Uso de paquetes externos con cuadernos de Jupyter Notebook en clústeres de Apache Spark en HDInsight
Aprenda a configurar una instancia de Jupyter Notebook en clústeres de Apache Spark en HDInsight para usar paquetes maven externos de Apache aportados por la comunidad que no se incluyan listos para utilizarse en el clúster.
Puede buscar el repositorio de Maven para obtener una lista completa de los paquetes que están disponibles. También puede obtener una lista de paquetes disponibles de otras fuentes. Por ejemplo, dispone de la lista completa de los paquetes externos aportados por la comunidad en Spark Packages(Paquetes Spark).
En este artículo, aprenderá a utilizar el paquete spark-csv con Jupyter Notebook.
Requisitos previos
Un clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure.
Experiencia en el uso de Jupyter Notebooks con Spark en HDInsight. Para más información, consulte Carga de datos y ejecución de consultas en un clúster de Apache Spark en Azure HDInsight.
El esquema de URI para el almacenamiento principal de clústeres. Sería
wasb://para Azure Storage,abfs://para Azure Data Lake Storage Gen2. Si la transferencia segura está habilitada para Azure Storage o Data Lake Storage Gen2, el URI seríawasbs://oabfss://, respectivamente; consulte también Transferencia segura.
Uso de paquetes externos con cuadernos de Jupyter Notebook
Vaya a
https://CLUSTERNAME.azurehdinsight.net/jupyter, dondeCLUSTERNAMEes el nombre del clúster de Spark.Cree un nuevo notebook. Seleccione Nuevo y, a continuación, seleccione Spark.

Se crea y se abre un nuevo cuaderno con el nombre Untitled.pynb. Seleccione el nombre del cuaderno en la parte superior y escriba un nombre descriptivo.
Utilizará la instrucción mágica
%%configurepara configurar el cuaderno para usar un paquete externo. En los cuadernos que utilizan paquetes externos, asegúrese de invocar la instrucción mágica%%configureen la primera celda de código. Esto garantiza que el kernel se configure para utilizar el paquete antes de iniciar la sesión.Importante
Si se olvida de configurar el kernel en la primera celda, puede utilizar el parámetro
%%configurecon el parámetro-f, pero ello reiniciará la sesión y se perderá todo el trabajo.Versión de HDInsight Get-Help Para HDInsight 3.5 y HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}Para HDInsight 3.3 y HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }En el fragmento de código anterior, se esperan las coordenadas de Maven correspondientes al paquete externo de Maven Central Repository. En este fragmento de código,
com.databricks:spark-csv_2.11:1.5.0es la coordenada de Maven para el paquete spark-csv . Le mostramos cómo crear las coordenadas de un paquete.a. Busque el paquete en el repositorio de Maven. En este artículo, usaremos spark-csv.
b. En el repositorio, recopile los valores de GroupId, ArtifactId y Version. Asegúrese de que los valores recopilados coincidan con el clúster. En este caso, estamos usando un paquete de Scala 2.11 y Spark 1.5.0, pero quizás tenga que seleccionar versiones diferentes para la versión de Scala o Spark concreta del clúster. Puede averiguar la versión de Scala del clúster mediante la ejecución de
scala.util.Properties.versionStringen el kernel de Spark Jupyter o en el envío de Spark. Puede averiguar la versión de Spark del clúster mediante la ejecución desc.versionen Jupyter Notebooks.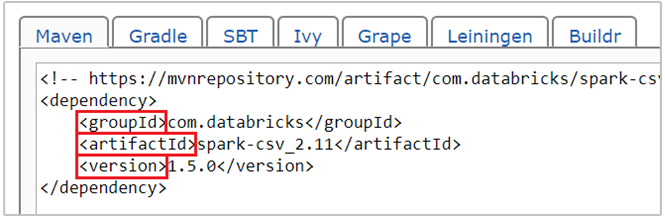
c. Concatene los tres valores separados por dos puntos ( : ).
com.databricks:spark-csv_2.11:1.5.0Ejecute la celda de código con la instrucción mágica
%%configure. De esta forma, se configurará la sesión de Livy subyacente para utilizar el paquete que facilitó. En las siguientes celdas del cuaderno, ya podrá usar el paquete como se muestra a continuación.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Para HDInsight 3.4 y versiones posteriores, debe usar este fragmento de código.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")A continuación, podrá ejecutar los fragmentos de código como se muestra seguidamente para ver los datos de la trama de datos que creó en el paso anterior.
df.show() df.select("Time").count()
Consulte también
Escenarios
- Apache Spark con BI: Análisis de datos interactivos con Spark en HDInsight con las herramientas de BI
- Apache Spark con Machine Learning: Uso de Spark en HDInsight para analizar la temperatura de un edificio mediante datos de HVAC
- Apache Spark con Machine Learning: uso de Spark en HDInsight para predecir los resultados de la inspección de alimentos
- Análisis de registros de un sitio web mediante Apache Spark en HDInsight
Creación y ejecución de aplicaciones
- Crear una aplicación independiente con Scala
- Ejecución de trabajos de forma remota en un clúster de Apache Spark mediante Apache Livy
Herramientas y extensiones
- Uso de paquetes externos de Python con cuadernos de Jupyter Notebook en clústeres de Apache Spark en HDInsight Linux
- Uso del complemento de herramientas de HDInsight para IntelliJ IDEA para crear y enviar aplicaciones de Spark Scala
- Use HDInsight Tools Plugin for IntelliJ IDEA to debug Apache Spark applications remotely (Uso del complemento de herramientas de HDInsight para IntelliJ IDEA para depurar aplicaciones de Apache Spark de forma remota)
- Uso de cuadernos de Apache Zeppelin con un clúster de Apache Spark en HDInsight
- Kernels disponible para Jupyter Notebook en clústeres Apache Spark para HDInsight
- Instalación de un cuaderno de Jupyter Notebook en el equipo y conexión al clúster de Apache Spark en HDInsight de Azure