Opetusohjelma: Kyselyjen tekeminen KQL-tietokannasta muistikirjan ja Apache Sparkin avulla
Muistikirjat ovat sekä luettavissa olevia asiakirjoja, jotka sisältävät tietoanalyysin kuvauksia ja tuloksia sekä suoritettavia tiedostoja tietojen analysointia varten. Tässä artikkelissa opit käyttämään Microsoft Fabric -muistikirjaa tietojen lukemiseen ja kirjoittamiseen KQL-tietokantaan Apache Sparkin avulla. Tässä opetusohjelmassa käytetään esi luotuja tietojoukkoja ja muistikirjoja sekä Reaaliaikainen tieto- että Tietotekniikka-ympäristöissä Microsoft Fabricissa. Lisätietoja muistikirjoista on ohjeaiheessa Microsoft Fabric -muistikirjojen käyttäminen.
Opit erityisesti
- KQL-tietokannan luominen
- Muistikirjan tuominen
- Tietojen kirjoittaminen KQL-tietokantaan Apache Sparkin avulla
- Tietojen kyseleminen KQL-tietokannasta
Edellytykset
- Työtila, jossa on Microsoft Fabric -yhteensopiva kapasiteetti
1- KQL-tietokannan luominen
Avaa siirtymisruudun alareunassa oleva käyttökokemuksen vaihtaja ja valitse Reaaliaikaiset tiedot.
Valitse KQL-tietokannan ruutu.
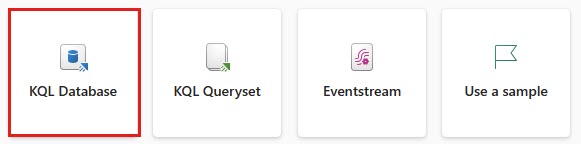
Kirjoita KQL-tietokannan nimi -kenttään nycGreenTaxi ja valitse sitten Luo.
KQL-tietokanta luodaan valitun työtilan kontekstissa.
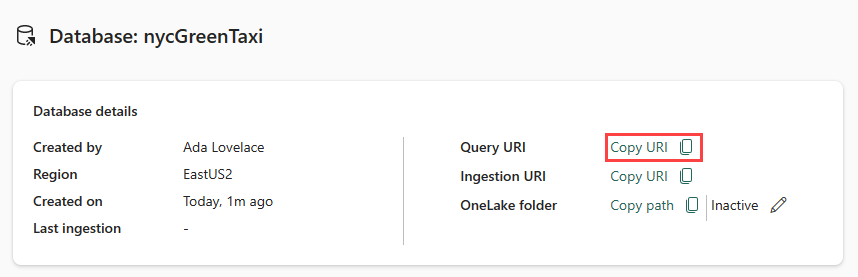
Kopioi kyselyn URI tietokannan tietokortista tietokannan koontinäytöstä ja liitä se jonnekin, kuten muistioon, jotta sitä voidaan käyttää myöhemmässä vaiheessa.
2- Lataa NYC GreenTaxi notebook
Olemme luoneet mallimuistikirjan, jossa käydään läpi kaikki tarvittavat vaiheet tietojen lataamiseksi tietokantaan Spark-liittimen avulla.
Lataa NYC GreenTaxi KQL -muistikirja avaamalla Fabric-mallisäilön GitHubissa.

Tallenna muistikirja paikallisesti laitteeseesi.
Muistiinpano
Muistikirja on tallennettava tiedostomuodossa
.ipynb.

3- Tuo muistikirja
Tämän työnkulun loppuosa tapahtuu tuotteen Tietotekniikka-osassa , ja se käyttää Spark-muistikirjaa tietojen lataamiseen ja kyselemiseen KQL-tietokannassasi.
Avaa siirtymisruudun alareunassa oleva käyttökokemuksen vaihtaja, valitse Kehitä ja sitten työtila.
Valitse Tuo>muistikirja>tästä tietokoneesta>Lataa ja valitse sitten edellisessä vaiheessa lataamasi NYC GreenTaxi -muistikirja.
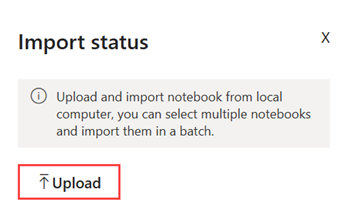
Kun tuonti on valmis, avaa muistikirja työtilastasi.
4- Nouda tiedot
Jos haluat tehdä tietokantakyselyn Spark-liittimen avulla, sinun on annettava luku- ja kirjoitusoikeudet NYC GreenTaxi blob -säilöön.
Suorita seuraavat solut valitsemalla toistopainike tai valitse solu ja paina Vaihto+ Enter -näppäintä. Toista tämä vaihe jokaisen koodisolun kohdalla.
Muistiinpano
Odota, että valmistumisen valintamerkki tulee näkyviin ennen seuraavan solun suorittamista.
Suorita seuraava solu, jotta voit ottaa käyttöön NYC GreenTaxi blob -säilön.
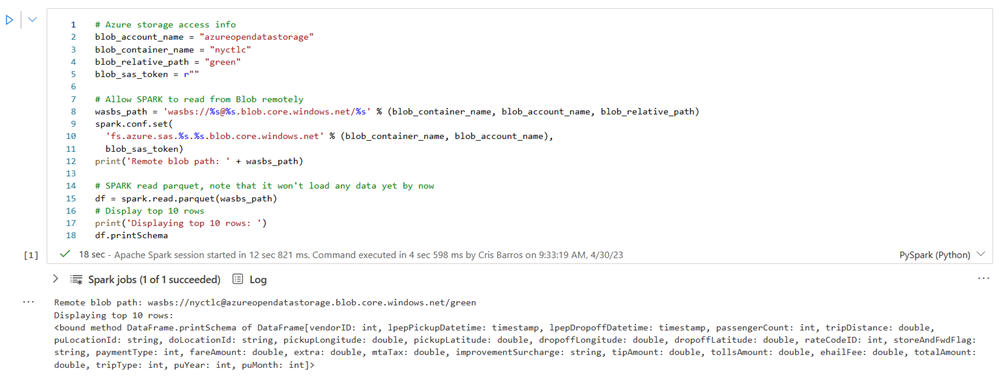
Liitä KustoURI:ssa aiemmin kopioimasi kyselyn URI-osoite paikkamerkkitekstin sijaan.
Muuta paikkamerkkitietokannan nimeksi nycGreenTaxi.
Muuta paikkamerkkitaulukon nimeksi GreenTaxiData.

Suorita solu.
Kirjoita tiedot tietokantaan suorittamalla seuraava solu. Tämän vaiheen suorittaminen voi kestää muutamia minuutteja.




Tietokannassa on nyt tietoja ladattuna taulukkoon nimeltä GreenTaxiData.
5- Suorita muistikirja
Suorita loput kaksi solua peräkkäin tietojen kyselemiseksi taulukosta. Tulokset näyttävät 20 suurinta ja alhaisimmat taksihinnat ja etäisyydet vuoden mukaan.

6- Tyhjennä resurssit
Tyhjennä luodut kohteet siirtymällä työtilaan, jossa ne on luotu.
Siirrä työtilassa hiiren osoitin poistettavan muistikirjan päälle, valitse Lisää-valikko [...] >Poista.
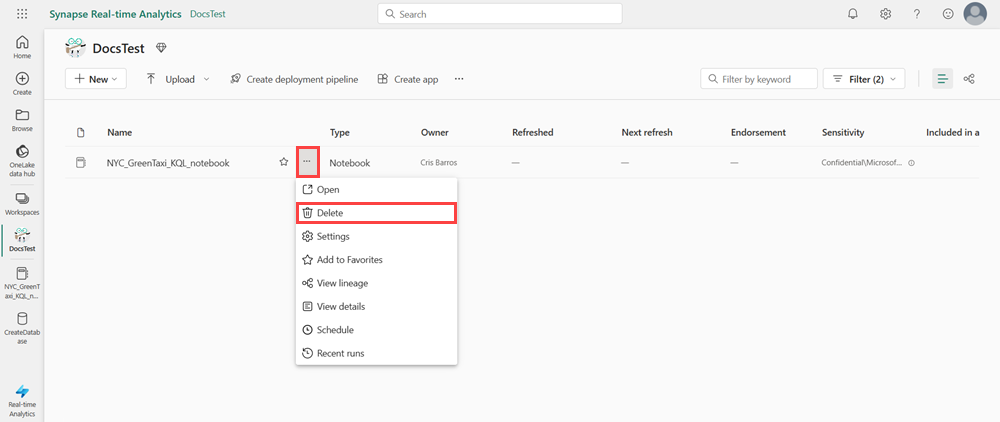
Valitse Poista. Muistikirjaa ei voi palauttaa, kun se on poistettu.
