Migrate Hive Metastore metadata from Azure Synapse Analytics to Fabric
The initial step in the Hive Metastore (HMS) migration involves determining the databases, tables, and partitions you want to transfer. It's not necessary to migrate everything; you can select specific databases. When identifying databases for migration, make sure to verify if there are managed or external Spark tables.
For HMS considerations, refer to differences between Azure Synapse Spark and Fabric.
Note
Alternatively, if your ADLS Gen2 contains Delta tables, you can create a OneLake shortcut to a Delta table in ADLS Gen2.
Prerequisites
- If you don’t have one already, create a Fabric workspace in your tenant.
- If you don’t have one already, create a Fabric lakehouse in your workspace.
Option 1: Export and import HMS to lakehouse metastore
Follow these key steps for migration:
- Step 1: Export metadata from source HMS
- Step 2: Import metadata into Fabric lakehouse
- Post-migration steps: Validate content
Note
Scripts only copy Spark catalog objects to Fabric lakehouse. Assumption is that the data is already copied (for example, from warehouse location to ADLS Gen2) or available for managed and external tables (for example, via shortcuts—preferred) into the Fabric lakehouse.
Step 1: Export metadata from source HMS
The focus of Step 1 is on exporting the metadata from source HMS to the Files section of your Fabric lakehouse. This process is as follows:
1.1) Import HMS metadata export notebook into your Azure Synapse workspace. This notebook queries and exports HMS metadata of databases, tables, and partitions to an intermediate directory in OneLake (functions not included yet). Spark internal catalog API is used in this script to read catalog objects.
1.2) Configure the parameters in the first command to export metadata information to an intermediate storage (OneLake). The following snippet is used to configure the source and destination parameters. Ensure to replace them with your own values.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Run all notebook commands to export catalog objects to OneLake. Once cells are completed, this folder structure under the intermediate output directory is created.
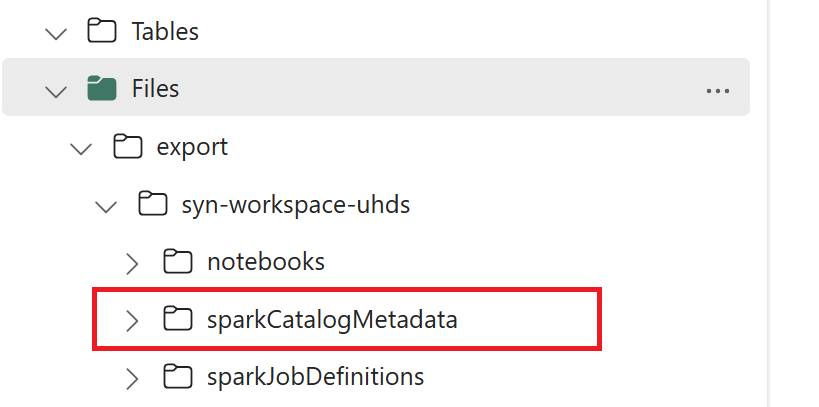
Step 2: Import metadata into Fabric lakehouse
Step 2 is when the actual metadata is imported from intermediate storage into the Fabric lakehouse. The output of this step is to have all HMS metadata (databases, tables, and partitions) migrated. This process is as follows:
2.1) Create a shortcut within the “Files” section of the lakehouse. This shortcut needs to point to the source Spark warehouse directory and is used later to do the replacement for Spark managed tables. See shortcut examples pointing to Spark warehouse directory:
- Shortcut path to Azure Synapse Spark warehouse directory:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Shortcut path to Azure Databricks warehouse directory:
dbfs:/mnt/<warehouse_dir> - Shortcut path to HDInsight Spark warehouse directory:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Shortcut path to Azure Synapse Spark warehouse directory:
2.2) Import HMS metadata import notebook into your Fabric workspace. Import this notebook to import database, table, and partition objects from intermediate storage. Spark internal catalog API is used in this script to create catalog objects in Fabric.
2.3) Configure the parameters in the first command. In Apache Spark, when you create a managed table, the data for that table is stored in a location managed by Spark itself, typically within the Spark's warehouse directory. The exact location is determined by Spark. This contrasts with external tables, where you specify the location and manage the underlying data. When you migrate the metadata of a managed table (without moving the actual data), the metadata still contains the original location information pointing to the old Spark warehouse directory. Hence, for managed tables,
WarehouseMappingsis used to do the replacement using the shortcut created in Step 2.1. All source managed tables are converted as external tables using this script.LakehouseIdrefers to the lakehouse created in Step 2.1 containing shortcuts.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Run all notebook commands to import catalog objects from intermediate path.
Note
When importing multiple databases, you can (i) create one lakehouse per database (the approach used here), or (ii) move all tables from different databases to a single lakehouse. For the latter, all migrated tables could be <lakehouse>.<db_name>_<table_name>, and you will need to adjust the import notebook accordingly.
Step 3: Validate content
Step 3 is where you validate that metadata has been migrated successfully. See different examples.
You can see the databases imported by running:
%%sql
SHOW DATABASES
You can check all tables in a lakehouse (database) by running:
%%sql
SHOW TABLES IN <lakehouse_name>
You can see the details of a particular table by running:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
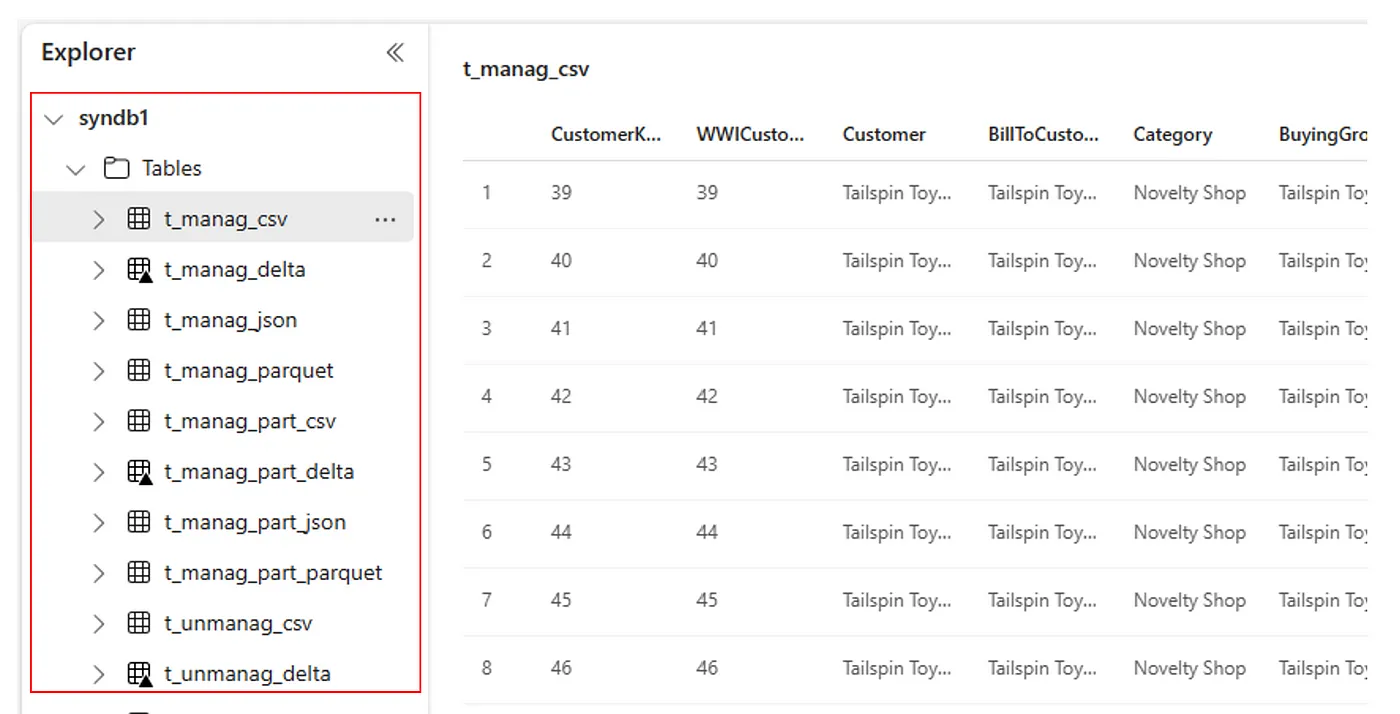
Alternatively, all imported tables are visible within the Lakehouse explorer UI Tables section for each lakehouse.
Other considerations
- Scalability: The solution here's using internal Spark catalog API to do import/export, but it isn't connecting directly to HMS to get catalog objects, so the solution couldn't scale well if the catalog is large. You would need to change the export logic using HMS DB.
- Data accuracy: There's no isolation guarantee, which means that if the Spark compute engine is doing concurrent modifications to the metastore while the migration notebook is running, inconsistent data can be introduced in Fabric lakehouse.
Related content
- Fabric vs. Azure Synapse Spark
- Learn more about migration options for Spark pools, configurations, libraries, notebooks and Spark job definition