Asociación y administración de un grupo de Spark de Synapse en Azure Machine Learning
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
En este artículo, aprenderá a asociar un grupo de Spark de Synapse en Azure Machine Learning. Puede asociar un grupo de Spark de Synapse en Azure Machine Learning mediante una de estas formas:
- Uso de la interfaz de usuario de Estudio de Azure Machine Learning
- Uso de la CLI de Azure Machine Learning
- Uso del SDK de Azure Machine Learning para Python
Prerrequisitos
- Una suscripción a Azure: si aún no tiene ninguna, cree una cuenta gratuita antes de empezar.
- Un área de trabajo de Azure Machine Learning. Consulte Creación de recursos del área de trabajo.
- Cree un área de trabajo de Azure Synapse Analytics en Azure Portal.
- Creación de un grupo de Apache Spark mediante Azure Portal.
Asociación de un grupo de Spark de Synapse en Azure Machine Learning
Azure Machine Learning ofrece diferentes formas de asociar y administrar un grupo de Synapse Spark.
Para asociar un grupo de Spark de Synapse con la pestaña Proceso de Studio:

- En la sección Administrar del panel izquierdo, seleccione Proceso.
- Seleccione Procesos asociados.
- En la pantalla Procesos asociados, seleccione Nuevo para ver las opciones de asociación de diferentes tipos de proceso.
- Seleccione Grupo de Spark de Synapse.
El panel se abre en Grupo de Synapse Spark en el lado derecho de la pantalla. En este panel:
Escriba un Nombre, que hace referencia al grupo de Spark de Synapse asociado dentro del recurso de Azure Machine Learning.
Seleccione una suscripción de Azure en el menú desplegable.
Seleccione un área de trabajo de Synapse en la lista desplegable.
Seleccione un grupo de Spark en el menú desplegable.
Active la opción Asignar una identidad administrada para habilitarla.
Seleccione un tipo de identidad administrada que se usará con este grupo de Spark de Synapse asociado.
Seleccione Actualizar para completar el proceso de asociación del grupo de Spark de Synapse.
Incorporación de asignaciones de roles en Azure Synapse Analytics
Para asegurarse de que el grupo de Spark de Synapse asociado funciona correctamente, asígnele el Rol de administrador desde la interfaz de usuario de Azure Synapse Analytics Studio. En estos pasos se muestra cómo hacerlo:
Abra su Área de trabajo de Synapse en Azure Portal.
En el panel izquierdo, haga clic en Información general.
Consulte Abrir Synapse Studio.
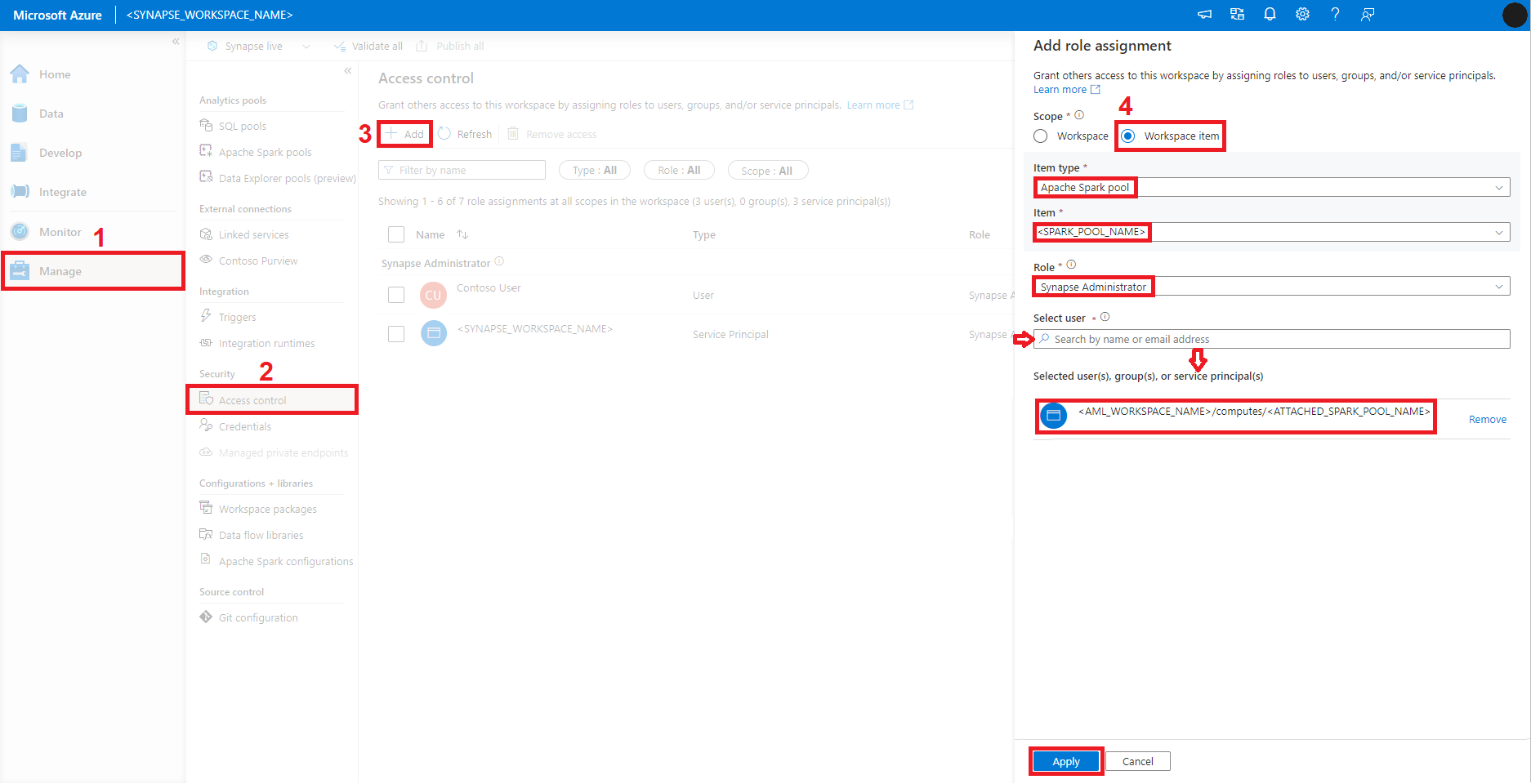
En Azure Synapse Analytics Studio, seleccione Administrar en el panel izquierdo.
Seleccione Access Control en la sección Seguridad del panel izquierdo, el segundo a partir de la izquierda.
Seleccione Agregar.
El panel Agregar asignación de roles se abrirá en el lado derecho de la pantalla. En este panel:
Seleccione Elemento de área de trabajo para Ámbito.
En el menú desplegable Tipo de elemento, seleccione Grupo de Apache Spark.
En el menú desplegable Elemento, seleccione el grupo de Apache Spark.
En el menú desplegable Rol, seleccione Administrador de Synapse.
En el cuadro de búsqueda Seleccionar usuario, comience a escribir el nombre del área de trabajo de Azure Machine Learning. Se muestra una lista de grupos de Spark de Synapse asociados. Seleccione el grupo de Spark de Synapse que desee de la lista.
Seleccione Aplicar.


Actualización del grupo de Spark de Synapse
Puede administrar el grupo de Spark de Synapse asociado desde la interfaz de usuario de Estudio de Azure Machine Learning. La funcionalidad de administración de grupos de Spark incluye actualizaciones de identidad administrada asociadas para un grupo de Spark de Synapse asociado. Puede asignar una identidad asignada por el sistema o una identidad asignada por el usuario al actualizar un grupo de Spark de Synapse. Debe crear una identidad administrada asignada por el usuario en Azure Portal, antes de asignarla a un grupo de Spark de Synapse.
Para actualizar la identidad administrada del grupo de Spark de Synapse asociado:

Abra la página Detalles del grupo de Spark de Synapse en Estudio de Azure Machine Learning.
Busque el icono de edición, que se encuentra en el lado derecho de la sección Identidad administrada.
Para asignar una identidad administrada por primera vez, active Asignar una identidad administrada para habilitarla.
Para asignar una identidad administrada asignada por el sistema:
- Seleccione Asignación del sistema como Tipo de identidad.
- Selecciona Actualización.
Para asignar una identidad administrada asignada por el usuario:
- Seleccione Asignación del usuario como Tipo de identidad.
- Seleccione una suscripción de Azure en el menú desplegable.
- Escriba las primeras letras del nombre de la identidad administrada asignada por el usuario en el cuadro que muestra el texto Buscar por nombre. Aparece una lista con nombres de identidad administrada asignados por el usuario coincidentes. Seleccione en la lista la identidad administrada asignada por el usuario que desee. Puede seleccionar varias identidades administradas asignadas por el usuario y asignarlas al grupo de Spark de Synapse asociado.
- Seleccione Actualizar.
Desasociación del grupo de Spark de Synapse
Es posible que quiera desasociar un grupo de Spark de Synapse asociado para limpiar un área de trabajo.
La interfaz de usuario de Estudio de Azure Machine Learning también proporciona una manera de desasociar un grupo de Spark de Synapse asociado. Para ello, siga estos pasos:
Abra la página Detalles del grupo de Spark de Synapse en Estudio de Azure Machine Learning.
Seleccione Desasociar para desasociar el grupo de Spark de Synapse asociado.
Proceso de Spark sin servidor en Azure Machine Learning
Algunos escenarios de usuario pueden requerir acceso a un recurso de proceso de Spark sin servidor, durante un envío de trabajo de Azure Machine Learning, sin necesidad de adjuntar un grupo de Spark. La integración de Azure Synapse Analytics con Azure Machine Learning también proporciona una experiencia de proceso de Spark sin servidor. Esto permite acceder a un proceso de Spark en un trabajo, sin necesidad de adjuntar primero el proceso a un área de trabajo. Obtenga más información sobre la experiencia de proceso de Spark sin servidor.