Depuración de trabajos de Apache Spark que se ejecutan en Azure HDInsight
En este artículo, aprenderá a realizar un seguimiento de trabajos de Apache Spark que se ejecutan en clústeres de HDInsight y a depurarlos. Depure con la interfaz de usuario de YARN de Apache Hadoop, la interfaz de usuario de Spark y el servidor de historial de Spark. Se inicia un trabajo de Spark mediante un cuaderno disponible en el clúster de Spark, Machine Learning: Predictive analysis on food inspection data using MLLib (Aprendizaje automático: análisis predictivo en datos de inspección de alimentos con MLLib). Siga estos pasos para realizar el seguimiento de una aplicación que haya enviado mediante cualquier otro enfoque, por ejemplo, spark-submit.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Un clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure.
Debería haber iniciado la ejecución del cuaderno, Machine learning: Predictive analysis on food inspection data using MLLib (Aprendizaje automático: análisis predictivo en datos de inspección de alimentos con MLLib). Para obtener instrucciones sobre cómo ejecutar este cuaderno, siga el vínculo.
Seguimiento de una aplicación en la interfaz de usuario de YARN
Inicie la interfaz de usuario de YARN. Seleccione Yarn en Paneles de clúster.
Sugerencia
También puede iniciar la interfaz de usuario de YARN desde la de Ambari. Para iniciar la interfaz de usuario de Ambari, seleccione Inicio de Ambari en Paneles de clúster. En la interfaz de usuario de Ambari, vaya a YARN>Quick Links (Vínculos rápidos)> la instancia activa de Resource Manager >Resource Manager UI (Interfaz de usuario de Resource Manager).
Dado que se inició el trabajo de Spark mediante cuadernos de Jupyter Notebook, la aplicación se llama remotesparkmagics (el nombre de todas las aplicaciones que se inician desde los cuadernos). Seleccione el identificador de la aplicación, que se encuentra junto al nombre de la aplicación, para más información sobre el trabajo. Esta acción inicia la vista de la aplicación.
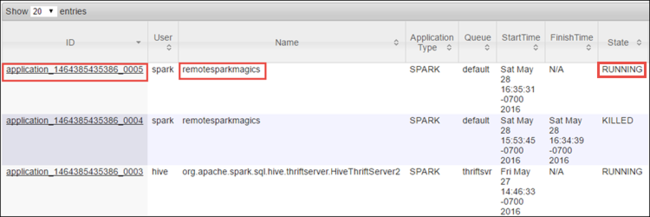
Para estas aplicaciones que se inician desde los cuadernos de Jupyter Notebook, el estado es siempre EN EJECUCIÓN hasta que se sale del cuaderno.
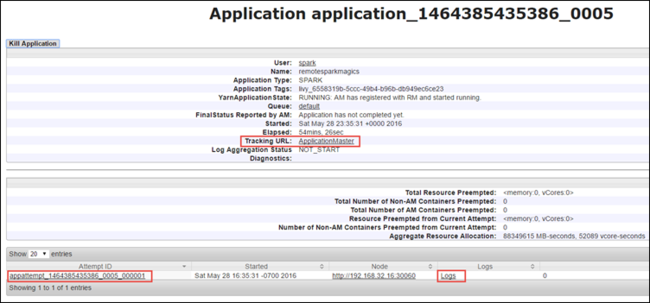
En la vista de la aplicación, puede explorar más en profundidad para averiguar los contenedores asociados con la aplicación y los registros (stdout y stderr). También puede iniciar la interfaz de usuario de Spark haciendo clic en el vínculo correspondiente a la Dirección URL de seguimiento, tal como se muestra a continuación.
Seguimiento de una aplicación en la interfaz de usuario de Spark
En la interfaz de usuario de Spark, puede explorar en profundidad los trabajos de Spark generados por la aplicación que ha iniciado anteriormente.
Para iniciar la interfaz de usuario de Spark, desde la vista de la aplicación, seleccione el vínculo en la Dirección URL de seguimiento, como se muestra en la captura de pantalla anterior. Puede ver todos los trabajos de Spark iniciados por la aplicación que se ejecuta en el cuaderno de Jupyter Notebook.
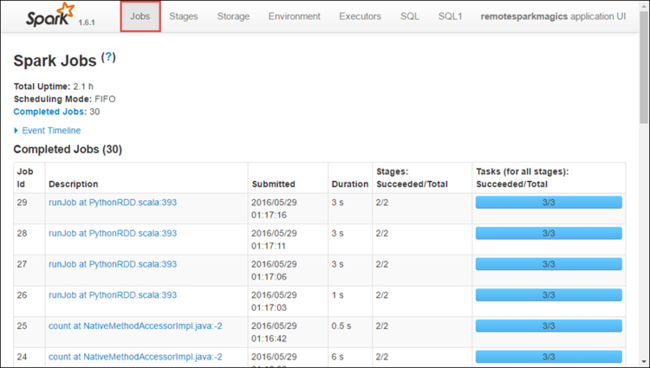
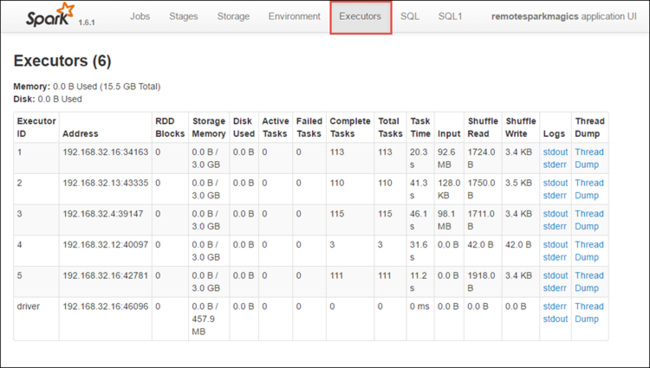
Seleccione la pestaña Executors (Ejecutores) para ver la información de procesamiento y almacenamiento de cada elemento de ejecución. También puede recuperar la pila de llamadas seleccionando el vínculo Thread Dump (Volcado de subprocesos).
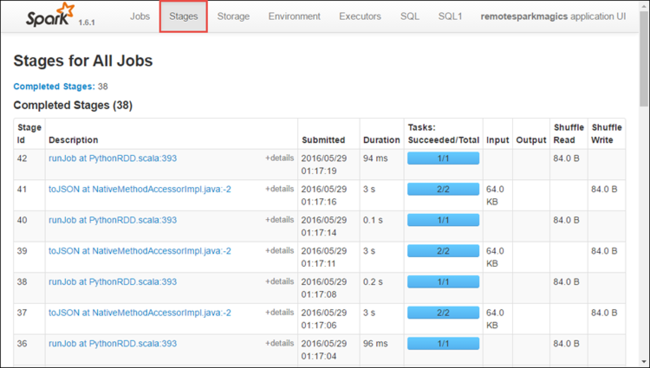
Seleccione la pestaña Stages (Fases) para ver las fases asociadas a la aplicación.
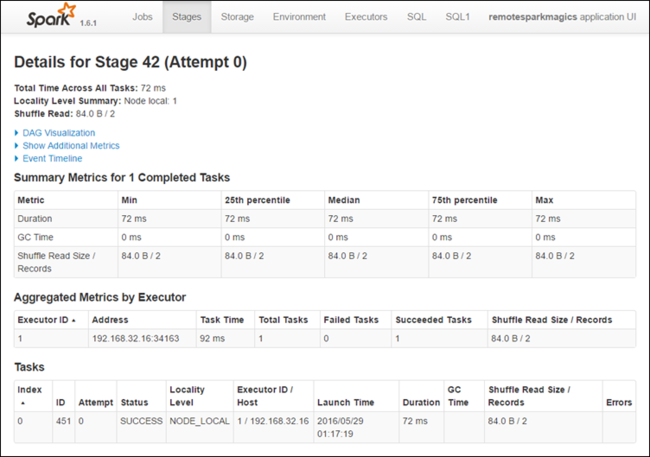
Cada fase puede tener varias tareas de las que puede ver las estadísticas de ejecución, como se muestra a continuación.
En la página de detalles de la fase, puede iniciar la visualización de DAG. Expanda el vínculo DAG Visualization (Visualización de DAG) en la parte superior de la página, como se muestra a continuación.
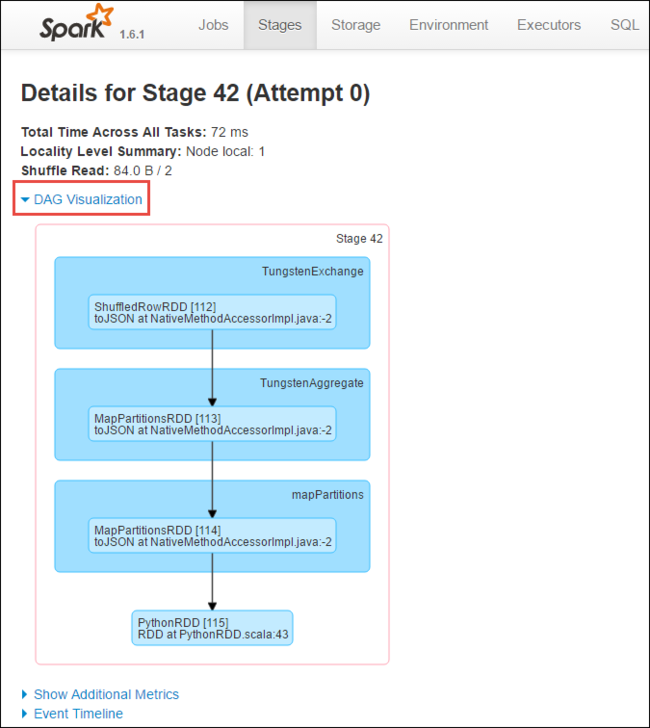
El DAG o grafo acíclico dirigido representa las distintas fases de la aplicación. Cada cuadro azul en el grafo representa una operación de Spark que se invoca desde la aplicación.
En la página de detalles de la fase, también puede iniciar la vista de escala de tiempo de la aplicación. Expanda el vínculo Event Timeline (Escala de tiempo del evento) en la parte superior de la página, como se muestra a continuación.
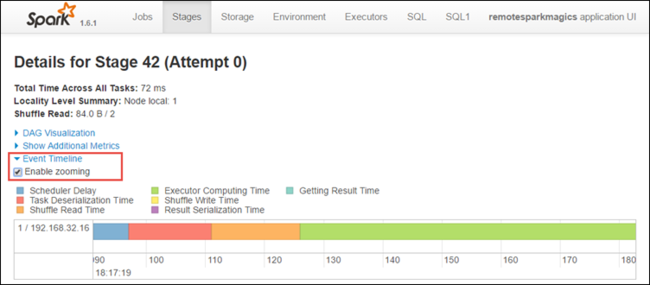
Esta imagen permite mostrar los eventos de Spark en forma de una escala de tiempo. La vista de la escala de tiempo está disponible en tres niveles: entre trabajos, dentro de un trabajo y dentro de una fase. La imagen anterior captura la vista de la escala de tiempo para una fase determinada.
Sugerencia
Si selecciona la casilla Enable zooming (Habilitar zoom), puede desplazarse a izquierda y derecha en la vista de escala de tiempo.
Otras pestañas de la interfaz de usuario de Spark proporcionan también información útil acerca de la instancia de Spark.
- Pestaña Almacenamiento: si la aplicación crea varios RDD, podrá encontrar información sobre estos en esta pestaña.
- Pestaña Environment (Entorno): esta pestaña proporciona información útil sobre la instancia de Spark, como:
- La versión de la escala
- El directorio de registro de eventos asociado con el clúster
- El número de núcleos del ejecutor de la aplicación
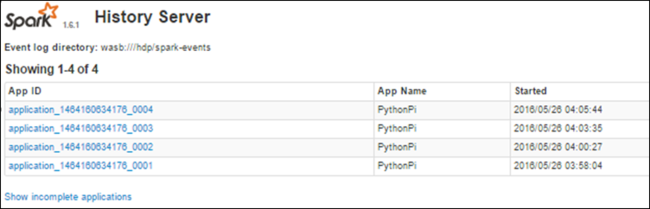
Búsqueda de información acerca de los trabajos completados con el servidor de historial de Spark
Cuando se completa un trabajo, se conserva la información sobre este en el servidor de historial de Spark.
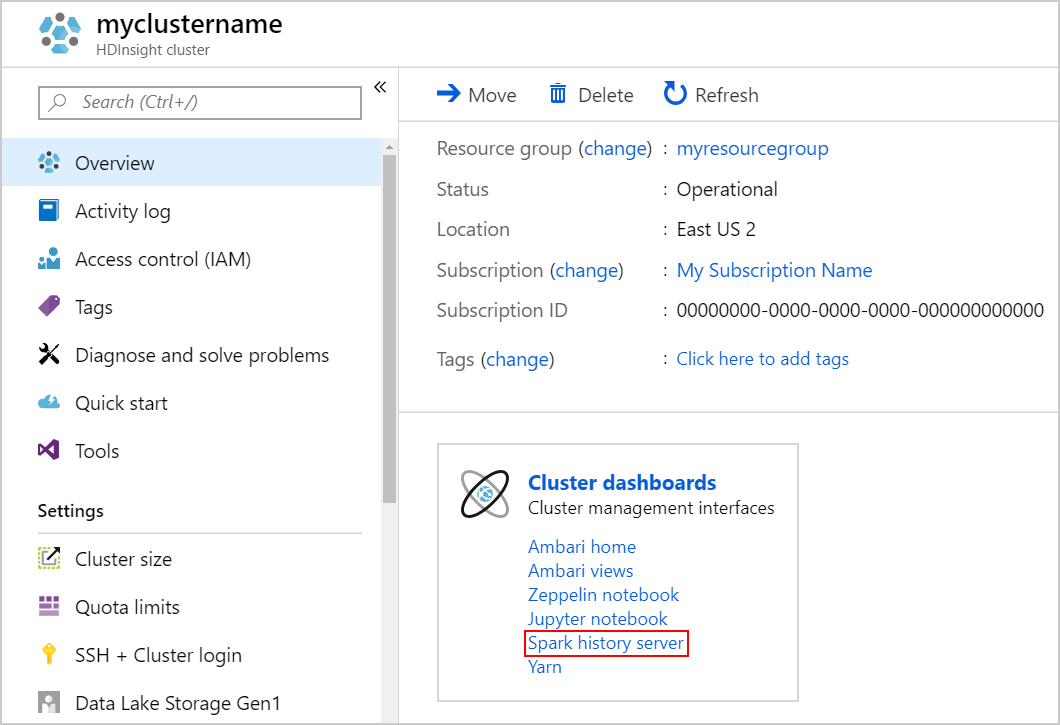
Para iniciar el servidor de historial de Spark, en la página Información general, seleccione Servidor de historial de Spark en Paneles de clúster.
Sugerencia
También puede iniciar la interfaz de usuario del servidor de historial de Spark desde la de Ambari. Para iniciar la interfaz de usuario de Ambari, en la hoja de información general, seleccione Inicio de Ambari en Paneles de clúster. En la interfaz de usuario de Ambari, vaya a Spark2>Quick Links (Vínculos rápidos) >Spark2 History Server UI (UI del servidor de historial de Spark).
Aparecerá una lista de todas las aplicaciones completadas. Seleccione un identificador de aplicación para explorar en profundidad una aplicación y obtener más información.