Explore data in your mirrored database with notebooks
You can explore the data replicated from your mirrored database with Spark queries in notebooks.
Notebooks are a powerful code item for you to develop Apache Spark jobs and machine learning experiments on your data. You can use notebooks in the Fabric Lakehouse to explore your mirrored tables.
Prerequisites
- Complete the tutorial to create a mirrored database from your source database.
- Tutorial: Configure Microsoft Fabric mirrored database for Azure Cosmos DB (Preview)
- Tutorial: Configure Microsoft Fabric mirrored databases from Azure Databricks (Preview)
- Tutorial: Configure Microsoft Fabric mirrored databases from Azure SQL Database
- Tutorial: Configure Microsoft Fabric mirrored databases from Azure SQL Managed Instance (Preview)
- Tutorial: Configure Microsoft Fabric mirrored databases from Snowflake
Create a shortcut
You first need to create a shortcut from your mirrored tables into the Lakehouse, and then build notebooks with Spark queries in your Lakehouse.
In the Fabric portal, open Data Engineering.
If you don't have a Lakehouse created already, select Lakehouse and create a new Lakehouse by giving it a name.
Select Get Data -> New shortcut.
Select Microsoft OneLake.
You can see all your mirrored databases in the Fabric workspace.
Select the mirrored database you want to add to your Lakehouse, as a shortcut.
Select desired tables from the mirrored database.
Select Next, then Create.
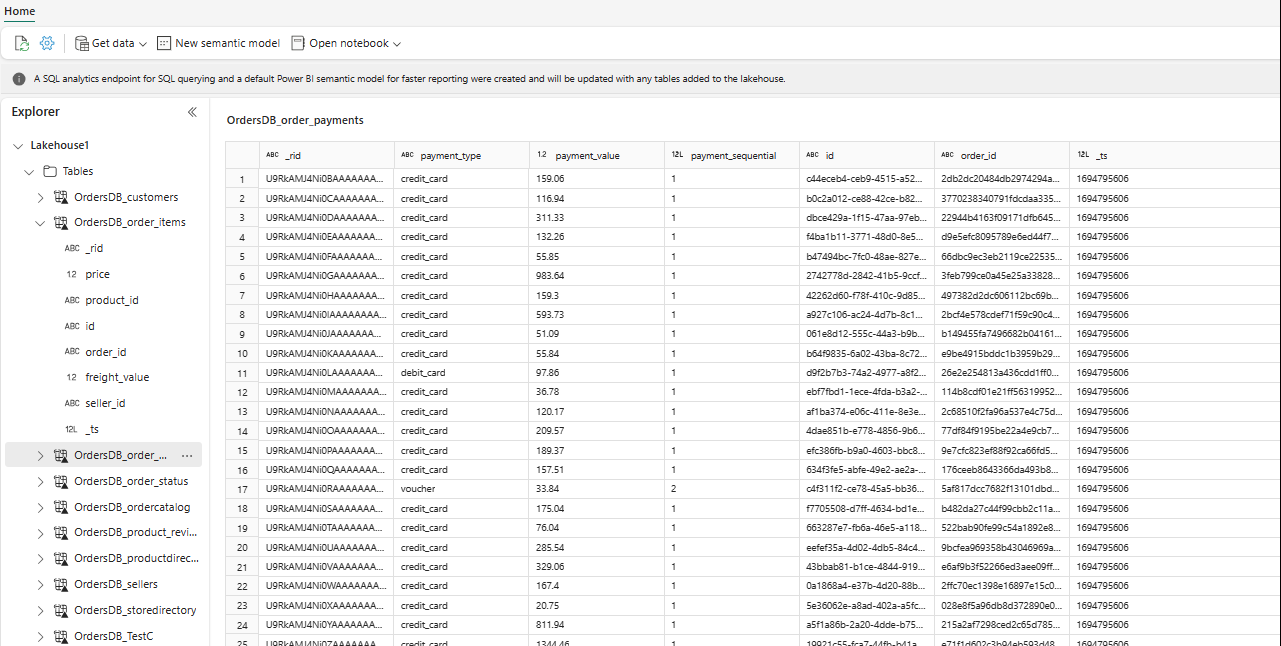
In the Explorer, you can now see selected table data in your Lakehouse.
Tip
You can add other data in Lakehouse directly or bring shortcuts like S3, ADLS Gen2. You can navigate to the SQL analytics endpoint of the Lakehouse and join the data across all these sources with mirrored data seamlessly.
To explore this data in Spark, select the
...dots next to any table. Select New notebook or Existing notebook to begin analysis.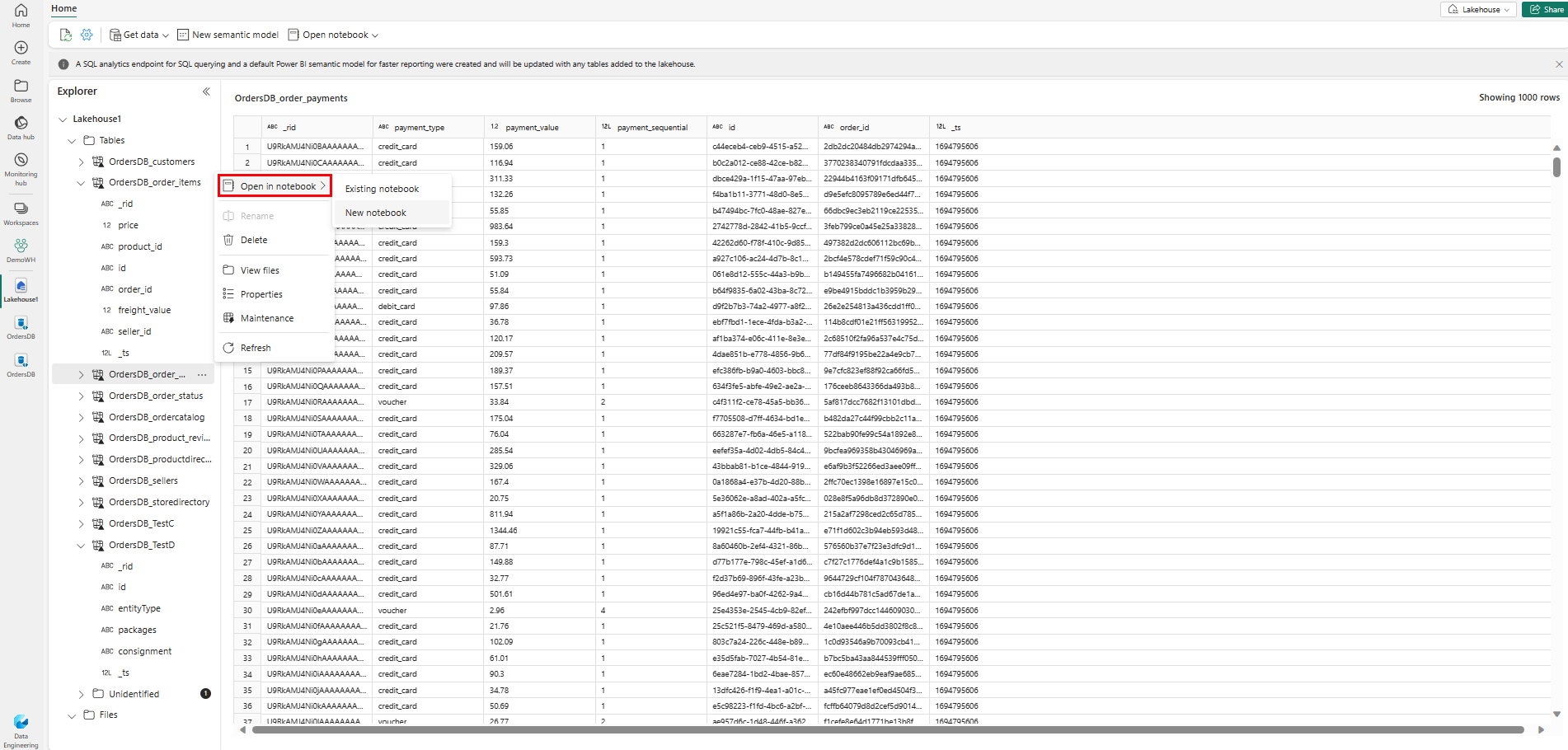
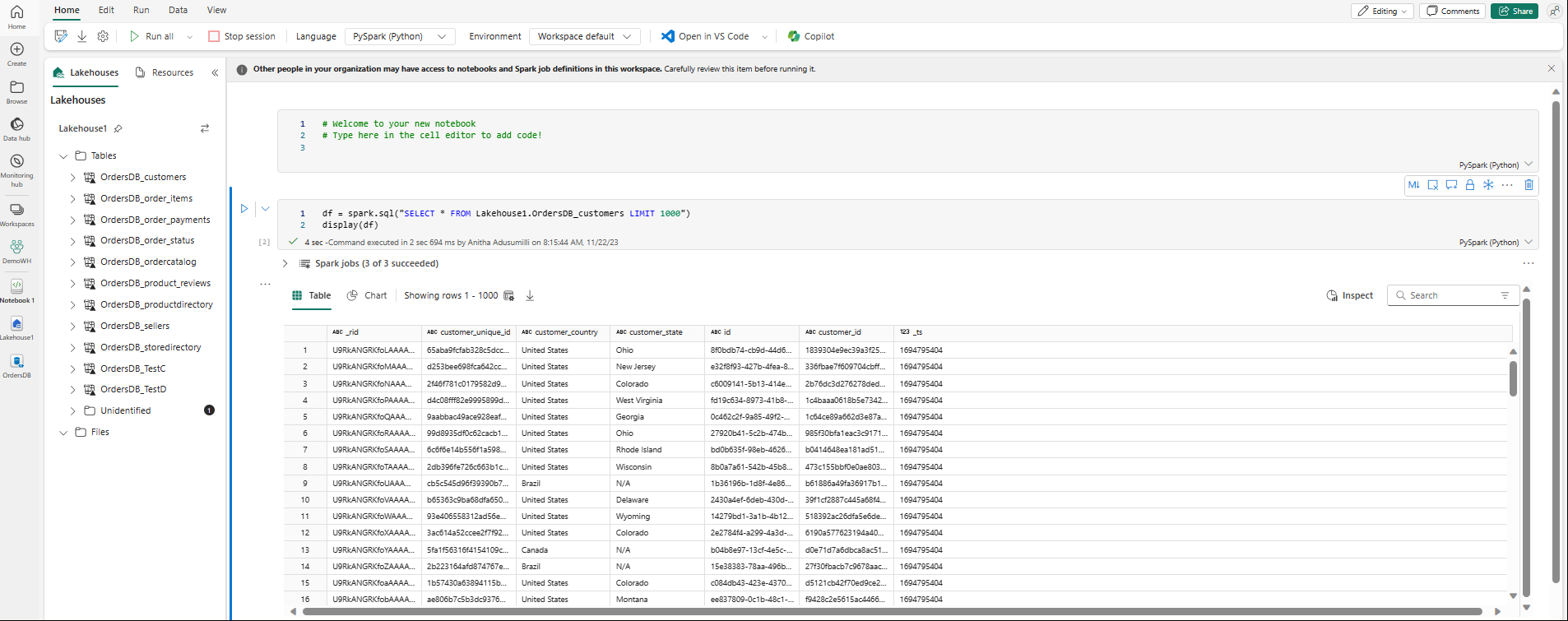
The notebook will automatically open and the load the dataframe with a
SELECT ... LIMIT 1000Spark SQL query.- New notebooks can take up to two minutes to load completely. You can avoid this delay by using an existing notebook with an active session.
- New notebooks can take up to two minutes to load completely. You can avoid this delay by using an existing notebook with an active session.


