Tutorial: Creación de una aplicación de Scala Maven para Apache Spark en HDInsight mediante IntelliJ
En este tutorial aprenderá a crear una aplicación de Apache Spark escrita en Scala mediante Apache Maven con IntelliJ IDEA. En el artículo se usa Apache Maven como sistema de compilación y comienza con un arquetipo existente de Maven para Scala proporcionado por IntelliJ IDEA. Crear una aplicación de Scala en IntelliJ IDEA conlleva los pasos siguientes:
- Use Maven como el sistema de compilación.
- Actualice el archivo del modelo de objetos de proyectos (POM) para resolver las dependencias de módulo de Spark.
- Escriba la aplicación con Scala.
- Genere un archivo jar que se pueda enviar a los clústeres de HDInsight Spark.
- Ejecute la aplicación en un clúster Spark mediante Livy.
En este tutorial, aprenderá a:
- Instale el complemento de Scala para IntelliJ IDEA.
- Usar IntelliJ para desarrollar una aplicación de Scala Maven
- Creación de un proyecto de Scala independiente
Prerrequisitos
Un clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure.
Kit de desarrollo de Oracle Java. En este tutorial se usa la versión 8.0.202 de Java.
Un IDE de Java. En este artículo se usa IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Consulte Instalación de Azure Toolkit for IntelliJ.
Instale el complemento de Scala para IntelliJ IDEA.
Para instalar el complemento Scala, siga estos pasos:
Abra IntelliJ IDEA.
En la pantalla de bienvenida, vaya a Configure>Plugins (Configurar > Complementos) para abrir la ventana Plugins (Complementos).
Seleccione Instalar para Azure Toolkit for IntelliJ.
Seleccione Install (Instalar) para el complemento de Scala que se presenta en la nueva ventana.
Después de que el complemento se instale correctamente, debe reiniciar el IDE.
Uso de IntelliJ para crear la aplicación
Inicie IntelliJ IDEA y seleccione Create New Project (Crear proyecto) para abrir la ventana New Project (Nuevo proyecto).
Seleccione Azure Spark/HDInsight en el panel izquierdo.
Seleccione Spark Project (Scala) (Proyecto de Spark [Scala]) en la ventana principal.
En la lista desplegable Build tool (Herramienta de compilación), seleccione uno de los valores siguientes:
- Maven: para agregar compatibilidad con el asistente para la creación de proyectos de Scala.
- SBT para administrar las dependencias y compilar el proyecto de Scala.
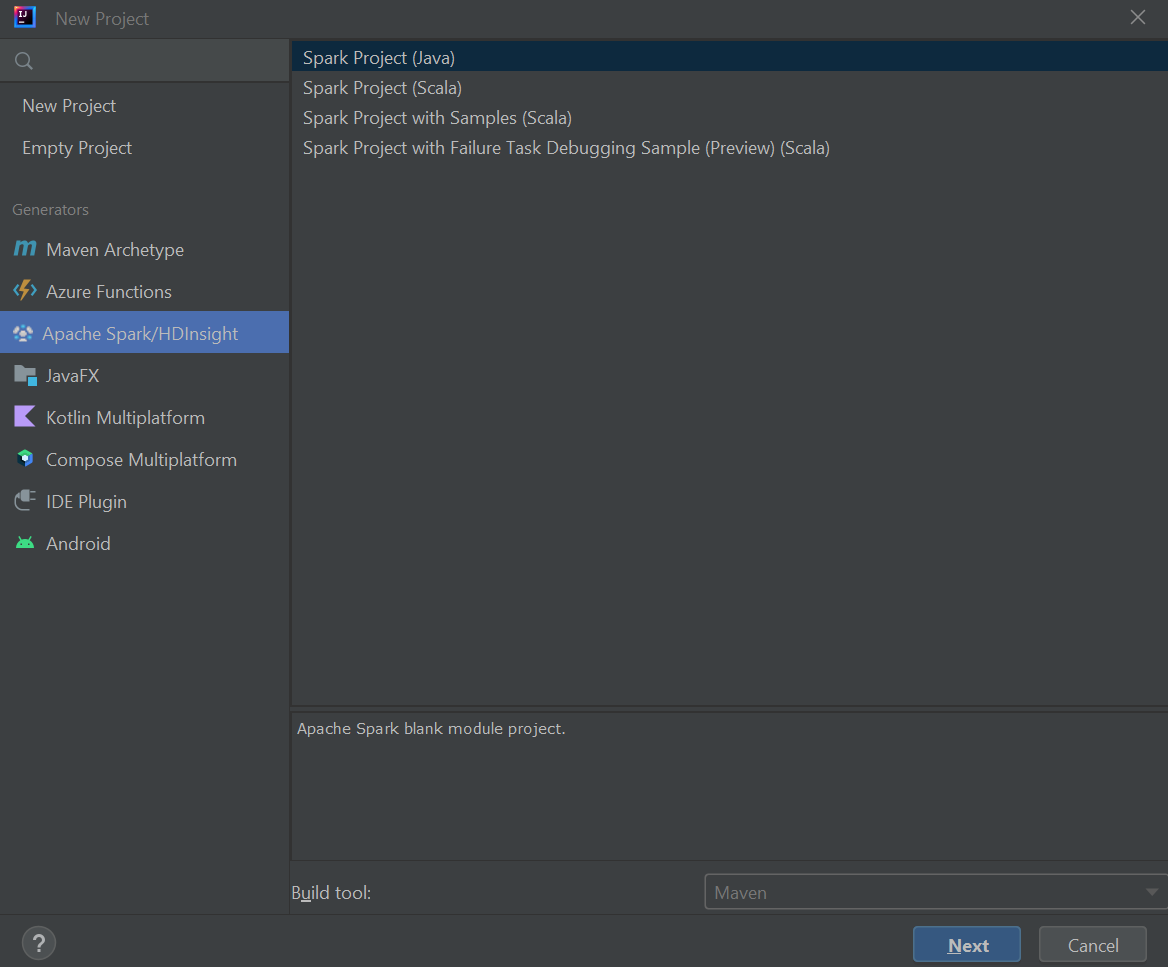
Seleccione Siguiente.
En la ventana New Project (Nuevo proyecto), proporcione la siguiente información:
Propiedad Descripción Nombre de proyecto Escriba un nombre. Ubicación del proyecto Escriba la ubicación para guardar el proyecto. Project SDK (SDK del proyecto) Este campo estará en blanco la primera vez que se use IDEA. Seleccione New... (Nuevo...) y vaya a su JDK. Versión de Spark El asistente de creación integra la versión adecuada de los SDK de Spark y Scala. Si la versión del clúster de Spark es anterior a 2.0, seleccione Spark 1.x. De lo contrario, seleccione Spark2.x. En este ejemplo se usa Spark 2.3.0 (Scala 2.11.8) . 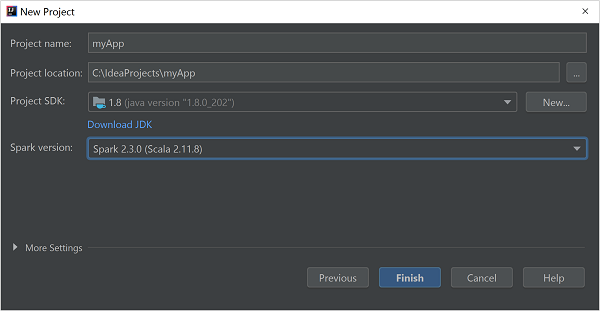
Seleccione Finalizar.
Creación de un proyecto de Scala independiente
Inicie IntelliJ IDEA y seleccione Create New Project (Crear proyecto) para abrir la ventana New Project (Nuevo proyecto).
Seleccione Maven en el panel izquierdo.
Especifique un SDK de proyecto. Si está en blanco, seleccione New... (Nuevo...) y vaya al directorio de instalación de Java.
Active la casilla Create from archetype (Crear desde arquetipo).
En la lista de arquetipos, seleccione
org.scala-tools.archetypes:scala-archetype-simple. Este arquetipo crea la estructura de directorios adecuada y descargará las dependencias predeterminadas necesarias para escribir el programa con Scala.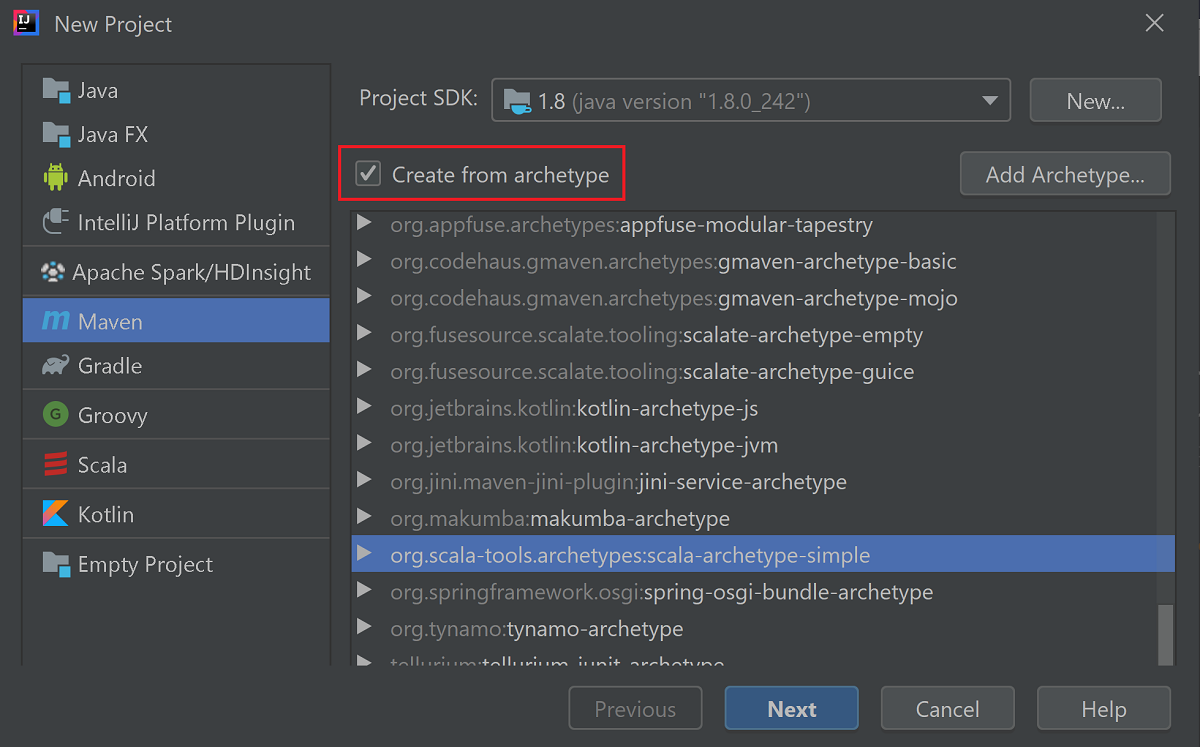
Seleccione Siguiente.
Expanda Coordenadas de artefacto. Proporcione los valores correspondientes para GroupId (Id. de grupo) y ArtifactId (Id. de artefacto). Name (Nombre) y Location (Ubicación) se rellenarán automáticamente. Los siguientes valores se utilizan en este tutorial:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
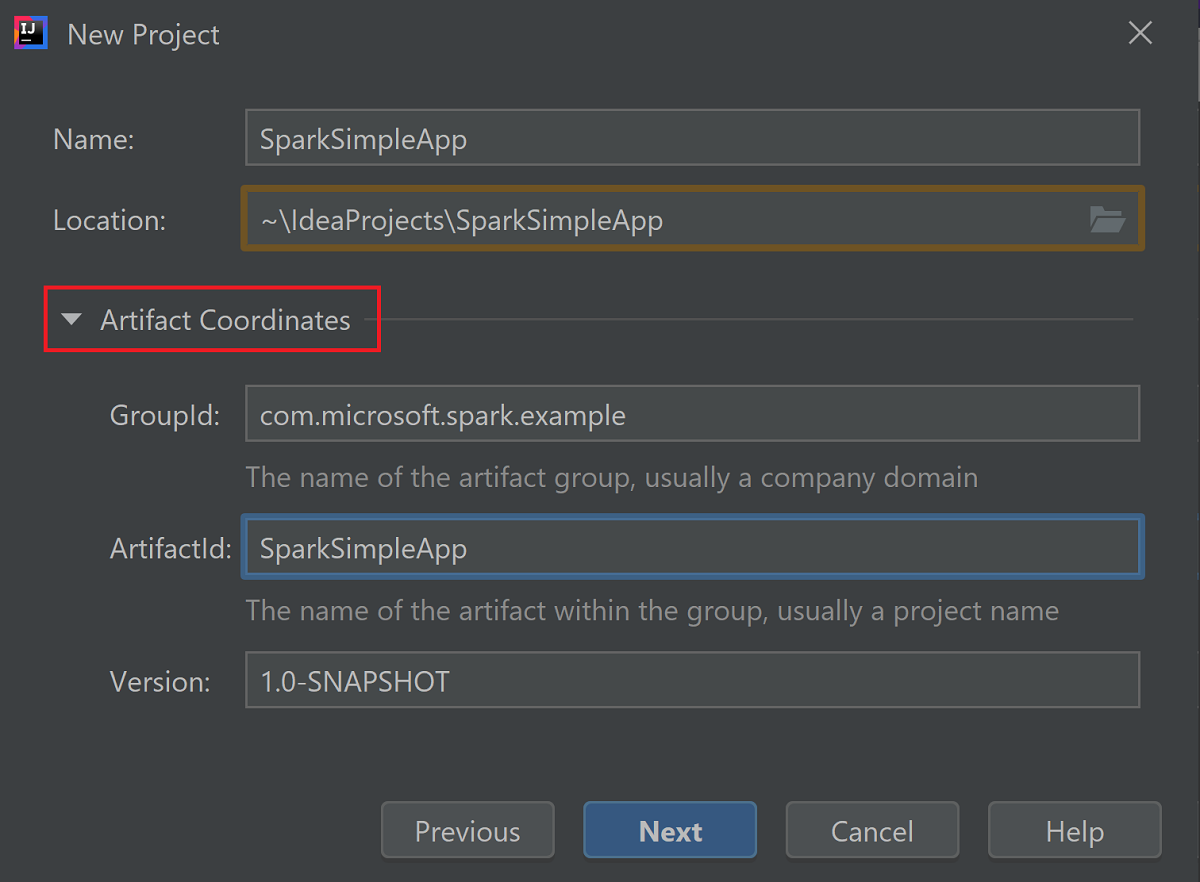
Seleccione Siguiente.
Compruebe la configuración y seleccione Next (Siguiente).
Compruebe el nombre y la ubicación del proyecto, y seleccione Finish(Finalizar). El proyecto tardará unos minutos en importarse.
Una vez importado el proyecto, en el panel izquierdo, vaya a SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Haga clic con el botón derecho en MySpec y, luego, seleccione Delete... (Eliminar...). Este archivo no es necesario para la aplicación. Seleccione OK (Aceptar) en el cuadro de diálogo.
En los pasos siguientes, actualizará el archivo pom.xml para definir las dependencias de la aplicación de Scala para Spark. Para que tales dependencias se descarguen y resuelvan automáticamente, debe configurar Maven.
En el menú File (Archivo), seleccione Settings (Configuración) para abrir la ventana Settings (Configuración).
En la ventana Settings (Configuración), vaya a Build, Execution, Deployment>Build Tools>Maven>Importing (Compilación, ejecución o implementación > Herramientas de compilación > Maven > Importación).
Active la casilla Import Maven projects automatically (Importar proyectos de Maven automáticamente).
Seleccione Aplicar y luego Aceptar. Volverá a la ventana del proyecto.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::En el panel izquierdo, vaya a src>main>scala>com.microsoft.spark.exampley haga doble clic en App para abrir App.scala.
Reemplace el código de ejemplo existente por el código siguiente y guarde los cambios. Este código lee los datos de HVAC.csv (disponible en todos los clústeres de HDInsight Spark). Recupera las filas que solo tienen un dígito en la sexta columna. Luego escribe el resultado en /HVACOut en el contenedor de almacenamiento predeterminado para el clúster.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }En el panel izquierdo, haga doble clic en pom.xml.
En
<project>\<properties>, agregue los siguientes segmentos:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>En
<project>\<dependencies>, agregue los siguientes segmentos:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Cree el archivo .jar. IntelliJ IDEA permite crear JAR como un artefacto de un proyecto. Siga estos pasos.
En el menú File (Archivo), seleccione Project Structure... (Estructura de proyecto).
En la ventana Project Structure (Estructura de proyecto), vaya a Artifacts>the plus symbol +>JAR>From modules with dependencies... (Artefactos > el símbolo + > JAR > Desde módulos con dependencias).
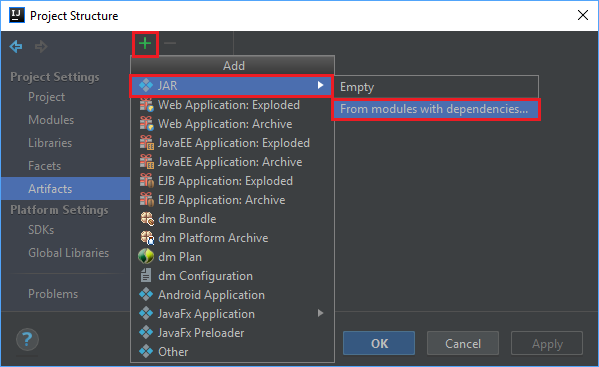
En la ventana Create JAR from Modules (Crear JAR a partir de módulos), seleccione el icono de carpeta en el cuadro de texto Main Class (Clase principal).
En el cuadro de diálogo Select Main Class (Seleccionar clase principal), seleccione la clase que aparece de forma predeterminada y, luego, seleccione OK (Aceptar).
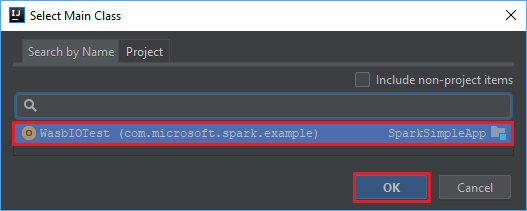
En la ventana Create JAR from Modules (Crear JAR desde módulos), asegúrese de que está seleccionada la opción Extract to the target JAR (Extraer al archivo JAR de destino) y, después, seleccione OK (Aceptar). Este valor crea un archivo JAR único con todas las dependencias.
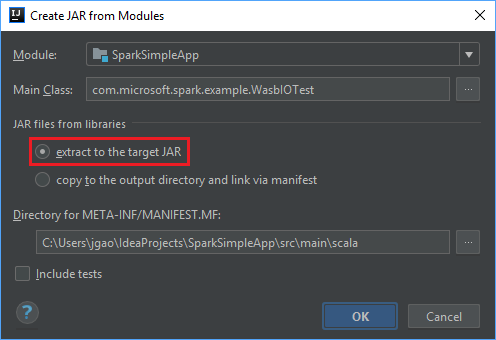
La pestaña Output Layout (Diseño de salida) enumera todos los archivos JAR que forman parte del proyecto Maven. Puede seleccionar y eliminar aquellos de los que la aplicación de Scala no tenga ninguna dependencia directa. Para la aplicación que va a crear aquí, puede quitar todos, salvo el último (SparkSimpleApp compile output). Seleccione los archivos JAR que va a eliminar y, después, seleccione símbolo negativo - .
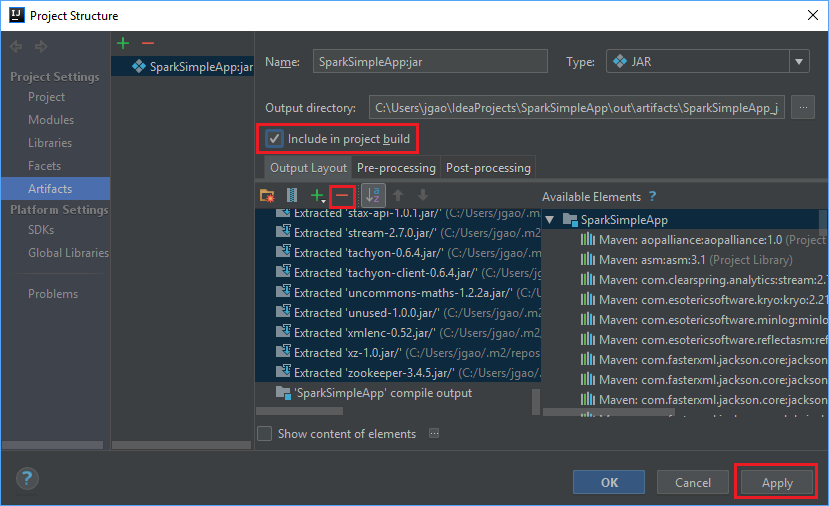
Asegúrese de que la casilla Include in project build (Incluir en compilación del proyecto) está activada, lo que garantiza que el archivo jar se crea cada vez que el proyecto se compila o actualiza. Seleccione Apply (Aplicar) y, después, OK (Aceptar).
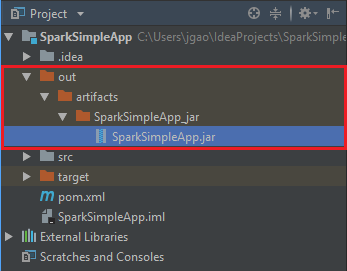
Para crear el archivo JAR, vaya a Build>Build Artifacts>Build (Compilar > Artefactos de compilación > Compilar). El proyecto se compilará al cabo de 30 segundos aproximadamente. El archivo JAR de salida se crea en \out\artifacts.
Ejecución de la aplicación en el clúster de Apache Spark
Para ejecutar la aplicación en el clúster, puede usar los siguientes enfoques:
Copie el archivo jar de la aplicación en el blob de Azure Storage asociado con el clúster. Puede usar AzCopy, una utilidad de línea de comandos, para hacerlo. Hay muchos otros clientes que se pueden utilizar también para cargar datos. Puede encontrar más información al respecto en Carga de datos para trabajos de Apache Hadoop en HDInsight.
Use Apache Livy para enviar un trabajo de la aplicación de manera remota al clúster Spark. Los clústeres Spark en HDInsight incluye Livy, que expone los puntos de conexión REST para enviar trabajos de Spark de forma remota. Para más información, consulte Envío remoto de trabajos de Apache Spark mediante la utilización de Apache Livy con clústeres Spark en HDInsight.
Limpieza de recursos
Si no va a seguir usando esta aplicación, elimine el clúster que creó mediante los siguientes pasos:
Inicie sesión en Azure Portal.
En el cuadro Búsqueda en la parte superior, escriba HDInsight.
Seleccione Clústeres de HDInsight en Servicios.
En la lista de clústeres de HDInsight que aparece, seleccione el signo ... situado junto al clúster que ha creado para este tutorial.
Seleccione Eliminar. Seleccione Sí.
Paso siguiente
En este artículo ha aprendido a crear una aplicación en Scala para Apache Spark. Vaya al siguiente artículo para aprender a ejecutar esta aplicación en un clúster de HDInsight Spark con Livy.