Transformer des données à l’aide de dbt
Remarque
Apache Airflow Job est alimenté par Apache Airflow.
DBT (Data Build Tool) est une interface de ligne de commande (CLI) open source qui simplifie la transformation et la modélisation des données dans les entrepôts de données en gérant du code SQL complexe de manière structurée et gérable. Elle permet aux équipes de données de créer des transformations fiables et testables au cœur de leurs pipelines analytiques.
Lorsqu’elles sont associées à Apache Airflow, les fonctionnalités de transformation de DBT sont améliorées par les fonctionnalités de planification, d’orchestration et de gestion des tâches d’Airflow. Cette approche combinée, associant l’expertise de DBT en matière de transformation à la gestion des flux de travail d’Airflow, permet d’obtenir des pipelines de données efficaces et robustes, ce qui se traduit par des décisions plus rapides et plus pertinentes fondées sur les données.
Ce tutoriel montre comment créer un DAG Apache Airflow qui utilise DBT pour transformer des données stockées dans l’entrepôt de données Microsoft Fabric.
Prérequis
Pour commencer, vous devez remplir les conditions préalables suivantes :
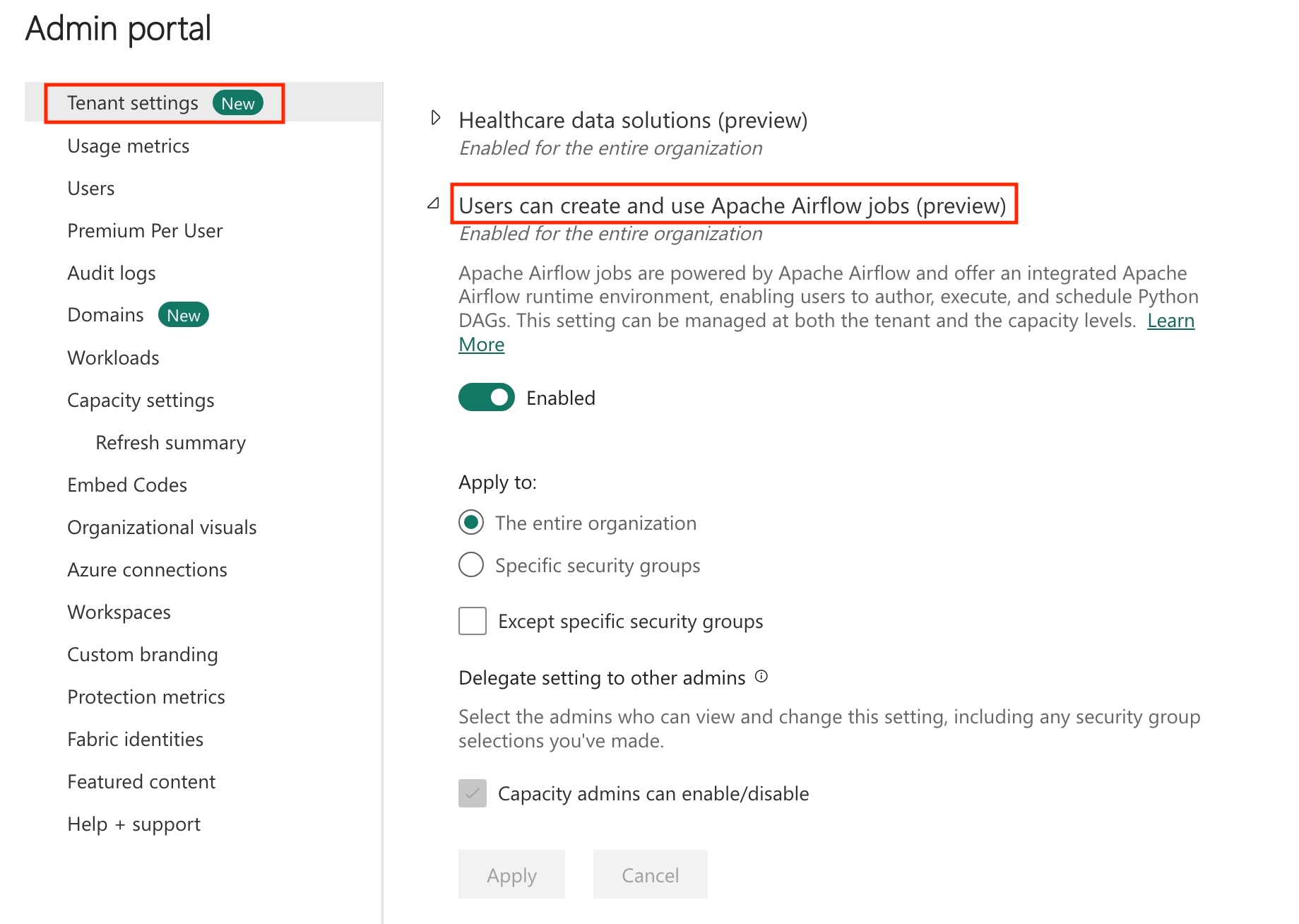
Activez Apache Airflow Job dans votre locataire.
Remarque
Étant donné qu’Apache Airflow Job est en préversion, vous devez l’activer via votre administrateur client. Si vous voyez déjà Apache Airflow Job, votre administrateur client peut l’avoir déjà activé.
Accédez au portail d’administration –> Paramètres du locataire –> Sous Microsoft Fabric –> Développez la section « Les utilisateurs peuvent créer et utiliser Apache Airflow Job (préversion) ».
Sélectionnez Appliquer.
Créez le principal de service. Ajoutez le principal de service en tant que
Contributordans l’espace de travail où vous créez un entrepôt de données.Si vous n’en avez pas encore, créez un Fabric Warehouse. Ingérez des données dans votre entrepôt à l’aide de pipelines de données. Pour ce tutoriel, nous utilisons l’exemple NYC Taxi-Green.

Transformer les données stockées dans Fabric Warehouse à l’aide de dbt
Cette section vous permet de vous familiariser avec les étapes suivantes :
- Spécifiez les exigences.
- Créez un projet DBT dans le stockage managé Fabric fourni par la tâche Apache Airflow.
- Créer un DAG Apache Airflow pour orchestrer des travaux dbt
Spécifier les exigences
Créez un fichier nommé requirements.txt dans le dossier dags. Ajoutez les packages suivants en tant que configuration requise pour Apache Airflow.
astronomer-cosmos : ce package est utilisé pour exécuter vos projets dbt core en tant que dags Apache Airflow et groupes de tâches.
dbt-fabric : ce package est utilisé pour créer un projet DBT, qui peut ensuite être déployé sur un entrepôt de données Fabric
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Créez un projet DBT dans le stockage managé Fabric fourni par la tâche Apache Airflow.
Dans cette section, nous créons un exemple de projet DBT dans la tâche Apache Airflow pour le jeu de données
nyc_taxi_greenavec la structure de répertoire suivante.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetCréez le dossier
nyc_taxi_greendans le dossierdagsavec le fichierprofiles.yml. Ce dossier contient tous les fichiers requis pour le projet dbt.
Copiez le contenu suivant dans le
profiles.yml. Ce fichier de configuration contient les détails et les profils de connexion de base de données utilisés par dbt. Mettez à jour les valeurs d’espace réservé et enregistrez le fichier.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>Créez un fichier
dbt_project.ymlpuis copiez-y le contenu suivant. Ce fichier spécifie la configuration au niveau du projet.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tableCréez le dossier
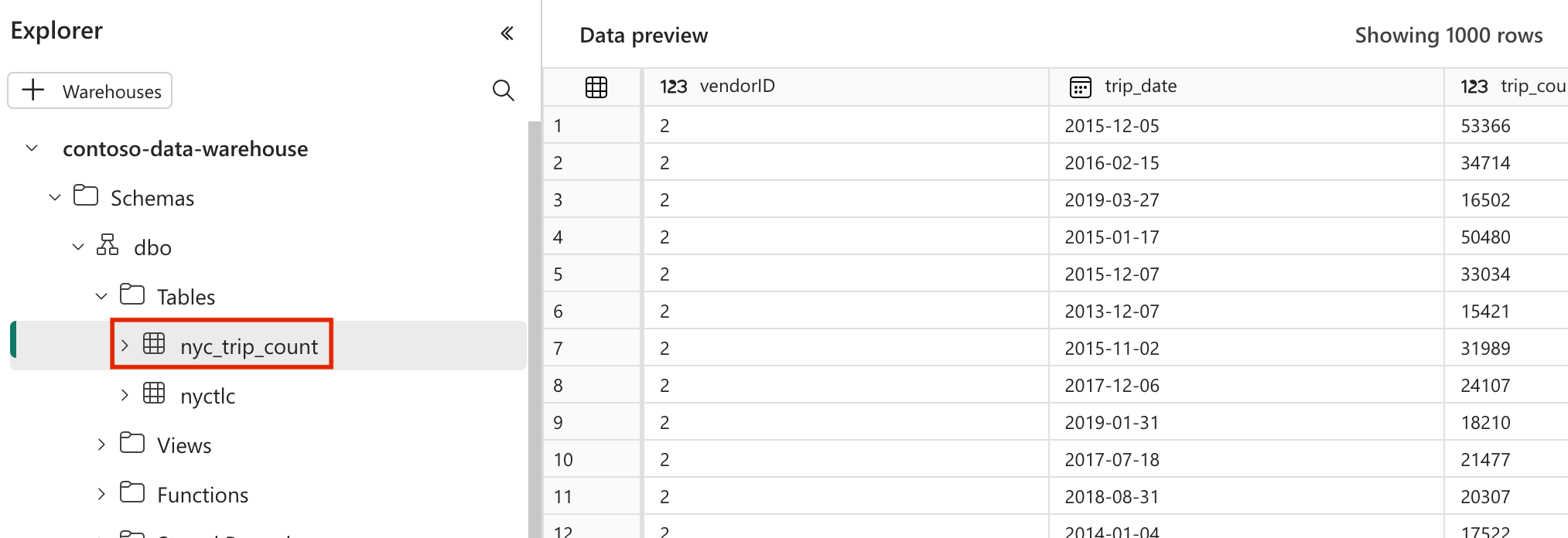
modelsdans le dossiernyc_taxi_green. Pour ce tutoriel, nous créons l’exemple de modèle dans le fichier nomményc_trip_count.sqlqui crée la table affichant le nombre d’allers-retours par jour par fournisseur. Copiez le contenu suivant dans le fichier.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


Créer un DAG Apache Airflow pour orchestrer des travaux dbt
Créez le fichier nommé
my_cosmos_dag.pydans le dossierdagset collez-y le contenu suivant.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
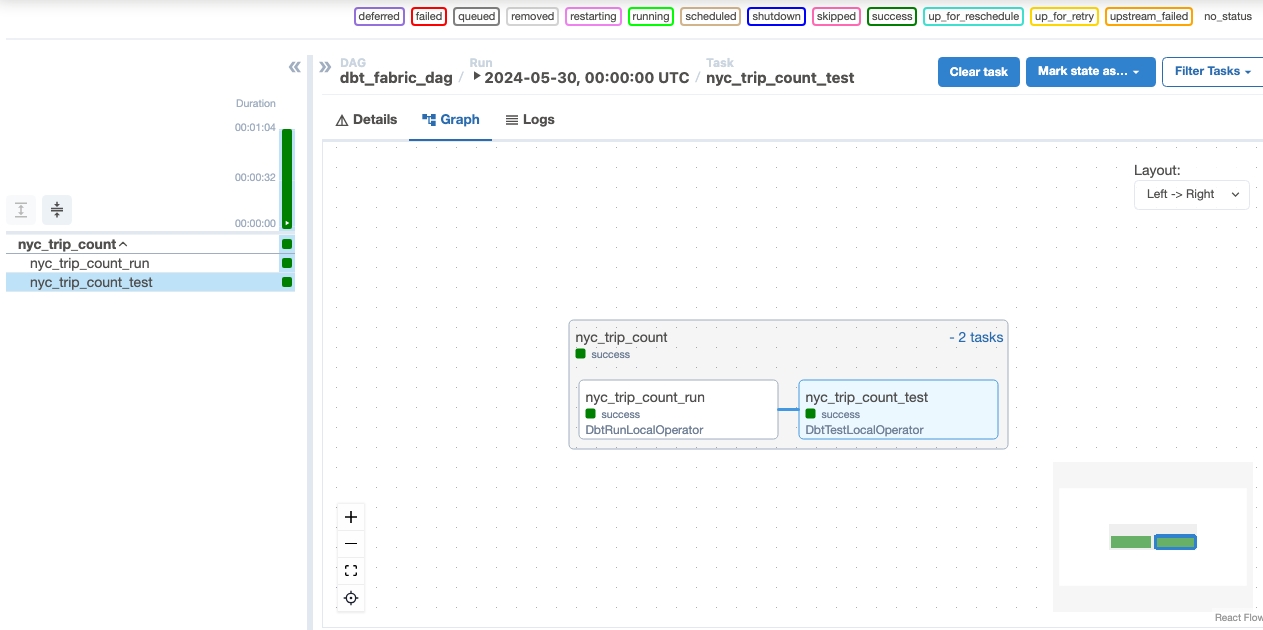
Exécuter votre DAG
Exécutez le DAG dans la tâche Apache Airflow.
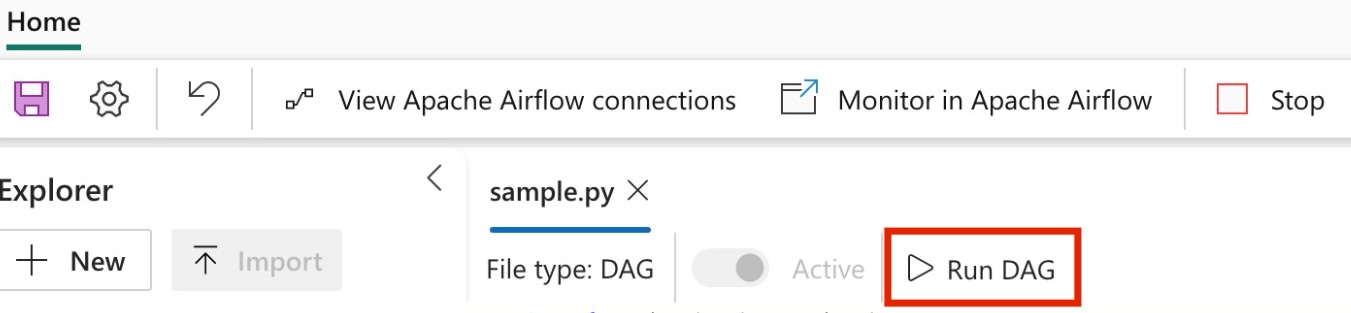
Pour voir votre DAG chargé dans l’IU Apache Airflow, cliquez sur
Monitor in Apache Airflow.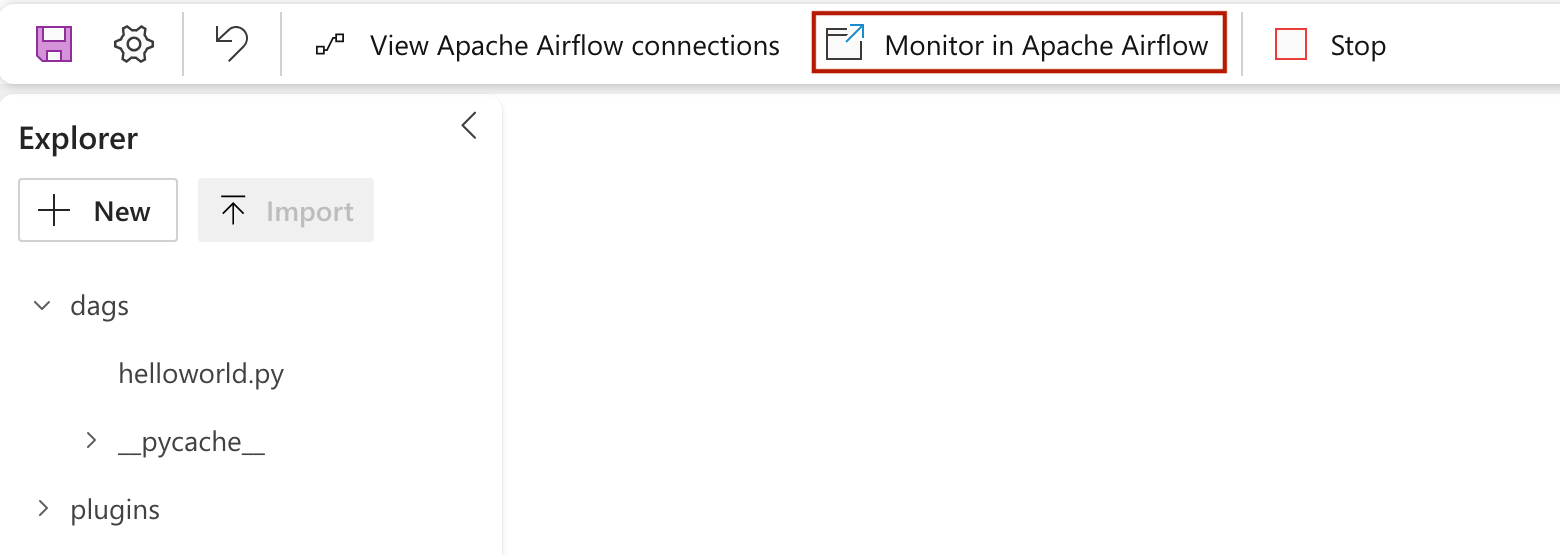



Valider vos données
- Après une exécution réussie, pour valider vos données, vous pouvez voir la nouvelle table nommée « nyc_trip_count.sql » créée dans votre entrepôt de données Fabric.