Cómo generar inserciones con inferencia del modelo de Azure AI
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de inserciones con modelos implementados en la inferencia de modelos de Azure AI en los servicios de Azure AI.
Requisitos previos
Para usar modelos de inserción en la aplicación, necesita lo siguiente:
Suscripción a Azure. Si usa Modelos de GitHub, puede actualizar la experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a la inferencia de modelos de Azure AI si es su caso.
Recurso de Servicios de Azure AI. Para más información, vea Creación de un recurso de Servicios de Azure AI.
Dirección URL y clave del punto de conexión.
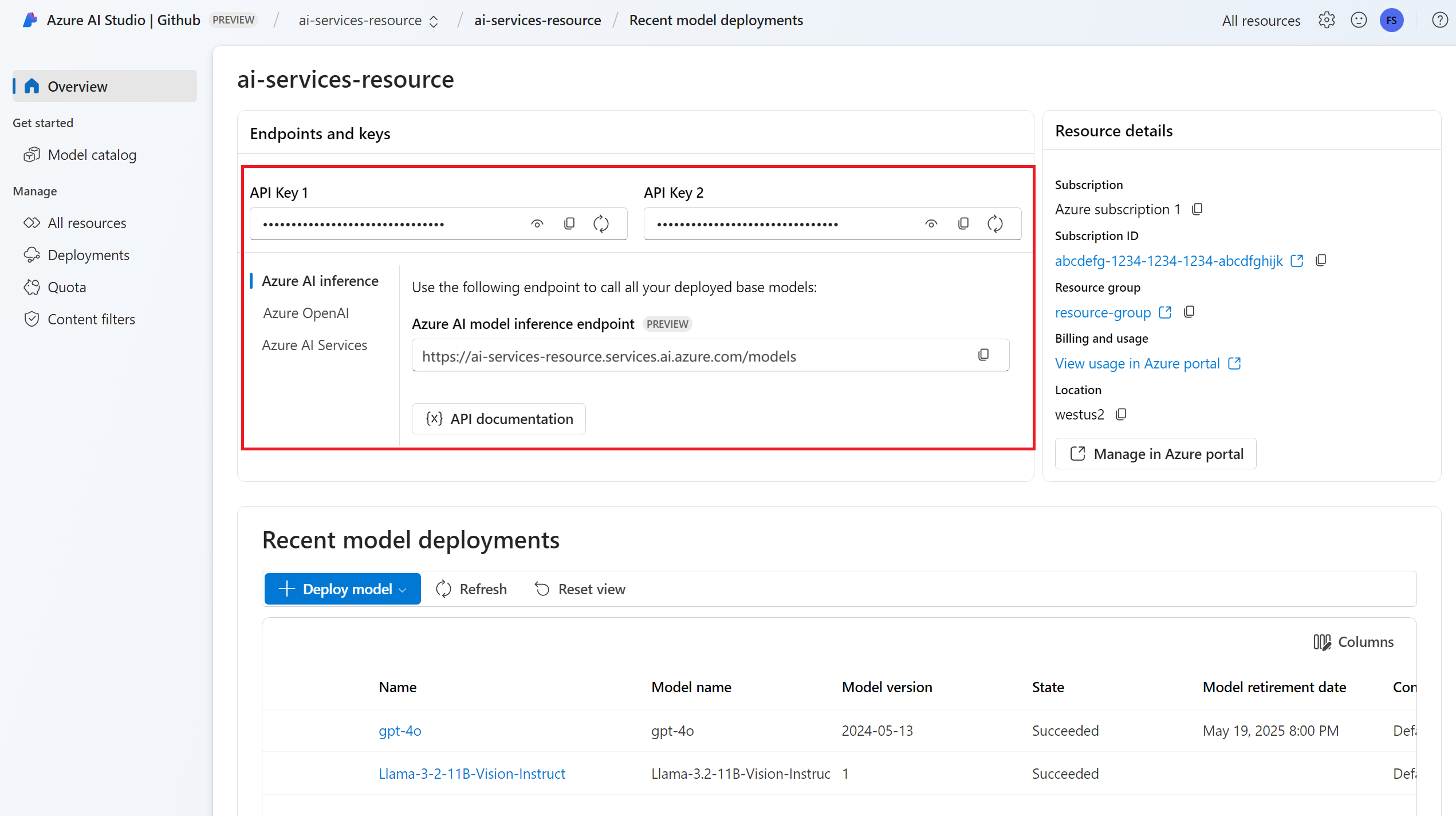

Implementación de modelo de inserciones. Si no tiene una lectura, lea Incorporación y configuración de modelos en los servicios de Azure AI para agregar un modelo de inserción al recurso.
Instale el paquete de inferencia de Azure AI con el siguiente comando:
pip install -U azure-ai-inferenceSugerencia
Más información sobre el Paquete de inferencia y referencia de Azure AI.
Uso de incrustaciones
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="text-embedding-3-small"
)
Si ha configurado el recurso para que admita Microsoft Entra ID, puede utilizar el siguiente fragmento de código para crear un cliente.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="text-embedding-3-small"
)
Creación de inserciones
Cree una solicitud de inserción para ver la salida del modelo.
response = model.embed(
input=["The ultimate answer to the question of life"],
)
Sugerencia
Al crear una solicitud, tenga en cuenta el límite de entrada del token para el modelo. Si necesita insertar partes más grandes del texto, necesitará una estrategia de fragmentación.
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Puede ser útil para calcular inserciones en lotes de entrada. El parámetro inputs puede ser una lista de cadenas, donde cada cadena es una entrada diferente. A su vez, la respuesta es una lista de inserciones, donde cada inserción corresponde a la entrada en la misma posición.
response = model.embed(
input=[
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
)
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Sugerencia
Al crear lotes de solicitud, tenga en cuenta el límite de lotes para cada uno de los modelos. La mayoría de los modelos tienen un límite de lotes de 1024.
Especificar dimensiones de inserción
Puede especificar el número de dimensiones para las inserciones. En el código de ejemplo siguiente se muestra cómo crear inserciones con 1024 dimensiones. Observe que no todos los modelos de inserción admiten que indique el número de dimensiones de la solicitud y, en esos casos, se devuelve un error 422.
response = model.embed(
input=["The ultimate answer to the question of life"],
dimensions=1024,
)
Creación de diferentes tipos de inserciones
Algunos modelos pueden generar múltiples inserciones para la misma entrada en función de cómo planee usarlos. Esta capacidad le permite recuperar inserciones más precisas para los patrones de RAG.
El siguiente ejemplo muestra cómo crear inserciones que se utilizan para crear una inserción para un documento que se almacenará en una base de datos vectorial:
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type=EmbeddingInputType.DOCUMENT,
)
Cuando trabaje en una consulta para recuperar un documento de este tipo, puede usar el siguiente fragmento de código para crear las inserciones para la consulta y maximizar el rendimiento de la recuperación.
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["What's the ultimate meaning of life?"],
input_type=EmbeddingInputType.QUERY,
)
Observe que no todos los modelos de inserción admiten que indique el tipo de entrada en la solicitud y, en esos casos, se devuelve un error 422. De forma predeterminada, se devuelven inserciones de tipo Text.
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de inserciones con modelos implementados en la inferencia de modelos de Azure AI en los servicios de Azure AI.
Requisitos previos
Para usar modelos de inserción en la aplicación, necesita lo siguiente:
Suscripción a Azure. Si usa Modelos de GitHub, puede actualizar la experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a la inferencia de modelos de Azure AI si es su caso.
Recurso de Servicios de Azure AI. Para más información, vea Creación de un recurso de Servicios de Azure AI.
Dirección URL y clave del punto de conexión.
Implementación de modelo de inserciones. Si no tiene una lectura, lea Incorporación y configuración de modelos en los servicios de Azure AI para agregar un modelo de inserción al recurso.
Instalar la biblioteca de Inferencia de Azure para JavaScript con el siguiente comando:
npm install @azure-rest/ai-inferenceSugerencia
Más información sobre el Paquete de inferencia y referencia de Azure AI.
Uso de incrustaciones
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL),
"text-embedding-3-small"
);
Si ha configurado el recurso para que admita Microsoft Entra ID, puede utilizar el siguiente fragmento de código para crear un cliente.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Creación de inserciones
Cree una solicitud de inserción para ver la salida del modelo.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
}
});
Sugerencia
Al crear una solicitud, tenga en cuenta el límite de entrada del token para el modelo. Si necesita insertar partes más grandes del texto, necesitará una estrategia de fragmentación.
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Puede ser útil para calcular inserciones en lotes de entrada. El parámetro inputs puede ser una lista de cadenas, donde cada cadena es una entrada diferente. A su vez, la respuesta es una lista de inserciones, donde cada inserción corresponde a la entrada en la misma posición.
var response = await client.path("/embeddings").post({
body: {
input: [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
}
});
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Sugerencia
Al crear lotes de solicitud, tenga en cuenta el límite de lotes para cada uno de los modelos. La mayoría de los modelos tienen un límite de lotes de 1024.
Especificar dimensiones de inserción
Puede especificar el número de dimensiones para las inserciones. En el código de ejemplo siguiente se muestra cómo crear inserciones con 1024 dimensiones. Observe que no todos los modelos de inserción admiten que indique el número de dimensiones de la solicitud y, en esos casos, se devuelve un error 422.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
dimensions: 1024,
}
});
Creación de diferentes tipos de inserciones
Algunos modelos pueden generar múltiples inserciones para la misma entrada en función de cómo planee usarlos. Esta capacidad le permite recuperar inserciones más precisas para los patrones de RAG.
El siguiente ejemplo muestra cómo crear inserciones que se utilizan para crear una inserción para un documento que se almacenará en una base de datos vectorial:
var response = await client.path("/embeddings").post({
body: {
input: ["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type: "document",
}
});
Cuando trabaje en una consulta para recuperar un documento de este tipo, puede usar el siguiente fragmento de código para crear las inserciones para la consulta y maximizar el rendimiento de la recuperación.
var response = await client.path("/embeddings").post({
body: {
input: ["What's the ultimate meaning of life?"],
input_type: "query",
}
});
Observe que no todos los modelos de inserción admiten que indique el tipo de entrada en la solicitud y, en esos casos, se devuelve un error 422. De forma predeterminada, se devuelven inserciones de tipo Text.
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de inserciones con modelos implementados en la inferencia de modelos de Azure AI en los servicios de Azure AI.
Requisitos previos
Para usar modelos de inserción en la aplicación, necesita lo siguiente:
Suscripción a Azure. Si usa Modelos de GitHub, puede actualizar la experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a la inferencia de modelos de Azure AI si es su caso.
Recurso de Servicios de Azure AI. Para más información, vea Creación de un recurso de Servicios de Azure AI.
Dirección URL y clave del punto de conexión.
Implementación de modelo de inserciones. Si no tiene una lectura, lea Incorporación y configuración de modelos en los servicios de Azure AI para agregar un modelo de inserción al recurso.
Agregue el paquete de inferencia de Azure AI al proyecto:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Sugerencia
Más información sobre el Paquete de inferencia y referencia de Azure AI.
Si usa Entra ID, también necesita el siguiente paquete:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Importar el siguiente espacio de nombres:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Uso de incrustaciones
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
EmbeddingsClient client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(System.getProperty("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Si ha configurado el recurso para que admita Microsoft Entra ID, puede utilizar el siguiente fragmento de código para crear un cliente.
client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Creación de inserciones
Cree una solicitud de inserción para ver la salida del modelo.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList("The ultimate answer to the question of life"));
Response<EmbeddingsResult> response = client.embed(requestOptions);
Sugerencia
Al crear una solicitud, tenga en cuenta el límite de entrada del token para el modelo. Si necesita insertar partes más grandes del texto, necesitará una estrategia de fragmentación.
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
System.out.println("Embedding: " + response.getValue().getData());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
Puede ser útil para calcular inserciones en lotes de entrada. El parámetro inputs puede ser una lista de cadenas, donde cada cadena es una entrada diferente. A su vez, la respuesta es una lista de inserciones, donde cada inserción corresponde a la entrada en la misma posición.
requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList(
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
));
response = client.embed(requestOptions);
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
Sugerencia
Al crear lotes de solicitud, tenga en cuenta el límite de lotes para cada uno de los modelos. La mayoría de los modelos tienen un límite de lotes de 1024.
Especificar dimensiones de inserción
Puede especificar el número de dimensiones para las inserciones. En el código de ejemplo siguiente se muestra cómo crear inserciones con 1024 dimensiones. Observe que no todos los modelos de inserción admiten que indique el número de dimensiones de la solicitud y, en esos casos, se devuelve un error 422.
Creación de diferentes tipos de inserciones
Algunos modelos pueden generar múltiples inserciones para la misma entrada en función de cómo planee usarlos. Esta capacidad le permite recuperar inserciones más precisas para los patrones de RAG.
El siguiente ejemplo muestra cómo crear inserciones que se utilizan para crear una inserción para un documento que se almacenará en una base de datos vectorial:
List<String> input = Arrays.asList("The answer to the ultimate question of life, the universe, and everything is 42");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
response = client.embed(requestOptions);
Cuando trabaje en una consulta para recuperar un documento de este tipo, puede usar el siguiente fragmento de código para crear las inserciones para la consulta y maximizar el rendimiento de la recuperación.
input = Arrays.asList("What's the ultimate meaning of life?");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
response = client.embed(requestOptions);
Observe que no todos los modelos de inserción admiten que indique el tipo de entrada en la solicitud y, en esos casos, se devuelve un error 422. De forma predeterminada, se devuelven inserciones de tipo Text.
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de inserciones con modelos implementados en la inferencia de modelos de Azure AI en los servicios de Azure AI.
Requisitos previos
Para usar modelos de inserción en la aplicación, necesita lo siguiente:
Suscripción a Azure. Si usa Modelos de GitHub, puede actualizar la experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a la inferencia de modelos de Azure AI si es su caso.
Recurso de Servicios de Azure AI. Para más información, vea Creación de un recurso de Servicios de Azure AI.
Dirección URL y clave del punto de conexión.
Implementación de modelo de inserciones. Si no tiene una lectura, lea Incorporación y configuración de modelos en los servicios de Azure AI para agregar un modelo de inserción al recurso.
Instale el paquete de inferencia de Azure AI con el siguiente comando:
dotnet add package Azure.AI.Inference --prereleaseSugerencia
Más información sobre el Paquete de inferencia y referencia de Azure AI.
Si usa Entra ID, también necesita el siguiente paquete:
dotnet add package Azure.Identity
Uso de incrustaciones
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
EmbeddingsClient client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Si ha configurado el recurso para que admita Microsoft Entra ID, puede utilizar el siguiente fragmento de código para crear un cliente.
client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"text-embedding-3-small"
);
Creación de inserciones
Cree una solicitud de inserción para ver la salida del modelo.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Sugerencia
Al crear una solicitud, tenga en cuenta el límite de entrada del token para el modelo. Si necesita insertar partes más grandes del texto, necesitará una estrategia de fragmentación.
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
Console.WriteLine($"Embedding: {response.Value.Data}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Puede ser útil para calcular inserciones en lotes de entrada. El parámetro inputs puede ser una lista de cadenas, donde cada cadena es una entrada diferente. A su vez, la respuesta es una lista de inserciones, donde cada inserción corresponde a la entrada en la misma posición.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
Sugerencia
Al crear lotes de solicitud, tenga en cuenta el límite de lotes para cada uno de los modelos. La mayoría de los modelos tienen un límite de lotes de 1024.
Especificar dimensiones de inserción
Puede especificar el número de dimensiones para las inserciones. En el código de ejemplo siguiente se muestra cómo crear inserciones con 1024 dimensiones. Observe que no todos los modelos de inserción admiten que indique el número de dimensiones de la solicitud y, en esos casos, se devuelve un error 422.
Creación de diferentes tipos de inserciones
Algunos modelos pueden generar múltiples inserciones para la misma entrada en función de cómo planee usarlos. Esta capacidad le permite recuperar inserciones más precisas para los patrones de RAG.
El siguiente ejemplo muestra cómo crear inserciones que se utilizan para crear una inserción para un documento que se almacenará en una base de datos vectorial:
var input = new List<string> {
"The answer to the ultimate question of life, the universe, and everything is 42"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Cuando trabaje en una consulta para recuperar un documento de este tipo, puede usar el siguiente fragmento de código para crear las inserciones para la consulta y maximizar el rendimiento de la recuperación.
var input = new List<string> {
"What's the ultimate meaning of life?"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Observe que no todos los modelos de inserción admiten que indique el tipo de entrada en la solicitud y, en esos casos, se devuelve un error 422. De forma predeterminada, se devuelven inserciones de tipo Text.
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de inserciones con modelos implementados en la inferencia de modelos de Azure AI en los servicios de Azure AI.
Requisitos previos
Para usar modelos de inserción en la aplicación, necesita lo siguiente:
Suscripción a Azure. Si usa Modelos de GitHub, puede actualizar la experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a la inferencia de modelos de Azure AI si es su caso.
Recurso de Servicios de Azure AI. Para más información, vea Creación de un recurso de Servicios de Azure AI.
Dirección URL y clave del punto de conexión.
- Implementación de modelo de inserciones. Si no tiene una lectura, lea Incorporación y configuración de modelos en los servicios de Azure AI para agregar un modelo de inserción al recurso.
Uso de incrustaciones
Para usar las inserciones de texto, use la ruta /embeddings anexada a la dirección URL base junto con la credencial indicada en api-key. El encabezado Authorization también se admite con el formato Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Si ha configurado el recurso con el soporte de Microsoft Entra ID, pase el token en el encabezado Authorization:
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Creación de inserciones
Cree una solicitud de inserción para ver la salida del modelo.
{
"input": [
"The ultimate answer to the question of life"
]
}
Sugerencia
Al crear una solicitud, tenga en cuenta el límite de entrada del token para el modelo. Si necesita insertar partes más grandes del texto, necesitará una estrategia de fragmentación.
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 9,
"completion_tokens": 0,
"total_tokens": 9
}
}
Puede ser útil para calcular inserciones en lotes de entrada. El parámetro inputs puede ser una lista de cadenas, donde cada cadena es una entrada diferente. A su vez, la respuesta es una lista de inserciones, donde cada inserción corresponde a la entrada en la misma posición.
{
"input": [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
]
}
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
},
{
"index": 1,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 19,
"completion_tokens": 0,
"total_tokens": 19
}
}
Sugerencia
Al crear lotes de solicitud, tenga en cuenta el límite de lotes para cada uno de los modelos. La mayoría de los modelos tienen un límite de lotes de 1024.
Especificar dimensiones de inserción
Puede especificar el número de dimensiones para las inserciones. En el código de ejemplo siguiente se muestra cómo crear inserciones con 1024 dimensiones. Observe que no todos los modelos de inserción admiten que indique el número de dimensiones de la solicitud y, en esos casos, se devuelve un error 422.
{
"input": [
"The ultimate answer to the question of life"
],
"dimensions": 1024
}
Creación de diferentes tipos de inserciones
Algunos modelos pueden generar múltiples inserciones para la misma entrada en función de cómo planee usarlos. Esta capacidad le permite recuperar inserciones más precisas para los patrones de RAG.
El siguiente ejemplo muestra cómo crear inserciones que se utilizan para crear una inserción para un documento que se almacenará en una base de datos vectorial:
{
"input": [
"The answer to the ultimate question of life, the universe, and everything is 42"
],
"input_type": "document"
}
Cuando trabaje en una consulta para recuperar un documento de este tipo, puede usar el siguiente fragmento de código para crear las inserciones para la consulta y maximizar el rendimiento de la recuperación.
{
"input": [
"What's the ultimate meaning of life?"
],
"input_type": "query"
}
Observe que no todos los modelos de inserción admiten que indique el tipo de entrada en la solicitud y, en esos casos, se devuelve un error 422. De forma predeterminada, se devuelven inserciones de tipo Text.