Opetusohjelma: Lennon viiveen ennustaminen R:n avulla
Tässä opetusohjelmassa esitellään päästä päähän -esimerkki Synapse Data Science -työnkulusta Microsoft Fabricissa. Se käyttää nycflights13-tietoja ja R: ää ennustamaan, saapuuko kone yli 30 minuuttia myöhään. Sen jälkeen se käyttää ennustetuloksia vuorovaikutteisen Power BI -koontinäytön luomiseen.
Tässä opetusohjelmassa opit:
- Käytä siistejä paketteja (reseptejä, jäsennystä, rsamplea, työnkulkuja) tietojen käsittelyyn ja koneoppimismallin kouluttamiseen
- Kirjoita tulostiedot Lakehouse-järjestelmään delta-taulukkona
- Luo Power BI -visualisointiraportti, jotta voit käyttää suoraan kyseisen lakehousen tietoja
Edellytykset
Hanki Microsoft Fabric -tilaus. Voit myös rekisteröityä ilmaiseen Microsoft Fabric -kokeiluversioon.
Siirry Synapse Data Science -käyttökokemukseen aloitussivun vasemmassa reunassa olevan käyttökokemuksen vaihtajan avulla.

Avaa muistikirja tai luo se. Lisätietoja on artikkelissa Microsoft Fabric -muistikirjojen käyttäminen.
Muuta ensisijaista kieltä määrittämällä kieliasetukseksi SparkR (R ).
Liitä muistikirjasi Lakehouseen. Valitse vasemmalla puolella Lisää lisätäksesi olemassa olevan lakehousen tai luodaksesi lakehousen.
Pakettien asentaminen
Asenna nycflights13-paketti, jotta voit käyttää koodia tässä opetusohjelmassa.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Tietojen tutkiminen
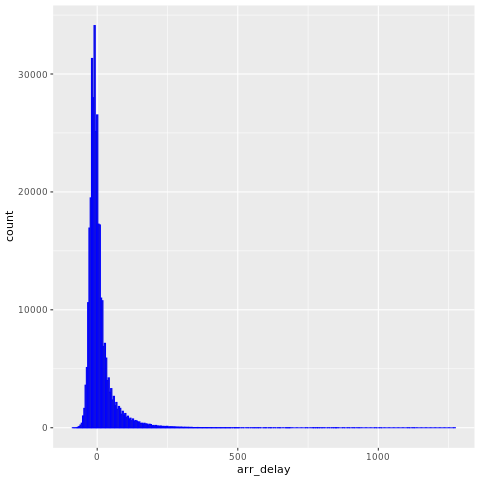
nycflights13 Tiedoissa on tietoa noin 325 819 lennosta, jotka saapuivat New Yorkin lähelle vuonna 2013. Katso ensin lentojen viivästysten jakauma. Tästä kaaviosta käy ilmi, että saapumisviiveiden jakauma on vino. Sillä on pitkä hännän korkeissa arvoissa.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Lataa tiedot ja tee muuttujiin muutamia muutoksia:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Ennen kuin luomme mallin, harkitse muutamia tiettyjä muuttujia, jotka ovat tärkeitä sekä esikäsittelyssä että mallinnmisessa.
Muuttuja arr_delay on kerroinmuuttuja. Logistista regressiomallin harjoittamista varten on tärkeää, että tulosmuuttuja on tekijämuuttuja.
glimpse(flight_data)
Noin 16 % tämän tietojoukon lennoista saapui yli 30 minuuttia myöhään.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
Ominaisuudella dest on 104 lentokohdetta.
unique(flight_data$dest)
On 16 erillistä kantajaa.
unique(flight_data$carrier)
Tietojen jakaminen
Jaa yksittäinen tietojoukko kahdeksi joukoksi : harjoitusjoukko ja testausjoukko . Säilytä suurin osa alkuperäisen tietojoukon riveistä (satunnaisesti valittuna alijoukkona) harjoitustietojoukossa. Harjoitustietojoukon avulla voit sopia malliin ja mitata mallin suorituskykyä testitietojoukon avulla.
rsample Paketin avulla voit luoda objektin, joka sisältää tietoja tietojen jakamisesta. Luo sitten harjoitus- ja testausjoukoille DataFrame-kehyksiä kahden muun rsample funktion avulla:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Reseptin ja roolien luominen
Luo resepti yksinkertaiselle logistiselle regressiomallille. Ennen mallin harjoittamista käytä reseptiä uusien ennusteiden luomiseen ja mallin edellyttämän esikäsittelyn suorittamiseen.
Käytä funktiota update_role() niin, että reseptit tietävät, että flight ja time_hour ovat muuttujia, mukautetulla roolilla nimeltä ID. Roolilla voi olla mikä tahansa merkkiarvo. Kaava sisältää kaikki harjoitusjoukon muuttujat lukuun ottamatta arr_delayennusteina. Resepti säilyttää nämä kaksi id-muuttujaa, mutta ei käytä niitä joko tuloksina tai ennustajina.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Jos haluat tarkastella nykyisiä muuttujien ja roolien joukkoa, käytä -funktiota summary() :
summary(flights_rec)
Ominaisuuksien luominen
Paranna malliasi ominaisuuksien avulla. Lennon päivämäärällä voi olla kohtuullinen vaikutus myöhäisen saapumisen todennäköisyyteen.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Se voi auttaa lisäämään mallitermit, jotka on johdettu päivämäärästä, jolla voi olla merkitystä mallille. Johdettu seuraavat merkitykselliset ominaisuudet yksittäisestä päivämäärämuuttujasta:
- Viikonpäivä
- kuukausi
- Vastaako päivämäärä lomaa vai ei
Lisää kolme vaihetta reseptiin:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Sovita malli reseptin avulla
Käytä logistista regressiota lentotietojen mallintamiseen. Luo ensin mallimääritys paketilla parsnip :
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Niputa workflows mallisi parsnip (lr_mod) reseptin kanssa paketin avulla (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Sinun täytyy harjoittaa malli.
Tämä funktio voi valmistella reseptin ja harjoittaa mallin tuloksena olevista ennusteista:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Käytä apufunktioita xtract_fit_parsnip() ja extract_recipe() poimi malli- tai reseptiobjekteja työnkulusta. Tässä esimerkissä nouda asennettu malliobjekti ja käytä sitten broom::tidy() funktiota saadaksesi siistin pyövelin mallikertoimista:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Tulosten ennustaminen
Yksi kutsu predict() käyttää harjoitetulla työnkululla (flights_fit) ennusteita, joissa on näkymättömiä testitietoja. Menetelmä predict() soveltaa reseptiä uusiin tietoihin ja välittää sitten tulokset varustettuun malliin.
predict(flights_fit, test_data)
Hae tulos kohteesta predict() , jotta voit palauttaa ennustetun luokan: late verrattuna on_time. Kuitenkin kunkin lennon ennustetuille luokan todennäköisyyksille käytetään augment() mallia yhdessä testitietojen kanssa niiden tallentamiseksi yhteen:
flights_aug <-
augment(flights_fit, test_data)
Tarkista tiedot:
glimpse(flights_aug)
Mallin arvioiminen
Meillä on nyt tibble ennustetulla luokan todennäköisyydellä. Ensimmäisillä riveillä malli ennusti oikein viisi lentoa ajallaan (arvot .pred_on_time ovat p > 0.50). Ennustettavana on kuitenkin 81 455 riviä.
Tarvitsemme mittarin, joka kertoo, kuinka hyvin malli ennusti myöhässä saapumiset, verrattuna tulosmuuttujan todelliseen tilaan. arr_delay
Käytä mittayksikkönä käyrän vastaanottimen toimintaominaisuutena olevaa aluetta (AUC-ROC). Laske se :n ja roc_auc():n avulla roc_curve() paketistayardstick:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Luo Power BI -raportti
Mallin tulos näyttää hyvältä. Luo vuorovaikutteinen Power BI -koontinäyttö lennon viiveen ennustetulosten avulla. Koontinäytössä näkyy lentojen määrä lentoyhtiön mukaan ja lentojen määrä kohteen mukaan. Koontinäyttö voi suodattaa viivettä ennustetulosten mukaan.
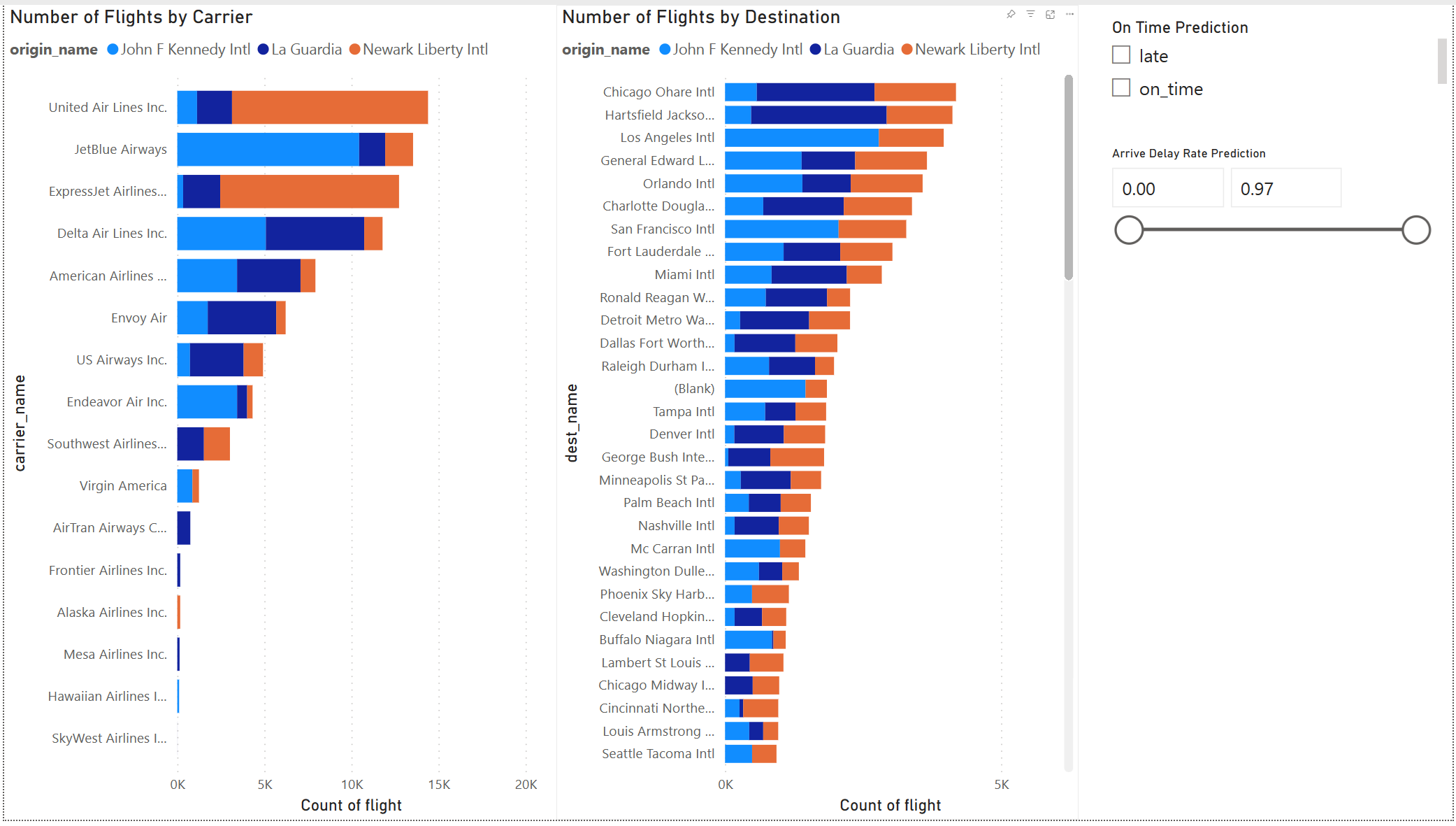
Sisällytä kantajan nimi ja lentokentän nimi ennustetulostietojoukkoon:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Tarkista tiedot:
glimpse(flights_clean)
Muunna tiedot Spark DataFrame -kehykseksi:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Kirjoita tiedot Lakehousessasi delta-taulukkoon:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Voit luoda semanttisen mallin deltataulukon avulla.
Valitse vasemmalta OneLake-tietokeskus
Valitse lakehouse, jonka kiinnitit muistikirjaasi
Valitse Avaa
Valitse Uusi semanttinen malli
Valitse uuden semanttisen mallin nycflight13 ja valitse sitten Vahvista
Semanttinen mallisi on luotu. Valitse Uusi raportti
Luo raportti valitsemalla tai vetämällä kenttiä Tiedot - ja Visualisoinnit-ruuduista raporttipohjalle
Voit luoda tämän osion alussa näkyvän raportin käyttämällä näitä visualisointeja ja tietoja:
 Pinottu palkkikaavio, jossa on:
Pinottu palkkikaavio, jossa on: - Y-akseli: carrier_name
- X-akseli: lento. Valitse Koosteelle Määrä
- Selite: origin_name
- Pinottu palkkikaavio, jossa on:
- Y-akseli: dest_name
- X-akseli: lento. Valitse Koosteelle Määrä
- Selite: origin_name
 Osittaja, jossa:
Osittaja, jossa: - Kenttä: _pred_class
- Osittaja, jossa:
- Kenttä: _pred_late