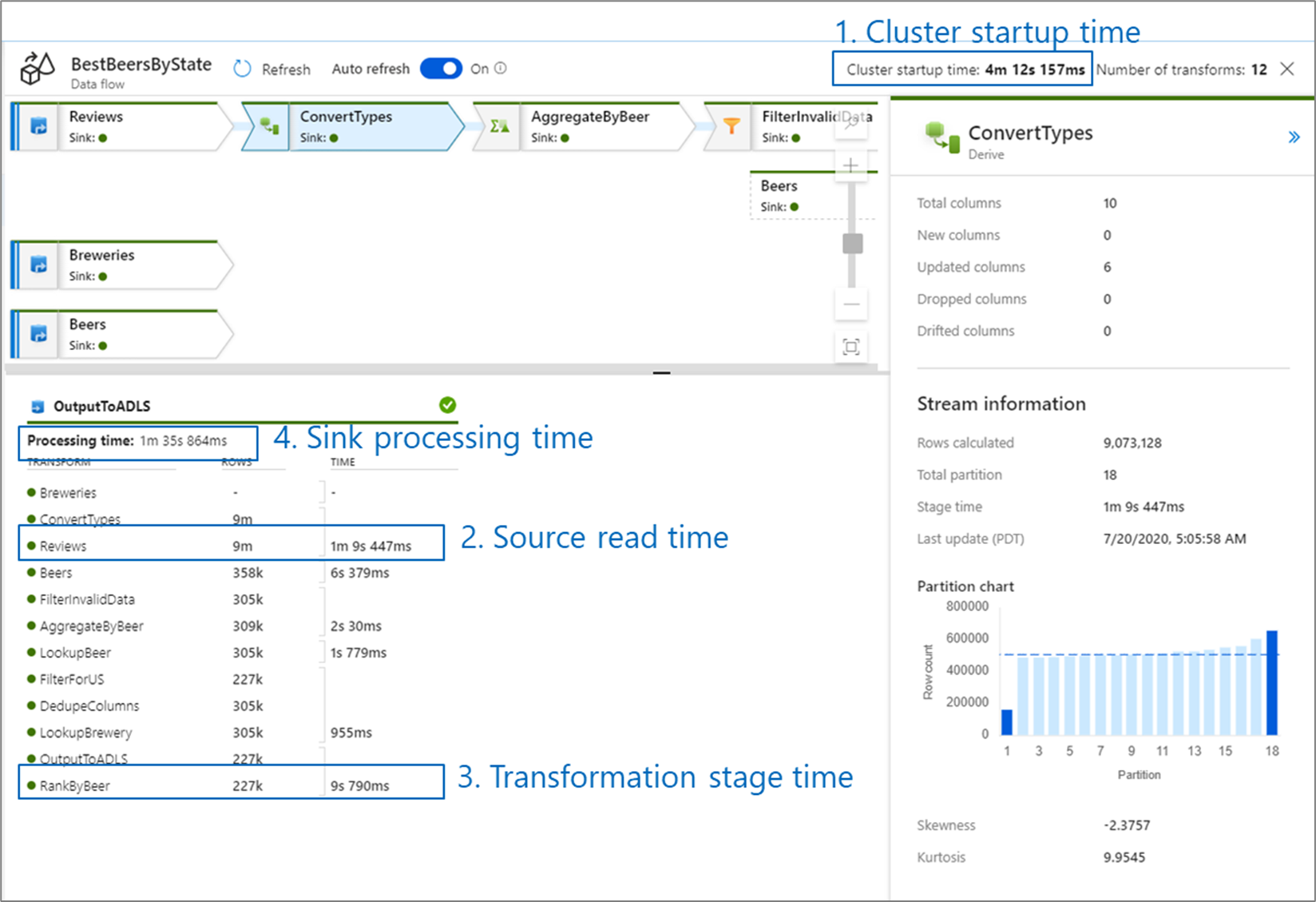
Il tempo di avvio del cluster è il tempo necessario per avviare un cluster Apache Spark. Questo valore si trova nell'angolo superiore destro della schermata di monitoraggio. I flussi di dati vengono eseguiti in un modello JUST-In-Time in cui ogni processo usa un cluster isolato. Questo tempo di avvio richiede in genere 3-5 minuti. Per i processi sequenziali, il tempo di avvio può essere ridotto abilitando un valore di durata (time to live). Per altre informazioni, vedere la sezione Time to live in Integration Runtime performance (Prestazioni del runtime di integrazione).
I flussi di dati usano un ottimizzatore Spark che riordina ed esegue la logica di business in "fasi" per eseguire il più rapidamente possibile. Per ogni sink in cui scrive il flusso di dati, l'output di monitoraggio elenca la durata di ogni fase di trasformazione, insieme al tempo necessario per scrivere dati nel sink. Il tempo più grande è probabilmente il collo di bottiglia del flusso di dati. Se la fase di trasformazione che accetta il più grande contiene un'origine, è possibile esaminare ulteriormente l'ottimizzazione del tempo di lettura. Se una trasformazione richiede molto tempo, potrebbe essere necessario ripartizionare o aumentare le dimensioni del runtime di integrazione. Se il tempo di elaborazione del sink è elevato, potrebbe essere necessario aumentare le prestazioni del database o verificare che non venga restituito un singolo file.
Dopo aver identificato il collo di bottiglia del flusso di dati, usare le strategie di ottimizzazione seguenti per migliorare le prestazioni.
Test della logica del flusso di dati
Quando si progettano e si testano flussi di dati dall'interfaccia utente, la modalità di debug consente di testare in modo interattivo un cluster Spark live, che consente di visualizzare in anteprima i dati ed eseguire i flussi di dati senza attendere il riscaldamento di un cluster. Per altre informazioni, vedere Modalità di debug.
Scheda Ottimizza
La scheda Ottimizza contiene le impostazioni per configurare lo schema di partizionamento del cluster Spark. Questa scheda esiste in ogni trasformazione del flusso di dati e specifica se si desidera ripartizionare i dati dopo il completamento della trasformazione. La regolazione del partizionamento fornisce il controllo sulla distribuzione dei dati tra nodi di calcolo e ottimizzazioni della località dei dati che possono avere effetti positivi e negativi sulle prestazioni complessive del flusso di dati.
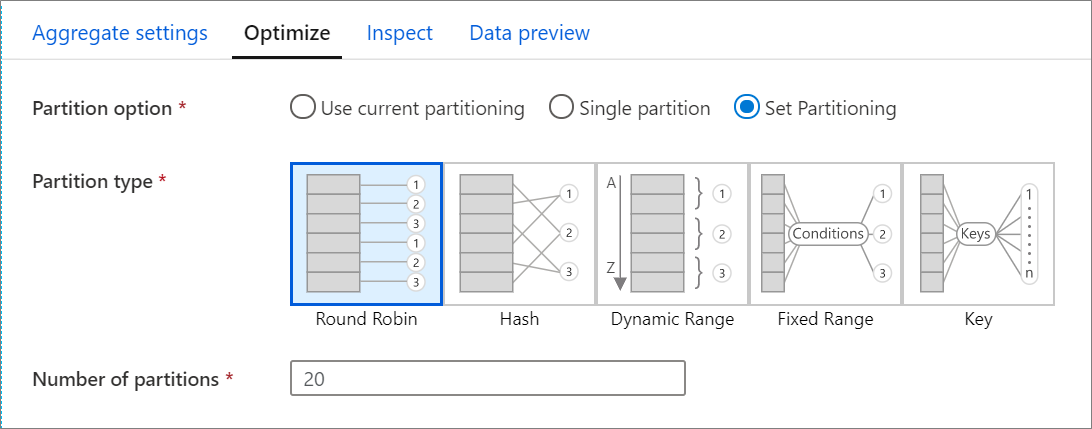
Per impostazione predefinita, è selezionata l'opzione Usa partizionamento corrente che indica al servizio di mantenere il partizionamento dell'output corrente della trasformazione. Poiché la suddivisione dei dati richiede tempo, è consigliabile usare il partizionamento corrente nella maggior parte degli scenari. Gli scenari in cui è possibile suddividere i dati includono dopo aggregazioni e join che asimmetria significativamente i dati o quando si usa il partizionamento di origine in un database SQL.
Per modificare il partizionamento in qualsiasi trasformazione, selezionare la scheda Ottimizza e selezionare il pulsante di opzione Imposta partizionamento . Viene visualizzata una serie di opzioni per il partizionamento. Il metodo migliore per il partizionamento è diverso in base ai volumi di dati, alle chiavi candidate, ai valori Null e alla cardinalità.
Importante
Una singola partizione combina tutti i dati distribuiti in una singola partizione. Si tratta di un'operazione molto lenta che influisce in modo significativo anche su tutte le operazioni di trasformazione e scrittura downstream. Questa opzione è fortemente sconsigliata, a meno che non esista un motivo aziendale esplicito per usarla.
In ogni trasformazione sono disponibili le opzioni di partizionamento seguenti:
Round robin
Round robin distribuisce i dati equamente tra le partizioni. Usare il round robin quando non si hanno candidati chiave validi per implementare una strategia di partizionamento intelligente solida e intelligente. È possibile impostare il numero di partizioni fisiche.
Hash
Il servizio produce un hash di colonne per produrre partizioni uniformi, in modo che le righe con valori simili rientrano nella stessa partizione. Quando si usa l'opzione Hash, verificare la possibile asimmetria della partizione. È possibile impostare il numero di partizioni fisiche.
Intervallo dinamico
L'intervallo dinamico usa intervalli dinamici Spark in base alle colonne o alle espressioni fornite. È possibile impostare il numero di partizioni fisiche.
Intervallo fisso
Creare un'espressione che fornisce un intervallo fisso per i valori all'interno delle colonne di dati partizionate. Per evitare l'asimmetria della partizione, è necessario avere una buona conoscenza dei dati prima di usare questa opzione. I valori immessi per l'espressione vengono usati come parte di una funzione di partizione. È possibile impostare il numero di partizioni fisiche.
Chiave
Se si ha una buona conoscenza della cardinalità dei dati, il partizionamento delle chiavi potrebbe essere una buona strategia. Il partizionamento delle chiavi crea partizioni per ogni valore univoco nella colonna. Non è possibile impostare il numero di partizioni perché il numero è basato su valori univoci nei dati.
Suggerimento
L'impostazione manuale dello schema di partizionamento ricompilazione dei dati e può compensare i vantaggi di Spark Optimizer. Una procedura consigliata consiste nel non impostare manualmente il partizionamento a meno che non sia necessario.
Livello di registrazione
Se non è necessaria ogni esecuzione della pipeline delle attività del flusso di dati per registrare completamente tutti i log di telemetria dettagliati, facoltativamente è possibile impostare il livello di registrazione su "Basic" o "Nessuno". Quando si eseguono i flussi di dati in modalità "Dettagliato" (impostazione predefinita), si richiede al servizio di registrare completamente l'attività a ogni singolo livello di partizione durante la trasformazione dei dati. Può trattarsi di un'operazione costosa, quindi l'abilitazione dettagliata solo quando la risoluzione dei problemi può migliorare il flusso di dati complessivo e le prestazioni della pipeline. La modalità "Basic" registra solo le durate della trasformazione dei log mentre "Nessuno" fornirà solo un riepilogo delle durate.

Contenuto correlato
- Ottimizzazione delle origini
- Ottimizzazione dei sink
- Ottimizzazione delle trasformazioni
- Uso dei flussi di dati nelle pipeline
Sono disponibili altri articoli relativi alle prestazioni dei flussi di dati: