Uso de Azure Toolkit for IntelliJ para crear aplicaciones de Apache Spark para un clúster de HDInsight
En este artículo se muestra cómo desarrollar aplicaciones de Apache Spark en Azure HDInsight con el complemento Azure Toolkit para el IDE de IntelliJ. Azure HDInsight es un servicio de análisis administrado de código abierto en la nube. El servicio le permite usar marcos de código abierto como Hadoop, Apache Spark, Apache Hive y Apache Kafka.
Puede usar el complemento Azure Toolkit de varias maneras:
- Desarrollar y enviar una aplicación Spark con Scala en un clúster de Spark en HDInsight.
- Tener acceso a los recursos del clúster de Azure HDInsight Spark.
- Desarrollar y ejecutar localmente una aplicación Spark en Scala.
En este artículo aprenderá a:
- Usar el complemento Azure Toolkit for IntelliJ
- Desarrollar aplicaciones de Apache Spark
- Enviar una aplicación al clúster de Azure HDInsight
Requisitos previos
Un clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure. Solo se admiten clústeres de HDInsight en la nube pública, mientras que otros tipos de nube segura (por ejemplo, nubes gubernamentales) no se admiten.
Kit de desarrollo de Oracle Java. En este artículo se usa la versión 8.0.202 de Java.
IntelliJ IDEA. En este artículo se usa IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Consulte Instalación de Azure Toolkit for IntelliJ.
Instale el complemento de Scala para IntelliJ IDEA.
Pasos de instalación del complemento Scala:
Abra IntelliJ IDEA.
En la pantalla de bienvenida, vaya a Configure>Plugins (Configurar > Complementos) para abrir la ventana Plugins (Complementos).
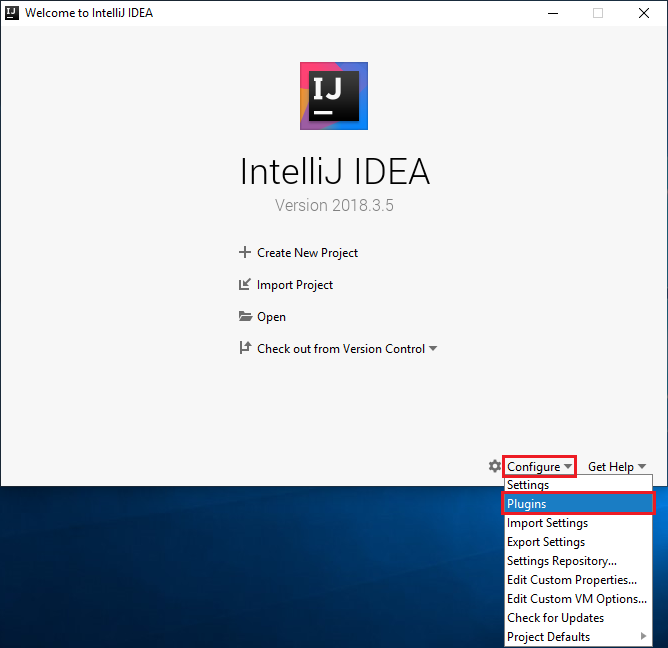
Seleccione Install (Instalar) para el complemento de Scala que se presenta en la nueva ventana.
Después de que el complemento se instale correctamente, debe reiniciar el IDE.
Creación de una aplicación Spark en Scala para un clúster de HDInsight Spark
Inicie IntelliJ IDEA y seleccione Create New Project (Crear proyecto) para abrir la ventana New Project (Nuevo proyecto).
Seleccione Azure Spark/HDInsight en el panel izquierdo.
Seleccione Spark Project (Scala) (Proyecto de Spark [Scala]) en la ventana principal.
En la lista desplegable Build tool (Herramienta de compilación), seleccione una de las siguientes opciones:
Maven: para agregar compatibilidad con el asistente para la creación de proyectos de Scala.
SBT para administrar las dependencias y compilar el proyecto de Scala.
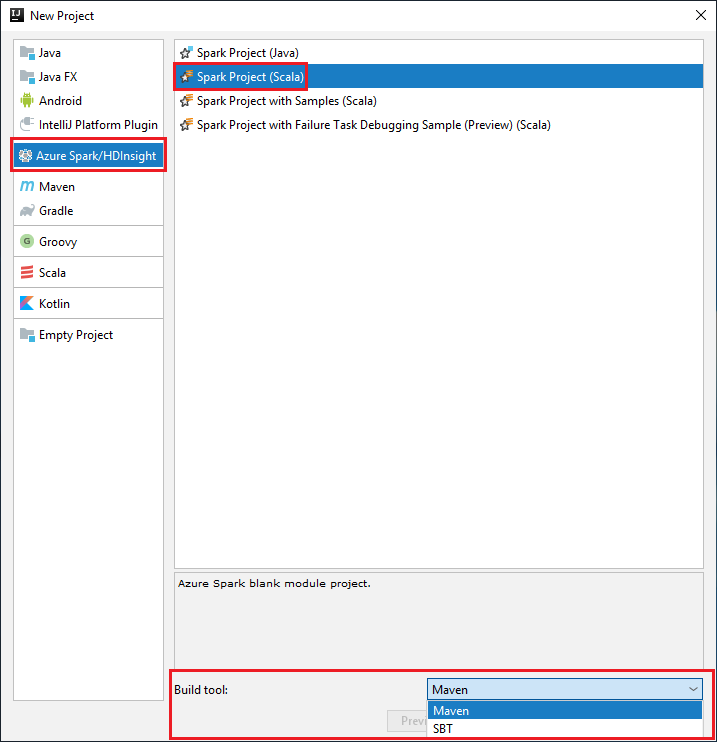
Seleccione Siguiente.
En la ventana New Project (Nuevo proyecto), proporcione la siguiente información:
Propiedad Descripción Nombre de proyecto Escriba un nombre. En este artículo se usa myApp.Ubicación del proyecto Escriba la ubicación para guardar el proyecto. Project SDK (SDK del proyecto) Este campo puede estar en blanco la primera vez que se usa IDEA. Seleccione New... (Nuevo...) y vaya a su JDK. Versión de Spark El asistente de creación integra la versión adecuada de los SDK de Spark y Scala. Si la versión del clúster de Spark es anterior a 2.0, seleccione Spark 1.x. De lo contrario, seleccione Spark2.x. En este ejemplo se usa Spark 2.3.0 (Scala 2.11.8) . 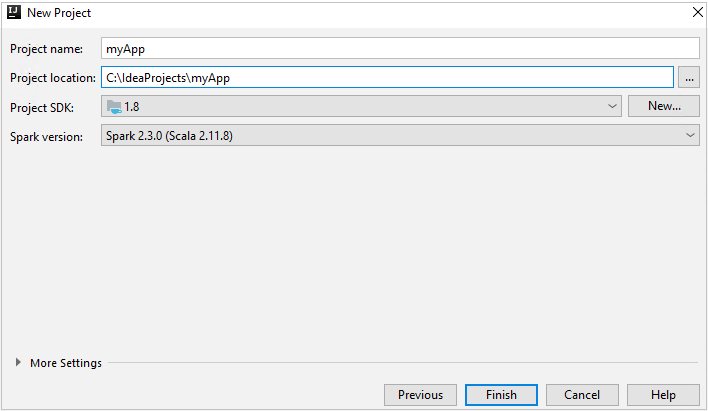
Seleccione Finalizar. El proyecto puede tardar unos minutos en estar disponible.
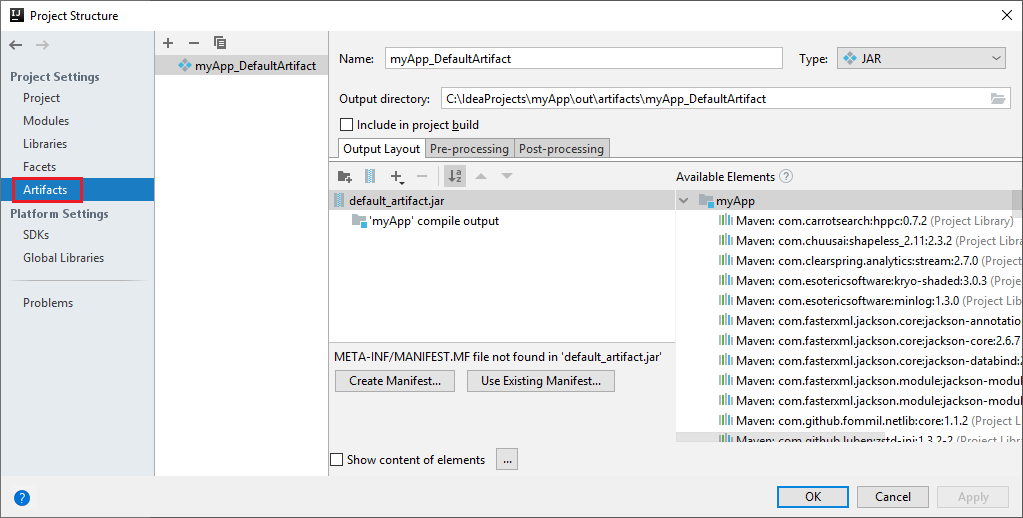
El proyecto de Spark crea automáticamente un artefacto. Para ver el artefacto, siga estos pasos:
a. En la barra de menús, vaya a Archivo>Estructura del proyecto... .
b. En la ventana Estructura del proyecto, seleccione Artefactos.
c. Seleccione Cancelar después de ver el artefacto.
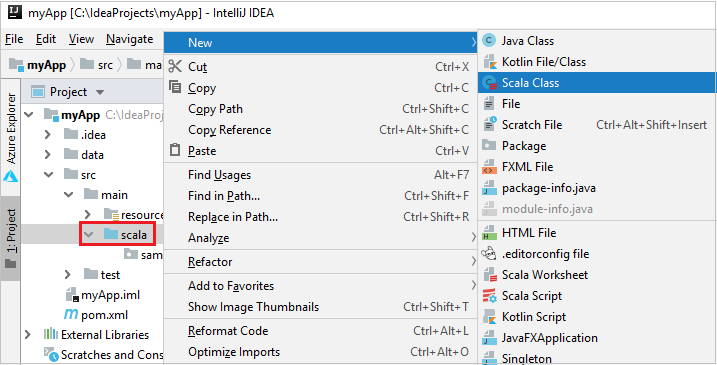
Agregue el código fuente de aplicación mediante los siguientes pasos:
a. En Proyecto, vaya a myApp>src>main>scala.
b. Haga clic con el botón derecho en scala, y, a continuación, vaya a Nuevo>Clase Scala.
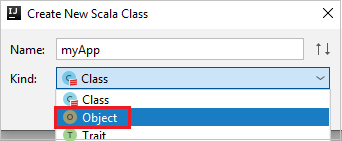
c. En el cuadro de diálogo Crear nueva clase Scala, proporcione un nombre, seleccione Objeto en la lista desplegable Variante y seleccione Aceptar.
d. A continuación, el archivo myApp.scala se abre en la vista principal. Reemplace el código predeterminado por el código encontrado a continuación:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }El código lee los datos de HVAC.csv (disponible en todos los clústeres de HDInsight Spark), recupera las filas que solo tienen un dígito en la séptima columna del archivo CSV y escribe la salida en
/HVACOuten el contenedor de almacenamiento predeterminado para el clúster.
Conéctese a su clúster de HDInsight
El usuario puede iniciar sesión en la suscripción a Azure o vincular un clúster de HDInsight. Use el nombre de usuario y la contraseña de Ambari o credenciales unidas a un dominio para conectarse al clúster de HDInsight.
Inicie sesión en la suscripción de Azure
En la barra de menús, vaya a Ver>Ventanas de herramientas>Azure Explorer.
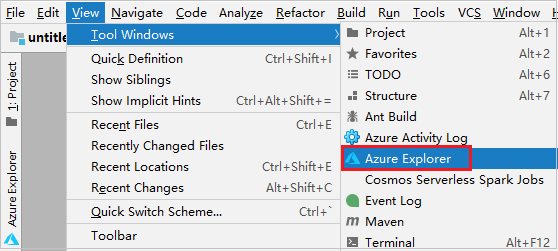
En Azure Explorer, haga clic con el botón derecho en el nodo Azure y después seleccione Iniciar sesión.
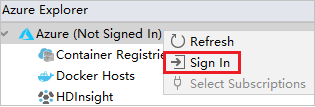
En el cuadro de diálogo de inicio de sesión en Azure, seleccione Inicio de sesión del dispositivo y, a continuación, Iniciar sesión.
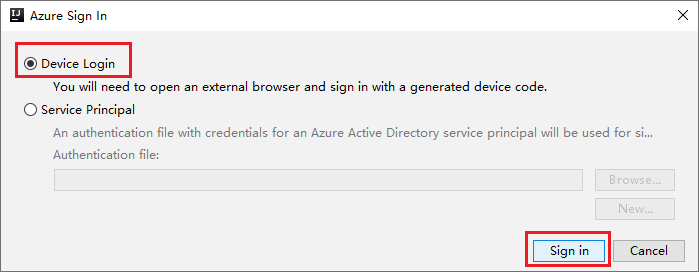
En el cuadro de diálogo Inicio de sesión del dispositivo de Azure, haga clic en Copiar y abrir.
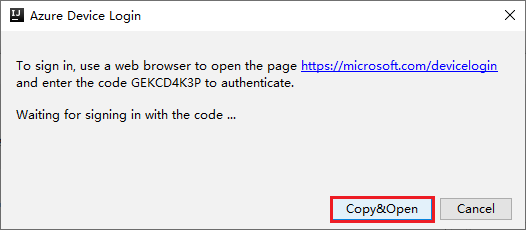
En la interfaz del explorador, pegue el código y, a continuación, haga clic en Siguiente.
Escriba sus credenciales de Azure y, a continuación, cierre el explorador.
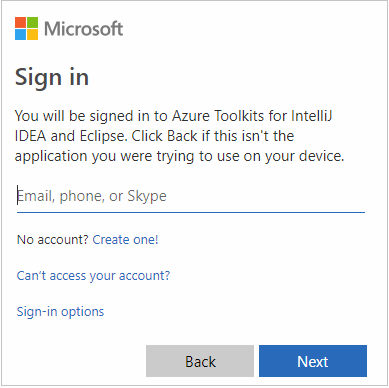
Cuando haya iniciado sesión, en el cuadro de diálogo Select Subscriptions (Seleccionar suscripciones) se enumeran todas las suscripciones de Azure asociadas a las credenciales. Seleccione su suscripción y luego seleccione el botón Seleccionar.
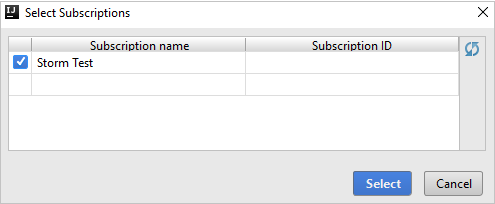
En Azure Explorer, expanda HDInsight para ver los clústeres de HDInsight Spark de sus suscripciones.
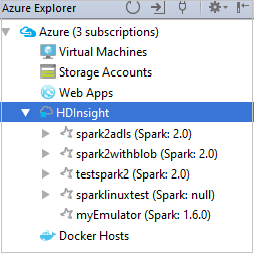
Para ver los recursos (por ejemplo, las cuentas de almacenamiento) asociados al clúster, puede expandir un nodo de nombre de clúster.
Vinculación de un clúster
Puede vincular un clúster de HDInsight mediante el nombre de usuario administrado de Apache Ambari. De forma similar, para un clúster de HDInsight unido a un dominio, puede vincular con el dominio y el nombre de usuario, como user1@contoso.com. También puede vincular el clúster del servicio de Livy.
En la barra de menús, vaya a Ver>Ventanas de herramientas>Azure Explorer.
En Azure Explorer, haga clic con el botón derecho en el nodo HDInsight y, a continuación, seleccione Vincular un clúster.
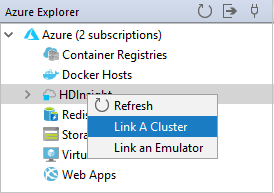
Las opciones disponibles en la ventana Vincular un clúster variarán dependiendo del valor que seleccione en la lista desplegable Tipo de recurso de vínculo. Escriba estos valores y, a continuación, seleccione Aceptar.
Clúster de HDInsight
Propiedad Value Tipo de recurso de vínculo Seleccione Clúster de HDInsight en la lista desplegable. Nombre o dirección URL del clúster Escriba el nombre del clúster. Tipo de autenticación Dejar como Autenticación básica Nombre de usuario Escriba el nombre de usuario del clúster, el valor predeterminado es admin. Contraseña Escriba la contraseña del nombre de usuario. 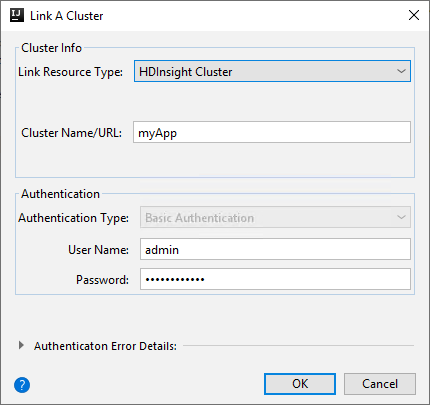
Livy Service
Propiedad Value Tipo de recurso de vínculo Seleccione Livy Service en la lista desplegable. Punto de conexión de Livy Escribir punto de conexión de Livy Cluster Name Escriba el nombre del clúster. Punto de conexión de Yarn Opcional. Tipo de autenticación Dejar como Autenticación básica Nombre de usuario Escriba el nombre de usuario del clúster, el valor predeterminado es admin. Contraseña Escriba la contraseña del nombre de usuario. 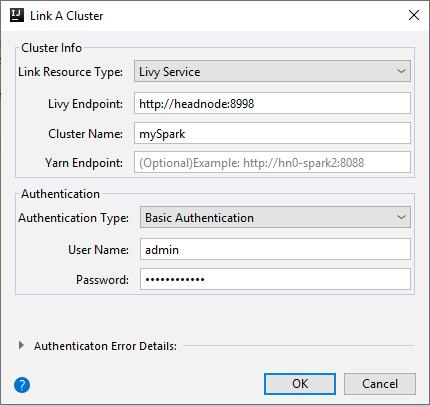
Puede ver su clúster vinculado en el nodo HDInsight.
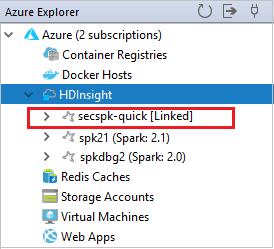
También puede desvincular un clúster de Azure Explorer.
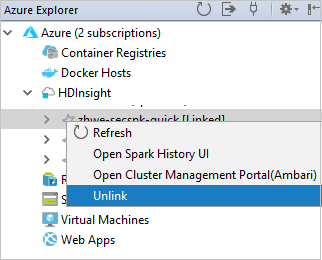
Ejecución de una aplicación Spark en Scala en un clúster de HDInsight Spark
Después de crear una aplicación de Scala, puede enviarla al clúster.
En el proyecto, vaya a myApp>src>main>scala>myApp. Haga clic con el botón derecho en myApp y seleccione Enviar aplicación Spark (probablemente estará en la parte inferior de la lista).
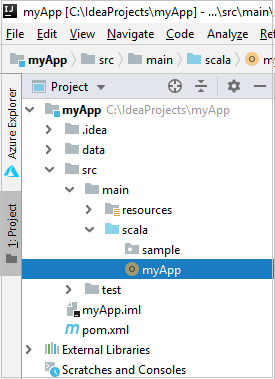
En el cuadro de diálogo Enviar aplicación Spark, seleccione 1. Spark en HDInsight.
En la ventana Editar configuración, proporcione los valores siguientes y, a continuación, seleccione Aceptar:
Propiedad Value Clústeres de Spark (solo Linux) Seleccione el clúster de HDInsight Spark en el que quiere ejecutar la aplicación. Seleccione un artefacto para enviarlo Deje la configuración predeterminada. Nombre de clase principal el valor predeterminado es la clase principal del archivo seleccionado. Puede cambiar la clase si selecciona los puntos suspensivos ( ... ) y elige otra clase. Configuraciones del trabajo Puede cambiar las claves o valores predeterminados. Para más información, consulte API de REST de Apache Livy. Argumentos de la línea de comandos Puede especificar los argumentos divididos por un espacio para la clase principal, si es necesario. Archivos jar a los que se hace referencia y archivos a los que se hace referencia puede escribir las rutas de acceso de los archivos y los Jar a los que se hace referencia, si los hubiera. También puede examinar archivos en el sistema de archivos virtual de Azure, que actualmente solo admite el clúster de ADLS Gen 2. Para obtener más información: Apache Spark Configuration (Configuración de Apache Spark). Consulte también cómo cargar recursos en un clúster. Almacenamiento de carga del trabajo Expanda para mostrar opciones adicionales. Tipo de almacenamiento Seleccione la opción para usar Azure Blob para cargar en la lista desplegable. Cuenta de almacenamiento Escriba su cuenta de Storage. Clave de almacenamiento Escriba su clave de almacenamiento. Contenedor de almacenamiento Seleccione su contenedor de almacenamiento en la lista desplegable una vez que se hayan escrito Cuenta de Storage y Clave de almacenamiento. 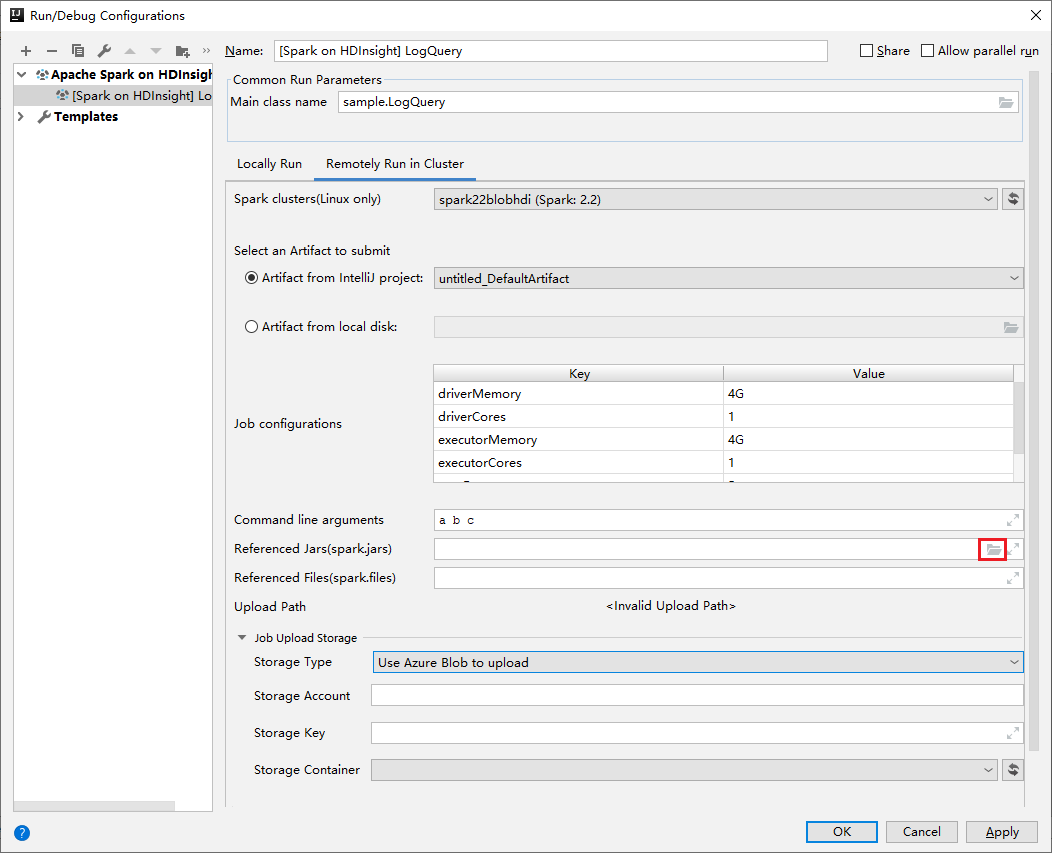
Seleccione SparkJobRun para enviar el proyecto para el clúster seleccionado. La pestaña Remote Spark Job in Cluster (Trabajo de Spark remoto en clúster) muestra el progreso de la ejecución del trabajo en la parte inferior. Puede detener la aplicación si hace clic en el botón rojo.
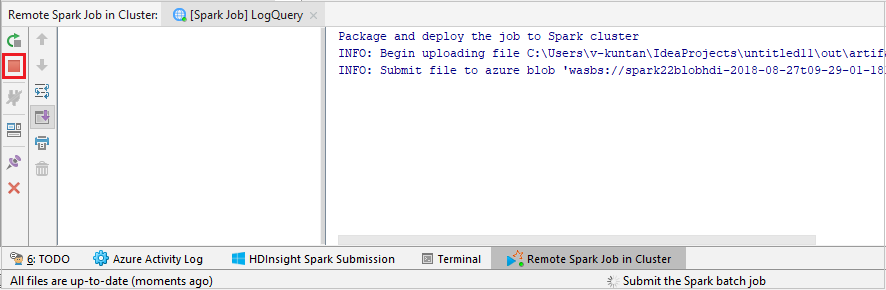
Depuración de aplicaciones Apache Spark de forma local o remota en un clúster de HDInsight
También se recomienda otra manera de enviar la aplicación Spark al clúster. Puede hacerlo estableciendo los parámetros del IDE de configuraciones de ejecución o depuración. Consulte Depuración de aplicaciones de Apache Spark de forma local o remota en un clúster de HDInsight con Azure Toolkit for IntelliJ mediante SSH.
Acceso y administración de clústeres de HDInsight Spark mediante el uso del kit de herramientas de Azure para IntelliJ
Puede realizar varias operaciones mediante Azure Toolkit for IntelliJ. La mayoría de las operaciones se inician desde Azure Explorer. En la barra de menús, vaya a Ver>Ventanas de herramientas>Azure Explorer.
Acceso a la vista de trabajo
En Azure Explorer, vaya a HDInsight><Su clúster >>Trabajos.
En el panel derecho, la pestaña Spark Job View (Vista de trabajos de Spark) muestra todas las aplicaciones que se ejecutaron en el clúster. Seleccione el nombre de la aplicación para la que desea ver más detalles.
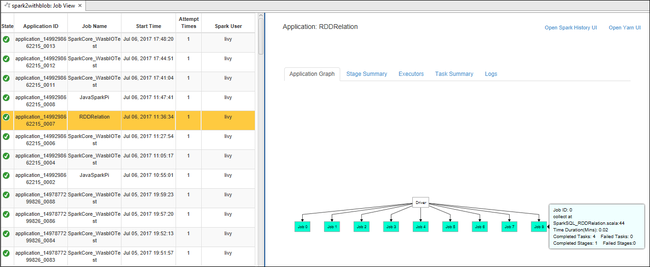
Para mostrar información básica del trabajo de ejecución, mantenga el mouse sobre el gráfico del trabajo. Para ver el gráfico de fases y la información que todo trabajo genera, seleccione un nodo del gráfico del trabajo.
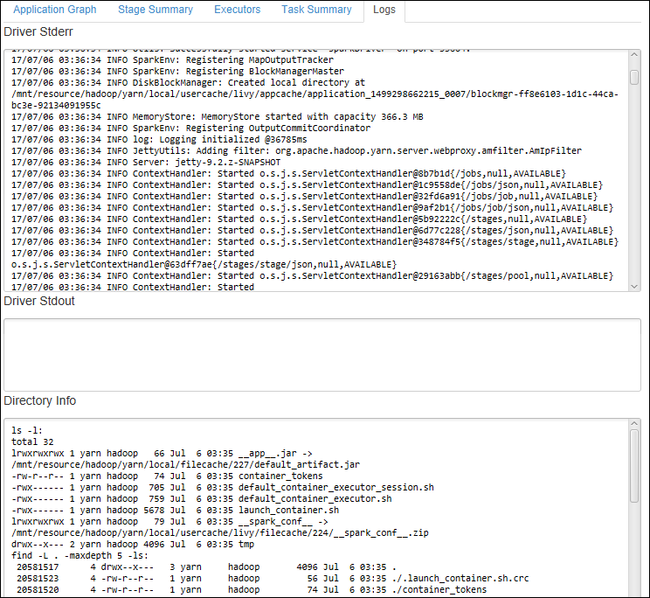
Para ver registros usados con frecuencia, como Driver Stderr, Driver Stdout y Directory Info, seleccione la pestaña Registro.
Puede ver la interfaz de usuario del historial de Spark y la interfaz de usuario de YARN (en el nivel de aplicación). Seleccione un enlace en la parte superior de la ventana.
Acceso al servidor de historial de Spark
En Azure Explorer, expanda HDInsight, haga clic con el botón derecho en el nombre del clúster de Spark y seleccione Abrir IU de historial de Spark.
Cuando se le solicite, escriba las credenciales de administrador del clúster, que especificó al configurar el clúster.
En el panel del servidor de historial de Spark, puede usar el nombre de aplicación para buscar la aplicación que acaba de terminar de ejecutar. En el código anterior, se establece el nombre de la aplicación mediante
val conf = new SparkConf().setAppName("myApp"). El nombre de la aplicación de Spark es myApp.
Inicio del portal de Ambari
En Azure Explorer, expanda HDInsight, haga clic con el botón derecho en el nombre del clúster de Spark y seleccione Abrir el portal de administración de clústeres (Ambari) .
Cuando se le pida, escriba las credenciales de administrador para el clúster. Estas son las credenciales que especificó durante el proceso de configuración de clúster.
Administración de suscripciones de Azure
De forma predeterminada, el kit de herramientas de Azure para IntelliJ enumera los clústeres de Spark de todas las suscripciones de Azure. Si es necesario, puede especificar las suscripciones a las que desea tener acceso.
En Azure Explorer, haga clic con el botón derecho en el nodo raíz de Azure y seleccione Seleccionar suscripciones.
En la ventana Seleccionar suscripciones, desactive las casillas situadas junto a las suscripciones a las que no desea tener acceso y seleccione Cerrar.
Consola de Spark
Puede ejecutar la consola local de Spark (Scala) o la consola de sesión interactiva de Spark Livy (Scala).
Consola local de Spark (Scala)
Asegúrese de que cumple el requisito previo de WINUTILS.EXE.
En la barra de menús, vaya a Ejecutar>Editar configuraciones...
En la ventana Ejecutar/depurar configuraciones, en el panel izquierdo, vaya a Apache Spark en HDInsight>[Spark en HDInsight] myApp.
En la ventana principal, seleccione la pestaña
Locally Run.Proporcione los valores siguientes y seleccione Aceptar:
Propiedad Value Clase principal del trabajo el valor predeterminado es la clase principal del archivo seleccionado. Puede cambiar la clase si selecciona los puntos suspensivos ( ... ) y elige otra clase. Variables de entorno Asegúrese de que el valor de HADOOP_HOME sea correcto. Ubicación de WINUTILS.exe Asegúrese de que la ruta de acceso sea correcta. 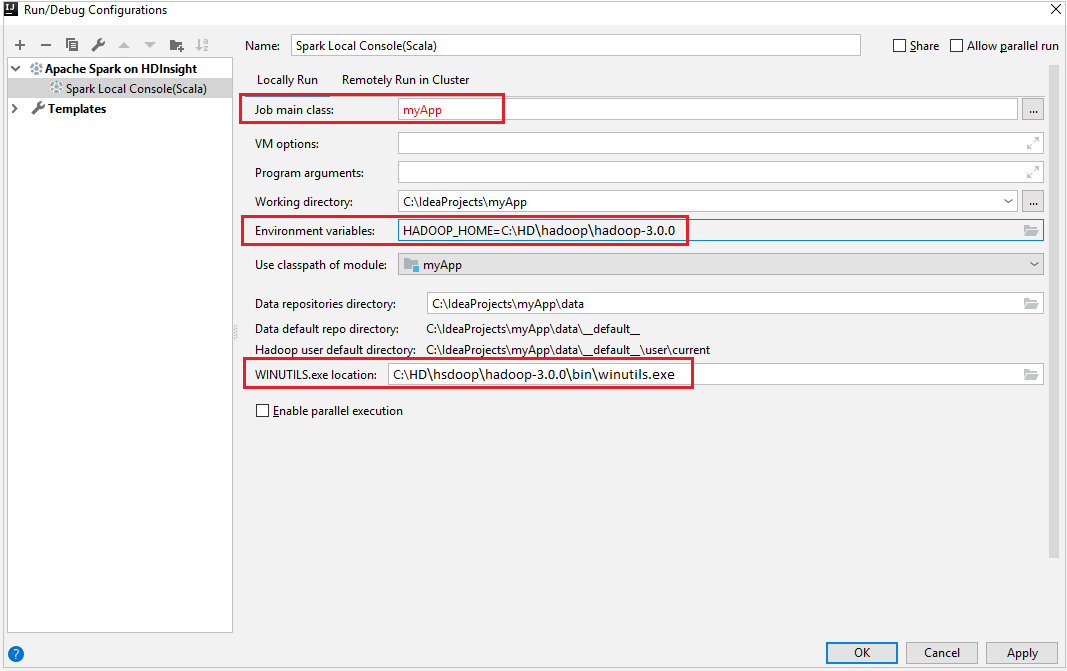
En el proyecto, vaya a myApp>src>main>scala>myApp.
En la barra de menús, vaya a Herramientas>Consola de Spark>Run Spark Local Console(Scala) (Ejecutar consola local de Spark (Scala)).
Pueden aparecer dos cuadros de diálogo para preguntarle si quiere corregir automáticamente las dependencias. Si es así, seleccione Autocorrección.
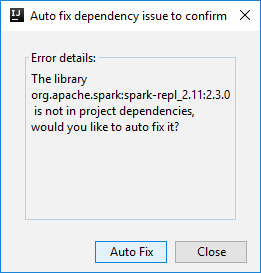
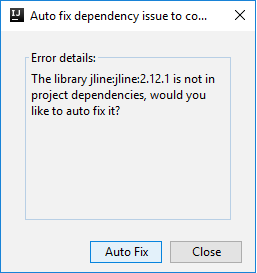
El aspecto de la consola debería ser similar al de la siguiente imagen. En la ventana de la consola, escriba
sc.appNamey presione CTRL + Entrar. Se muestra el resultado. Para detener la consola local, haga clic en el botón rojo.
Consola de sesión interactiva de Spark Livy (Scala)
En la barra de menús, vaya a Ejecutar>Editar configuraciones...
En la ventana Ejecutar/depurar configuraciones, en el panel izquierdo, vaya a Apache Spark en HDInsight>[Spark en HDInsight] myApp.
En la ventana principal, seleccione la pestaña
Remotely Run in Cluster.Proporcione los valores siguientes y seleccione Aceptar:
Propiedad Value Clústeres de Spark (solo Linux) Seleccione el clúster de HDInsight Spark en el que quiere ejecutar la aplicación. Nombre de clase principal el valor predeterminado es la clase principal del archivo seleccionado. Puede cambiar la clase si selecciona los puntos suspensivos ( ... ) y elige otra clase. 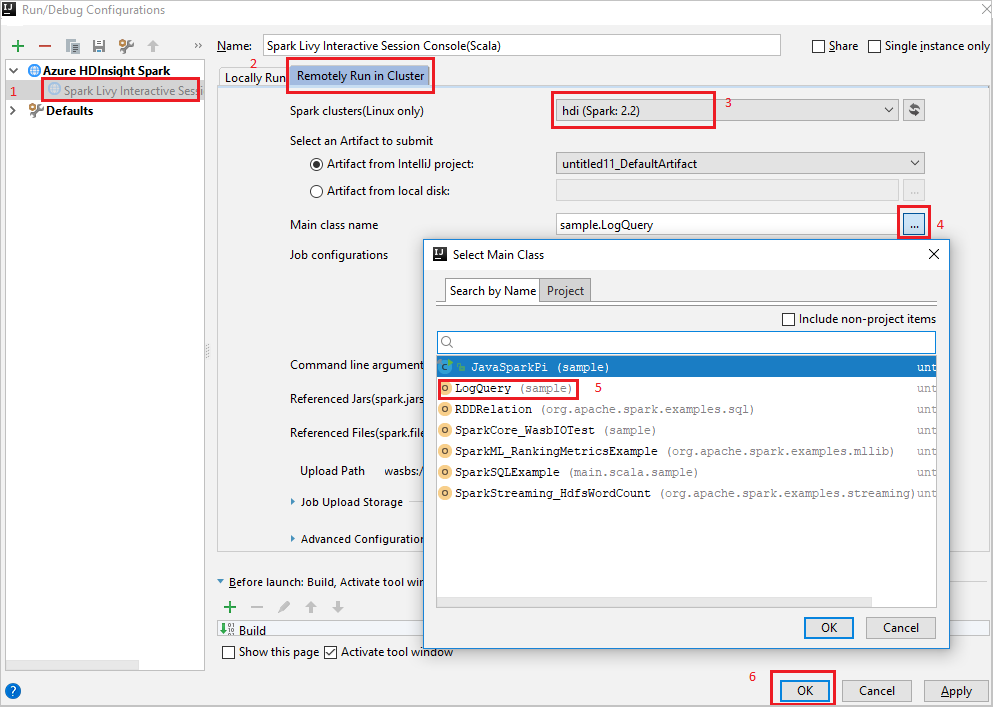
En el proyecto, vaya a myApp>src>main>scala>myApp.
En la barra de menús, vaya a Herramientas>Consola de Spark>Run Spark Livy Interactive Session Console(Scala) (Ejecutar consola interactiva de Spark Livy (Scala)).
El aspecto de la consola debería ser similar al de la siguiente imagen. En la ventana de la consola, escriba
sc.appNamey presione CTRL + Entrar. Se muestra el resultado. Para detener la consola local, haga clic en el botón rojo.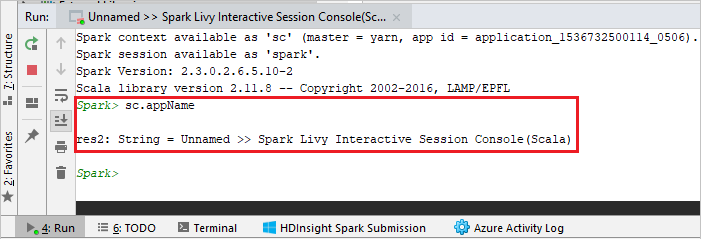
Envío de la selección a la consola de Spark
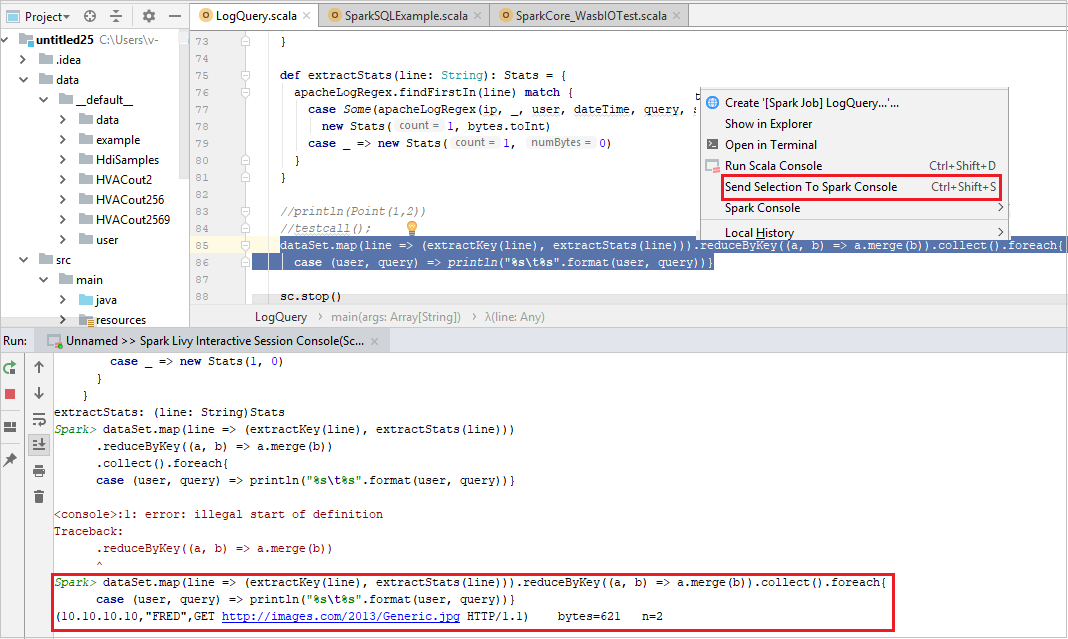
Resulta cómodo predecir el resultado del script mediante el envío de código a la consola local o a la consola de sesión interactiva de Livy (Scala). Puede resaltar parte del código en el archivo de Scala y hacer clic con el botón derecho en Send Selection To Spark Console (Enviar selección a consola de Spark). El código seleccionado se envía a la consola. El resultado se muestra después del código en la consola. La consola comprueba si hay errores.
Integración con HDInsight Identity Broker (HIB)
Conexión al clúster de HDInsight ESP con el agente de HDInsight Identity Broker (HIB)
Puede seguir los pasos normales para iniciar sesión en la suscripción de Azure para conectarse a su clúster de HDInsight ESP con el agente de HDInsight Identity Broker (HIB). Después de iniciar sesión, verá la lista de clústeres en Azure Explorer. Para conocer más instrucciones, consulte Conexión al clúster de HDInsight.
Ejecución de una aplicación Spark en Scala en un clúster de HDInsight Spark con el agente de HDInsight Identity Broker (HIB)
Puede seguir los pasos normales para enviar el trabajo a un clúster de HDInsight ESP con el agente de HDInsight Identity Broker (HIB). Consulte Ejecución de una aplicación Spark en Scala en un clúster de HDInsight Spark para más instrucciones.
Cargaremos los archivos necesarios en una carpeta denominada con su cuenta de inicio de sesión y podrá ver la ruta de acceso de carga en el archivo de configuración.

Consola de Spark en un clúster de HDInsight ESP con el agente de HDInsight Identity Broker (HIB)
Puede ejecutar Spark Local Console (Scala) o ejecutar Spark Livy Interactive Session Console (Scala) en un clúster de HDInsight ESP con el agente de HDInsight Identity Broker (HIB). Consulte Consola de Spark para obtener más instrucciones.
Nota
En el caso del clúster de HDInsight ESP con HDInsight Identity Broker (HIB), las opciones para vincular un clúster y depurar las aplicaciones de Apache Spark de forma remota no se admiten actualmente.
Rol de solo lectura
Cuando los usuarios envían trabajos a un clúster con el permiso de rol de solo lectura, se requieren credenciales de Ambari.
Vínculo de clúster desde menú contextual
Inicie sesión con la cuenta del rol de solo lectura.
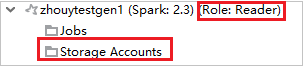
En Azure Explorer, expanda HDInsight para ver los clústeres de HDInsight de su suscripción. Los clústeres marcados como "Role:Reader" tienen únicamente permiso de solo lectura.
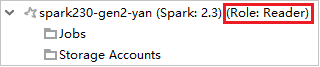
Haga clic derecho en el clúster con el permiso de rol de solo lectura. Seleccione Link this cluster (Vincular este clúster) en el menú contextual para vincular el clúster. Escriba el nombre de usuario y la contraseña de Ambari.
Si el clúster se vinculó correctamente, se actualizará HDInsight. La fase del clúster quedará vinculada.
Vínculo de clúster mediante la expansión del nodo de trabajos
Haga clic en el nodo Trabajos y aparecerá la ventana emergente Cluster Job Access Denied (Se denegó el acceso al trabajo del clúster).
Haga clic en Link this cluster (Vincular este clúster) para vincular el clúster.

Vínculo de clúster desde la ventana de configuraciones de ejecución o depuración
Cree una configuración de HDInsight. Luego, seleccione Remotely Run in Cluster (Ejecutar de forma remota en clúster).
Seleccione un clúster, que tiene permiso de rol de solo lectura para clústeres de Spark (solo Linux) . Aparece un mensaje de advertencia. Puede hacer clic en Link this cluster (Vincular este clúster) para vincular el clúster.
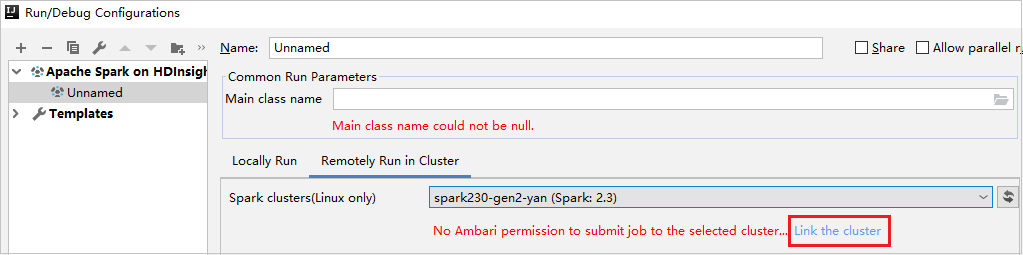
Visualización de cuentas de almacenamiento
Para los clústeres con permiso de rol de solo lectura, haga clic en el nodo Cuentas de almacenamiento y aparecerá la ventana emergente Storage Access Denied (Se denegó el acceso al almacenamiento). Seleccione Abrir Explorador de Azure Storage para abrir el explorador de Storage.

Para los clústeres vinculados, haga clic en el nodo Cuentas de almacenamiento y aparecerá la ventana emergente Storage Access Denied (Se denegó el acceso al almacenamiento). Puede hacer clic en Open Azure Storage (Abrir Azure Storage) para abrir el Explorador de Storage.

Conversión de las aplicaciones IntelliJ IDEA existentes para usar el kit de herramientas de Azure para IntelliJ
Puede convertir las aplicaciones Spark en Scala existentes creadas en IntelliJ IDEA para que sean compatibles con el kit de herramientas de Azure para IntelliJ. Esto le permitirá utilizar el complemento para enviar las aplicaciones a un clúster de HDInsight Spark.
Para una aplicación Spark en Scala existente creada con IntelliJ IDEA, abra el archivo
.imlasociado.En el nivel raíz, hay un elemento de module similar al siguiente texto:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Edite el elemento para agregar
UniqueKey="HDInsightTool"de forma que el elemento de module sea similar al siguiente texto:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Guarde los cambios. La aplicación ahora debe ser compatible con el kit de herramientas de Azure para IntelliJ. Puede comprobarlo si hace clic con el botón derecho en el nombre de proyecto en Proyecto. El menú emergente ahora debería tener la opción Submit Spark Application to HDInsight (Enviar aplicación Spark a HDInsight).
Limpieza de recursos
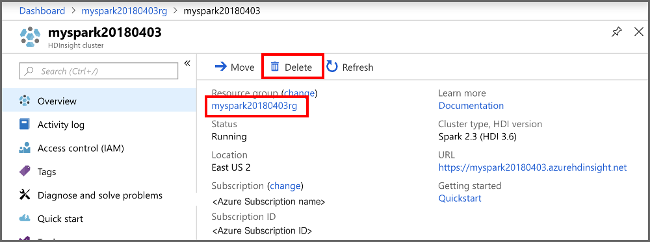
Si no va a seguir usando esta aplicación, elimine el clúster que creó mediante los siguientes pasos:
Inicie sesión en Azure Portal.
En el cuadro Búsqueda en la parte superior, escriba HDInsight.
Seleccione Clústeres de HDInsight en Servicios.
En la lista de clústeres de HDInsight que aparece, seleccione el botón ... situado junto al clúster que ha creado en este artículo.
Seleccione Eliminar. Seleccione Sí.
Errores y soluciones
Desmarque la carpeta src como Orígenes si recibe errores de compilación, tal y como se indica a continuación:
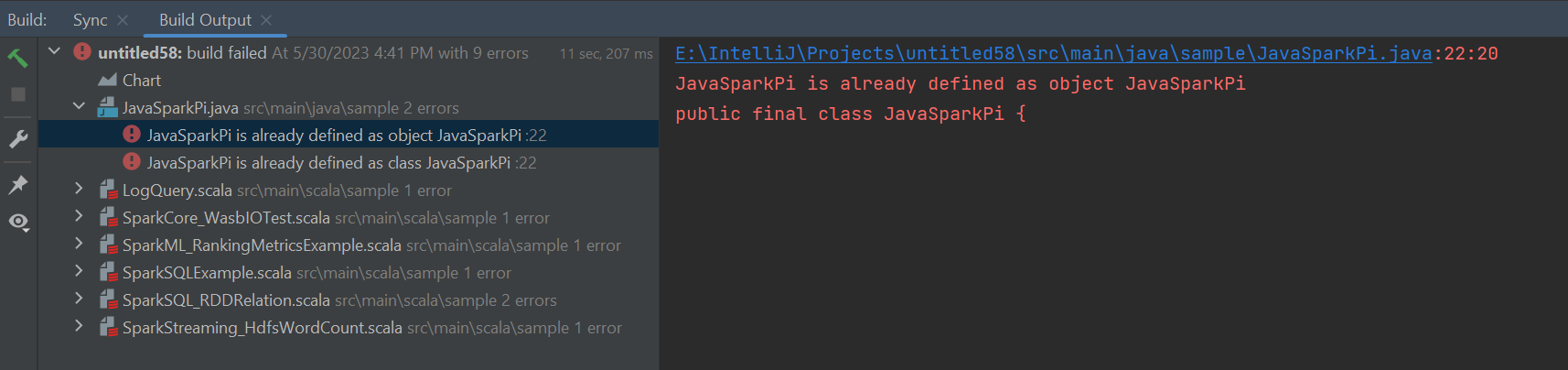
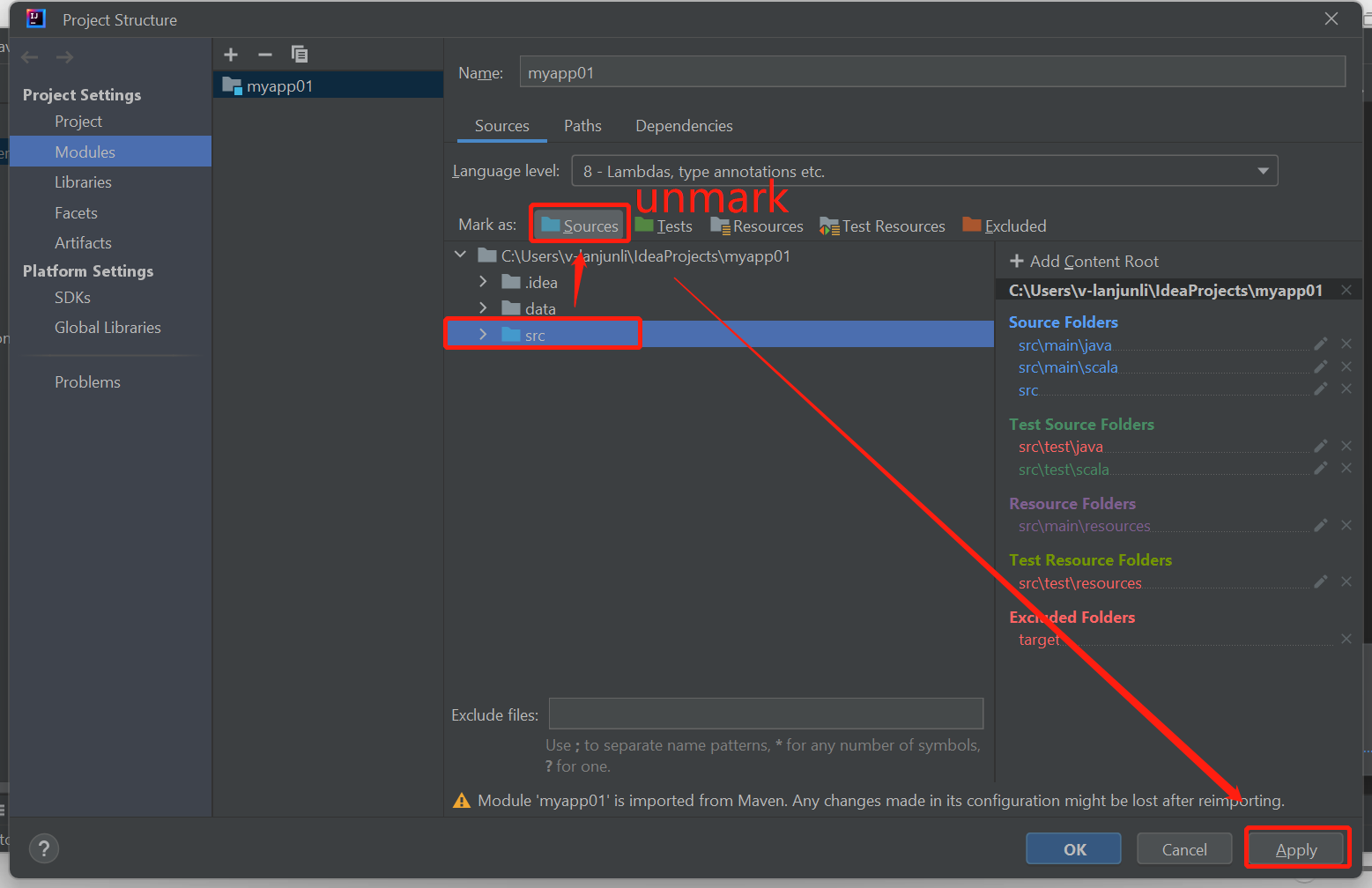
Desmarque la carpeta src como Orígenes para solucionar esta incidencia:
Vaya a Archivo y seleccione la estructura del proyecto.
Seleccione los módulos en Configuración del proyecto.
Seleccione el archivo src y desmárquelo como Orígenes.
Haga clic en el botón Aplicar y, a continuación, haga clic en el botón Aceptar para cerrar el cuadro de diálogo.
Pasos siguientes
En este artículo, ha aprendido a usar el complemento Azure Toolkit for IntelliJ para desarrollar aplicaciones de Apache Spark escritas en Scala. Después, las ha enviado a un clúster de HDInsight Spark directamente desde el entorno de desarrollo integrado (IDE) de IntelliJ. En el siguiente artículo podrá ver cómo extraer en una herramienta de análisis de BI, como Power BI, los datos que registró en Apache Spark.