Depuración de aplicaciones de Apache Spark en un clúster de HDInsight con Azure Toolkit for IntelliJ mediante SSH
En este artículo se ofrecen instrucciones paso a paso para el empleo de las herramientas de HDInsight de Azure Toolkit for IntelliJ para depurar aplicaciones de forma remota en un clúster de HDInsight.
Requisitos previos
Un clúster de Apache Spark en HDInsight. Vea Creación de un clúster de Apache Spark.
Para usuarios de Windows: Mientras se ejecuta la aplicación Spark en Scala local en un equipo Windows, puede producirse una excepción, como se explica en SPARK-2356. Esta excepción se produce porque falta WinUtils.exe en Windows.
Para solucionar este error, descargue Winutils.exe en una ubicación como C:\WinUtils\bin. Después, agregue una variable de entorno HADOOP_HOME y establezca el valor de la variable en C:\WinUtils.
IntelliJ IDEA (la edición Community es gratuita).
Un cliente SSH. Para más información, consulte Conexión a través de SSH con HDInsight (Apache Hadoop).
Creación de una aplicación de Scala en Spark
Inicie IntelliJ IDEA y seleccione Create New Project (Crear proyecto) para abrir la ventana New Project (Nuevo proyecto).
Seleccione Azure Spark/HDInsight en el panel izquierdo.
Seleccione Spark Project with Samples (Scala) (Proyecto de Spark con ejemplos [Scala]) en la ventana principal.
En la lista desplegable Build tool (Herramienta de compilación), seleccione una de las siguientes:
- Maven: para agregar compatibilidad con el asistente para la creación de proyectos de Scala.
- SBT para administrar las dependencias y compilar el proyecto de Scala.
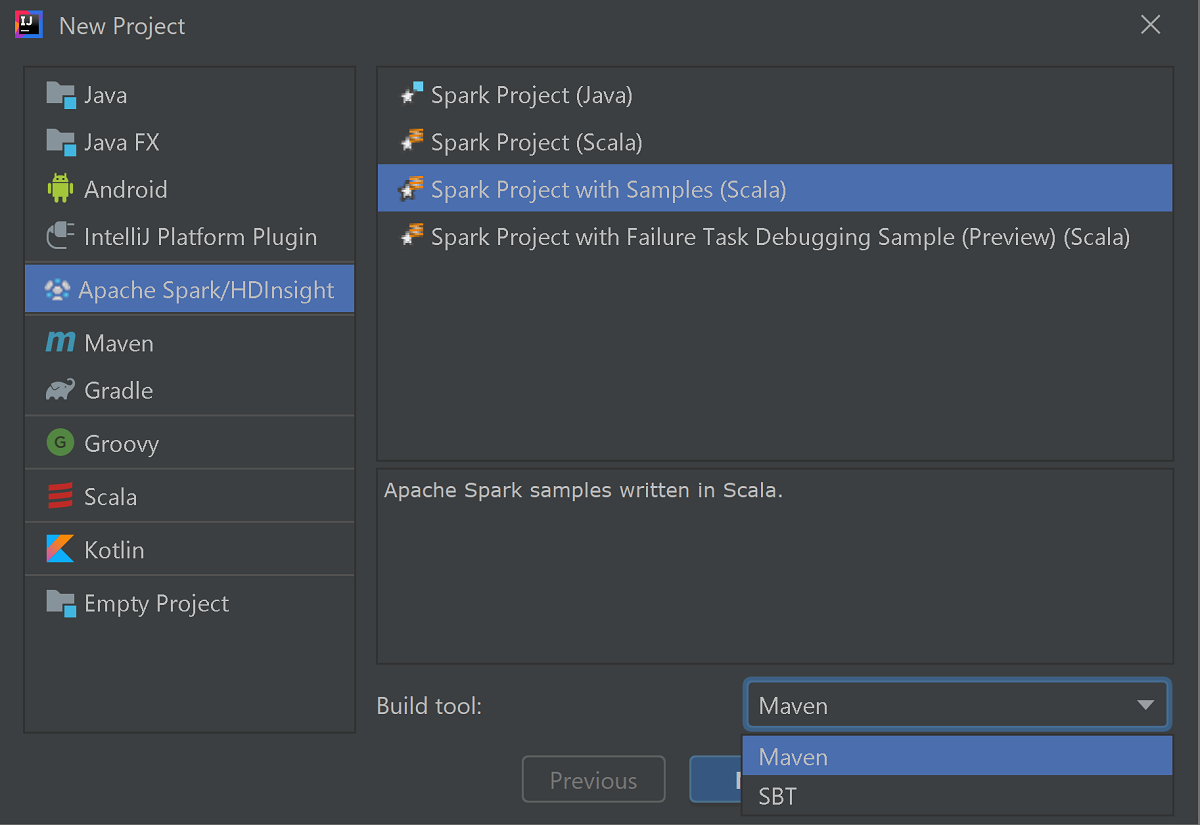
Seleccione Siguiente.
En la siguiente ventana New Project (Nuevo proyecto), proporcione la siguiente información:
Propiedad Descripción Nombre de proyecto Escriba un nombre. Este tutorial usa myApp.Ubicación del proyecto Escriba la ubicación deseada para guardar el proyecto. Project SDK (SDK del proyecto) Si está en blanco, seleccione New... (Nuevo...) y vaya a su JDK. Versión de Spark El asistente de creación integra la versión adecuada de los SDK de Spark y Scala. Si la versión del clúster de Spark es anterior a 2.0, seleccione Spark 1.x. De lo contrario, seleccione Spark 2.x. En este ejemplo se usa Spark 2.3.0 (Scala 2.11.8) . 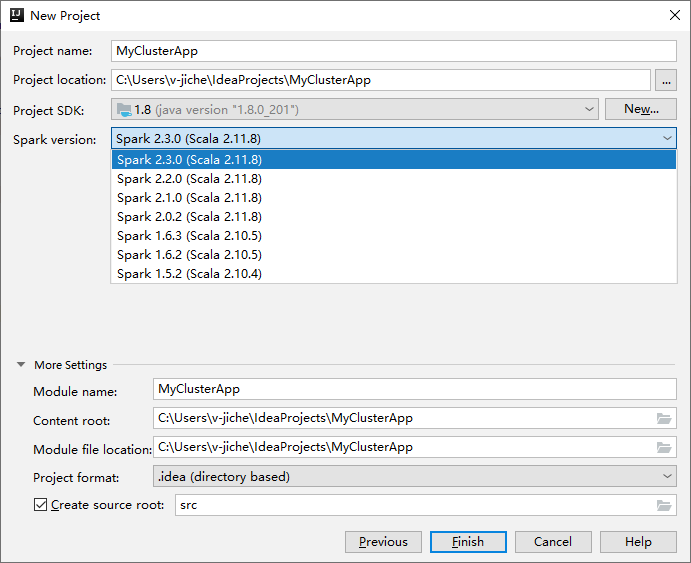
Seleccione Finalizar. El proyecto puede tardar unos minutos en estar disponible. Fíjese en la esquina inferior derecha para ver el progreso.
Expanda el proyecto y vaya a src>main>scala>sample. Haga doble clic en SparkCore_WasbIOTest.
Realizar una ejecución local
En el script SparkCore_WasbIOTest, haga clic con el botón derecho en el editor de scripts y luego seleccione la opción Run “SparkCore_WasbIOTest” (Ejecutar “SparkCore_WasbIOTest”) para realizar la ejecución local.
Una vez completada la ejecución local, puede ver el archivo de salida guardado en el Explorador de proyectos actual datos>default .
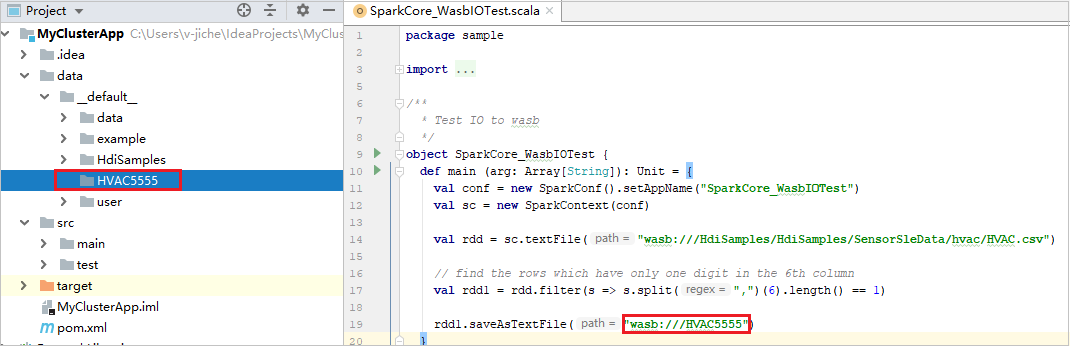
Nuestras herramientas han establecido automáticamente la configuración de la ejecución local predeterminada al realizar la ejecución local y la depuración local. Abra el XXX [Spark en HDInsight] de configuración en la esquina superior derecha; verá que ya se ha creado el XXX [Spark en HDInsight] en Apache Spark on HDInsight (Apache Spark en HDInsight). Cambie a la pestaña Ejecutar localmente.
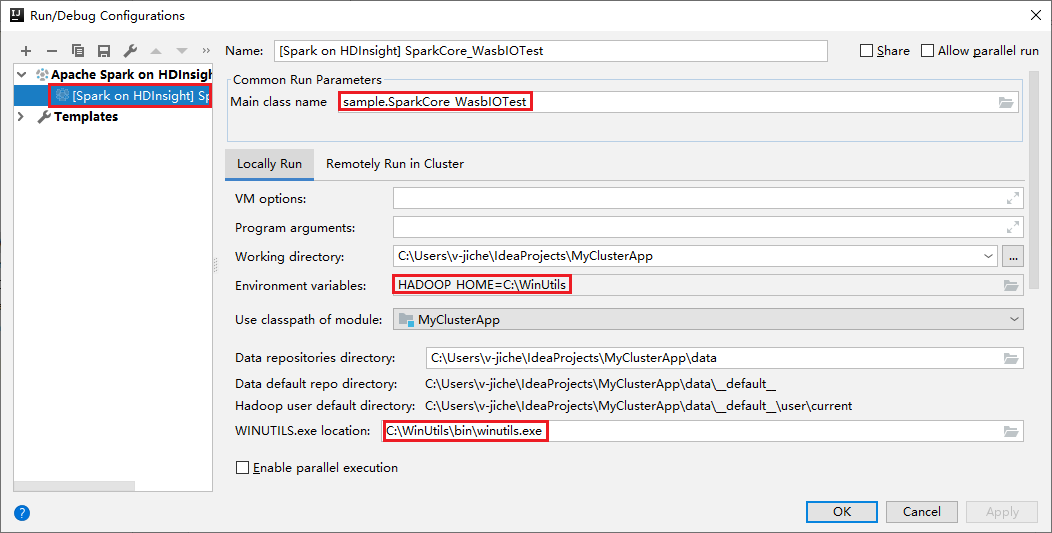
- Variables de entorno: si ya ha establecido la variable de entorno del sistema HADOOP_HOME en C:\WinUtils, detecta automáticamente que no es necesario agregarla manualmente.
- Ubicación de WinUtils.exe: si no se ha establecido la variable de entorno del sistema, haga clic en el botón correspondiente para encontrar la ubicación.
- Solo tiene que elegir cualquiera de las dos opciones. No se necesitan en MacOS y Linux.
También puede establecer la configuración manualmente antes de realizar la depuración local y la ejecución local. En la captura de pantalla anterior, seleccione el signo más ( + ). Después, seleccione la opción Apache Spark on HDInsight (Apache Spark en HDInsight). Escriba la información en Name (Nombre), Main class name (Nombre de clase principal) y haga clic en el botón de ejecución local.
Realizar una depuración local
Abra el script SparkCore_wasbloTest y establezca los puntos de interrupción.
Haga clic con el botón derecho en el editor de scripts y seleccione la opción Debug '[Spark Job]XXX' (Depurar "[Trabajo de Spark]XXX") para realizar la depuración local.
Realizar la ejecución remota
Seleccione Ejecutar>Editar configuraciones... . Desde este menú, puede crear o modificar las configuraciones para la depuración remota.
En el cuadro de diálogo Run/Debug Configurations (Ejecutar/depurar configuraciones), seleccione el signo más ( + ). Después, seleccione la opción Apache Spark on HDInsight (Apache Spark en HDInsight).
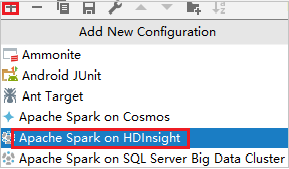
Cambie a la pestaña Remotely Run in Cluster (Ejecutar de forma remota en clúster). Escriba la información en los campos Name (Nombre), Spark cluster (Clúster de Spark) y Main class name (Nombre de clase principal). A continuación, haga clic en Advanced configuration (Remote Debugging) (Configuración avanzada [depuración remota]). Nuestras herramientas admiten la depuración con ejecutores. Parámetro numExecutors, el valor predeterminado es 5. Es mejor no establecer más de 3.
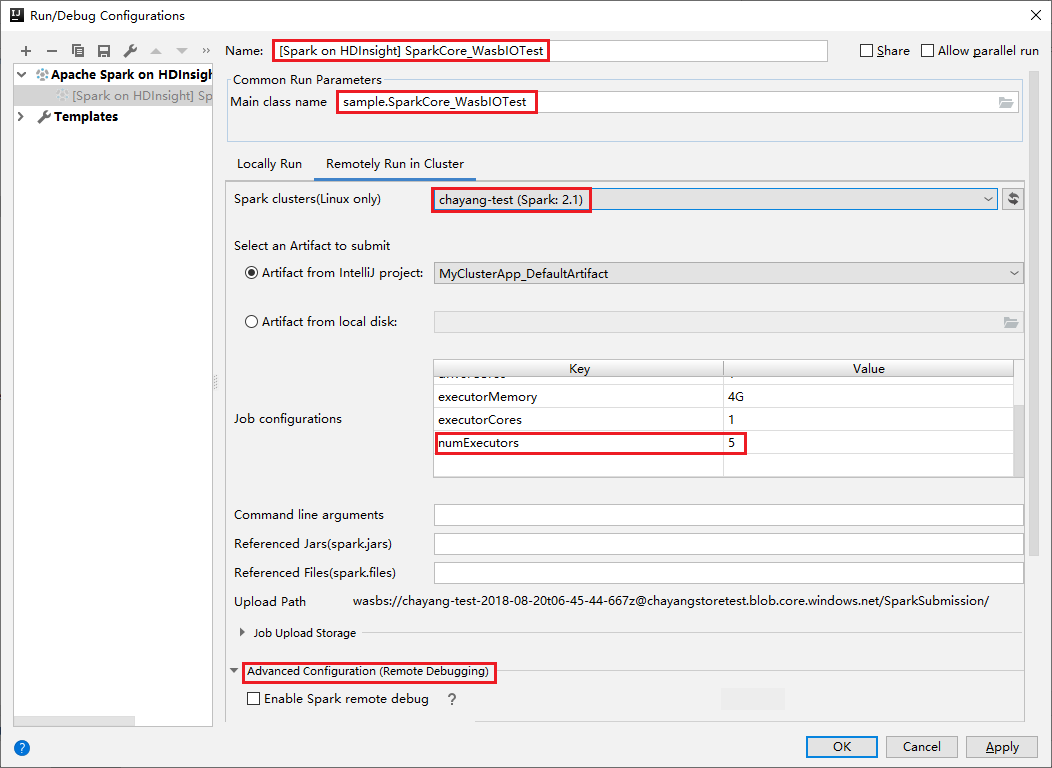
En la parte Advanced Configuration (Remote Debugging) (Configuración avanzada [depuración remota]), seleccione Enable Spark remote debug (Habilitar la depuración remota de Spark). Escriba el nombre de usuario SSH y luego especifique una contraseña o use un archivo de clave privada. Si desea realizar la depuración remota, debe establecerla. No es necesario establecerla si solo desea usar la ejecución remota.
La configuración se guarda ahora con el nombre especificado. Para ver los detalles de configuración, seleccione el nombre de configuración. Para realizar cambios, seleccione Edit Configurations (Editar configuraciones).
Después de completar la configuración, puede ejecutar el proyecto en el clúster remoto o realizar la depuración remota.

Haga clic en el botón Desconectar si los registros de envío no aparecen en el panel izquierdo. Sin embargo, continúa en ejecución en el back-end.
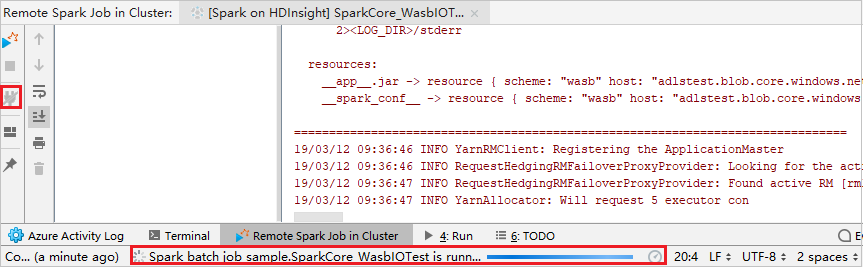
Realizar una depuración remota
Configure los puntos de interrupción y luego seleccione el icono Remote debug (Depuración remota). La diferencia con el envío remoto es que hay que configurar el nombre de usuario y la contraseña de SSH.

Cuando la ejecución del programa alcanza el punto de interrupción, aparecen una pestaña Controlador y dos pestañas Ejecutor en el panel Depurador. Seleccione el icono Resume Program (Continuar programa) para seguir ejecutando el código, que luego alcanza el siguiente punto de interrupción. Debe cambiar a la pestaña Executor (Ejecutor) correcta para buscar el ejecutor de destino que se va a depurar. Puede ver los registros de ejecución en la pestaña Console (Consola) correspondiente.
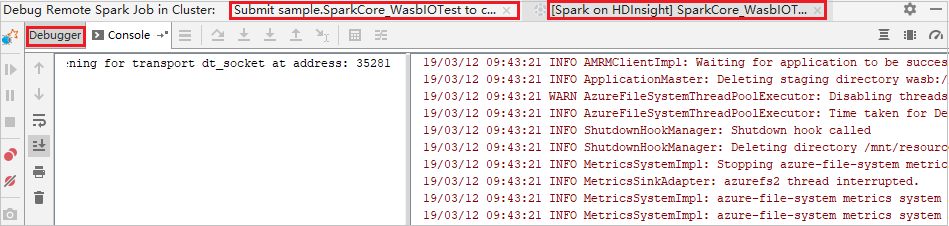
Realizar la depuración remota y la corrección de errores
Configure dos puntos de interrupción y luego seleccione el icono Depurar para iniciar el proceso de depuración remota.
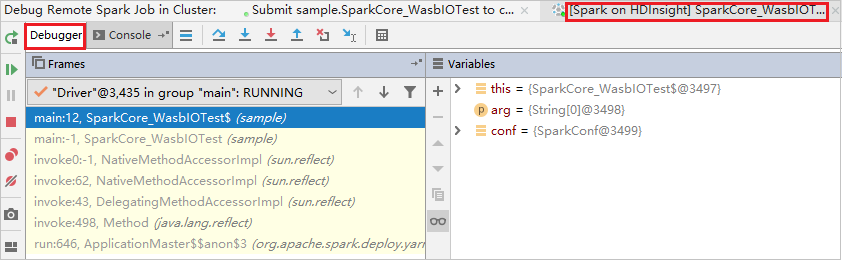
El código se detiene en el primer punto de interrupción y se muestra la información de parámetros y variables en el panel Variables.
Seleccione el icono Resume Program (Continuar programa) para continuar. El código se detiene en el segundo punto. La excepción se detecta según lo previsto.
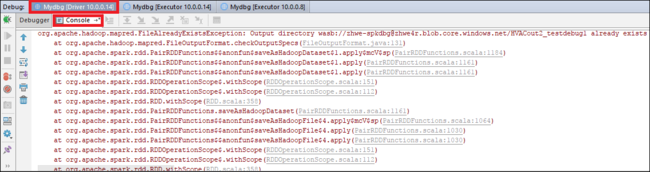
Vuelva a seleccionar el icono Resume Program (Continuar programa). La ventana HDInsight Spark Subsmission (Envío de HDInsight Spark) muestra un error de ejecución de trabajo.
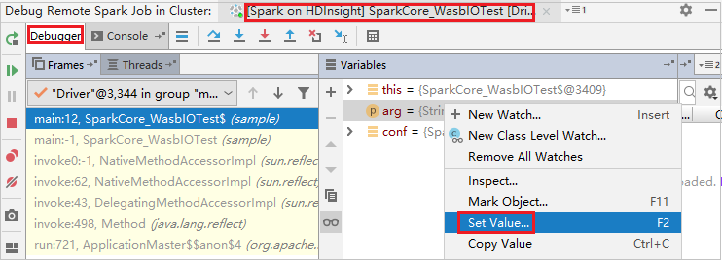
Para actualizar de forma dinámica el valor de variable mediante la funcionalidad de depuración de IntelliJ, vuelva a seleccionar Depurar. El panel Variables aparece de nuevo.
Haga clic con el botón derecho en el destino en el pestaña Depurar y, a continuación, seleccione Establecer valor. Luego escriba un nuevo valor para la variable. A continuación, seleccione Entrar para guardar el valor.
Seleccione el icono Resume Program (Continuar programa) para seguir ejecutando el programa. Esta vez no se detecta ninguna excepción. Puede ver que el proyecto se ejecuta correctamente sin ninguna excepción.
Pasos siguientes
Escenarios
- Apache Spark con BI: Análisis de datos interactivos con Spark en HDInsight con las herramientas de BI
- Apache Spark con Machine Learning: uso de Apache Spark en HDInsight para analizar la temperatura de edificios con los datos del sistema de acondicionamiento de aire
- Apache Spark con Machine Learning: uso de Spark en HDInsight para predecir los resultados de la inspección de alimentos
- Análisis de registros de un sitio web mediante Apache Spark en HDInsight
Creación y ejecución de aplicaciones
- Crear una aplicación independiente con Scala
- Ejecución de trabajos de forma remota en un clúster de Apache Spark mediante Apache Livy
Herramientas y extensiones
- Uso de Azure Toolkit for IntelliJ con el fin de crear aplicaciones Apache Spark para un clúster de HDInsight
- Uso de Azure Toolkit for IntelliJ para depurar de forma remota aplicaciones de Apache Spark mediante VPN
- Uso de las herramientas de HDInsight de Azure Toolkit for Eclipse con el fin de crear aplicaciones Apache Spark
- Uso de cuadernos de Apache Zeppelin con un clúster de Apache Spark en HDInsight
- Kernels para Jupyter Notebook en clústeres Azure Spark en Azure HDInsight
- Uso de paquetes externos con cuadernos de Jupyter Notebook
- Instalación de un cuaderno de Jupyter Notebook en el equipo y conexión al clúster de Apache Spark en HDInsight de Azure