Käytä Siistiä
Siistimpi on kokoelma R-paketteja, joita tietojenkäsittelyasiantuntijat käyttävät yleisimmin tavallisissa tietoanalyyseissä. Se sisältää paketit tietojen tuomista (readr), tietojen visualisointia (ggplot2), tietojen käsittelyä (dplyr, tidyr), funktionaalista ohjelmointia (purrr) ja mallin luomista (tidymodels) varten. In-paketit tidyverse on suunniteltu toimimaan saumattomasti yhteen ja noudattamaan yhdenmukaisia suunnitteluperiaatteita.
Microsoft Fabric jakaa -sovelluksen uusimman vakaan version jokaisen suorituksenaikaisen julkaisun tidyverse yhteydessä. Tuo ja aloita tuttujen R-pakettien käyttö.
Edellytykset
Hanki Microsoft Fabric -tilaus. Voit myös rekisteröityä ilmaiseen Microsoft Fabric -kokeiluversioon.
Siirry Synapse Data Science -käyttökokemukseen aloitussivun vasemmassa reunassa olevan käyttökokemuksen vaihtajan avulla.

Avaa muistikirja tai luo se. Lisätietoja on artikkelissa Microsoft Fabric -muistikirjojen käyttäminen.
Muuta ensisijaista kieltä määrittämällä kieliasetukseksi SparkR (R ).
Liitä muistikirjasi Lakehouseen. Valitse vasemmalla puolella Lisää lisätäksesi olemassa olevan lakehousen tai luodaksesi lakehousen.
Kuorma tidyverse
# load tidyverse
library(tidyverse)
Tietojen tuonti
readr on R-paketti, joka tarjoaa työkaluja suorakulmaisten datatiedostojen, kuten CSV-, TSV- ja kiinteäleveyksisten tiedostojen, lukemiseen. readr tarjoaa nopean ja helpon tavan lukea suorakulmaisia datatiedostoja, kuten funktioita read_csv() sekä read_tsv() lukea CSV- ja TSV-tiedostoja.
Luodaan ensin R-data.frame, kirjoitetaan se Lakehouse-järjestelmään käyttämällä readr::write_csv() ja luetaan se uudelleen :n avulla readr::read_csv().
Muistiinpano
Jos haluat käyttää Lakehouse-tiedostoja :n avullareadr, sinun on käytettävä Tiedoston ohjelmointirajapinnan polkua. Napsauta Lakehouse Explorerissa hiiren kakkospainikkeella tiedostoa tai kansiota, jota haluat käyttää, ja kopioi sen Tiedoston ohjelmointirajapinnan polku pikavalikosta.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Kirjoitetaan sitten tiedot Lakehouseen tiedoston ohjelmointirajapinnan polun avulla.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Lue tiedot Lakehousesta.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Tietojen siistiminen
tidyr on R-paketti, joka tarjoaa työkaluja sotkuisten tietojen käsittelyyn. Kohteen pääfunktiot tidyr on suunniteltu auttamaan tietojen muotoilussa siistiin muotoon. Siisteillä tiedoilla on tietty rakenne, jossa kukin muuttuja on sarake ja kukin havainto on rivi, mikä helpottaa tietojen käsittelemistä R:ssä ja muissa työkaluissa.
Esimerkiksi funktiota gather() in tidyr voi käyttää leveiden tietojen muuntamiseen pitkiksi tiedoiksi. Esimerkki:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Funktionaalinen ohjelmointi
purrr on R-paketti, joka parantaa R:n funktionaalista ohjelmointityökalupakettia tarjoamalla kattavan ja yhtenäisen työkalujoukon funktioiden ja vektorien käsittelemiseen. Paras paikka aloittaa purrr on funktioperhe map() , jonka avulla voit korvata useita silmukoita koodilla, joka on sekä ytimekkömpi että helpompi lukea. Tässä on esimerkki siitä, miten funktiota käytetään map() luettelon eri elementteihin:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Tietojen käsittely
dplyr on R-paketti, joka tarjoaa yhtenäisen verbijoukon, joka auttaa ratkaisemaan yleisimpiä tietojenkäsittelyongelmia, kuten muuttujien valitseminen nimien perusteella, arvojen perusteella poimintatapaukset, useiden arvojen pienentäminen yhteen yhteenvetoon ja rivien järjestyksen muuttaminen jne. Seuraavassa on joitakin esimerkkejä:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Tietojen visualisointi
ggplot2 on R-paketti grafiikan deklaratiiviseen luomiseen Grafiikan kieliopin perusteella. Annat tiedot, kerrot ggplot2 , miten muuttujia yhdistetään estetiikkaan, mitä graafisia primitiivejä käytetään, ja se huolehtii yksityiskohdista. Seuraavassa on muutamia esimerkkejä:
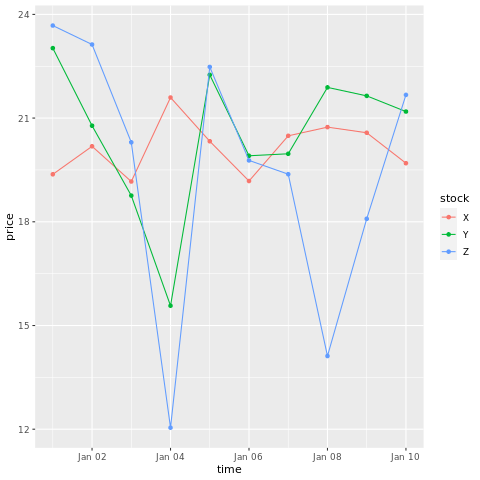
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
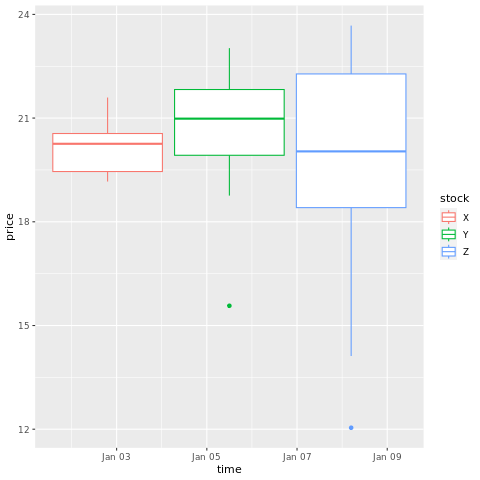
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Mallin luominen
Sovelluskehys tidymodels on kokoelma paketteja mallinnusta ja koneoppimista varten periaatteiden avulla tidyverse . Se kattaa luettelon ydinpaketeista, jotka koskevat monenlaisia mallin luontitehtäviä, kuten rsample junan/testin tietojoukon otosten jakamista, parsnip mallimääritystä, recipes tietojen esikäsittelyä, workflows mallinnustyönkulkuja, tune hyperparametrien säätöä, yardstick mallin arviointia, broom mallitulosteiden seurantaa ja dials parametrien hallintaa. Saat lisätietoja paketeista tutustumalla siistien suodattimien verkkosivustoon. Tässä on esimerkki lineaarisen regressiomallin luomisesta, joka ennustaa auton mailit gallonaa (mpg) kohti sen painon (wt) perusteella:
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
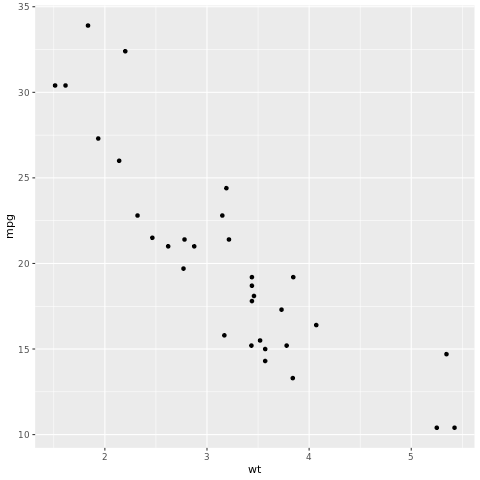
Pistekaaviosta suhde näyttää suunnilleen lineaariselta ja varianssi näyttää vakiolta. Kokeillaanpa mallintamista lineaarisen regression avulla.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Käytä lineaarista regressiomallia testitietojoukon ennustamiseen.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
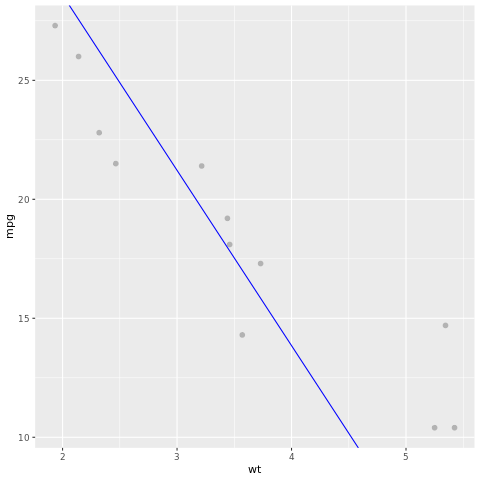
Tutustutaan seuraavaksi mallin tulokseen. Voimme piirtää mallin viivakaaviona ja testata pohjan totuustietoja saman kaavion pisteinä. Malli näyttää hyvältä.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")