Error de depuración de trabajos de Spark con Azure Toolkit for IntelliJ (versión preliminar)
En este artículo se proporcionan instrucciones paso a paso sobre cómo usar las herramientas de HDInsight de Azure Toolkit for IntelliJ para ejecutar aplicaciones de depuración de errores de Spark.
Requisitos previos
Kit de desarrollo de Oracle Java. En este tutorial se usa la versión 8.0.202 de Java.
IntelliJ IDEA. En este artículo se usa IntelliJ IDEA Community 2019.1.3.
Azure Toolkit for IntelliJ. Consulte Instalación de Azure Toolkit for IntelliJ.
Conéctese al clúster de HDInsight. Vea Conexión al clúster de HDInsight.
Explorador de Azure Storage. Vea Descargar el Explorador de Microsoft Azure Storage.
Creación de un proyecto con la plantilla de depuración
Cree un proyecto de Spark 2.3.2 para continuar con la depuración de errores; use el archivo de ejemplo de depuración de tareas de este documento.
Abra IntelliJ IDEA. Abra la ventana New Project (Nuevo proyecto).
a. Seleccione Azure Spark/HDInsight en el panel izquierdo.
b. Seleccione Spark Project with Failure Task Debugging Samples (Preview) (Scala) (Proyecto de Spark con ejemplos de depuración de tareas de error [versión preliminar] [Scala]) en la ventana principal.
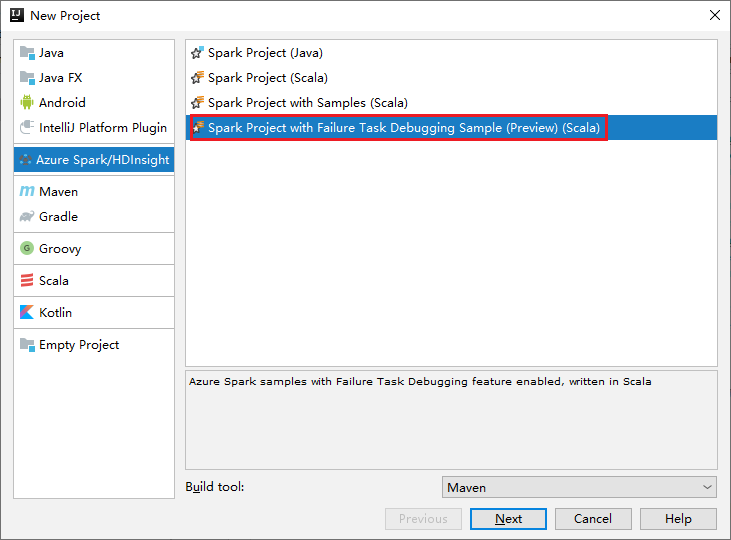
c. Seleccione Next (Siguiente).
En la ventana Nuevo proyecto, siga estos pasos:
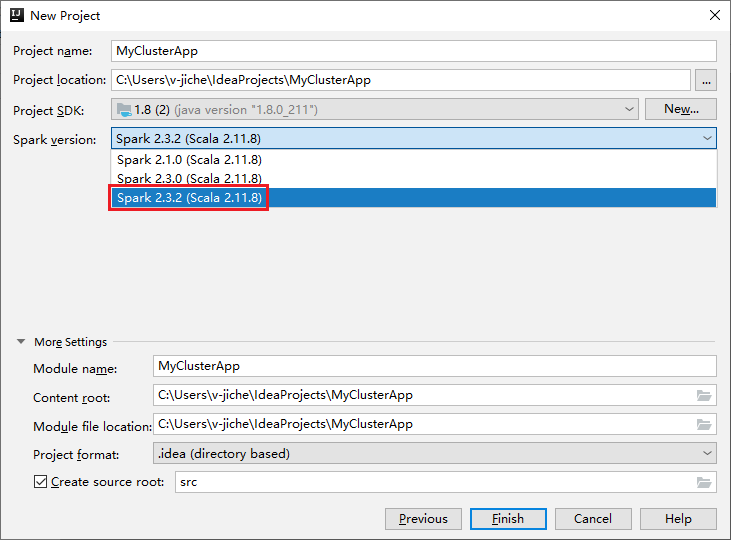
a. Escriba un nombre y una ubicación de proyecto.
b. En la lista desplegable Project SDK (SDK del proyecto), seleccione Java 1.8 para el clúster de Spark 2.3.2.
c. En la lista desplegable Spark Version (Versión de Spark), seleccione Spark 2.3.2(Scala 2.11.8) .
d. Seleccione Finalizar.
Seleccione src>main>scala para abrir el código en el proyecto. En este ejemplo se usa el script AgeMean_Div() .
Ejecución de una aplicación Scala o Java de Spark en un clúster de HDInsight
Cree una aplicación de Scala o Java de Spark, y después ejecútela en un clúster de Spark mediante estos pasos:
Haga clic en Add Configuration (Agregar configuración) para abrir la ventana Run/Debug Configurations (Ejecutar/depurar configuraciones).

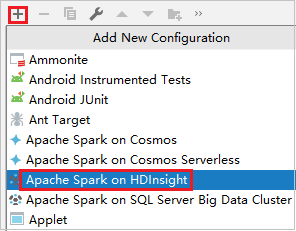
En el cuadro de diálogo Run/Debug Configurations (Ejecutar/depurar configuraciones), seleccione el signo más (+). Después, seleccione la opción Apache Spark on HDInsight (Apache Spark en HDInsight).
Cambie a la pestaña Remotely Run in Cluster (Ejecutar de forma remota en clúster). Escriba la información en los campos Name (Nombre), Spark cluster (Clúster de Spark) y Main class name (Nombre de clase principal). Nuestras herramientas admiten la depuración con ejecutores. El valor predeterminado de numExecutors es 5, y se recomienda no establecerlo por encima de 3. Para reducir el tiempo de ejecución, puede agregar spark.yarn.maxAppAttempts a job Configurations y establecer el valor en 1. Haga clic en el botón Aceptar para guardar la configuración.
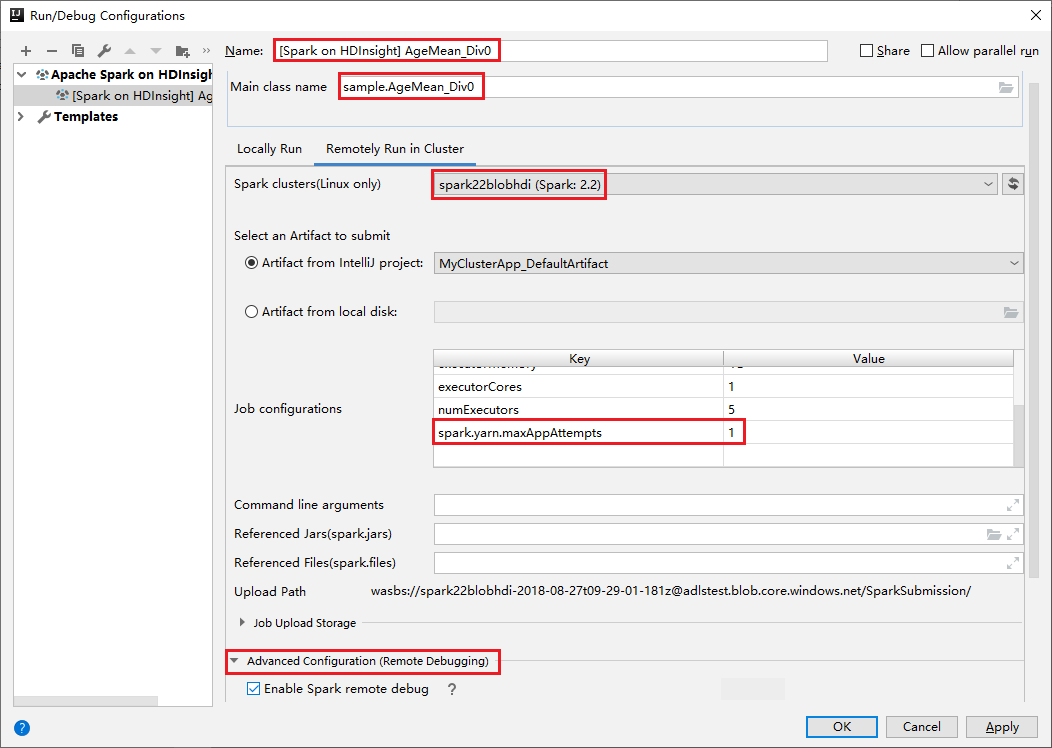
La configuración se guarda ahora con el nombre especificado. Para ver los detalles de configuración, seleccione el nombre de configuración. Para realizar cambios, seleccione Edit Configurations (Editar configuraciones).
Después de completar la configuración, puede ejecutar el proyecto en el clúster remoto.

Puede comprobar el identificador de la aplicación en la ventana de salida.

Error en la descarga del perfil de trabajo
Si se produce un error al enviar el trabajo, puede descargar el perfil de trabajo con errores en el equipo local para depurarlo más.
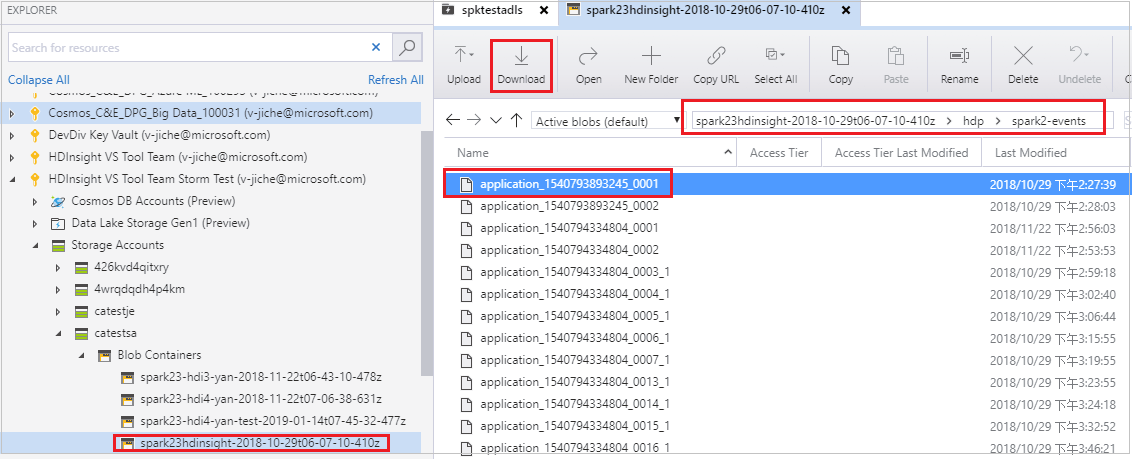
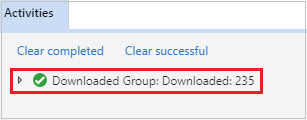
Abra el Explorador de Storage de Microsoft Azure, busque la cuenta de HDInsight del clúster del trabajo con errores, descargue los recursos de trabajo con errores desde la ubicación correspondiente: \hdp\spark2-events\.spark-failures\<id. de la aplicación> a una carpeta local. En la ventana activities (Actividades) se mostrará el progreso de la descarga.
Configuración del entorno de depuración local y depuración en caso de error
Abra el proyecto original, o bien cree uno y asócielo al código fuente original. Actualmente solo se admite la versión spark2.3.2 para la depuración de errores.
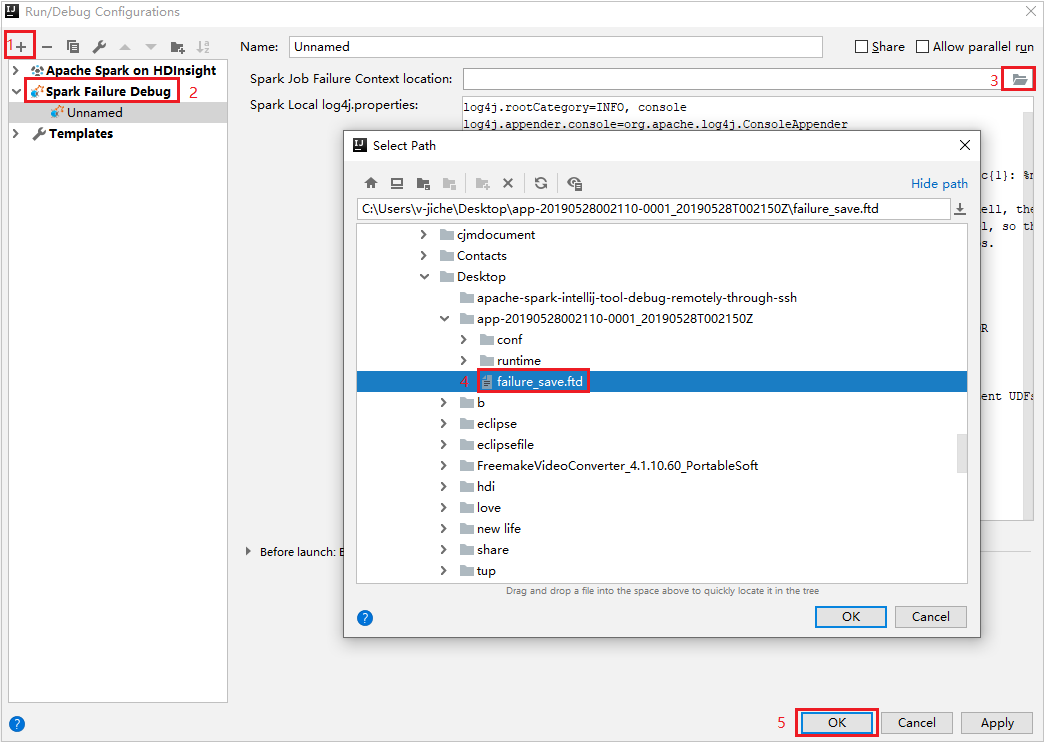
En IntelliJ IDEA, cree un archivo de configuración Spark Failure Debug (Depuración de errores de Spark) y seleccione el archivo FTD de los recursos de trabajo con errores que ha descargado antes para el campo Spark Job Failure Context location (Ubicación del contexto de error del trabajo de Spark).
Haga clic en el botón de ejecución local en la barra de herramientas; el error se mostrará en la ventana de ejecución.
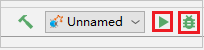
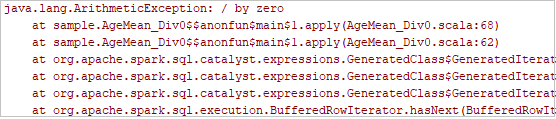
Establezca el punto de interrupción como se indica en el registro y, después, haga clic en el botón depuración local para realizar la depuración local como en los proyectos normales de Scala o Java en IntelliJ.
Después de la depuración, si el proyecto se completa de forma correcta, puede volver a enviar el trabajo con error al clúster de Spark en HDInsight.
Pasos siguientes
Escenarios
- Apache Spark con BI: Análisis de datos interactivos con Spark en HDInsight con las herramientas de BI
- Apache Spark con Machine Learning: uso de Apache Spark en HDInsight para analizar la temperatura de edificios con los datos del sistema de acondicionamiento de aire
- Apache Spark con Machine Learning: uso de Spark en HDInsight para predecir los resultados de la inspección de alimentos
- Análisis de registros de un sitio web mediante Apache Spark en HDInsight
Creación y ejecución de aplicaciones
- Crear una aplicación independiente con Scala
- Ejecución de trabajos de forma remota en un clúster de Apache Spark mediante Apache Livy
Herramientas y extensiones
- Uso de Azure Toolkit for IntelliJ con el fin de crear aplicaciones Apache Spark para un clúster de HDInsight
- Uso de Azure Toolkit for IntelliJ para depurar de forma remota aplicaciones de Apache Spark mediante VPN
- Uso de las herramientas de HDInsight de Azure Toolkit for Eclipse con el fin de crear aplicaciones Apache Spark
- Uso de cuadernos de Apache Zeppelin con un clúster de Apache Spark en HDInsight
- Kernels para Jupyter Notebook en clústeres Azure Spark en Azure HDInsight
- Uso de paquetes externos con cuadernos de Jupyter Notebook
- Instalación de un cuaderno de Jupyter Notebook en el equipo y conexión al clúster de Apache Spark en HDInsight de Azure