Tutorial: Crear canalizaciones de aprendizaje automático de producción
SE APLICA A:  SDK de Python azure-ai-ml v2 (actual)
SDK de Python azure-ai-ml v2 (actual)
Nota
Para ver un tutorial que usa SDK v1 para compilar una canalización, consulte Tutorial: Creación de una canalización de Azure Machine Learning para la clasificación de imágenes.
El núcleo de una canalización de aprendizaje automático consiste en dividir una tarea de aprendizaje automático completa en un flujo de trabajo de varios pasos. Cada paso es un componente administrable que se puede desarrollar, optimizar, configurar y automatizar individualmente. Los pasos se conectan a través de interfaces bien definidas. El servicio de canalización de Azure Machine Learning organiza automáticamente todas las dependencias entre los pasos de la canalización. Las ventajas de usar una canalización están estandarizadas con la práctica de MLOps, la colaboración en equipo escalable, la eficiencia del entrenamiento y la reducción de costos. Para más información sobre las ventajas de las canalizaciones, consulte Qué son las canalizaciones de Azure Machine Learning
En este tutorial, usa Azure Machine Learning para crear un proyecto de aprendizaje automático listo para producción mediante el SDK v2 de Python de Azure Machine Learning.
Esto significa que podrá aprovechar el SDK de Python de Azure Machine Learning para:
- Controle su área de trabajo de Azure Machine Learning
- Creación de recursos de datos de Azure Machine Learning
- Crear componentes reutilizables de Azure Machine Learning
- Crear, validar y ejecutar canalizaciones de Azure Machine Learning
Durante este tutorial, crea una canalización de Azure Machine Learning para entrenar un modelo para la predicción predeterminada del crédito. La canalización controla dos pasos:
- Preparación de los datos
- Entrenamiento y registro del modelo entrenado
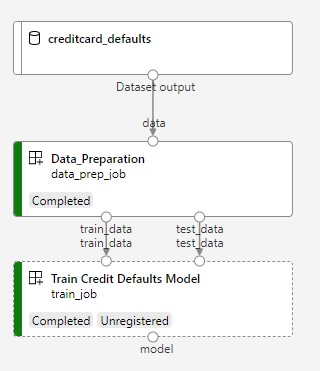
La imagen siguiente muestra una canalización simple que verá en el studio de Azure una vez la introduzca.
Los dos pasos son la preparación de datos y el segundo entrenamiento.
En este vídeo se muestra cómo empezar a trabajar en el estudio de Azure Machine Learning para que pueda seguir los pasos del tutorial. El vídeo muestra cómo crear un cuaderno, crear una instancia de proceso y clonar el cuaderno. Estos pasos también se describen en las secciones siguientes.
Requisitos previos
-
Para usar Azure Machine Learning, necesita un área de trabajo. Si no tiene una, complete Crear recursos necesarios para empezar para crear un área de trabajo y obtener más información sobre su uso.
Importante
Si el área de trabajo de Azure Machine Learning está configurada con una red virtual administrada, es posible que tenga que agregar reglas de salida para permitir el acceso a los repositorios de paquetes de Python públicos. Para más información, vea Escenario: Acceso a paquetes de aprendizaje automático públicos.
-
Inicie sesión en Studio y seleccione el área de trabajo si aún no está abierta.
Complete el tutorial Carga, acceso y exploración de datos para crear el recurso de datos que necesita en este tutorial. Asegúrese de ejecutar todo el código para crear el recurso de datos iniciales. Explore los datos y revíselos si lo desea, pero solo necesitará los datos iniciales en este tutorial.
-
Abra o cree una libreta en el área de trabajo:
- Si desea copiar y pegar código en celdas, cree un cuaderno nuevo.
- O, abra tutorials/get-started-notebooks/pipeline.ipynb desde la sección Ejemplos de Studio. A continuación, seleccione Clonar para agregar el cuaderno a sus Archivos. Para encontrar cuadernos de ejemplo, consulte Aprender con cuadernos de ejemplo.
Establecer el kernel y abrirlo en Visual Studio Code (VS Code)
En la barra superior del cuaderno abierto, cree una instancia de proceso si aún no tiene una.

Si la instancia de proceso se detiene, seleccione Iniciar proceso y espere hasta que se ejecute.

Espere hasta que la instancia de cálculo esté en ejecución. A continuación, asegúrese de que el kernel, que se encuentra en la parte superior derecha, es
Python 3.10 - SDK v2. Si no es así, use la lista desplegable para seleccionar este kernel.
Si no ve este kernel, compruebe que la instancia de proceso se está ejecutando. Si es así, seleccione el botón Actualizar situado en la parte superior derecha del cuaderno.
Si ves un banner que dice que debes autenticarte, selecciona Autenticar.
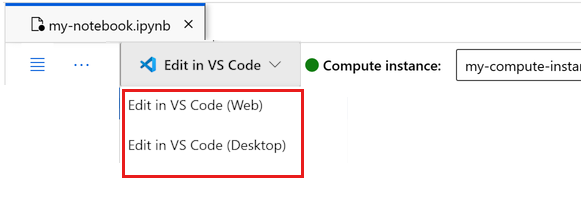
Puede ejecutar el cuaderno aquí o abrirlo en VS Code para un entorno de desarrollo integrado (IDE) completo con la eficacia de los recursos de Azure Machine Learning. Seleccione Abrir en VS Codey, a continuación, seleccione la opción web o de escritorio. Cuando se inicia de esta manera, VS Code se adjunta a la instancia de proceso, el kernel y el sistema de archivos del área de trabajo.




Importante
El resto de este tutorial contiene celdas del cuaderno del tutorial. Cópielos y péguelos en su nuevo cuaderno, o cambie al cuaderno actual si lo ha clonado.
Configuración de los recursos de la canalización
El marco de trabajo de Azure Machine Learning se puede usar desde la CLI, el SDK de Python o la interfaz de Estudio. En este ejemplo, usa el SDK v2 de Python de Azure Machine Learning para crear una canalización.
Antes de crear la canalización, necesita los siguientes recursos:
- El recurso de datos para el entrenamiento
- El entorno de software para ejecutar la canalización
- Un recurso de proceso en el que ejecuta el trabajo
Creación de un manipulador para el área de trabajo
Antes de profundizar en el código, necesita una manera de hacer referencia a su área de trabajo. Creará ml_client para un manipulador para el área de trabajo. A continuación, use ml_client para administrar los recursos y puestos de trabajo.
En la celda siguiente, escriba el identificador de suscripción, el nombre del grupo de recursos y el nombre del área de trabajo. Para establecer estos valores:
- En la barra de herramientas de Estudio de Azure Machine Learning superior derecha, seleccione el nombre del área de trabajo.
- Copie el valor del área de trabajo, el grupo de recursos y el identificador de suscripción en el código.
- Tendrá que copiar un valor, cerrar el área y pegar y, a continuación, volver para el siguiente.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Nota
La creación de MLClient no se conectará al área de trabajo. La inicialización del cliente es lenta, esperará a la primera vez que necesite hacer una llamada (esto ocurrirá en la siguiente celda de código).
Para comprobar la conexión, realice una llamada a ml_client. Puesto que esta es la primera vez que realiza una llamada al área de trabajo, se le pedirá que se autentique.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Acceso al recurso de datos registrados
Para empezar, obtenga los datos que ha registrado antes en Tutorial: Carga, acceso y exploración de los datos en Azure Machine Learning.
- Azure Machine Learning usa un objeto
Datapara registrar una definición reutilizable de datos y consumir datos dentro de una canalización.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
Creación de un entorno de trabajo para los pasos de canalización
Hasta ahora, ha creado un entorno de desarrollo en la instancia de proceso, la máquina de desarrollo. También necesita un entorno para cada paso de la canalización. Cada paso puede tener su propio entorno, o puede usar algunos entornos comunes para varios pasos.
En este ejemplo, crea un entorno de Conda para los trabajos mediante un archivo yaml de Conda. En primer lugar, cree un directorio en el que almacenar el archivo.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Ahora, cree el archivo en el directorio de dependencias.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
La especificación contiene algunos paquetes habituales, que usa en la canalización (numpy y pip), junto con algunos paquetes específicos de Azure Machine Learning (azureml-mlflow).
Los paquetes de Azure Machine Learning no son obligatorios para ejecutar trabajos de Azure Machine Learning. Sin embargo, agregar estos paquetes le permite interactuar con Azure Machine Learning para registrar métricas y modelos, todo dentro del trabajo de Azure Machine Learning. Los usa en el script de entrenamiento más adelante en este tutorial.
Use el archivo yaml para crear y registrar este entorno personalizado en el área de trabajo:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
Compilación de la canalización de entrenamiento
Ahora que tiene todos los recursos necesarios para ejecutar la canalización, es el momento de compilar la propia canalización.
Las canalizaciones de Azure Machine Learning son flujos de trabajo de ML reutilizables que normalmente constan de varios componentes. La vida típica de un componente es:
- Escriba la especificación yaml del componente o créela mediante programación con
ComponentMethod. - Opcionalmente, registre el componente con un nombre y una versión en el área de trabajo para que se pueda reutilizar y compartir.
- Cargue ese componente desde el código de la canalización.
- Implementación de la canalización mediante las entradas, las salidas y los parámetros del componente.
- Envíe la canalización.
Hay dos maneras de crear un componente, una definición mediante programación y yaml. Las dos secciones siguientes le guiarán por la creación de un componente de ambas maneras. Puede crear los dos componentes que prueban ambas opciones o elegir su método preferido.
Nota
En este tutorial para simplificar, usamos el mismo proceso para todos los componentes. Sin embargo, puede establecer diferentes procesos para cada componente, por ejemplo agregando una línea como train_step.compute = "cpu-cluster". Para ver un ejemplo de creación de una canalización con diferentes procesos para cada componente, consulte la sección Trabajo de canalización básica del tutorial de canalización cifar-10.
Creación del componente 1: preparación de datos (mediante definición de programación)
Comencemos creando el primer componente. Este componente controla el preprocesamiento de los datos. La tarea de preprocesamiento se realiza en el archivo de Python data_prep.py.
En primer lugar, cree una carpeta de origen para el componente data_prep:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Este script realiza la tarea sencilla de dividir los datos en conjuntos de datos de entrenamiento y prueba. Azure Machine Learning monta conjuntos de datos como carpetas en los procesos; por lo tanto, creamos una función auxiliar select_first_file para acceder al archivo de datos dentro de la carpeta de entrada montada.
MLFlow se usa para registrar los parámetros y las métricas durante la ejecución de la canalización.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Ahora que tiene un script que puede realizar la tarea deseada, cree un componente de Azure Machine Learning a partir de él.
Use el CommandComponent de uso general que puede ejecutar acciones de línea de comandos. Esta acción de línea de comandos puede llamar directamente a comandos del sistema o ejecutar un script. Las entradas y salidas se especifican en la línea de comandos a través de la notación ${{ ... }}.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
Opcionalmente, registre el componente en el área de trabajo para volver a usarlo en el futuro.
# Now we register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create (register) the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
Creación del componente 2: entrenamiento (mediante la definición de yaml)
El segundo componente que cree consume los datos de entrenamiento y prueba, entrena un modelo basado en árbol y devuelve el modelo de salida. Use las funcionalidades de registro de Azure Machine Learning para registrar y visualizar el progreso del aprendizaje.
Ha usado la clase CommandComponent para crear el primer componente. Esta vez use la definición de yaml para definir el segundo componente. Cada método tiene sus propias ventajas. Una definición de yaml se puede comprobar realmente a lo largo del código y proporcionaría un seguimiento del historial legible. El método mediante programación con CommandComponent puede ser más fácil con la documentación de clase integrada y la finalización del código.
Cree el directorio para este componente:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Cree el script de entrenamiento en el directorio :
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Como puede ver en este script de entrenamiento, una vez entrenado el modelo, el archivo del modelo se guarda y registra en el área de trabajo. Ahora puede usar el modelo registrado en puntos de conexión de inferencia.
Para el entorno de este paso, use uno de los entornos integrados (mantenidos) de Azure Machine Learning. La etiqueta azureml indica al sistema que use la búsqueda del nombre en entornos mantenidos.
En primer lugar, cree el archivo yaml que describe el componente:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Ahora cree y registre el componente. Registrarlo le permite volver a usarlo en otras canalizaciones. Además, cualquier otra persona con acceso al área de trabajo puede usar el componente registrado.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now we register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create (register) the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
Creación de la canalización a partir de componentes
Ahora que ambos componentes están definidos y registrados, puede empezar a implementar la canalización.
Aquí, usa los datos de entrada, la proporción de división y el nombre del modelo registrado como variables de entrada. A continuación, llame a los componentes y conéctelos a través de sus identificadores de entradas y salidas. Se puede acceder a las salidas de cada paso a través de la propiedad .outputs.
Las funciones de Python devueltas por load_component() funcionan como cualquier función normal de Python que usamos dentro de una canalización para llamar a cada paso.
Para codificar la canalización, use un decorador específico @dsl.pipeline que identifique las canalizaciones de Azure Machine Learning. En el decorador, podemos especificar la descripción de la canalización y los recursos predeterminados, como proceso y almacenamiento. Al igual que una función de Python, las canalizaciones pueden tener entradas. Después, puede crear varias instancias de una sola canalización con diferentes entradas.
Aquí, usamos los datos de entrada, la proporción de división y el nombre del modelo registrado como variables de entrada. A continuación, llamamos a los componentes y los conectamos a través de sus identificadores de entradas y salidas. Se puede acceder a las salidas de cada paso a través de la propiedad .outputs.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
Ahora, use la definición de canalización para crear una instancia de una canalización con el conjunto de datos, dividir la velocidad de elección y el nombre que ha elegido para el modelo.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
Enviar el archivo
Ahora es el momento de enviar el trabajo para que se ejecute en Azure Machine Learning. Esta vez se usa create_or_update en ml_client.jobs.
Aquí también pasa un nombre de experimento. Un experimento es un contenedor para todas las iteraciones que se hacen en un proyecto determinado. Todos los trabajos enviados en el mismo nombre de experimento se enumerarán de manera correlativa en Estudio de Azure Machine Learning.
Una vez completada, la canalización registra un modelo en el área de trabajo como resultado del entrenamiento.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
Puede realizar un seguimiento del progreso de la canalización mediante el vínculo generado en la celda anterior. Al seleccionar este vínculo por primera vez, es posible que vea que la canalización todavía se está ejecutando. Una vez completado, puede examinar los resultados de cada componente.
Haga doble clic en el componente Train Credit Defaults Model (Entrenar modelo predeterminado de crédito).
Hay dos resultados importantes que querrá ver sobre el entrenamiento:
Ver los registros:
- Seleccione la pestaña Outputs + logs (Resultados y registros).
- Abra las carpetas en
user_logs>std_log.txtEsta sección muestra el script run stdout.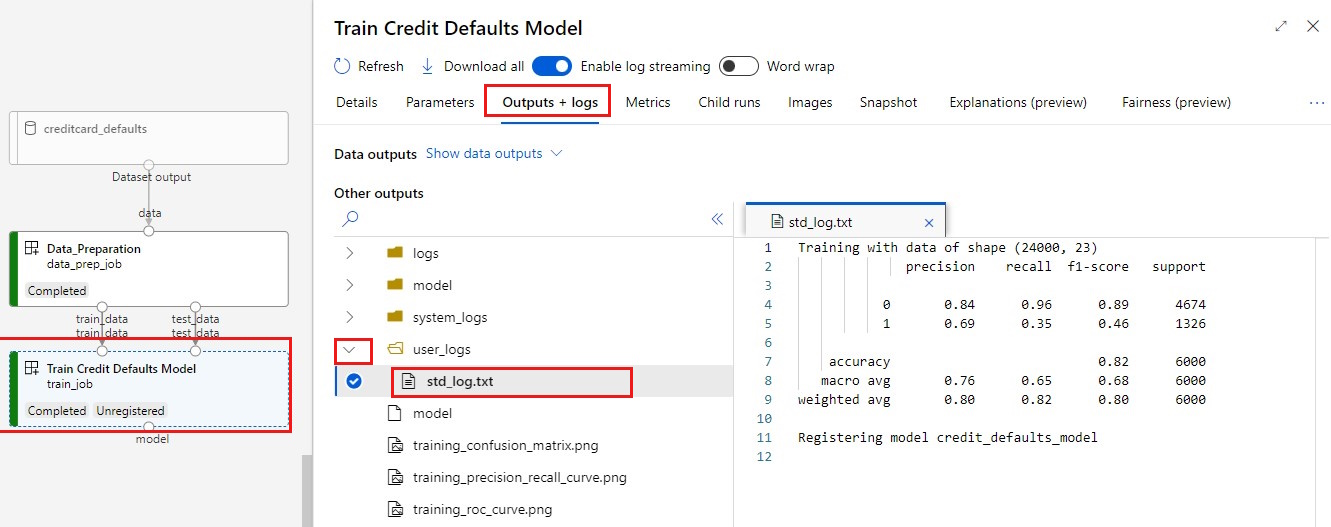
Ver las métricas: seleccione la pestaña Métricas. En esta sección se muestran diferentes métricas registradas. En este ejemplo, mlflow
autologging, ha registrado automáticamente las métricas de entrenamiento.


Implementación del modelo como un punto de conexión en línea
Para obtener información sobre cómo implementar el modelo en un punto de conexión en línea, consulte Tutorial sobre implementación de un modelo como punto de conexión en línea.
Limpieza de recursos
Si quiere continuar con otros tutoriales, ve a Pasos siguientes.
Detención de una instancia de proceso
Si no va a utilizar ahora la instancia de proceso, deténgala:
- En el estudio, en el área de navegación de la izquierda, seleccione Proceso.
- En las pestañas superiores, seleccione Instancia de proceso.
- Seleccione la instancia de proceso en la lista.
- En la barra de herramientas superior, seleccione Detener.
Eliminación de todos los recursos
Importante
Los recursos que creó pueden usarse como requisitos previos para otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Si no va a usar ninguno de los recursos que ha creado, elimínelos para no incurrir en cargos:
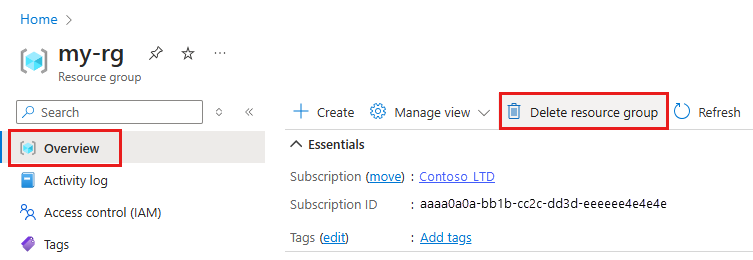
En Azure Portal, en el cuadro de búsqueda, escriba Grupos de recursos y selecciónelo en los resultados.
En la lista, seleccione el grupo de recursos que creó.
En la página Información general, seleccione Eliminar grupo de recursos.
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.