Envío de trabajos de Spark en Azure Machine Learning
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Azure Machine Learning admite los envíos de trabajo de aprendizaje automático independientes y la creación de canalizaciones de aprendizaje automático que implican varios pasos del flujo de trabajo de aprendizaje automático. Azure Machine Learning controla la creación de trabajos de Spark independientes y de componentes de Spark reutilizables que las canalizaciones de Azure Machine Learning pueden usar. En este artículo, aprenderá a enviar trabajos de Spark con:
- IU del Estudio de Azure Machine Learning
- CLI de Azure Machine Learning
- SDK de Azure Machine Learning
Para más información sobre Conceptos de Apache Spark en Azure Machine Learning, visite este recurso.
Requisitos previos
SE APLICA A: Extensión de ML de la CLI de Azure v2 (actual)
- Una suscripción a Azure: si aún no tiene ninguna, cree una cuenta gratuita antes de empezar.
- Un área de trabajo de Azure Machine Learning. Visite Crear recursos del área de trabajo para obtener más información.
- Creará una instancia de proceso de Azure Machine Learning.
- Instalar la CLI de Azure Machine Learning.
- (Opcional): un grupo de Synapse Spark asociado en el área de trabajo de Azure Machine Learning.
Nota:
- Para obtener más información sobre el acceso a los recursos mientras se usa el proceso de Spark sin servidor de Azure Machine Learning y el grupo de Spark de Synapse conectado, visite Garantizar el acceso a los recursos para trabajos de Spark.
- Azure Machine Learning proporciona un grupo de cuota compartida desde el que todos los usuarios pueden acceder a la cuota de proceso para realizar pruebas durante un tiempo limitado. Cuando se usa el proceso de Spark sin servidor, Azure Machine Learning le permite acceder a esta cuota compartida durante un breve tiempo.
Asociación de identidades administradas asignadas por el usuario mediante la CLI v2
- Cree un archivo YAML que defina la identidad administrada asignada por el usuario que se debe asociar al área de trabajo:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - Con el parámetro
--file, use el archivo YAML en el comandoaz ml workspace updatepara asociar la identidad administrada asignada por el usuario:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Asociación de identidades administradas asignadas por el usuario mediante ARMClient
- Instale
ARMClient, una sencilla herramienta de línea de comandos que invoca la API de Azure Resource Manager. - Cree un archivo JSON que defina la identidad administrada asignada por el usuario que se debe asociar al área de trabajo:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Para adjuntar la identidad administrada asignada por el usuario al área de trabajo, ejecute el siguiente comando en el símbolo del sistema o en el símbolo del sistema de PowerShell.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Nota:
- Para garantizar la ejecución correcta del trabajo de Spark, debe asignar los roles Colaborador y Colaborador de datos de Storage Blob, que hay en la cuenta de almacenamiento de Azure que se usa para la entrada y salida de datos, a la identidad que usa el trabajo de Spark.
- El acceso a la red pública debe estar habilitado en el área de trabajo de Azure Synapse para garantizar la correcta ejecución del trabajo de Spark mediante un grupo de Synapse Spark conectado.
- En un área de trabajo Azure Synapse, que tiene una red virtual administrada asociada, si un grupo de Synapse Spark adjunto apunta a un grupo Synapse Spark debe configurar un punto de conexión privado administrado a una cuenta de almacenamiento para garantizar el acceso a los datos.
- El proceso de Spark sin servidor admite la red virtual administrada de Azure Machine Learning. Si se aprovisiona una red administrada para el proceso de Spark sin servidor, también se deben aprovisionar los puntos de conexión privados correspondientes para la cuenta de almacenamiento para garantizar el acceso a los datos.
Enviar un trabajo independiente de Spark
Después de realizar los cambios necesarios para la parametrización de script de Python, puede usar un script de Python desarrollado con limpieza y transformación de datos interactivos para enviar un trabajo por lotes, a fin de procesar un mayor volumen de datos. Puede enviar un trabajo por lotes de limpieza y transformación de datos como un trabajo de Spark independiente.
Un trabajo de Spark requiere un script de Python que tome argumentos. Puede modificar el código de Python desarrollado originalmente a partir de la limpieza y transformación de datos interactivos para desarrollar ese script. Aquí se muestra un script de Python de ejemplo.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Nota:
En este ejemplo de código de Python se usa pyspark.pandas. Esto solo se admite en el entorno de ejecución Spark versión 3.2 o posteriores.
Este script toma dos argumentos, que pasan la ruta de acceso de los datos de entrada y la carpeta de salida, respectivamente:
--titanic_data--wrangled_data
SE APLICA A: Extensión de ML de la CLI de Azure v2 (actual)
Para crear un trabajo, puede definir un trabajo de Spark independiente como un archivo de especificación YAML, que puede usar en el comando az ml job create, con el parámetro --file. Defina estas propiedades en el archivo YAML:
Propiedades de YAML en la especificación del trabajo de Spark
type: establecer enspark.code: define la ubicación de la carpeta que contiene código fuente y scripts para este trabajo.entry: define el punto de entrada del trabajo. Debe cubrir una de estas propiedades:file: define el nombre del script de Python que actúa como punto de entrada para el trabajo.class_name: define el nombre de la clase que actúa como punto de entrada para el trabajo.
py_files: define una lista de archivos.zip,.eggo.py, que se colocarán enPYTHONPATH, para la ejecución correcta del trabajo. Esta propiedad es opcional.jars: define una lista de archivos.jarque se van a incluir en el controlador de Spark y el ejecutorCLASSPATH, para la ejecución correcta del trabajo. Esta propiedad es opcional.files: define una lista de archivos que se deben copiar en el directorio de trabajo de cada ejecutor para la ejecución correcta del trabajo. Esta propiedad es opcional.archives: define una lista de archivos que se deben extraer en el directorio de trabajo de cada ejecutor para la ejecución correcta del trabajo. Esta propiedad es opcional.conf: define estas propiedades de controlador y ejecutor de Spark:spark.driver.cores: el número de núcleos para el controlador de Spark.spark.driver.memory: memoria asignada para el controlador spark, en gigabytes (GB).spark.executor.cores: el número de núcleos para el ejecutor de Spark.spark.executor.memory: asignación de memoria para el ejecutor de Spark, en gigabytes (GB).spark.dynamicAllocation.enabled: si los ejecutores deben asignarse de forma dinámica, como valorTrueoFalse.- Si la asignación dinámica de ejecutores está habilitada, define estas propiedades:
spark.dynamicAllocation.minExecutors: el número mínimo de instancias de ejecutores de Spark para la asignación dinámica.spark.dynamicAllocation.maxExecutors: el número máximo de instancias de ejecutores de Spark para la asignación dinámica.
- Si la asignación dinámica de ejecutores está deshabilitada, define esta propiedad:
spark.executor.instances: el número de instancias del ejecutor de Spark.
environment: un entorno de Azure Machine Learning para ejecutar el trabajo.args: argumentos de la línea de comandos que se deben pasar al script de Python del punto de entrada del trabajo. Revise el archivo de especificación YAML que se proporciona aquí para obtener un ejemplo.resources: esta propiedad define los recursos que va a usar un proceso de Spark sin servidor de Azure Machine Learning. Usa las siguientes propiedades:instance_type: el tipo de instancia de proceso que se va a usar para el grupo de Spark. Actualmente se admiten los siguientes tipos de instancias:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version: define la versión del entorno de ejecución de Spark. Actualmente se admiten las siguientes versiones del entorno de ejecución de Spark:3.33.4Importante
Azure Synapse Runtime para Apache Spark: Anuncios
- Entorno de ejecución de Azure Synapse para Apache Spark 3.3:
- Fecha de anuncio de EOLA: 12 de julio de 2024
- Fecha de finalización del soporte: 31 de marzo de 2025. Luego de esta fecha, el tiempo de ejecución se desactivará.
- Para obtener soporte técnico continuo y un rendimiento óptimo, se recomienda migrar a Apache Spark 3.4.
- Entorno de ejecución de Azure Synapse para Apache Spark 3.3:
Este es un archivo YAML de ejemplo:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute: esta propiedad define el nombre de un grupo de Synapse Spark asociado, como se muestra en este ejemplo:compute: mysparkpoolinputs: esta propiedad define entradas para el trabajo de Spark. Las entradas de un trabajo de Spark pueden ser un valor literal o datos almacenados en un archivo o carpeta.- Un valor literal puede ser un número, un valor booleano o una cadena. Aquí se muestran algunos ejemplos:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Los datos almacenados en un archivo o carpeta deben definirse con estas propiedades:
type: establece esta propiedad enuri_file, ouri_folder, para los datos de entrada contenidos en un archivo o una carpeta, respectivamente.path: el URI de los datos de entrada, comoazureml://,abfss://owasbs://.mode: establece esta propiedad endirect. En este ejemplo se muestra la definición de una entrada de trabajo, a la que se puede hacer referencia como$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Un valor literal puede ser un número, un valor booleano o una cadena. Aquí se muestran algunos ejemplos:
outputs: esta propiedad define las salidas del trabajo de Spark. Los resultados de un trabajo de Spark se pueden escribir en un archivo o en una ubicación de carpeta, que se define mediante las tres propiedades siguientes:type: puede establecer esta propiedad enuri_fileouri_folder, para escribir datos de salida en un archivo o una carpeta respectivamente.path: esta propiedad define el URI de ubicación de salida, comoazureml://,abfss://owasbs://.mode: establece esta propiedad endirect. En este ejemplo se muestra la definición de una salida de trabajo, que puede hacer referencia como${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity: esta propiedad opcional define la identidad usada para enviar este trabajo. Puede tener valoresuser_identityymanaged. Si la especificación YAML no define una identidad, el trabajo de Spark usa la identidad predeterminada.
Trabajo de Spark independiente
En este ejemplo de especificación YAML se muestra un trabajo de Spark independiente. Usa un proceso de Spark sin servidor de Azure Machine Learning:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Nota:
Para usar un grupo de Spark Synapse asociado, defina la propiedad compute en el archivo de especificación YAML de ejemplo mostrado anteriormente en lugar de la propiedad resources.
Puede usar los archivos YAML mostrados anteriormente en el comando az ml job create, con el parámetro --file, para crear un trabajo de Spark independiente como se muestra:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Puede ejecutar el comando anterior desde:
- terminal de una instancia de proceso de Azure Machine Learning.
- un terminal de Visual Studio Code conectado a una instancia de proceso de Azure Machine Learning.
- el equipo local que tiene instalada la CLI de Azure Machine Learning.
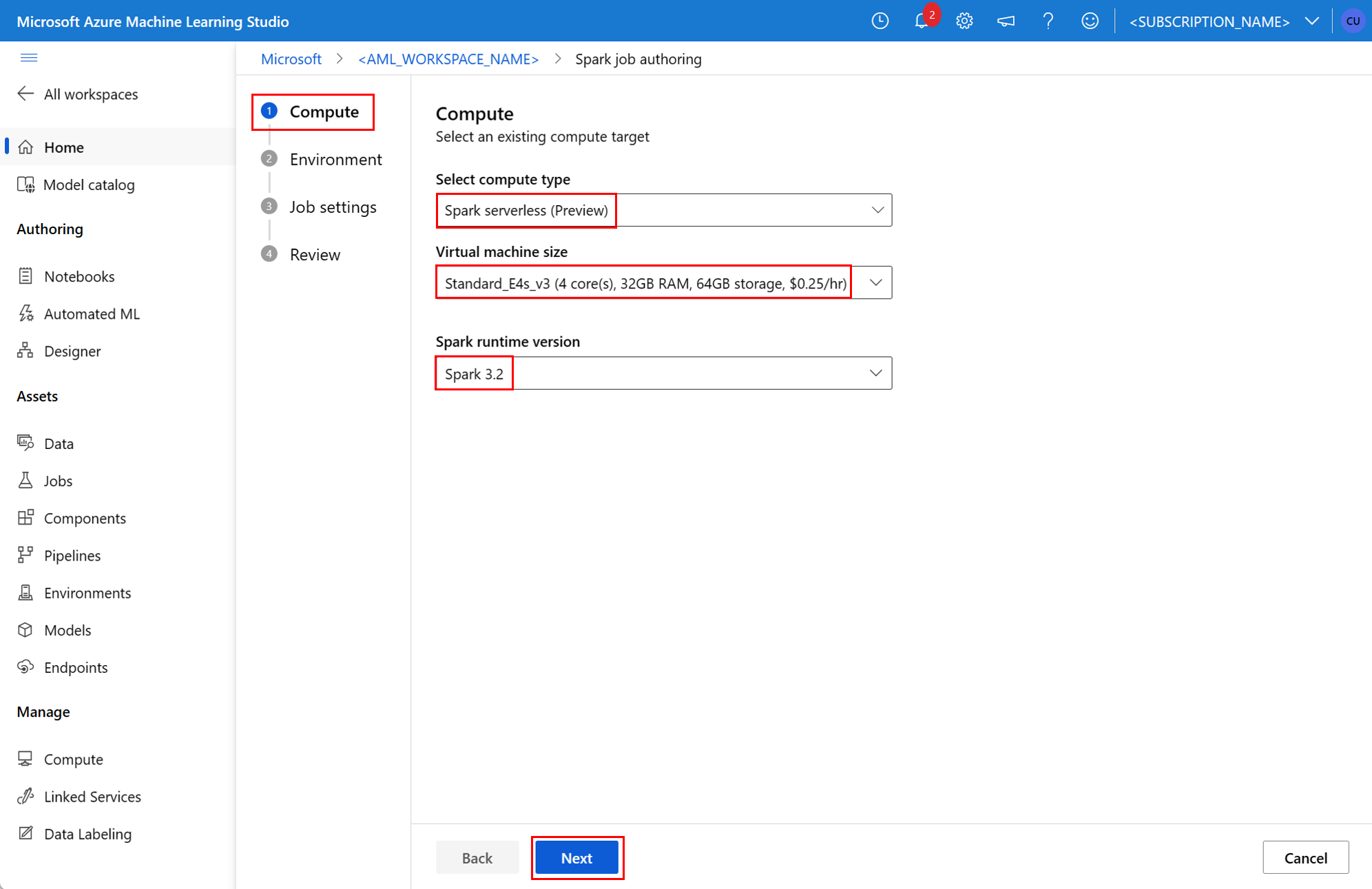
Componente de Spark en un trabajo de canalización
Un componente de Spark ofrece la flexibilidad de usar el mismo componente en varias canalizaciones de Azure Machine Learning como paso de canalización.
SE APLICA A: Extensión de ML de la CLI de Azure v2 (actual)
La sintaxis de YAML para un componente de Spark es similar a la sintaxis de YAML para la especificación del trabajo de Spark de la mayoría de las maneras. Estas propiedades se definen de forma diferente en la especificación YAML del componente spark:
name: el nombre del componente de Spark.version: la versión del componente de Spark.display_name: el nombre del componente de Spark que se va a mostrar en la interfaz de usuario y en otro lugar.description: descripción del componente de Spark.inputs: esta propiedad es similar a la propiedadinputsdescrita en sintaxis YAML para la especificación del trabajo de Spark, salvo que no define la propiedadpath. Este fragmento de código muestra un ejemplo de la propiedad del componenteinputsSpark:inputs: titanic_data: type: uri_file mode: directoutputs: esta propiedad es similar a la propiedadoutputsdescrita en sintaxis YAML para la especificación del trabajo de Spark, salvo que no define la propiedadpath. Este fragmento de código muestra un ejemplo de la propiedad del componenteoutputsSpark:outputs: wrangled_data: type: uri_folder mode: direct
Nota:
Un componente de Spark no define las propiedades identity, ni compute, ni resources. El archivo de especificación YAML de canalización define estas propiedades.
Este archivo de especificación YAML proporciona un ejemplo de un componente de Spark:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Puede usar el componente de Spark definido en el archivo de especificación YAML anterior en un trabajo de canalización de Azure Machine Learning. Visite el recurso de esquema YAML del trabajo de canalización para obtener más información sobre la sintaxis de YAML que define un trabajo de canalización. En este ejemplo se muestra un archivo de especificación YAML para un trabajo de canalización, con un componente de Spark y un proceso de Spark sin servidor de Azure Machine Learning:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Nota
Para usar un grupo de Synapse Spark asociado, defina la propiedad compute en el archivo de especificación YAML de ejemplo mostrado anteriormente en lugar de la propiedad resources.
Puede usar el archivo de especificación YAML anterior en el comando az ml job create, mediante el parámetro --file, para crear un trabajo de canalización como se muestra:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Puede ejecutar el comando anterior desde:
- el terminal de una instancia de proceso de Azure Machine Learning.
- el terminal de Visual Studio Code, conectado a una instancia de proceso de Azure Machine Learning.
- el equipo local que tiene instalada la CLI de Azure Machine Learning.
Solución de problemas de trabajos de Spark
Para solucionar problemas de un trabajo de Spark, puede acceder a los registros generados para ese trabajo en Estudio de Azure Machine Learning. Para ver los registros de un trabajo de Spark:
- Vaya a Trabajos desde el panel izquierdo en la interfaz de usuario de Estudio de Azure Machine Learning
- Seleccione la pestaña Todos los trabajos
- Seleccione el valor Nombre para mostrar del trabajo
- En la página de detalles del trabajo, seleccione la pestaña Salida y registros
- En el explorador de archivos, expanda la carpeta registros y, a continuación, expanda la carpeta azureml
- Acceda a los registros de trabajos de Spark dentro de las carpetas del controlador y del administrador de bibliotecas
Nota
Para solucionar problemas de trabajos de Spark creados durante la limpieza y transformación de datos interactivos en una sesión de cuaderno, seleccione Detalles del trabajo cerca de la esquina superior derecha de la interfaz de usuario del cuaderno. Se crea un trabajo de Spark desde una sesión interactiva de cuaderno bajo el nombre de experimentoejecuciones de cuaderno.