Migrate Spark job definition from Azure Synapse to Fabric
To move Spark job definitions (SJD) from Azure Synapse to Fabric, you have two different options:
- Option 1: create Spark job definition manually in Fabric.
- Option 2: you can use a script to export Spark job definitions from Azure Synapse and import them in Fabric using the API.
For Spark job definition considerations, refer to differences between Azure Synapse Spark and Fabric.
Prerequisites
If you don’t have one already, create a Fabric workspace in your tenant.
Option 1: Create Spark job definition manually
To export a Spark job definition from Azure Synapse:
- Open Synapse Studio: Sign-in into Azure. Navigate to your Azure Synapse workspace and open the Synapse Studio.
- Locate the Python/Scala/R Spark job: Find and identify the Python/Scala/R Spark job definition that you want to migrate.
- Export the job definition configuration:
- In Synapse Studio, open the Spark Job Definition.
- Export or note down the configuration settings, including script file location, dependencies, parameters, and any other relevant details.
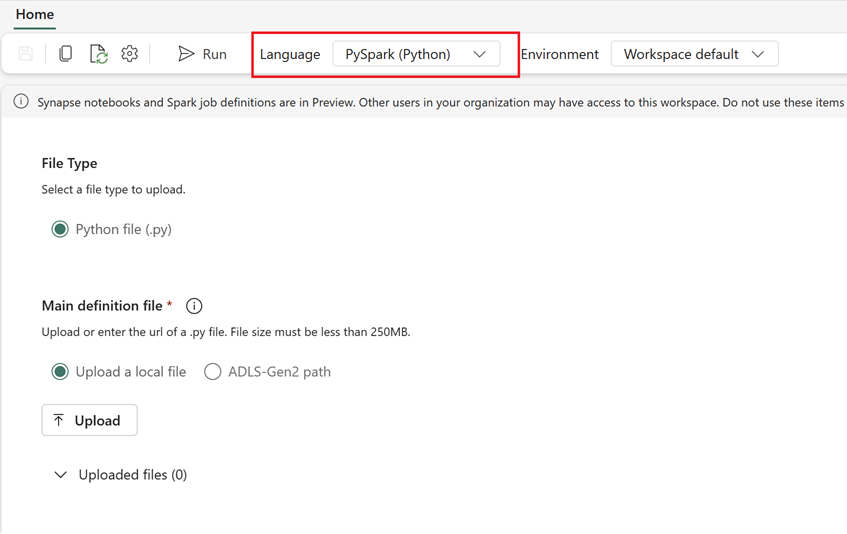
To create a new Spark job definition (SJD) based on the exported SJD information in Fabric:
- Access Fabric workspace: Sign in to Fabric and access your workspace.
- Create a new Spark job definition in Fabric:
- In Fabric, go to Data Engineering homepage.
- Select Spark Job Definition.
- Configure the job using the information you exported from Synapse, including script location, dependencies, parameters, and cluster settings.
- Adapt and test: Make any necessary adaptation to the script or configuration to suit the Fabric environment. Test the job in Fabric to ensure it runs correctly.
Once the Spark job definition is created, validate dependencies:
- Ensure using the same Spark version.
- Validate the existence of the main definition file.
- Validate the existence of the referenced files, dependencies, and resources.
- Linked services, data source connections and mount points.
Learn more about how to create an Apache Spark job definition in Fabric.
Option 2: Use the Fabric API
Follow these key steps for migration:
- Prerequisites.
- Step 1: Export Spark job definition from Azure Synapse to OneLake (.json).
- Step 2: Import Spark job definition automatically into Fabric using the Fabric API.
Prerequisites
The prerequisites include actions you need to consider before starting Spark job definition migration to Fabric.
- A Fabric workspace.
- If you don’t have one already, create a Fabric lakehouse in your workspace.
Step 1: Export Spark job definition from Azure Synapse workspace
The focus of Step 1 is on exporting Spark job definition from Azure Synapse workspace to OneLake in json format. This process is as follows:
- 1.1) Import SJD migration notebook to Fabric workspace. This notebook exports all Spark job definitions from a given Azure Synapse workspace to an intermediate directory in OneLake. Synapse API is used to export SJD.
- 1.2) Configure the parameters in the first command to export Spark job definition to an intermediate storage (OneLake). This only exports the json metadata file. The following snippet is used to configure the source and destination parameters. Ensure to replace them with your own values.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
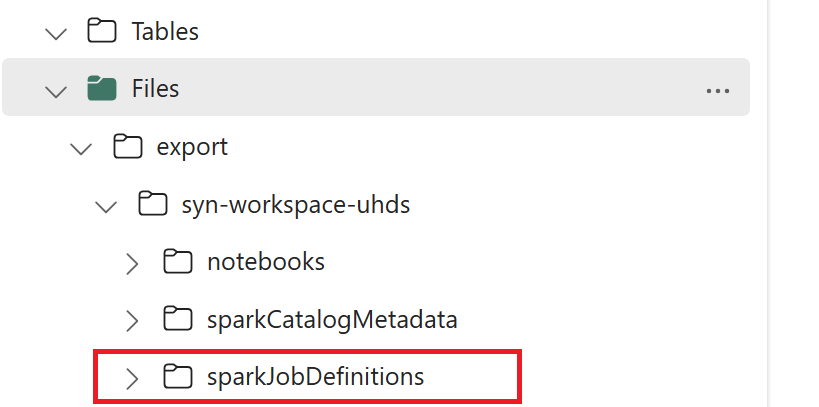
- 1.3) Run the first two cells of the export/import notebook to export Spark job definition metadata to OneLake. Once cells are completed, this folder structure under the intermediate output directory is created.
Step 2: Import Spark job definition into Fabric
Step 2 is when Spark job definitions are imported from intermediate storage into the Fabric workspace. This process is as follows:
- 2.1) Validate the configurations in the 1.2 to ensure the right workspace and prefix are indicated to import the Spark job definitions.
- 2.2) Run the third cell of the export/import notebook to import all Spark job definitions from intermediate location.
Note
The export option outputs a json metadata file. Ensure that Spark job definition executable files, reference files, and arguments are accessible from Fabric.