Inicio rápido: Creación de un clúster de Apache Spark en Azure HDInsight mediante Azure Portal
En este inicio rápido, se usa Azure Portal para crear un clúster de Apache Spark en Azure HDInsight. Luego se crea un cuaderno de Jupyter Notebook y se usa para ejecutar consultas de Spark SQL en tablas de Apache Hive. Azure HDInsight es un servicio administrado, de espectro completo y de análisis de código abierto para empresas. El marco de Apache Spark para HDInsight permite un análisis de datos y un procesamiento de clústeres rápidos mediante el procesamiento en memoria. Jupyter Notebook permite interactuar con los datos, combinar código con texto Markdown y realizar visualizaciones simples.
Para una explicación detallada de las configuraciones disponibles, consulte el artículo sobre la configuración de clústeres en HDInsight. Para más información sobre el uso del portal para crear clústeres, consulte el artículo sobre la creación de clústeres en el portal.
Si usa varios clústeres juntos, quizá quiere crear una red virtual. Si usa un clúster de Spark, también es posible que quiera usar Hive Warehouse Connector. Para más información, consulte Planificación de una red virtual para Azure HDInsight e Integración de Apache Spark y Apache Hive con el conector de Hive Warehouse.
Importante
La facturación de los clústeres de HDInsight se prorratea por minuto, tanto si se usan como si no. Por consiguiente, es aconsejable eliminar el clúster al terminar de usarlo. Para obtener más información, consulte la sección Limpieza de recursos de este artículo.
Prerrequisitos
Una cuenta de Azure con una suscripción activa. Cree una cuenta gratuita.
Creación de un clúster de Apache Spark en HDInsight
Azure Portal se usa para crear un clúster de HDInsight que utiliza blobs de Azure Storage Blob como almacenamiento de clústeres. Para más información sobre el uso de Data Lake Storage Gen2, consulte Guía de inicio rápido: Configuración de clústeres en HDInsight.
Inicie sesión en Azure Portal.
En el menú superior, seleccione + Crear un recurso.
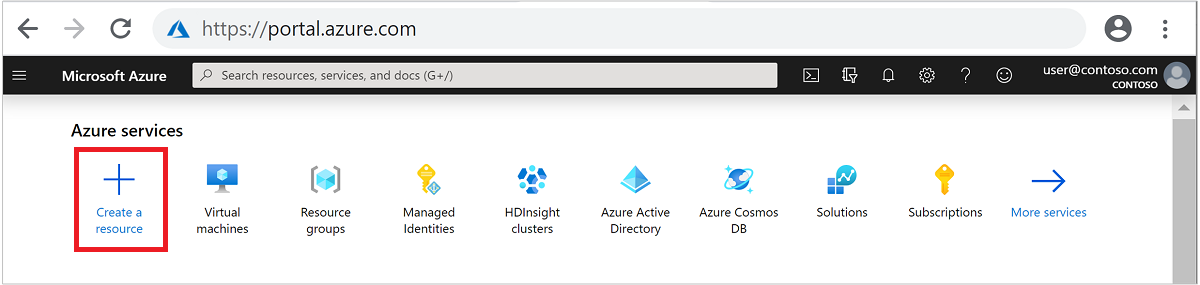
Seleccione Analytics>Azure HDInsight para ir a la página Crear clúster de HDInsight.
En la pestaña Básico, especifique la siguiente información:
Propiedad Descripción Subscription En la lista desplegable, seleccione la suscripción de Azure que se usa para el clúster. Resource group En la lista desplegable, seleccione el grupo de recursos existente o seleccione Crear. Nombre del clúster Escriba un nombre único global. Region En la lista desplegable, seleccione una región donde crear el clúster. Zona de disponibilidad Opcional: especifique una zona de disponibilidad donde implementar el clúster. Tipo de clúster Seleccione el tipo de clúster para abrir una lista. En ella, seleccione Spark. Versión del clúster Este campo se rellenará automáticamente con la versión predeterminada una vez que se haya seleccionado el tipo de clúster. Nombre de usuario de inicio de sesión del clúster Escriba el nombre de usuario de inicio de sesión del clúster. El nombre predeterminado es admin. Use esta cuenta para iniciar sesión en Jupyter Notebook más adelante en la guía de inicio rápido. Contraseña de inicio de sesión de clúster Escriba la contraseña de inicio de sesión del clúster. Nombre de usuario de Secure Shell (SSH) Escriba el nombre de usuario de SSH. El nombre de usuario de SSH usado para este inicio rápido es sshuser. De manera predeterminada, esta cuenta comparte la contraseña con la cuenta de nombre de usuario de inicio de sesión del clúster. 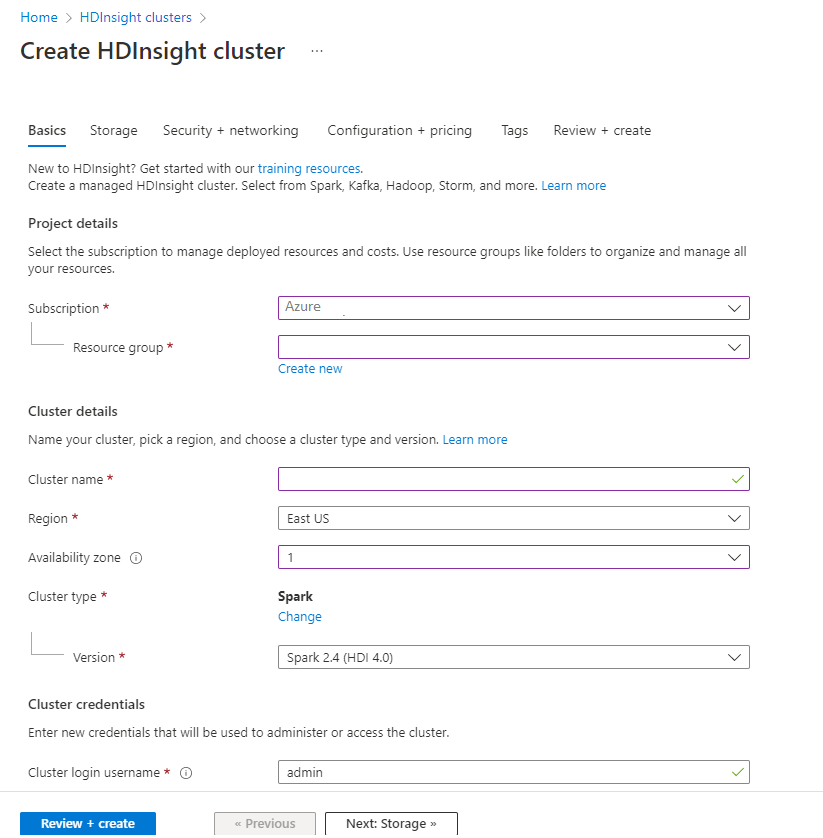
Seleccione Next: Storage >> (Siguiente: Almacenamiento >>) para ir a la página Almacenamiento.
En Almacenamiento, proporcione los valores siguientes:
Propiedad Descripción Tipo de almacenamiento principal Use el valor predeterminado Azure Storage. Método de selección Use el valor predeterminado Seleccionar de la lista. Cuenta de almacenamiento principal Use el valor que se rellena automáticamente. Contenedor Use el valor que se rellena automáticamente. 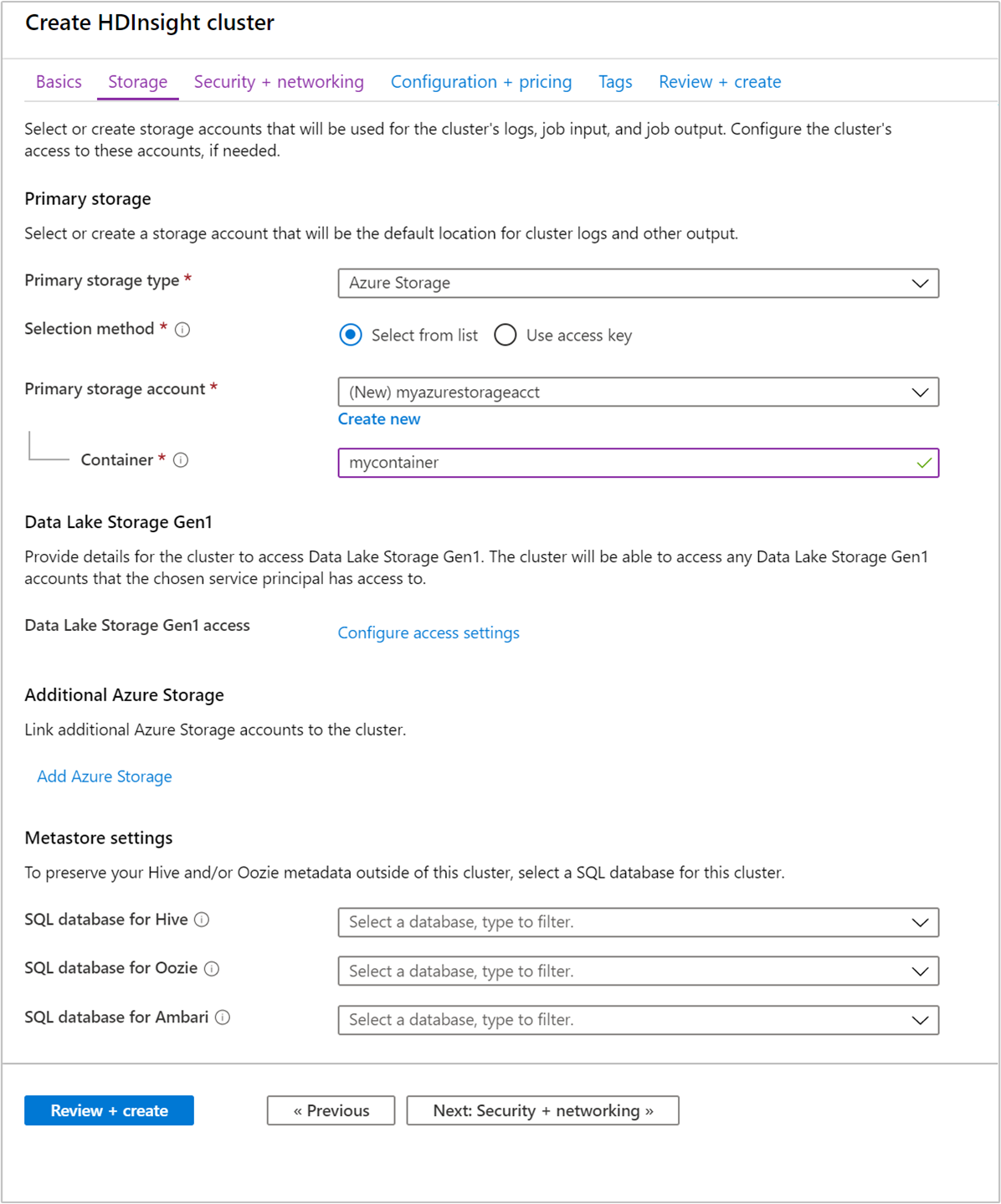
Seleccione Revisar y crear para continuar.
Seleccione Revisar y crear y, después, Crear. La creación del clúster tarda aproximadamente 20 minutos. El clúster debe crearse para poder pasar a la siguiente sesión.
Si surge algún problema al crear clústeres de HDInsight, podría deberse a que no tiene los permisos adecuados para hacerlo. Para más información, consulte Requisitos de control de acceso.
Creación de un cuaderno de Jupyter Notebook
Jupyter Notebook es un entorno de cuaderno interactivo que admite varios lenguajes de programación. El cuaderno le permite interactuar con los datos, combinar código con el texto de marcado y realizar visualizaciones básicas.
En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net/jupyter, dondeCLUSTERNAMEes el nombre del clúster. Cuando se le solicite, escriba las credenciales de inicio de sesión del clúster.Seleccione Nuevo>PySpark para crear un cuaderno.
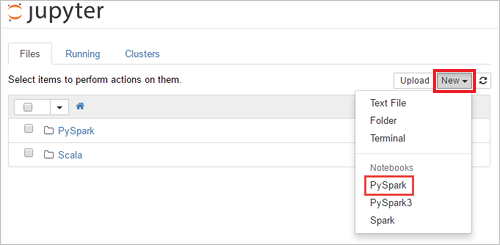
Se crea y se abre un nuevo cuaderno con el nombre Untitled(Untitled.pynb).
Ejecución de instrucciones de Apache Spark SQL
SQL (Lenguaje de consulta estructurado) es el lenguaje más común y ampliamente utilizado en la consulta y definición de datos. Spark SQL funciona como una extensión de Apache Spark para procesar datos estructurados, mediante la conocida sintaxis de SQL.
Compruebe que el kernel esté preparado. El kernel está preparado cuando aparece un círculo vacío junto al nombre del kernel en el cuaderno. Un círculo sólido indica que el kernel está ocupado.

Al iniciar el cuaderno por primera vez, el kernel realiza tareas en segundo plano. Espere a que el kernel esté preparado.
Pegue el código siguiente en una celda vacía y presione MAYÚS + ENTRAR para ejecutar el código. El comando muestra las tablas Hive del clúster:
%%sql SHOW TABLESSi se utiliza un cuaderno de Jupyter Notebook con un clúster de HDInsight, se obtiene un valor de
sqlContextpreestablecido que puede usar para ejecutar consultas de Hive mediante Spark SQL.%%sqlindica a Jupyter Notebook que use el valor desqlContextpreestablecido para ejecutar la consulta de Hive. La consulta recupera las 10 primeras filas de una tabla de Hive (hivesampletable) que se incluye de forma predeterminada en todos los clústeres de HDInsight. Se tardan unos 30 segundos en obtener los resultados. El resultado tendrá una apariencia similar a la siguiente: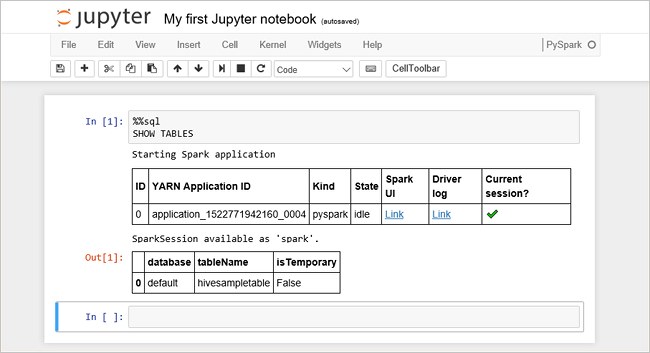 es inicio rápido." border="true":::
es inicio rápido." border="true":::Cada vez que se ejecuta una consulta en Jupyter, el título de la ventana del explorador web muestra el estado (Busy) (Ocupado) junto con el título del cuaderno. También verá un círculo sólido junto al texto PySpark en la esquina superior derecha.
Ejecute otra consulta para ver los datos en
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10Debe actualizar la pantalla para mostrar la salida de la consulta.
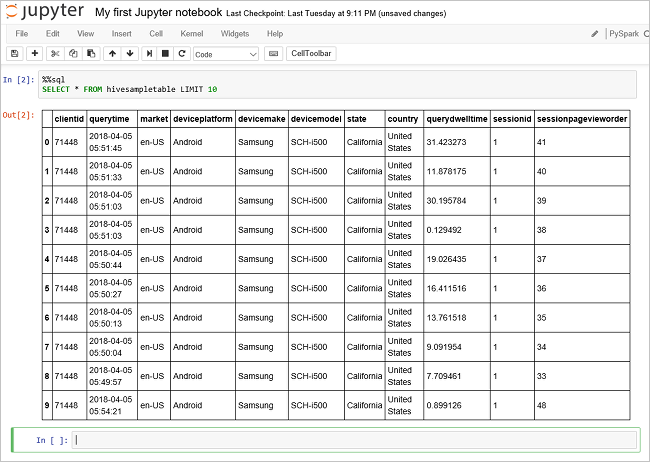 Insight" border="true":::
Insight" border="true":::En el menú File (Archivo) del cuaderno, seleccione Close and Halt (Cerrar y detener). Al cerrar el cuaderno, se liberan los recursos de clúster.
Limpieza de recursos
HDInsight guarda los datos en Azure Storage o Azure Data Lake Storage, por lo que puede eliminar de manera segura un clúster si no se está usando. Los clústeres de HDInsight se cobran aunque no se estén usando. Como en muchas ocasiones los cargos por el clúster son mucho más elevados que los cargos por el almacenamiento, desde el punto de vista económico tiene sentido eliminar clústeres cuando no se usen. Si tiene previsto pasar inmediatamente al tutorial de Pasos siguientes, es aconsejable que no elimine el clúster.
Vuelva a Azure Portal y seleccione Eliminar.
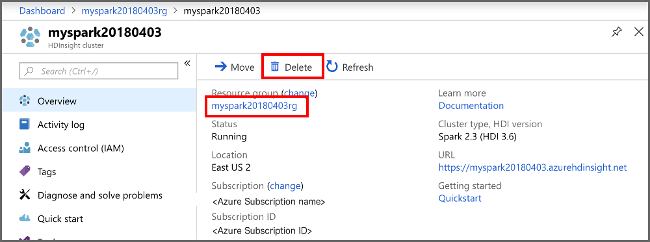 sight cluster" border="true":::
sight cluster" border="true":::
También puede seleccionar el nombre del grupo de recursos para abrir la página del grupo de recursos y, a continuación, seleccionar Eliminar grupo de recursos. Al eliminar el grupo de recursos, se eliminan tanto el clúster de HDInsight como la cuenta de almacenamiento predeterminada.
Pasos siguientes
En este inicio rápido, ha aprendido a crear un clúster de Apache Spark en HDInsight y a ejecutar una consulta básica de Spark SQL. Pase al siguiente tutorial, donde aprenderá a usar un clúster de HDInsight para ejecutar consultas interactivas en datos de ejemplo.