Integrieren des Databricks Unity-Katalogs in OneLake
Dieses Szenario zeigt, wie externe Delta-Tabellen aus dem Unity-Katalog mit Hilfe von Shortcuts in OneLake integriert werden können. Nach diesem Tutorial werden Sie in der Lage sein, Ihre externen Delta-Tabellen aus dem Unity-Katalog automatisch mit einem Microsoft Fabric Lakehouse zu synchronisieren.
Voraussetzungen
Bevor Sie beginnen können, benötigen Sie Folgendes:
- Ein Fabric-Arbeitsbereich.
- Ein Fabric Lakehouse in Ihrem Arbeitsbereich.
- Externe Unity Catalog Delta-Tabellen, die in Ihrem Azure Databricks-Arbeitsbereich erstellt wurden.
Einrichten Ihrer Cloud Storage-Verbindung
Überprüfen Sie zunächst, welche Speicherorte in Azure Data Lake Storage Gen2 (ADLS Gen2) Ihre Unity Catalog-Tabellen verwenden. Diese Cloud-Speicherverbindung wird von OneLake-Verknüpfungen verwendet. So erstellen Sie eine Cloudverbindung mit dem entsprechenden Unity-Katalogspeicherort:
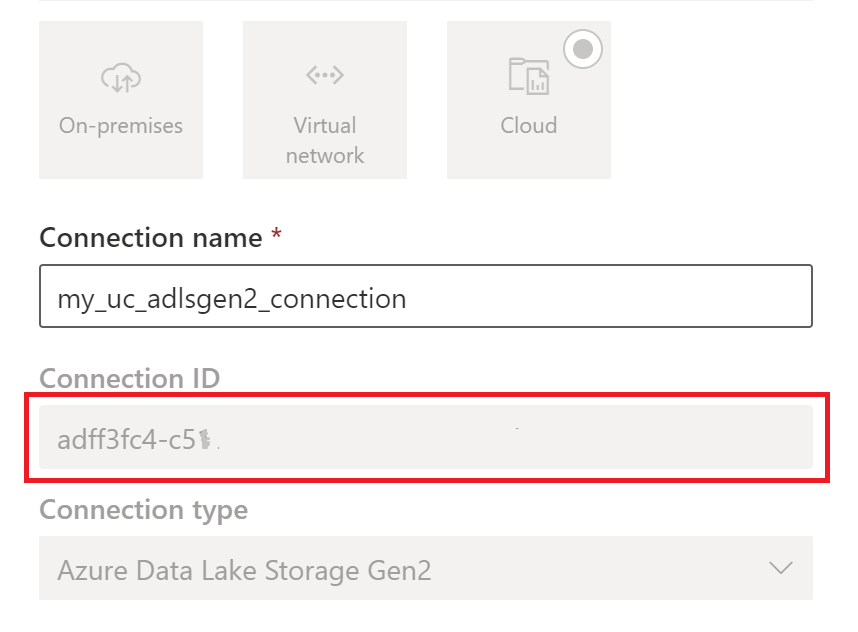
Erstellen Sie eine Cloud-Speicherverbindung, die von Ihren Unity Catalog-Tabellen verwendet wird. Erfahren Sie, wie Sie eine ADLS Gen2-Verbindung einrichten.
Nachdem Sie die Verbindung erstellt haben, rufen Sie die Verbindungs-ID ab, indem Sie Einstellungen
 >Verbindungen und Gateways verwalten>Verbindungen>Einstellungen auswählen.
>Verbindungen und Gateways verwalten>Verbindungen>Einstellungen auswählen.
Hinweis
Die Gewährung von direktem Speicherzugriff auf externe Speicherorte in ADLS Gen2 berücksichtigt keine von Unity Catalog gewährten Berechtigungen oder durchgeführten Audits. Der direkte Zugriff umgeht Überwachung, Herkunft und andere Sicherheits- und Überwachungsfunktionen von Unity Catalog, einschließlich Zugriffskontrolle und Berechtigungen. Sie sind für die Verwaltung des direkten Speicherzugriffs über ADLS Gen2 verantwortlich und stellen sicher, dass die Benutzer die entsprechenden Berechtigungen über Fabric erhalten. Vermeiden Sie alle Szenarien, die direkten Schreibzugriff auf Speicherebene für Buckets gewähren, die von Databricks verwaltete Tabellen speichern. Das Ändern, Löschen oder Entwickeln von Objekten direkt über den Speicher, die ursprünglich von Unity Catalog verwaltet wurden, kann zu einer Datenbeschädigung führen.
Ausführen des Notebooks
Sobald Sie die Cloud-Verbindungs-ID erhalten haben, integrieren Sie die Tabellen des Unity-Katalogs wie folgt in das Fabric Lakehouse:
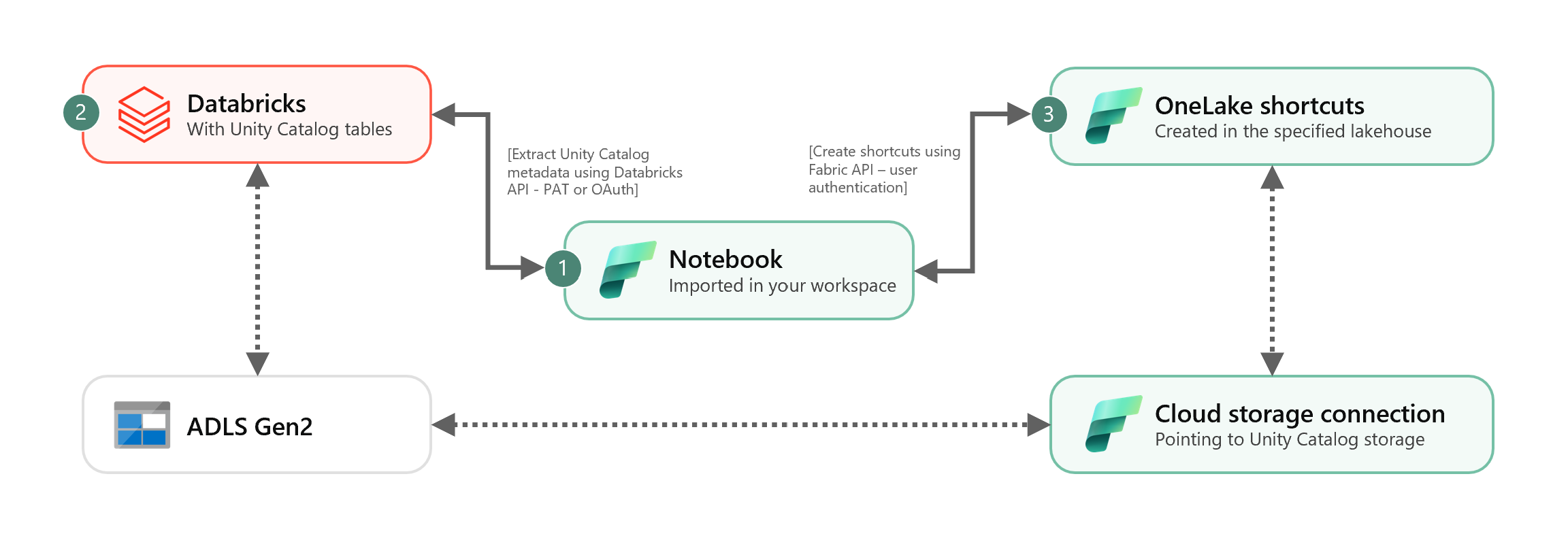
Importieren Sie Synchronisierungs-Notebook in Ihren Fabric-Arbeitsbereich. Dieses Notizbuch exportiert alle Metadaten von Unity-Katalogtabellen aus einem bestimmten Katalog und Schemata in Ihrem Metastore.
Konfigurieren Sie die Parameter in der ersten Zelle des Notebooks, um Unity Catalog-Tabellen zu integrieren. Für den Export von Unity-Catalog-Tabellen wird die Databricks-API verwendet, die durch PAT-Token authentifiziert wird. Der folgende Codeschnipsel wird verwendet, um die Quellparameter (Unity Catalog) und Zielparameter (OneLake) zu konfigurieren. Diese müssen durch Ihre eigenen Werte ersetzt werden.
# Databricks workspace dbx_workspace = "<databricks_workspace_url>" dbx_token = "<pat_token>" # Unity Catalog dbx_uc_catalog = "catalog1" dbx_uc_schemas = '["schema1", "schema2"]' # Fabric fab_workspace_id = "<workspace_id>" fab_lakehouse_id = "<lakehouse_id>" fab_shortcut_connection_id = "<connection_id>" # If True, UC table renames and deletes will be considered fab_consider_dbx_uc_table_changes = TrueFühren Sie alle Zellen des Notebooks aus, um mit der Synchronisierung von Unity Catalog Delta-Tabellen mit OneLake mithilfe von Tastenkombinationen zu beginnen. Nach Abschluss des Notebooks stehen Verknüpfungen zu Unity Catalog Delta-Tabellen im Lakehouse, SQL-Analysenendpunkt und semantischen Modell zur Verfügung.
Planen des Notebooks
Wenn Sie das Notebook in regelmäßigen Abständen ausführen möchten, um Unity Catalog Delta-Tabellen in OneLake zu integrieren, ohne dass eine manuelle Neusynchronisierung/ein erneuter Lauf erforderlich ist, können Sie das Notebook entweder planen oder eine Notebook-Aktivität in einer Datenpipeline innerhalb von Fabric Data Factory verwenden.
Wenn Sie im letzten Szenario Parameter aus der Datenpipeline übergeben möchten, legen Sie die erste Zelle des Notebooks als Umschaltparameterzelle fest und stellen Sie die entsprechenden Parameter in der Pipeline bereit.

Andere Aspekte
- Für Produktionsszenarien empfehlen wir die Verwendung von Databricks OAuth für die Authentifizierung und Azure Key Vault für die Verwaltung von Geheimnissen. Sie können zum Beispiel die MSSparkUtils-Dienstprogramme für Anmeldeinformationen verwenden, um auf die Geheimnisse des Schlüsseltresors zuzugreifen.
- Das Notebook funktioniert mit externen Delta-Tabellen im Unity-Katalog. Wenn Sie mehrere Cloud-Speicherorte für Ihre Unity-Katalog-Tabellen verwenden, d. h. mehr als einen ADLS Gen2, wird empfohlen, das Notebook für jede Cloud-Verbindung separat auszuführen.
- Von Unity Catalog verwaltete Delta-Tabellen, Ansichten, materialisierte Ansichten, Streaming-Tabellen und Nicht-Delta-Tabellen werden nicht unterstützt.
- Änderungen an den Tabellenschemata des Unity-Katalogs, wie das Hinzufügen/Löschen von Spalten, werden automatisch in den Verknüpfungen berücksichtigt. Einige Aktualisierungen, wie das Umbenennen und Löschen von Tabellen im Unity-Katalog, erfordern jedoch eine erneute Synchronisierung/einen erneuten Start des Notebooks. Dies wird von
fab_consider_dbx_uc_table_changes-Parametern berücksichtigt. - Bei Schreibszenarien kann die Verwendung derselben Speicherebene für verschiedene Recheneinheiten zu unbeabsichtigten Folgen führen. Achten Sie darauf, dass Sie die Auswirkungen bei der Verwendung verschiedener Apache Spark-Compute-Engines und -Laufzeitversionen verstehen.