Uso de Azure Toolkit for Eclipse para crear aplicaciones de Apache Spark para un clúster de HDInsight
Use las herramientas de HDInsight de Azure Toolkit for Eclipse a fin de desarrollar aplicaciones de Apache Spark escritas en Scala y enviarlas a un clúster de Azure HDInsight Spark directamente desde el IDE de Eclipse. Puede usar el complemento de las herramientas de HDInsight de varias maneras distintas:
- Para desarrollar y enviar una aplicación Spark en Scala en un clúster de HDInsight Spark.
- Para acceder a los recursos del clúster de Azure HDInsight Spark.
- Para desarrollar y ejecutar localmente una aplicación Spark en Scala.
Requisitos previos
Clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure.
IDE de Eclipse. En este artículo se usa el IDE de Eclipse para desarrolladores de Java.
Instalación de los complementos requeridos
Instalación del kit de herramientas de Azure para Eclipse
Para obtener instrucciones de instalación, consulte Instalación del Kit de herramientas de Azure para Eclipse.
Instalación del complemento Scala
Al abrir Eclipse, las herramientas de HDInsight detectan automáticamente si se ha instalado el complemento Scala. Seleccione Aceptar para continuar y luego siga las instrucciones para instalar el complemento desde Marketplace de Eclipse. Reinicie el IDE después de que finalice la instalación.
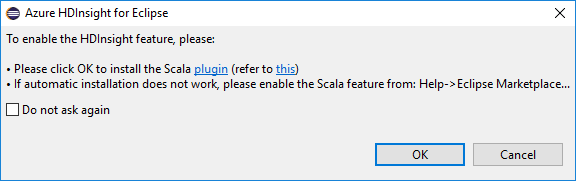
Confirmación de complementos
Vaya a Ayuda>Eclipse Marketplace...
Seleccione la pestaña Instalado.
Debería ver al menos:
- Azure Toolkit for Eclipse <versión>.
- IDE de Scala <versión>.
Inicie sesión en la suscripción de Azure
Inicie el IDE de Eclipse.
Vaya a Window>Show View>Other...>Sign In... (Ventana > Mostrar vista > Otros > Iniciar sesión...).
En el cuadro de diálogo Show View (Mostrar vista), vaya a Azure>Azure Explorer y, a continuación, seleccione Open (Abrir).
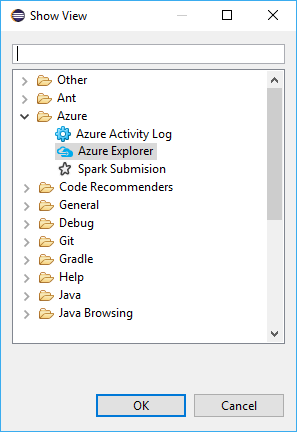
En Azure Explorer, haga clic con el botón derecho en el nodo Azure y después seleccione Iniciar sesión.
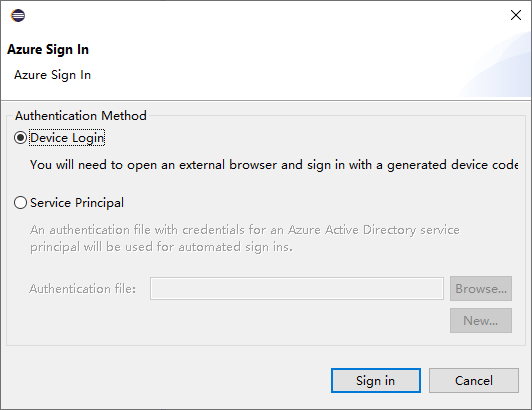
En el cuadro de diálogo Azure Sign In (Inicio de sesión en Azure), elija el método de autenticación, seleccione Sign in (Iniciar sesión) y complete el proceso de inicio de sesión.
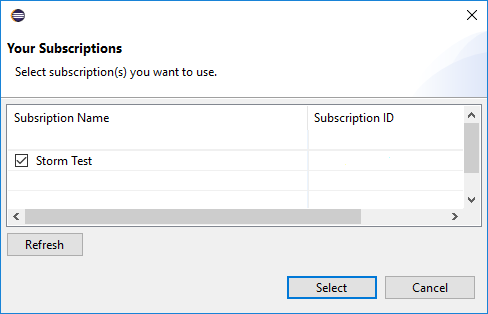
Cuando haya iniciado sesión, en el cuadro de diálogo Select Subscriptions (Seleccionar suscripciones) se enumeran todas las suscripciones de Azure asociadas a las credenciales. Haga clic en Select (Seleccionar) para cerrar el cuadro de diálogo.
En la pestaña Azure Explorer, vaya a Azure>HDInsight para ver los clústeres de HDInsight Spark de su suscripción.
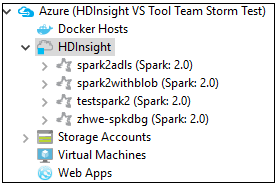
Puede expandir un nodo de nombre de clúster para ver los recursos (por ejemplo, las cuentas de almacenamiento) asociados al clúster.
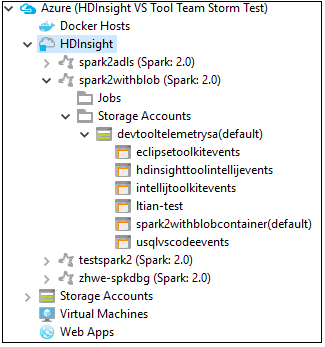
Vinculación de un clúster
Puede vincular un clúster normal mediante el nombre de usuario administrado de Ambari. De forma similar, para un clúster de HDInsight unido a un dominio, puede vincular con el dominio y el nombre de usuario, como user1@contoso.com.
En Azure Explorer, haga clic con el botón derecho en HDInsight y, a continuación, seleccione Link A Cluster (Vincular un clúster).
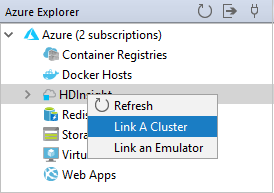
Escriba el nombre de clúster, el nombre de usuario y la contraseña y, luego, seleccione Aceptar. De manera opcional, escriba la cuenta de almacenamiento, la clave de almacenamiento y, a continuación, seleccione el contenedor de almacenamiento para que el explorador de almacenamiento funcione en la vista de árbol de la izquierda.
Nota:
Si el clúster se registró en la suscripción de Azure y se vinculó, se usan la clave de almacenamiento, el nombre de usuario y la contraseña vinculados.
Para un usuario solo de teclado, cuando el foco actual está en Clave de almacenamiento, debe usar Ctrl+TAB para centrarse en el siguiente campo del cuadro de diálogo.
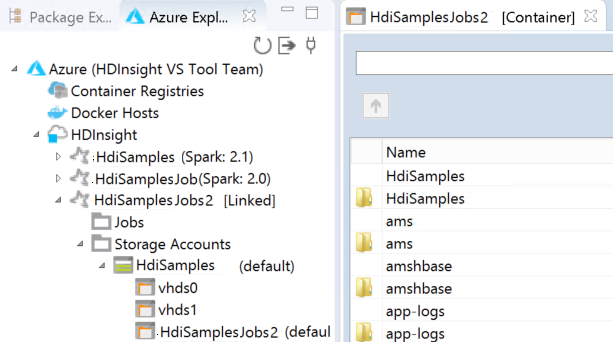
Puede ver el clúster vinculado en HDInsight. Ahora puede enviar una aplicación a este clúster vinculado.
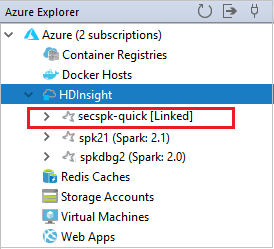
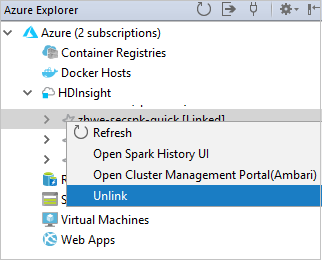
También puede desvincular un clúster de Azure Explorer.
Configuración de un proyecto Spark en Scala de un clúster Spark en HDInsight
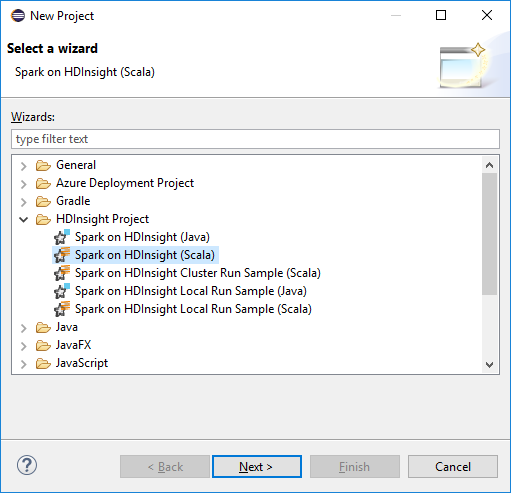
En el área de trabajo del IDE de Eclipse, seleccione File>New>Project... (Archivo > Nuevo > Proyecto).
En el Asistente para nuevo proyecto, seleccione HDInsight Project>Spark on HDInsight (Scala) (Proyecto de HDInsight > Spark on HDInsight [Scala]). Luego, seleccione Siguiente.
En el cuadro de diálogo New HDInsight Scala Project (Nuevo proyecto de Scala para HDInsight), proporcione los valores siguientes y luego seleccione Siguiente:
- Escriba un nombre para el proyecto.
- En el área JRE, asegúrese de que el valor de Use an execution environment JRE (Uso de un entorno de ejecución JRE) esté establecido en JavaSE-1.7 o posterior.
- En el área de Biblioteca de Spark, puede elegir la opción Use Maven to configure Spark SDK (Usar Maven para configurar el SDK de Spark). Nuestra herramienta integra la versión correcta del SDK de Spark y de Scala. También puede elegir la opción Add Spark SDK manually (Agregar SDK de Spark manualmente) y descargar y agregar dicho SDK de forma manual.
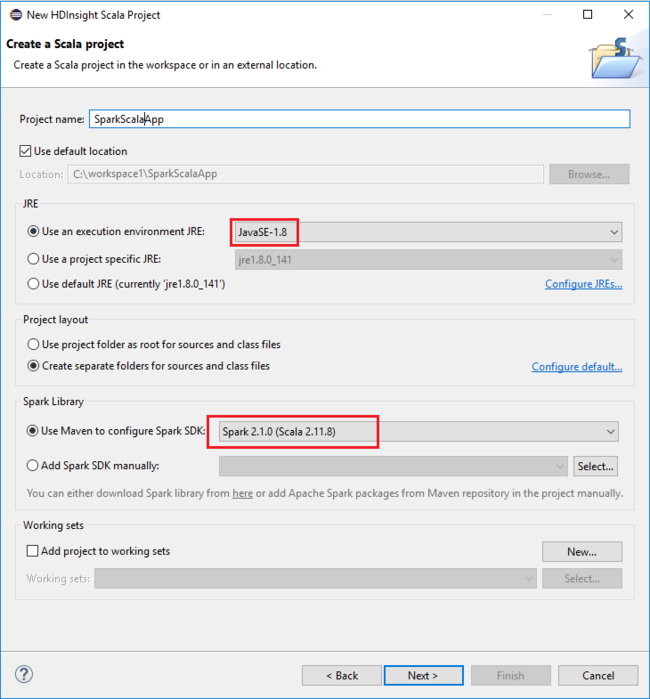
En el siguiente cuadro de diálogo, revise los detalles y, a continuación, seleccione Finish (Finalizar).
Creación de una aplicación de Scala para un clúster de HDInsight Spark
En explorador de paquetes, expanda el proyecto que creó anteriormente. Haga clic con el botón derecho en src y seleccione New>Other... (Nuevo > Otros).
En el cuadro de diálogo Select a wizard (Seleccionar un asistente), seleccione Scala Wizards>Scala Object (Asistentes para Scala > Objeto de Scala). Luego, seleccione Siguiente.
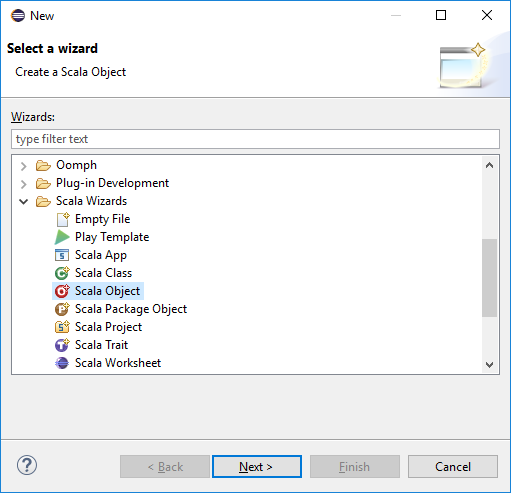
En el cuadro de diálogo Crear nuevo archivo, escriba un nombre para el objeto y seleccione Finalizar. Se abrirá un editor de texto.
En el editor de texto, reemplace el contenido actual por el código siguiente:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Ejecute la aplicación en un clúster de HDInsight Spark:
a. En el Explorador de paquetes, haga clic con el botón derecho en el nombre del proyecto y seleccione Submit Spark Application to HDInsight (Enviar aplicación Spark a HDInsight).
b. En el cuadro de diálogo Spark Submission (Envío de Spark), proporcione los siguientes valores y luego seleccione Enviar:
Para Cluster Name(Nombre del clúster), seleccione el clúster Spark en HDInsight en el que quiere ejecutar la aplicación.
Seleccione un artefacto del proyecto Eclipse o uno de un disco duro. El valor predeterminado depende del elemento en el que se hace clic con el botón derecho desde el explorador de paquetes.
En la lista desplegable Nombre de la clase principal, el asistente para envío muestra todos los nombres de objetos del proyecto. Seleccione o escriba uno que quiera ejecutar. Si ha seleccionado un artefacto de una unidad de disco duro, debe escribir manualmente el nombre de la clase principal.
Dado que el código de aplicación de este ejemplo no requiere ningún argumento de línea de comandos ni archivos o JAR de referencia, puede dejar vacíos los demás cuadros de texto.
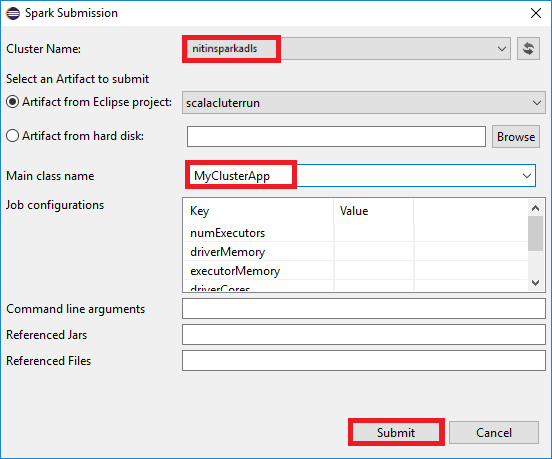
La pestaña Spark Submission (Envío de Spark) debería empezar a mostrar el progreso. Puede detener la aplicación si selecciona el botón rojo de la ventana Spark Submission (Envío de Spark). También puede ver los registros de ejecución de esta aplicación concreta si selecciona el icono de globo (que se indica con el cuadro azul en la imagen).
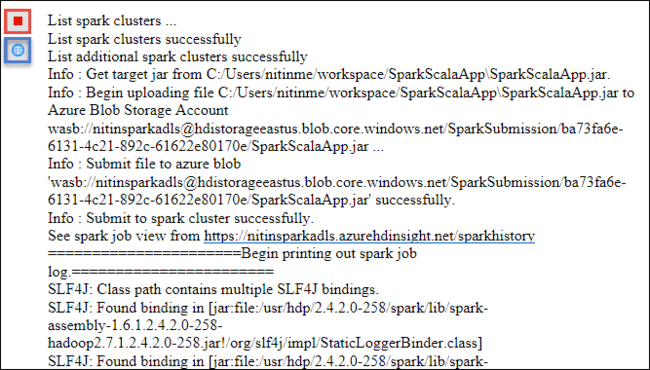
Acceso y administración de clústeres HDInsight Spark mediante las herramientas de HDInsight del kit de herramientas de Azure para Eclipse
Puede realizar varias operaciones mediante herramientas de HDInsight, incluido el acceso a la salida del trabajo.
Acceso a la vista de trabajo
En Azure Explorer, expanda HDInsight y el nombre del clúster de Spark. Después, seleccione Trabajos.
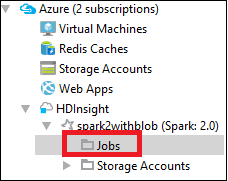
Seleccione el nodo Trabajos. Si la versión de Java es anterior a la 1.8, las Herramientas de HDInsight le recordarán automáticamente que instale el conector E(fx)clipse. Seleccione Aceptar para continuar y luego siga las instrucciones del asistente para instalarlo desde el Marketplace de Eclipse y reiniciar Eclipse.
Abra la vista de trabajo desde el nodo Trabajos. En el panel derecho, la pestaña Spark Job View (Vista de trabajos de Spark) muestra todas las aplicaciones que se ejecutaron en el clúster. Seleccione el nombre de la aplicación para la que desea ver más detalles.
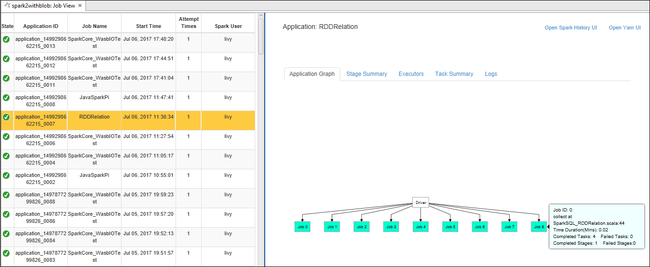
Luego puede realizar cualquiera de estas acciones:
Mantener el puntero sobre el gráfico del trabajo. Muestra información básica sobre el trabajo en ejecución. Seleccione el gráfico del trabajo para ver las fases y la información que genera cada trabajo.
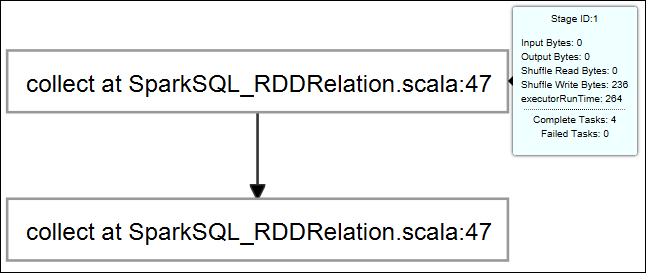
Para ver registros usados con frecuencia, como Driver Stderr, Driver Stdout y Directory Info, seleccione la pestaña Registro.
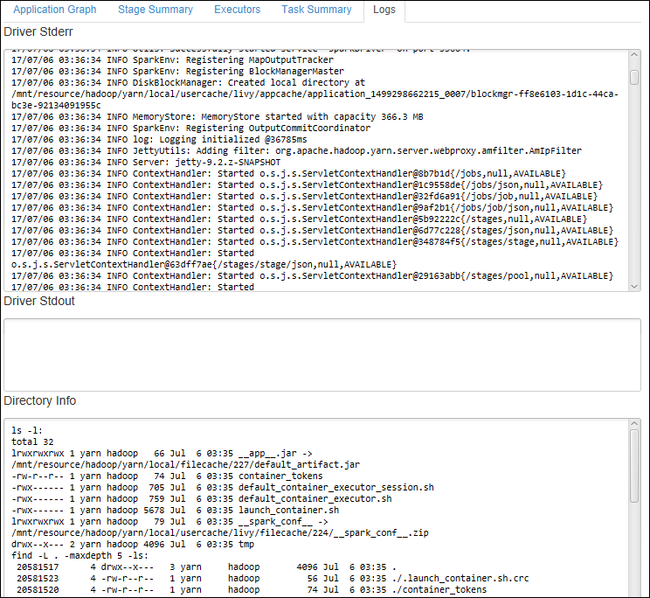
Abra la interfaz de usuario del historial de Spark y la interfaz de usuario de Apache Hadoop YARN (en el nivel de aplicación) mediante la selección de los hipervínculos de la parte superior de la ventana.
Acceso al contenedor de almacenamiento para el clúster
En Azure Explorer, expanda el nodo raíz HDInsight para ver una lista de los clústeres HDInsight Spark disponibles.
Expanda el nombre del clúster para ver la cuenta de almacenamiento y el contenedor de almacenamiento predeterminado para el clúster.
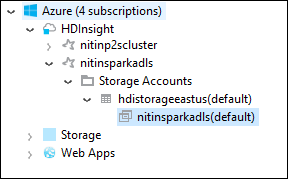
Seleccione el nombre del contenedor de almacenamiento asociado al clúster. En el panel derecho, haga doble clic en la carpeta HVACOut. Abra uno de los archivos part- para ver la salida de la aplicación.
Acceso al servidor de historial de Spark
En Azure Explorer, haga clic con el botón derecho en el nombre del clúster Spark y seleccione Open Spark History UI (Abrir IU de historial de Spark). Cuando se le pida, escriba las credenciales de administrador para el clúster. Las ha especificado al aprovisionar el clúster.
En el panel del servidor de historial de Spark, use el nombre de aplicación para buscar la aplicación que acaba de terminar de ejecutar. En el código anterior, se establece el nombre de la aplicación mediante
val conf = new SparkConf().setAppName("MyClusterApp"). Por lo tanto, el nombre de la aplicación Spark era MyClusterApp.
Inicio del portal de Apache Ambari
En Azure Explorer, haga clic con el botón derecho en el nombre del clúster de Spark y seleccione Open Cluster Management Portal (Ambari) (Abrir portal de administración de clústeres [Ambari]).
Cuando se le pida, escriba las credenciales de administrador para el clúster. Las ha especificado al aprovisionar el clúster.
Administración de suscripciones de Azure
De forma predeterminada, las herramientas de HDInsight en el kit de herramientas de Azure para Eclipse enumeran los clústeres de Spark de todas las suscripciones de Azure. Si es necesario, puede especificar las suscripciones que desea que tengan acceso al clúster.
En Azure Explorer, haga clic con el botón derecho en el nodo raíz de Azure y seleccione Manage Subscriptions (Administrar suscripciones).
En el cuadro de diálogo, desactive las casillas de la suscripción a la que no quiere acceder y luego seleccione Cerrar. También puede seleccionar Sign Out (Cerrar sesión) si desea cerrar sesión en su suscripción de Azure.
Ejecución local de una aplicación Spark en Scala
Puede utilizar las herramientas de HDInsight del kit de herramientas de Azure para Eclipse si quiere ejecutar aplicaciones Spark en Scala localmente en su estación de trabajo. Normalmente estas aplicaciones no necesitan tener acceso a los recursos de clúster, como el contenedor de almacenamiento, y se pueden ejecutar y probar de forma local.
Requisito previo
Mientras se ejecuta la aplicación Spark en Scala local en un equipo Windows, puede producirse una excepción, como se explica en SPARK-2356. Esta excepción se produce porque falta WinUtils.exe en Windows.
Para solucionar este error, necesita Winutils.exe en una ubicación como C:\WinUtils\bin y, después, agregue la variable de entorno HADOOP_HOME y establezca el valor de la variable en C\WinUtils.
Ejecución de una aplicación Spark en Scala local
Inicie Eclipse y cree un proyecto. En el cuadro de diálogo Nuevo proyecto, realice las siguientes selecciones y después seleccione Siguiente.
En el Asistente para nuevo proyecto, seleccione HDInsight Project>Spark on HDInsight Local Run Sample (Scala) (Proyecto de HDInsight > Ejemplo de ejecución local de HDInsight [Scala]). Luego, seleccione Siguiente.
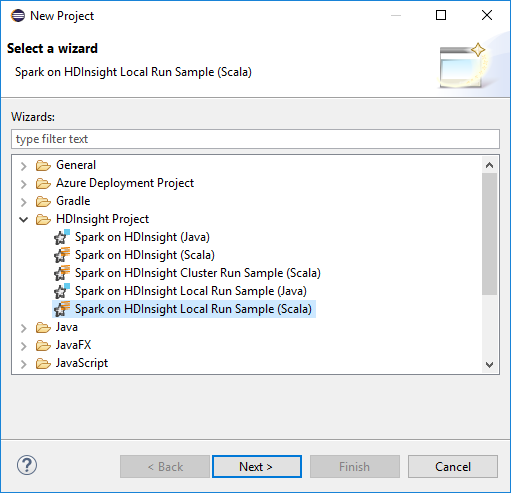
Para proporcionar los detalles del proyecto, siga los pasos del 3 a 6 de la sección anterior Configuración de un proyecto Spark en Scala de un clúster Spark en HDInsight.
La plantilla agrega un código de ejemplo (LogQuery) en la carpeta src que puede ejecutar localmente en el equipo.

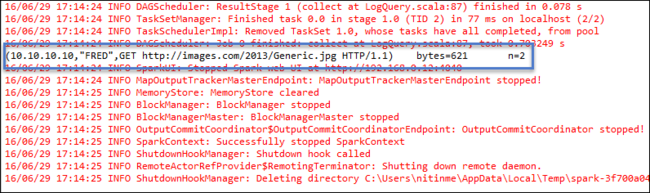
Haga clic con el botón derecho en LogQuery. Scala y seleccione Run As>1 Scala Application (Ejecutar como > 1 aplicación Scala). Aparece una salida como esta en la pestaña Consola:
Rol de solo lectura
Cuando los usuarios envían trabajos a un clúster con el permiso de rol de solo lectura, se requieren credenciales de Ambari.
Vínculo de clúster desde menú contextual
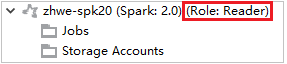
Inicie sesión con la cuenta del rol de solo lectura.
En Azure Explorer, expanda HDInsight para ver los clústeres de HDInsight de su suscripción. Los clústeres marcados como "Role:Reader" tienen únicamente permiso de solo lectura.
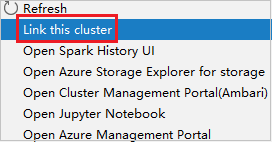
Haga clic derecho en el clúster con el permiso de rol de solo lectura. Seleccione Link this cluster (Vincular este clúster) en el menú contextual para vincular el clúster. Escriba el nombre de usuario y la contraseña de Ambari.
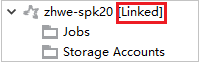
Si el clúster se vinculó correctamente, se actualizará HDInsight. La fase del clúster quedará vinculada.
Vínculo de clúster mediante la expansión del nodo de trabajos
Haga clic en el nodo Trabajos y aparecerá la ventana emergente Cluster Job Access Denied (Se denegó el acceso al trabajo del clúster).
Haga clic en Link this cluster (Vincular este clúster) para vincular el clúster.
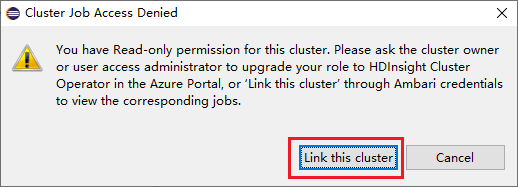
Vinculación del clúster desde la ventana de envío de Spark
Cree un proyecto de HDInsight.
Haga clic con el botón derecho en el paquete. A continuación, seleccione Submit Spark Application to HDInsight (Enviar aplicación Spark a HDInsight).
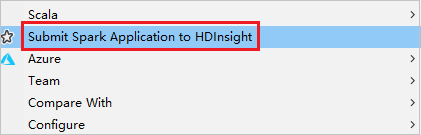
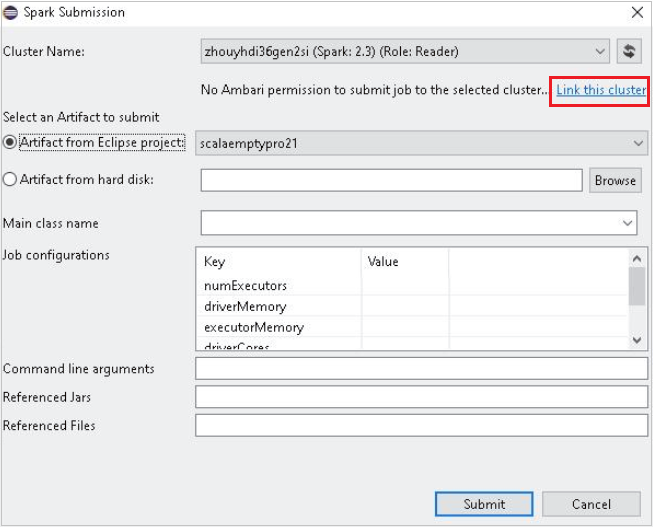
En Cluster Name (Nombre del clúster), seleccione un clúster que tenga permiso de rol de solo lectura. Aparece un mensaje de advertencia. Puede hacer clic en Link this cluster (Vincular este clúster) para vincular el clúster.
Visualización de cuentas de almacenamiento
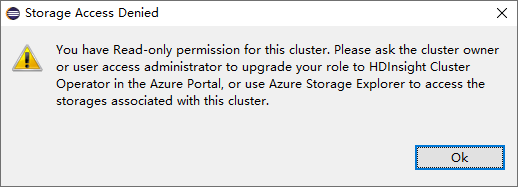
Para los clústeres con permiso de rol de solo lectura, haga clic en el nodo Cuentas de almacenamiento y aparecerá la ventana emergente Storage Access Denied (Se denegó el acceso al almacenamiento).
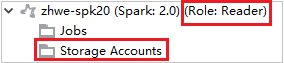
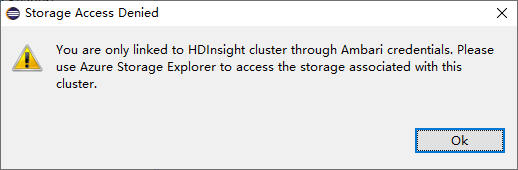
Para los clústeres vinculados, haga clic en el nodo Cuentas de almacenamiento y aparecerá la ventana emergente Storage Access Denied (Se denegó el acceso al almacenamiento).
Problemas conocidos
Al utilizar Link A Cluster (Vincular un clúster), es aconsejable especificar las credenciales de almacenamiento.
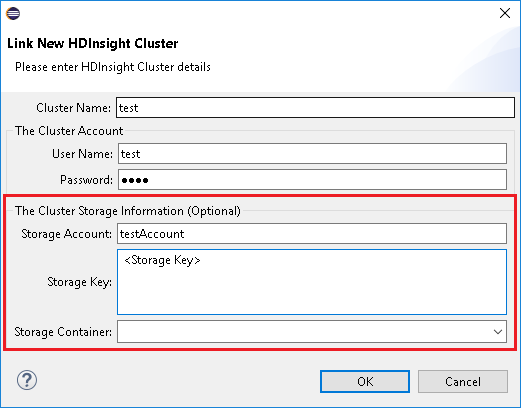
Hay dos formas de enviar los trabajos. Si se proporcionan credenciales de almacenamiento, se utilizará el modo por lotes para enviar el trabajo. De lo contrario, se utilizará el modo interactivo. Si el clúster está ocupado, puede aparecer el siguiente error.


Consulte también
Escenarios
- Apache Spark con BI: Análisis de datos interactivos con Spark en HDInsight con las herramientas de BI
- Apache Spark con Machine Learning: Uso de Spark en HDInsight para analizar la temperatura de un edificio mediante datos de HVAC
- Apache Spark con Machine Learning: uso de Spark en HDInsight para predecir los resultados de la inspección de alimentos
- Análisis de registros de un sitio web mediante Apache Spark en HDInsight
Creación y ejecución de aplicaciones
- Crear una aplicación independiente con Scala
- Ejecución de trabajos de forma remota en un clúster de Apache Spark mediante Apache Livy
Herramientas y extensiones
- Uso del kit de herramientas de Azure para IntelliJ con el fin de crear y enviar aplicaciones Spark en Scala
- Uso de Azure Toolkit for IntelliJ para depurar de forma remota aplicaciones de Apache Spark mediante VPN
- Uso de Azure Toolkit for IntelliJ para depurar de forma remota aplicaciones de Apache Spark mediante SSH
- Uso de cuadernos de Apache Zeppelin con un clúster de Apache Spark en HDInsight
- Kernels disponible para Jupyter Notebook en clústeres Apache Spark para HDInsight
- Uso de paquetes externos con cuadernos de Jupyter Notebook
- Instalación de un cuaderno de Jupyter Notebook en el equipo y conexión al clúster de Apache Spark en HDInsight de Azure