Generación de finalizaciones de chat con la inferencia del modelo de Azure AI
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de finalizaciones de chat con modelos implementados en la inferencia de modelos de Azure AI en los servicios de Azure AI.
Requisitos previos
Para usar los modelos de finalización de chat en la aplicación, necesita:
Suscripción a Azure. Si usa Modelos de GitHub, puede actualizar la experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a la inferencia de modelos de Azure AI si es su caso.
Recurso de Servicios de Azure AI. Para más información, vea Creación de un recurso de Servicios de Azure AI.
Dirección URL y clave del punto de conexión.

Una implementación del modelo de finalizaciones de chat. Si no tiene ninguna, lea Agregar y configurar modelos en los servicios de Azure AI para agregar un modelo de finalización de chat al recurso.
Instale el paquete de inferencia de Azure AI con el siguiente comando:
pip install -U azure-ai-inferenceSugerencia
Más información sobre el Paquete de inferencia y referencia de Azure AI.
Uso de las finalizaciones de chat
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="mistral-large-2407"
)
Si ha configurado el recurso para que admita Microsoft Entra ID, puede utilizar el siguiente fragmento de código para crear un cliente.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="mistral-large-2407"
)
Creación de una solicitud de finalización de chat
En el ejemplo siguiente, se muestra cómo crear solicitudes básicas de finalizaciones de chat al modelo.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
)
Nota:
Algunos modelos no admiten mensajes del sistema (role="system"). Cuando se usa la API de inferencia del modelo de Azure AI, los mensajes del sistema se traducen a los mensajes de usuario, que es la funcionalidad más cercana disponible. Esta traducción se ofrece para mayor comodidad, pero es importante comprobar que el modelo sigue las instrucciones del mensaje del sistema con el nivel de confianza correcto.
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspeccione la sección usage de la respuesta para ver el número de tokens usados para el aviso, el número total de tokens generados y el número de tokens usados para la finalización.
Streaming de contenido
De forma predeterminada, la API de finalizaciones devuelve todo el contenido generado en una única respuesta. Si está generando finalizaciones largas, esperar la respuesta puede tardar muchos segundos.
Puede transmitir el contenido para obtenerlo a medida que se genera. El contenido de streaming permite empezar a procesar la finalización a medida que el contenido está disponible. Este modo devuelve un objeto que transmite la respuesta como eventos enviados por el servidor de solo datos. Extraiga fragmentos del campo delta, en lugar del campo de mensaje.
Para transmitir finalizaciones, establezca stream=True al llamar al modelo.
result = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
temperature=0,
top_p=1,
max_tokens=2048,
stream=True,
)
Para visualizar la salida, defina una función auxiliar para imprimir la secuencia.
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
import time
for update in result:
if update.choices:
print(update.choices[0].delta.content, end="")
Puede visualizar cómo el streaming genera contenido:
print_stream(result)
Exploración de más parámetros admitidos por el cliente de inferencia
Explore otros parámetros que puede especificar en el cliente de inferencia. Para obtener una lista completa de todos los parámetros admitidos y su documentación correspondiente, vea Referencia de la API de inferencia de modelos de Azure AI.
from azure.ai.inference.models import ChatCompletionsResponseFormatText
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
presence_penalty=0.1,
frequency_penalty=0.8,
max_tokens=2048,
stop=["<|endoftext|>"],
temperature=0,
top_p=1,
response_format={ "type": ChatCompletionsResponseFormatText() },
)
Algunos modelos no admiten el formato de salida JSON. Siempre puede pedir al modelo que genere salidas JSON. Sin embargo, no se garantiza que estas salidas sean JSON válidas.
Si desea pasar un parámetro que no está en la lista de parámetros admitidos, puede pasarlo al modelo subyacente mediante parámetros adicionales. Vea Pasar parámetros adicionales al modelo.
Creación de salidas JSON
Algunos modelos pueden crear salidas JSON. Establezca el response_format en json_object para habilita el modo JSON y garantizar que el mensaje que genera el modelo es JSON válido. También debe indicar al modelo que genere JSON usted mismo mediante un mensaje de usuario o sistema. Además, el contenido del mensaje puede cortarse parcialmente si finish_reason="length", que indica que la generación superó max_tokens o que la conversación superó la longitud máxima del contexto.
from azure.ai.inference.models import ChatCompletionsResponseFormatJSON
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant that always generate responses in JSON format, using."
" the following format: { ""answer"": ""response"" }."),
UserMessage(content="How many languages are in the world?"),
],
response_format={ "type": ChatCompletionsResponseFormatJSON() }
)
Pase de parámetros adicionales al modelo
La API de inferencia de modelos de Azure AI permite pasar parámetros adicionales al modelo. En el ejemplo de código siguiente se muestra cómo pasar el parámetro adicional logprobs al modelo.
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
model_extras={
"logprobs": True
}
)
Antes de pasar parámetros adicionales a la API de inferencia del modelo de Azure AI, asegúrese de que el modelo admite esos parámetros adicionales. Cuando se realiza la solicitud al modelo subyacente, el encabezado extra-parameters se pasa al modelo con el valor pass-through. Este valor indica al punto de conexión que pase los parámetros adicionales al modelo. El uso de parámetros adicionales con el modelo no garantiza que el modelo pueda controlarlos realmente. Lea la documentación del modelo para comprender qué parámetros adicionales se admiten.
Uso de herramientas
Algunos modelos admiten el uso de herramientas, que puede ser un recurso extraordinario cuando necesita descargar tareas específicas del modelo de lenguaje y, en su lugar, confiar en un sistema más determinista o incluso en un modelo de lenguaje diferente. La API de inferencia de modelos de Azure AI permite definir herramientas de la siguiente manera.
En el ejemplo de código siguiente se crea una definición de herramienta que puede buscar a partir de información de vuelo de dos ciudades diferentes.
from azure.ai.inference.models import FunctionDefinition, ChatCompletionsFunctionToolDefinition
flight_info = ChatCompletionsFunctionToolDefinition(
function=FunctionDefinition(
name="get_flight_info",
description="Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters={
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates",
},
"destination_city": {
"type": "string",
"description": "The flight destination city",
},
},
"required": ["origin_city", "destination_city"],
},
)
)
tools = [flight_info]
En este ejemplo, la salida de la función es que no hay vuelos disponibles para la ruta seleccionada, pero el usuario debe considerar la posibilidad de tomar un tren.
def get_flight_info(loc_origin: str, loc_destination: str):
return {
"info": f"There are no flights available from {loc_origin} to {loc_destination}. You should take a train, specially if it helps to reduce CO2 emissions."
}
Nota:
Los modelos de Cohere requieren que las respuestas de una herramienta sean un contenido JSON válido con formato de cadena. Al construir mensajes de tipo Tool, asegúrese de que la respuesta es una cadena JSON válida.
Pida al modelo que reserve vuelos con la ayuda de esta función:
messages = [
SystemMessage(
content="You are a helpful assistant that help users to find information about traveling, how to get"
" to places and the different transportations options. You care about the environment and you"
" always have that in mind when answering inqueries.",
),
UserMessage(
content="When is the next flight from Miami to Seattle?",
),
]
response = client.complete(
messages=messages, tools=tools, tool_choice="auto"
)
Puede inspeccionar la respuesta para averiguar si es necesario llamar a una herramienta. Inspeccione el motivo de finalización para determinar si se debe llamar a la herramienta. Recuerde que se pueden indicar varios tipos de herramientas. En este ejemplo se muestra una herramienta de tipo function.
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print("Finish reason:", response.choices[0].finish_reason)
print("Tool call:", tool_calls)
Para continuar, anexe este mensaje al historial de chats:
messages.append(
response_message
)
Ahora es el momento de llamar a la función adecuada para controlar la llamada a la herramienta. El siguiente fragmento de código itera todas las llamadas a herramienta indicadas en la respuesta y llama a la función correspondiente con los parámetros adecuados. La respuesta también se anexa al historial de chat.
import json
from azure.ai.inference.models import ToolMessage
for tool_call in tool_calls:
# Get the tool details:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments.replace("\'", "\""))
tool_call_id = tool_call.id
print(f"Calling function `{function_name}` with arguments {function_args}")
# Call the function defined above using `locals()`, which returns the list of all functions
# available in the scope as a dictionary. Notice that this is just done as a simple way to get
# the function callable from its string name. Then we can call it with the corresponding
# arguments.
callable_func = locals()[function_name]
function_response = callable_func(**function_args)
print("->", function_response)
# Once we have a response from the function and its arguments, we can append a new message to the chat
# history. Notice how we are telling to the model that this chat message came from a tool:
messages.append(
ToolMessage(
tool_call_id=tool_call_id,
content=json.dumps(function_response)
)
)
Vea la respuesta del modelo:
response = client.complete(
messages=messages,
tools=tools,
)
Aplicación de la seguridad del contenido
La API de inferencia de modelos de Azure AI admite Seguridad de contenido de Azure AI. Cuando se usan implementaciones con la seguridad de contenido de Azure AI activada, las entradas y las salidas pasan a través de un conjunto de modelos de clasificación destinados a detectar y evitar la salida de contenido perjudicial. El sistema de filtrado de contenido detecta y toma medidas en categorías específicas de contenido potencialmente perjudicial tanto en solicitudes de entrada como en finalizaciones de salida.
En el ejemplo siguiente se muestra cómo controlar eventos cuando el modelo detecta contenido perjudicial en el mensaje de entrada y la seguridad del contenido está habilitado.
from azure.ai.inference.models import AssistantMessage, UserMessage, SystemMessage
try:
response = client.complete(
messages=[
SystemMessage(content="You are an AI assistant that helps people find information."),
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
]
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
Sugerencia
Para más información sobre cómo configurar y controlar la configuración de seguridad del contenido de Azure AI, consulte la Documentación de seguridad de contenido de Azure AI.
Uso de finalizaciones de chat con imágenes
Algunos modelos pueden razonar entre texto e imágenes y generar finalizaciones de texto basadas en ambos tipos de entrada. En esta sección, explorará las funcionalidades de algunos modelos para la visión en forma de chat:
Importante
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error.
Para ver esta funcionalidad, descargue una imagen y codifique la información como base64 cadena. Los datos resultantes deben estar dentro de una Dirección URL de datos:
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
Visualizar la imagen:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

Ahora, cree una solicitud de finalización de chat con la imagen:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=0,
top_p=1,
max_tokens=2048,
)
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
print(f"{response.choices[0].message.role}:\n\t{response.choices[0].message.content}\n")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de finalizaciones de chat con modelos implementados en la inferencia de modelos de Azure AI en los servicios de Azure AI.
Requisitos previos
Para usar los modelos de finalización de chat en la aplicación, necesita:
Suscripción a Azure. Si usa Modelos de GitHub, puede actualizar la experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a la inferencia de modelos de Azure AI si es su caso.
Recurso de Servicios de Azure AI. Para más información, vea Creación de un recurso de Servicios de Azure AI.
Dirección URL y clave del punto de conexión.
Una implementación del modelo de finalizaciones de chat. Si no tiene ninguna, lea Agregar y configurar modelos en los servicios de Azure AI para agregar un modelo de finalización de chat al recurso.
Instale la biblioteca de inferencia de Azure para JavaScript con el siguiente comando:
npm install @azure-rest/ai-inferenceSugerencia
Más información sobre el Paquete de inferencia y referencia de Azure AI.
Uso de las finalizaciones de chat
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Si ha configurado el recurso para que admita Microsoft Entra ID, puede utilizar el siguiente fragmento de código para crear un cliente.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential()
);
Creación de una solicitud de finalización de chat
En el ejemplo siguiente, se muestra cómo crear solicitudes básicas de finalizaciones de chat al modelo.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
Nota:
Algunos modelos no admiten mensajes del sistema (role="system"). Cuando se usa la API de inferencia del modelo de Azure AI, los mensajes del sistema se traducen a los mensajes de usuario, que es la funcionalidad más cercana disponible. Esta traducción se ofrece para mayor comodidad, pero es importante comprobar que el modelo sigue las instrucciones del mensaje del sistema con el nivel de confianza correcto.
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspeccione la sección usage de la respuesta para ver el número de tokens usados para el aviso, el número total de tokens generados y el número de tokens usados para la finalización.
Streaming de contenido
De forma predeterminada, la API de finalizaciones devuelve todo el contenido generado en una única respuesta. Si está generando finalizaciones largas, esperar la respuesta puede tardar muchos segundos.
Puede transmitir el contenido para obtenerlo a medida que se genera. El contenido de streaming permite empezar a procesar la finalización a medida que el contenido está disponible. Este modo devuelve un objeto que transmite la respuesta como eventos enviados por el servidor de solo datos. Extraiga fragmentos del campo delta, en lugar del campo de mensaje.
Para transmitir finalizaciones, use .asNodeStream() al llamar al modelo.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
}).asNodeStream();
Puede visualizar cómo el streaming genera contenido:
var stream = response.body;
if (!stream) {
stream.destroy();
throw new Error(`Failed to get chat completions with status: ${response.status}`);
}
if (response.status !== "200") {
throw new Error(`Failed to get chat completions: ${response.body.error}`);
}
var sses = createSseStream(stream);
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
console.log(choice.delta?.content ?? "");
}
}
Exploración de más parámetros admitidos por el cliente de inferencia
Explore otros parámetros que puede especificar en el cliente de inferencia. Para obtener una lista completa de todos los parámetros admitidos y su documentación correspondiente, vea Referencia de la API de inferencia de modelos de Azure AI.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
presence_penalty: "0.1",
frequency_penalty: "0.8",
max_tokens: 2048,
stop: ["<|endoftext|>"],
temperature: 0,
top_p: 1,
response_format: { type: "text" },
}
});
Algunos modelos no admiten el formato de salida JSON. Siempre puede pedir al modelo que genere salidas JSON. Sin embargo, no se garantiza que estas salidas sean JSON válidas.
Si desea pasar un parámetro que no está en la lista de parámetros admitidos, puede pasarlo al modelo subyacente mediante parámetros adicionales. Vea Pasar parámetros adicionales al modelo.
Creación de salidas JSON
Algunos modelos pueden crear salidas JSON. Establezca el response_format en json_object para habilita el modo JSON y garantizar que el mensaje que genera el modelo es JSON válido. También debe indicar al modelo que genere JSON usted mismo mediante un mensaje de usuario o sistema. Además, el contenido del mensaje puede cortarse parcialmente si finish_reason="length", que indica que la generación superó max_tokens o que la conversación superó la longitud máxima del contexto.
var messages = [
{ role: "system", content: "You are a helpful assistant that always generate responses in JSON format, using."
+ " the following format: { \"answer\": \"response\" }." },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
response_format: { type: "json_object" }
}
});
Pase de parámetros adicionales al modelo
La API de inferencia de modelos de Azure AI permite pasar parámetros adicionales al modelo. En el ejemplo de código siguiente se muestra cómo pasar el parámetro adicional logprobs al modelo.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
headers: {
"extra-params": "pass-through"
},
body: {
messages: messages,
logprobs: true
}
});
Antes de pasar parámetros adicionales a la API de inferencia del modelo de Azure AI, asegúrese de que el modelo admite esos parámetros adicionales. Cuando se realiza la solicitud al modelo subyacente, el encabezado extra-parameters se pasa al modelo con el valor pass-through. Este valor indica al punto de conexión que pase los parámetros adicionales al modelo. El uso de parámetros adicionales con el modelo no garantiza que el modelo pueda controlarlos realmente. Lea la documentación del modelo para comprender qué parámetros adicionales se admiten.
Uso de herramientas
Algunos modelos admiten el uso de herramientas, que puede ser un recurso extraordinario cuando necesita descargar tareas específicas del modelo de lenguaje y, en su lugar, confiar en un sistema más determinista o incluso en un modelo de lenguaje diferente. La API de inferencia de modelos de Azure AI permite definir herramientas de la siguiente manera.
En el ejemplo de código siguiente se crea una definición de herramienta que puede buscar a partir de información de vuelo de dos ciudades diferentes.
const flight_info = {
name: "get_flight_info",
description: "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters: {
type: "object",
properties: {
origin_city: {
type: "string",
description: "The name of the city where the flight originates",
},
destination_city: {
type: "string",
description: "The flight destination city",
},
},
required: ["origin_city", "destination_city"],
},
}
const tools = [
{
type: "function",
function: flight_info,
},
];
En este ejemplo, la salida de la función es que no hay vuelos disponibles para la ruta seleccionada, pero el usuario debe considerar la posibilidad de tomar un tren.
function get_flight_info(loc_origin, loc_destination) {
return {
info: "There are no flights available from " + loc_origin + " to " + loc_destination + ". You should take a train, specially if it helps to reduce CO2 emissions."
}
}
Nota:
Los modelos de Cohere requieren que las respuestas de una herramienta sean un contenido JSON válido con formato de cadena. Al construir mensajes de tipo Tool, asegúrese de que la respuesta es una cadena JSON válida.
Pida al modelo que reserve vuelos con la ayuda de esta función:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
tool_choice: "auto"
}
});
Puede inspeccionar la respuesta para averiguar si es necesario llamar a una herramienta. Inspeccione el motivo de finalización para determinar si se debe llamar a la herramienta. Recuerde que se pueden indicar varios tipos de herramientas. En este ejemplo se muestra una herramienta de tipo function.
const response_message = response.body.choices[0].message;
const tool_calls = response_message.tool_calls;
console.log("Finish reason: " + response.body.choices[0].finish_reason);
console.log("Tool call: " + tool_calls);
Para continuar, anexe este mensaje al historial de chats:
messages.push(response_message);
Ahora es el momento de llamar a la función adecuada para controlar la llamada a la herramienta. El siguiente fragmento de código itera todas las llamadas a herramienta indicadas en la respuesta y llama a la función correspondiente con los parámetros adecuados. La respuesta también se anexa al historial de chat.
function applyToolCall({ function: call, id }) {
// Get the tool details:
const tool_params = JSON.parse(call.arguments);
console.log("Calling function " + call.name + " with arguments " + tool_params);
// Call the function defined above using `window`, which returns the list of all functions
// available in the scope as a dictionary. Notice that this is just done as a simple way to get
// the function callable from its string name. Then we can call it with the corresponding
// arguments.
const function_response = tool_params.map(window[call.name]);
console.log("-> " + function_response);
return function_response
}
for (const tool_call of tool_calls) {
var tool_response = tool_call.apply(applyToolCall);
messages.push(
{
role: "tool",
tool_call_id: tool_call.id,
content: tool_response
}
);
}
Vea la respuesta del modelo:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
}
});
Aplicación de la seguridad del contenido
La API de inferencia de modelos de Azure AI admite Seguridad de contenido de Azure AI. Cuando se usan implementaciones con la seguridad de contenido de Azure AI activada, las entradas y las salidas pasan a través de un conjunto de modelos de clasificación destinados a detectar y evitar la salida de contenido perjudicial. El sistema de filtrado de contenido detecta y toma medidas en categorías específicas de contenido potencialmente perjudicial tanto en solicitudes de entrada como en finalizaciones de salida.
En el ejemplo siguiente se muestra cómo controlar eventos cuando el modelo detecta contenido perjudicial en el mensaje de entrada y la seguridad del contenido está habilitado.
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
Sugerencia
Para más información sobre cómo configurar y controlar la configuración de seguridad del contenido de Azure AI, consulte la Documentación de seguridad de contenido de Azure AI.
Uso de finalizaciones de chat con imágenes
Algunos modelos pueden razonar entre texto e imágenes y generar finalizaciones de texto basadas en ambos tipos de entrada. En esta sección, explorará las funcionalidades de algunos modelos para la visión en forma de chat:
Importante
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error.
Para ver esta funcionalidad, descargue una imagen y codifique la información como base64 cadena. Los datos resultantes deben estar dentro de una Dirección URL de datos:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
Visualizar la imagen:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
Ahora, cree una solicitud de finalización de chat con la imagen:
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
temperature: 0,
top_p: 1,
max_tokens: 2048,
}
});
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de finalizaciones de chat con modelos implementados en la inferencia de modelos de Azure AI en los servicios de Azure AI.
Requisitos previos
Para usar los modelos de finalización de chat en la aplicación, necesita:
Suscripción a Azure. Si usa Modelos de GitHub, puede actualizar la experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a la inferencia de modelos de Azure AI si es su caso.
Recurso de Servicios de Azure AI. Para más información, vea Creación de un recurso de Servicios de Azure AI.
Dirección URL y clave del punto de conexión.
Una implementación del modelo de finalizaciones de chat. Si no tiene ninguna, lea Agregar y configurar modelos en los servicios de Azure AI para agregar un modelo de finalización de chat al recurso.
Agregue el paquete de inferencia de Azure AI al proyecto:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Sugerencia
Más información sobre el Paquete de inferencia y referencia de Azure AI.
Si usa Entra ID, también necesita el siguiente paquete:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Importe los siguientes espacios de nombres:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Uso de las finalizaciones de chat
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
Si ha configurado el recurso para que admita Microsoft Entra ID, puede utilizar el siguiente fragmento de código para crear un cliente.
Creación de una solicitud de finalización de chat
En el ejemplo siguiente, se muestra cómo crear solicitudes básicas de finalizaciones de chat al modelo.
Nota:
Algunos modelos no admiten mensajes del sistema (role="system"). Cuando se usa la API de inferencia del modelo de Azure AI, los mensajes del sistema se traducen a los mensajes de usuario, que es la funcionalidad más cercana disponible. Esta traducción se ofrece para mayor comodidad, pero es importante comprobar que el modelo sigue las instrucciones del mensaje del sistema con el nivel de confianza correcto.
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspeccione la sección usage de la respuesta para ver el número de tokens usados para el aviso, el número total de tokens generados y el número de tokens usados para la finalización.
Streaming de contenido
De forma predeterminada, la API de finalizaciones devuelve todo el contenido generado en una única respuesta. Si está generando finalizaciones largas, esperar la respuesta puede tardar muchos segundos.
Puede transmitir el contenido para obtenerlo a medida que se genera. El contenido de streaming permite empezar a procesar la finalización a medida que el contenido está disponible. Este modo devuelve un objeto que transmite la respuesta como eventos enviados por el servidor de solo datos. Extraiga fragmentos del campo delta, en lugar del campo de mensaje.
Puede visualizar cómo el streaming genera contenido:
Exploración de más parámetros admitidos por el cliente de inferencia
Explore otros parámetros que puede especificar en el cliente de inferencia. Para obtener una lista completa de todos los parámetros admitidos y su documentación correspondiente, vea Referencia de la API de inferencia de modelos de Azure AI. Algunos modelos no admiten el formato de salida JSON. Siempre puede pedir al modelo que genere salidas JSON. Sin embargo, no se garantiza que estas salidas sean JSON válidas.
Si desea pasar un parámetro que no está en la lista de parámetros admitidos, puede pasarlo al modelo subyacente mediante parámetros adicionales. Vea Pasar parámetros adicionales al modelo.
Creación de salidas JSON
Algunos modelos pueden crear salidas JSON. Establezca el response_format en json_object para habilita el modo JSON y garantizar que el mensaje que genera el modelo es JSON válido. También debe indicar al modelo que genere JSON usted mismo mediante un mensaje de usuario o sistema. Además, el contenido del mensaje puede cortarse parcialmente si finish_reason="length", que indica que la generación superó max_tokens o que la conversación superó la longitud máxima del contexto.
Pase de parámetros adicionales al modelo
La API de inferencia de modelos de Azure AI permite pasar parámetros adicionales al modelo. En el ejemplo de código siguiente se muestra cómo pasar el parámetro adicional logprobs al modelo.
Antes de pasar parámetros adicionales a la API de inferencia del modelo de Azure AI, asegúrese de que el modelo admite esos parámetros adicionales. Cuando se realiza la solicitud al modelo subyacente, el encabezado extra-parameters se pasa al modelo con el valor pass-through. Este valor indica al punto de conexión que pase los parámetros adicionales al modelo. El uso de parámetros adicionales con el modelo no garantiza que el modelo pueda controlarlos realmente. Lea la documentación del modelo para comprender qué parámetros adicionales se admiten.
Uso de herramientas
Algunos modelos admiten el uso de herramientas, que puede ser un recurso extraordinario cuando necesita descargar tareas específicas del modelo de lenguaje y, en su lugar, confiar en un sistema más determinista o incluso en un modelo de lenguaje diferente. La API de inferencia de modelos de Azure AI permite definir herramientas de la siguiente manera.
En el ejemplo de código siguiente se crea una definición de herramienta que puede buscar a partir de información de vuelo de dos ciudades diferentes.
En este ejemplo, la salida de la función es que no hay vuelos disponibles para la ruta seleccionada, pero el usuario debe considerar la posibilidad de tomar un tren.
Nota:
Los modelos de Cohere requieren que las respuestas de una herramienta sean un contenido JSON válido con formato de cadena. Al construir mensajes de tipo Tool, asegúrese de que la respuesta es una cadena JSON válida.
Pida al modelo que reserve vuelos con la ayuda de esta función:
Puede inspeccionar la respuesta para averiguar si es necesario llamar a una herramienta. Inspeccione el motivo de finalización para determinar si se debe llamar a la herramienta. Recuerde que se pueden indicar varios tipos de herramientas. En este ejemplo se muestra una herramienta de tipo function.
Para continuar, anexe este mensaje al historial de chats:
Ahora es el momento de llamar a la función adecuada para controlar la llamada a la herramienta. El siguiente fragmento de código itera todas las llamadas a herramienta indicadas en la respuesta y llama a la función correspondiente con los parámetros adecuados. La respuesta también se anexa al historial de chat.
Vea la respuesta del modelo:
Aplicación de la seguridad del contenido
La API de inferencia de modelos de Azure AI admite Seguridad de contenido de Azure AI. Cuando se usan implementaciones con la seguridad de contenido de Azure AI activada, las entradas y las salidas pasan a través de un conjunto de modelos de clasificación destinados a detectar y evitar la salida de contenido perjudicial. El sistema de filtrado de contenido detecta y toma medidas en categorías específicas de contenido potencialmente perjudicial tanto en solicitudes de entrada como en finalizaciones de salida.
En el ejemplo siguiente se muestra cómo controlar eventos cuando el modelo detecta contenido perjudicial en el mensaje de entrada y la seguridad del contenido está habilitado.
Sugerencia
Para más información sobre cómo configurar y controlar la configuración de seguridad del contenido de Azure AI, consulte la Documentación de seguridad de contenido de Azure AI.
Uso de finalizaciones de chat con imágenes
Algunos modelos pueden razonar entre texto e imágenes y generar finalizaciones de texto basadas en ambos tipos de entrada. En esta sección, explorará las funcionalidades de algunos modelos para la visión en forma de chat:
Importante
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error.
Para ver esta funcionalidad, descargue una imagen y codifique la información como base64 cadena. Los datos resultantes deben estar dentro de una Dirección URL de datos:
Visualizar la imagen:
Ahora, cree una solicitud de finalización de chat con la imagen:
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de finalizaciones de chat con modelos implementados en la inferencia de modelos de Azure AI en los servicios de Azure AI.
Requisitos previos
Para usar los modelos de finalización de chat en la aplicación, necesita:
Suscripción a Azure. Si usa Modelos de GitHub, puede actualizar la experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a la inferencia de modelos de Azure AI si es su caso.
Recurso de Servicios de Azure AI. Para más información, vea Creación de un recurso de Servicios de Azure AI.
Dirección URL y clave del punto de conexión.
Una implementación del modelo de finalizaciones de chat. Si no tiene ninguna, lea Agregar y configurar modelos en los servicios de Azure AI para agregar un modelo de finalización de chat al recurso.
Instale el paquete de inferencia de Azure AI con el siguiente comando:
dotnet add package Azure.AI.Inference --prereleaseSugerencia
Más información sobre el Paquete de inferencia y referencia de Azure AI.
Si usa Entra ID, también necesita el siguiente paquete:
dotnet add package Azure.Identity
Uso de las finalizaciones de chat
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"mistral-large-2407"
);
Si ha configurado el recurso para que admita Microsoft Entra ID, puede utilizar el siguiente fragmento de código para crear un cliente.
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"mistral-large-2407"
);
Creación de una solicitud de finalización de chat
En el ejemplo siguiente, se muestra cómo crear solicitudes básicas de finalizaciones de chat al modelo.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Nota:
Algunos modelos no admiten mensajes del sistema (role="system"). Cuando se usa la API de inferencia del modelo de Azure AI, los mensajes del sistema se traducen a los mensajes de usuario, que es la funcionalidad más cercana disponible. Esta traducción se ofrece para mayor comodidad, pero es importante comprobar que el modelo sigue las instrucciones del mensaje del sistema con el nivel de confianza correcto.
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Inspeccione la sección usage de la respuesta para ver el número de tokens usados para el aviso, el número total de tokens generados y el número de tokens usados para la finalización.
Streaming de contenido
De forma predeterminada, la API de finalizaciones devuelve todo el contenido generado en una única respuesta. Si está generando finalizaciones largas, esperar la respuesta puede tardar muchos segundos.
Puede transmitir el contenido para obtenerlo a medida que se genera. El contenido de streaming permite empezar a procesar la finalización a medida que el contenido está disponible. Este modo devuelve un objeto que transmite la respuesta como eventos enviados por el servidor de solo datos. Extraiga fragmentos del campo delta, en lugar del campo de mensaje.
Para transmitir finalizaciones, use CompleteStreamingAsync método al llamar al modelo. Observe que en este ejemplo, la llamada se ajusta en un método asincrónico.
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
},
MaxTokens=4096
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
Para visualizar la salida, defina un método asincrónico para imprimir la secuencia en la consola.
static async Task PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (chatUpdate.Role.HasValue)
{
Console.Write($"{chatUpdate.Role.Value.ToString().ToUpperInvariant()}: ");
}
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
Console.Write(chatUpdate.ContentUpdate);
}
}
}
Puede visualizar cómo el streaming genera contenido:
StreamMessageAsync(client).GetAwaiter().GetResult();
Exploración de más parámetros admitidos por el cliente de inferencia
Explore otros parámetros que puede especificar en el cliente de inferencia. Para obtener una lista completa de todos los parámetros admitidos y su documentación correspondiente, vea Referencia de la API de inferencia de modelos de Azure AI.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
PresencePenalty = 0.1f,
FrequencyPenalty = 0.8f,
MaxTokens = 2048,
StopSequences = { "<|endoftext|>" },
Temperature = 0,
NucleusSamplingFactor = 1,
ResponseFormat = new ChatCompletionsResponseFormatText()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Algunos modelos no admiten el formato de salida JSON. Siempre puede pedir al modelo que genere salidas JSON. Sin embargo, no se garantiza que estas salidas sean JSON válidas.
Si desea pasar un parámetro que no está en la lista de parámetros admitidos, puede pasarlo al modelo subyacente mediante parámetros adicionales. Vea Pasar parámetros adicionales al modelo.
Creación de salidas JSON
Algunos modelos pueden crear salidas JSON. Establezca el response_format en json_object para habilita el modo JSON y garantizar que el mensaje que genera el modelo es JSON válido. También debe indicar al modelo que genere JSON usted mismo mediante un mensaje de usuario o sistema. Además, el contenido del mensaje puede cortarse parcialmente si finish_reason="length", que indica que la generación superó max_tokens o que la conversación superó la longitud máxima del contexto.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage(
"You are a helpful assistant that always generate responses in JSON format, " +
"using. the following format: { \"answer\": \"response\" }."
),
new ChatRequestUserMessage(
"How many languages are in the world?"
)
},
ResponseFormat = new ChatCompletionsResponseFormatJSON()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Pase de parámetros adicionales al modelo
La API de inferencia de modelos de Azure AI permite pasar parámetros adicionales al modelo. En el ejemplo de código siguiente se muestra cómo pasar el parámetro adicional logprobs al modelo.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
AdditionalProperties = { { "logprobs", BinaryData.FromString("true") } },
};
response = client.Complete(requestOptions, extraParams: ExtraParameters.PassThrough);
Console.WriteLine($"Response: {response.Value.Content}");
Antes de pasar parámetros adicionales a la API de inferencia del modelo de Azure AI, asegúrese de que el modelo admite esos parámetros adicionales. Cuando se realiza la solicitud al modelo subyacente, el encabezado extra-parameters se pasa al modelo con el valor pass-through. Este valor indica al punto de conexión que pase los parámetros adicionales al modelo. El uso de parámetros adicionales con el modelo no garantiza que el modelo pueda controlarlos realmente. Lea la documentación del modelo para comprender qué parámetros adicionales se admiten.
Uso de herramientas
Algunos modelos admiten el uso de herramientas, que puede ser un recurso extraordinario cuando necesita descargar tareas específicas del modelo de lenguaje y, en su lugar, confiar en un sistema más determinista o incluso en un modelo de lenguaje diferente. La API de inferencia de modelos de Azure AI permite definir herramientas de la siguiente manera.
En el ejemplo de código siguiente se crea una definición de herramienta que puede buscar a partir de información de vuelo de dos ciudades diferentes.
FunctionDefinition flightInfoFunction = new FunctionDefinition("getFlightInfo")
{
Description = "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
Parameters = BinaryData.FromObjectAsJson(new
{
Type = "object",
Properties = new
{
origin_city = new
{
Type = "string",
Description = "The name of the city where the flight originates"
},
destination_city = new
{
Type = "string",
Description = "The flight destination city"
}
}
},
new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }
)
};
ChatCompletionsFunctionToolDefinition getFlightTool = new ChatCompletionsFunctionToolDefinition(flightInfoFunction);
En este ejemplo, la salida de la función es que no hay vuelos disponibles para la ruta seleccionada, pero el usuario debe considerar la posibilidad de tomar un tren.
static string getFlightInfo(string loc_origin, string loc_destination)
{
return JsonSerializer.Serialize(new
{
info = $"There are no flights available from {loc_origin} to {loc_destination}. You " +
"should take a train, specially if it helps to reduce CO2 emissions."
});
}
Nota:
Los modelos de Cohere requieren que las respuestas de una herramienta sean un contenido JSON válido con formato de cadena. Al construir mensajes de tipo Tool, asegúrese de que la respuesta es una cadena JSON válida.
Pida al modelo que reserve vuelos con la ayuda de esta función:
var chatHistory = new List<ChatRequestMessage>(){
new ChatRequestSystemMessage(
"You are a helpful assistant that help users to find information about traveling, " +
"how to get to places and the different transportations options. You care about the" +
"environment and you always have that in mind when answering inqueries."
),
new ChatRequestUserMessage("When is the next flight from Miami to Seattle?")
};
requestOptions = new ChatCompletionsOptions(chatHistory);
requestOptions.Tools.Add(getFlightTool);
requestOptions.ToolChoice = ChatCompletionsToolChoice.Auto;
response = client.Complete(requestOptions);
Puede inspeccionar la respuesta para averiguar si es necesario llamar a una herramienta. Inspeccione el motivo de finalización para determinar si se debe llamar a la herramienta. Recuerde que se pueden indicar varios tipos de herramientas. En este ejemplo se muestra una herramienta de tipo function.
var responseMessage = response.Value;
var toolsCall = responseMessage.ToolCalls;
Console.WriteLine($"Finish reason: {response.Value.Choices[0].FinishReason}");
Console.WriteLine($"Tool call: {toolsCall[0].Id}");
Para continuar, anexe este mensaje al historial de chats:
requestOptions.Messages.Add(new ChatRequestAssistantMessage(response.Value));
Ahora es el momento de llamar a la función adecuada para controlar la llamada a la herramienta. El siguiente fragmento de código itera todas las llamadas a herramienta indicadas en la respuesta y llama a la función correspondiente con los parámetros adecuados. La respuesta también se anexa al historial de chat.
foreach (ChatCompletionsToolCall tool in toolsCall)
{
if (tool is ChatCompletionsFunctionToolCall functionTool)
{
// Get the tool details:
string callId = functionTool.Id;
string toolName = functionTool.Name;
string toolArgumentsString = functionTool.Arguments;
Dictionary<string, object> toolArguments = JsonSerializer.Deserialize<Dictionary<string, object>>(toolArgumentsString);
// Here you have to call the function defined. In this particular example we use
// reflection to find the method we definied before in an static class called
// `ChatCompletionsExamples`. Using reflection allows us to call a function
// by string name. Notice that this is just done for demonstration purposes as a
// simple way to get the function callable from its string name. Then we can call
// it with the corresponding arguments.
var flags = BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Static;
string toolResponse = (string)typeof(ChatCompletionsExamples).GetMethod(toolName, flags).Invoke(null, toolArguments.Values.Cast<object>().ToArray());
Console.WriteLine("->", toolResponse);
requestOptions.Messages.Add(new ChatRequestToolMessage(toolResponse, callId));
}
else
throw new Exception("Unsupported tool type");
}
Vea la respuesta del modelo:
response = client.Complete(requestOptions);
Aplicación de la seguridad del contenido
La API de inferencia de modelos de Azure AI admite Seguridad de contenido de Azure AI. Cuando se usan implementaciones con la seguridad de contenido de Azure AI activada, las entradas y las salidas pasan a través de un conjunto de modelos de clasificación destinados a detectar y evitar la salida de contenido perjudicial. El sistema de filtrado de contenido detecta y toma medidas en categorías específicas de contenido potencialmente perjudicial tanto en solicitudes de entrada como en finalizaciones de salida.
En el ejemplo siguiente se muestra cómo controlar eventos cuando el modelo detecta contenido perjudicial en el mensaje de entrada y la seguridad del contenido está habilitado.
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
Sugerencia
Para más información sobre cómo configurar y controlar la configuración de seguridad del contenido de Azure AI, consulte la Documentación de seguridad de contenido de Azure AI.
Uso de finalizaciones de chat con imágenes
Algunos modelos pueden razonar entre texto e imágenes y generar finalizaciones de texto basadas en ambos tipos de entrada. En esta sección, explorará las funcionalidades de algunos modelos para la visión en forma de chat:
Importante
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error.
Para ver esta funcionalidad, descargue una imagen y codifique la información como base64 cadena. Los datos resultantes deben estar dentro de una Dirección URL de datos:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Visualizar la imagen:
Ahora, cree una solicitud de finalización de chat con la imagen:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de finalizaciones de chat con modelos implementados en la inferencia de modelos de Azure AI en los servicios de Azure AI.
Requisitos previos
Para usar los modelos de finalización de chat en la aplicación, necesita:
Suscripción a Azure. Si usa Modelos de GitHub, puede actualizar la experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a la inferencia de modelos de Azure AI si es su caso.
Recurso de Servicios de Azure AI. Para más información, vea Creación de un recurso de Servicios de Azure AI.
Dirección URL y clave del punto de conexión.
- Una implementación del modelo de finalizaciones de chat. Si no tiene ninguna, lea Agregar y configurar modelos en los servicios de Azure AI para agregar un modelo de finalización de chat al recurso.
Uso de las finalizaciones de chat
Para usar las incrustaciones de texto, use la ruta /chat/completions anexada a la dirección URL base junto con la credencial indicada en api-key. El encabezado Authorization también se admite con el formato Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Si ha configurado el recurso para que admita Microsoft Entra ID, pase el token en el encabezado Authorization:
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Creación de una solicitud de finalización de chat
En el ejemplo siguiente, se muestra cómo crear solicitudes básicas de finalizaciones de chat al modelo.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
Nota:
Algunos modelos no admiten mensajes del sistema (role="system"). Cuando se usa la API de inferencia del modelo de Azure AI, los mensajes del sistema se traducen a los mensajes de usuario, que es la funcionalidad más cercana disponible. Esta traducción se ofrece para mayor comodidad, pero es importante comprobar que el modelo sigue las instrucciones del mensaje del sistema con el nivel de confianza correcto.
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Inspeccione la sección usage de la respuesta para ver el número de tokens usados para el aviso, el número total de tokens generados y el número de tokens usados para la finalización.
Streaming de contenido
De forma predeterminada, la API de finalizaciones devuelve todo el contenido generado en una única respuesta. Si está generando finalizaciones largas, esperar la respuesta puede tardar muchos segundos.
Puede transmitir el contenido para obtenerlo a medida que se genera. El contenido de streaming permite empezar a procesar la finalización a medida que el contenido está disponible. Este modo devuelve un objeto que transmite la respuesta como eventos enviados por el servidor de solo datos. Extraiga fragmentos del campo delta, en lugar del campo de mensaje.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
Puede visualizar cómo el streaming genera contenido:
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
El último mensaje de la secuencia ha establecido finish_reason, lo que indica el motivo para que se detenga el proceso de generación.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Exploración de más parámetros admitidos por el cliente de inferencia
Explore otros parámetros que puede especificar en el cliente de inferencia. Para obtener una lista completa de todos los parámetros admitidos y su documentación correspondiente, vea Referencia de la API de inferencia de modelos de Azure AI.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"presence_penalty": 0.1,
"frequency_penalty": 0.8,
"max_tokens": 2048,
"stop": ["<|endoftext|>"],
"temperature" :0,
"top_p": 1,
"response_format": { "type": "text" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Algunos modelos no admiten el formato de salida JSON. Siempre puede pedir al modelo que genere salidas JSON. Sin embargo, no se garantiza que estas salidas sean JSON válidas.
Si desea pasar un parámetro que no está en la lista de parámetros admitidos, puede pasarlo al modelo subyacente mediante parámetros adicionales. Vea Pasar parámetros adicionales al modelo.
Creación de salidas JSON
Algunos modelos pueden crear salidas JSON. Establezca el response_format en json_object para habilita el modo JSON y garantizar que el mensaje que genera el modelo es JSON válido. También debe indicar al modelo que genere JSON usted mismo mediante un mensaje de usuario o sistema. Además, el contenido del mensaje puede cortarse parcialmente si finish_reason="length", que indica que la generación superó max_tokens o que la conversación superó la longitud máxima del contexto.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that always generate responses in JSON format, using the following format: { \"answer\": \"response\" }"
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"response_format": { "type": "json_object" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718727522,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"answer\": \"There are approximately 7,117 living languages in the world today, according to the latest estimates. However, this number can vary as some languages become extinct and others are newly discovered or classified.\"}",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 87,
"completion_tokens": 48
}
}
Pase de parámetros adicionales al modelo
La API de inferencia de modelos de Azure AI permite pasar parámetros adicionales al modelo. En el ejemplo de código siguiente se muestra cómo pasar el parámetro adicional logprobs al modelo.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Authorization: Bearer <TOKEN>
Content-Type: application/json
extra-parameters: pass-through
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"logprobs": true
}
Antes de pasar parámetros adicionales a la API de inferencia del modelo de Azure AI, asegúrese de que el modelo admite esos parámetros adicionales. Cuando se realiza la solicitud al modelo subyacente, el encabezado extra-parameters se pasa al modelo con el valor pass-through. Este valor indica al punto de conexión que pase los parámetros adicionales al modelo. El uso de parámetros adicionales con el modelo no garantiza que el modelo pueda controlarlos realmente. Lea la documentación del modelo para comprender qué parámetros adicionales se admiten.
Uso de herramientas
Algunos modelos admiten el uso de herramientas, que puede ser un recurso extraordinario cuando necesita descargar tareas específicas del modelo de lenguaje y, en su lugar, confiar en un sistema más determinista o incluso en un modelo de lenguaje diferente. La API de inferencia de modelos de Azure AI permite definir herramientas de la siguiente manera.
En el ejemplo de código siguiente se crea una definición de herramienta que puede buscar a partir de información de vuelo de dos ciudades diferentes.
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
En este ejemplo, la salida de la función es que no hay vuelos disponibles para la ruta seleccionada, pero el usuario debe considerar la posibilidad de tomar un tren.
Nota:
Los modelos de Cohere requieren que las respuestas de una herramienta sean un contenido JSON válido con formato de cadena. Al construir mensajes de tipo Tool, asegúrese de que la respuesta es una cadena JSON válida.
Pida al modelo que reserve vuelos con la ayuda de esta función:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
]
}
Puede inspeccionar la respuesta para averiguar si es necesario llamar a una herramienta. Inspeccione el motivo de finalización para determinar si se debe llamar a la herramienta. Recuerde que se pueden indicar varios tipos de herramientas. En este ejemplo se muestra una herramienta de tipo function.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726007,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0dF1gh",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
"finish_reason": "tool_calls",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 190,
"total_tokens": 226,
"completion_tokens": 36
}
}
Para continuar, anexe este mensaje al historial de chats:
Ahora es el momento de llamar a la función adecuada para controlar la llamada a la herramienta. El siguiente fragmento de código itera todas las llamadas a herramienta indicadas en la respuesta y llama a la función correspondiente con los parámetros adecuados. La respuesta también se anexa al historial de chat.
Vea la respuesta del modelo:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0DeFgH",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
{
"role": "tool",
"content": "{ \"info\": \"There are no flights available from Miami to Seattle. You should take a train, specially if it helps to reduce CO2 emissions.\" }",
"tool_call_id": "abc0DeFgH"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters":{
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": ["origin_city", "destination_city"]
}
}
}
]
}
Aplicación de la seguridad del contenido
La API de inferencia de modelos de Azure AI admite Seguridad de contenido de Azure AI. Cuando se usan implementaciones con la seguridad de contenido de Azure AI activada, las entradas y las salidas pasan a través de un conjunto de modelos de clasificación destinados a detectar y evitar la salida de contenido perjudicial. El sistema de filtrado de contenido detecta y toma medidas en categorías específicas de contenido potencialmente perjudicial tanto en solicitudes de entrada como en finalizaciones de salida.
En el ejemplo siguiente se muestra cómo controlar eventos cuando el modelo detecta contenido perjudicial en el mensaje de entrada y la seguridad del contenido está habilitado.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are an AI assistant that helps people find information."
},
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
Sugerencia
Para más información sobre cómo configurar y controlar la configuración de seguridad del contenido de Azure AI, consulte la Documentación de seguridad de contenido de Azure AI.
Uso de finalizaciones de chat con imágenes
Algunos modelos pueden razonar entre texto e imágenes y generar finalizaciones de texto basadas en ambos tipos de entrada. En esta sección, explorará las funcionalidades de algunos modelos para la visión en forma de chat:
Importante
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error.
Para ver esta funcionalidad, descargue una imagen y codifique la información como base64 cadena. Los datos resultantes deben estar dentro de una Dirección URL de datos:
Sugerencia
Tendrá que construir la dirección URL de datos mediante un scripting o un lenguaje de programación. En este tutorial se usa esta imagen de ejemplo en formato JPEG. Una dirección URL de datos tiene un formato como sigue: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
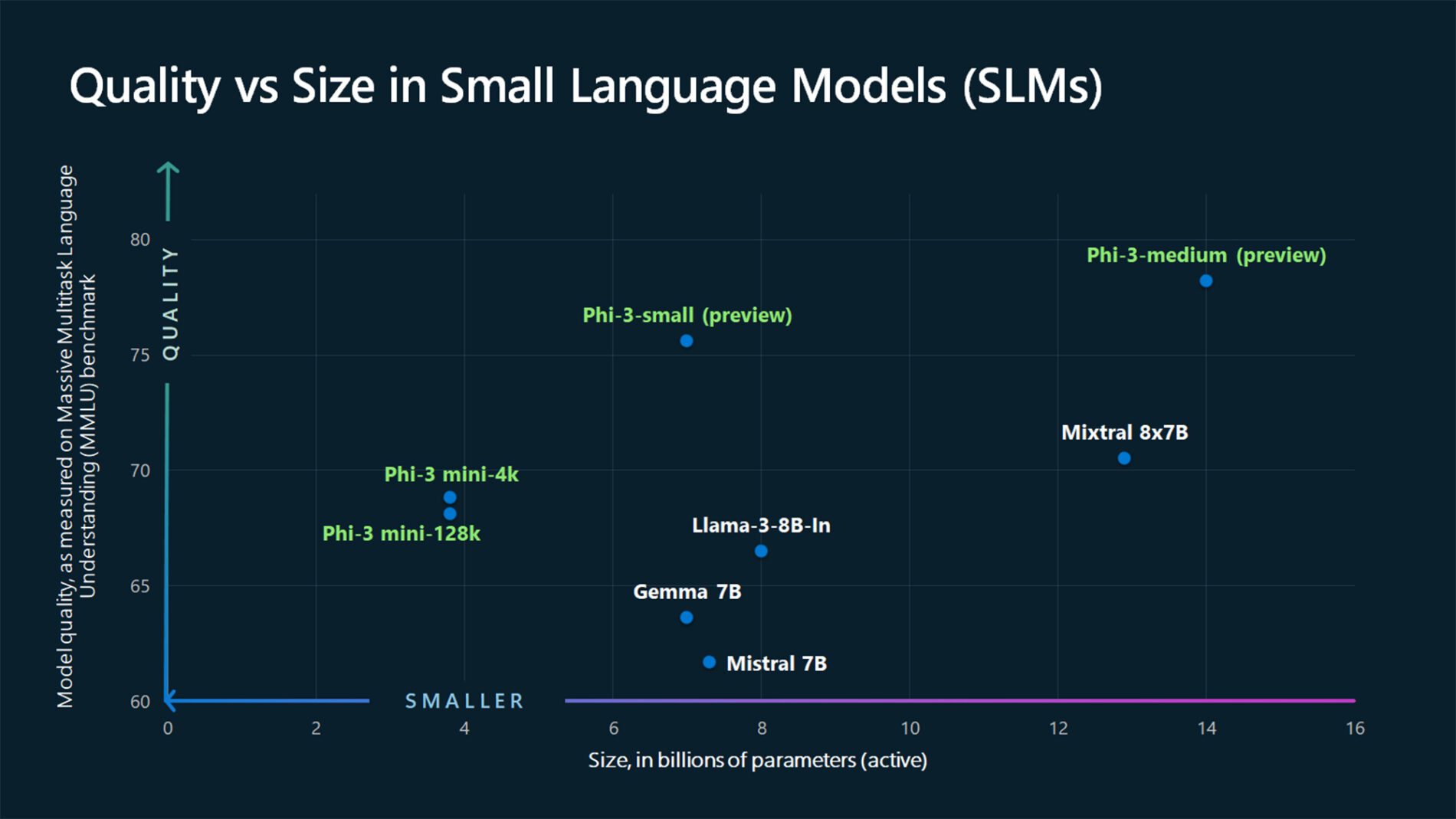{kind=link}
Visualizar la imagen:
Ahora, cree una solicitud de finalización de chat con la imagen:
{
"model": "phi-3.5-vision-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
La respuesta es la siguiente, donde puede ver las estadísticas de uso del modelo:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "phi-3.5-vision-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}