Umfassendes Lakehouse-Szenario: Übersicht und Architektur
Microsoft Fabric ist eine All-in-One-Analyselösung für Unternehmen, die alles von der Datenverschiebung über Data Science bis hin zu Echtzeitanalysen und Business Intelligence abdeckt. Die Lösung bietet eine umfassende Suite von Services (einschließlich Data Lake, Datentechnik und Datenintegration an einem Ort). Weitere Informationen finden Sie unter Was ist Microsoft Fabric?.
Dieses Tutorial führt Sie von der Datenerfassung bis zur Datennutzung durch ein umfassendes Szenario. Es hilft Ihnen, ein grundlegendes Verständnis von Fabric zu entwickeln (einschließlich der verschiedenen Funktionen und deren Integration sowie der Funktionen für Expert*innen und Citizen Developers, die bei der Nutzung dieser Plattform verwendet werden). Dieses Tutorial ist nicht als Referenzarchitektur, vollständige Liste von Features und Funktionen oder als Empfehlung bestimmter bewährter Methoden vorgesehen.
Umfassendes Lakehouse-Szenario
Üblicherweise haben Organisationen moderne Data Warehouses für ihre transaktionsbezogenen und strukturierten Datenanalyseanforderungen entwickelt. Data Lakehouses sind für Datenanalyseanforderungen im Zusammenhang mit Big Data (teilweise strukturiert bzw. unstrukturiert) konzipiert. Diese beiden Systeme wurden parallel ausgeführt, was zu Silos, Datenduplizierungen und erhöhten Gesamtkosten führte.
Fabric mit seiner Vereinheitlichung des Datenspeichers und der Standardisierung im Delta Lake-Format ermöglicht es Ihnen, Silos zu beseitigen, Datenduplizierungen zu verhindern und die Gesamtkosten erheblich zu reduzieren.
Dank der Flexibilität, die Fabric bietet, können Sie entweder Lakehouse- oder Data Warehouse-Architekturen implementieren oder kombinieren, um die Vorteile beider Optionen bei einfacher Implementierung nutzen zu können. In diesem Tutorial wird eine Einzelhandelsorganisation als Beispiel verwendet, deren Lakehouse Sie von den anfänglichen Schritten bis zur finalen Version erstellen. Dabei wird die Medallionarchitektur verwendet, bei der die Bronzeebene die Rohdaten, die Silberebene die validierten und deduplizierten Daten und die Goldebene hochgradig optimierte Daten umfasst. Sie können den gleichen Ansatz verwenden, um ein Lakehouse für jede Organisation aus einer beliebigen Branche zu implementieren.
In diesem Tutorial wird erläutert, wie Entwickler*innen des fiktiven Unternehmens Wide World Importers aus der Einzelhandelsbranche die folgenden Schritte ausführen:
Anmelden bei einem Power BI-Konto und Registrieren für die kostenlose Microsoft Fabric-Testversion. Wenn Sie nicht über eine Power BI-Lizenz verfügen, können Sie sich für eine kostenlose Fabric-Lizenz registrieren und dann die Fabric-Testversion starten.
Erstellen und Implementieren eines umfassenden Lakehouse für die Organisation:
- Erstellen eines Fabric-Arbeitsbereichs
- Erstellen eines Lakehouse
- Erfassen, Transformieren und Laden von Daten in das Lakehouse. Sie können außerdem die von OneLake erstellte Kopie Ihrer Daten im Lakehouse- und SQL-Analyseendpunktmodus untersuchen.
- Herstellen einer Verbindung mit dem Lakehouse mithilfe des SQL-Analyseendpunkts und Erstellen eines Power BI-Berichts mithilfe von DirectLake zum Analysieren von Vertriebsdaten in verschiedenen Dimensionen
- Optional können Sie die Datenerfassung und den Transformationsablauf mit einer Pipeline orchestrieren und planen.
Bereinigen von Ressourcen durch Löschen des Arbeitsbereichs und anderer Elemente
Aufbau
Die folgende Abbildung zeigt die umfassende Lakehouse-Architektur. Die beteiligten Komponenten werden in der folgenden Liste beschrieben.
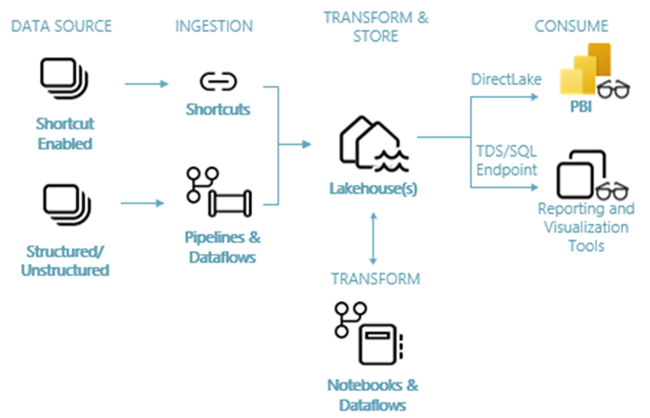
Datenquellen: Mit Fabric können Sie für eine optimierte Datenerfassung schnell und einfach eine Verbindung mit Azure Data Services sowie anderen cloudbasierten Plattformen und lokalen Datenquellen herstellen.
Erfassung: Mithilfe von mehr als 200 nativen Connectors können Sie schnell Erkenntnisse für Ihre Organisation gewinnen. Diese Connectors sind in die Fabric-Pipeline integriert und nutzen die benutzerfreundliche Drag-and-Drop-Datentransformation mit Dataflow. Darüber hinaus können Sie mit dem Verknüpfungsfeature in Fabric eine Verbindung mit vorhandenen Daten herstellen, ohne sie kopieren oder verschieben zu müssen.
Transformieren und Speichern: Für Fabric wird das Delta Lake-Standardformat verwendet. Das bedeutet, dass alle Fabric-Engines auf dasselbe in OneLake gespeicherte Dataset zugreifen und es bearbeiten können, ohne Daten zu duplizieren. Dieses Speichersystem bietet die Flexibilität, Lakehouses mithilfe einer Medaillonarchitektur oder eines Data Meshs zu erstellen (in Abhängigkeit von Ihren Organisationsanforderungen). Sie können zwischen einem Low-Code- oder No-Code-Ansatz für die Datentransformation wählen und entweder Pipelines und Dataflow oder Notebooks und Spark für eine Code-First-Umgebung verwenden.
Verwendung: Power BI kann Daten aus dem Lakehouse für die Berichterstellung und Visualisierung verwenden. Jedes Lakehouse verfügt über einen integrierten TDS-Endpunkt namens SQL-Analyseendpunkt für einfache Konnektivität und das Abfragen von Daten in den Lakehouse-Tabellen aus anderen Berichtstools. Der SQL-Analyseendpunkt stellt Benutzer*innen die SQL-Verbindungsfunktionalität bereit.
Beispieldataset
In diesem Lernprogramm wird die WWI-Beispieldatenbank (Wide World Importers) verwendet, die Sie im nächsten Lernprogramm in das Lakehouse importieren wird. Für das umfassende Lakehouse-Szenario wurden ausreichend Daten generiert, um die Skalierungs- und Leistungsfunktionen der Fabric-Plattform testen zu können.
Wide World Importers (WWI) ist ein Importeur und Großhändler von neuartigen Waren in der San Francisco Bay Area. Als Großhändler hat WWI hauptsächlich Unternehmen als Kunden, die ihre Produkte an Einzelpersonen weiterverkaufen. WWI verkauft an Einzelhandelskunden in den USA. Zu ihnen gehören Fachgeschäfte, Supermärkte, Computergeschäfte, touristische Geschäfte und einige Einzelpersonen. WWI verkauft seine Produkte über Zwischenhändler, die die Produkte im Auftrag von WWI bewerben, auch an andere Großhändler. Weitere Informationen zum Unternehmensprofil und -betrieb finden Sie unter Wide World Importers-Beispieldatenbanken für Microsoft SQL.
In der Regel werden Daten aus Transaktionssystemen oder Branchenanwendungen in ein Lakehouse eingefügt. Aus Gründen der Einfachheit wird in diesem Tutorial das von WWI bereitgestellte Dimensionsmodell als erste Datenquelle verwendet. Es wird als Quelle verwendet, um die Daten in einem Lakehouse zu erfassen und sie in verschiedenen Phasen einer Medaillonarchitektur (Bronze, Silber und Gold) zu transformieren.
Datenmodell
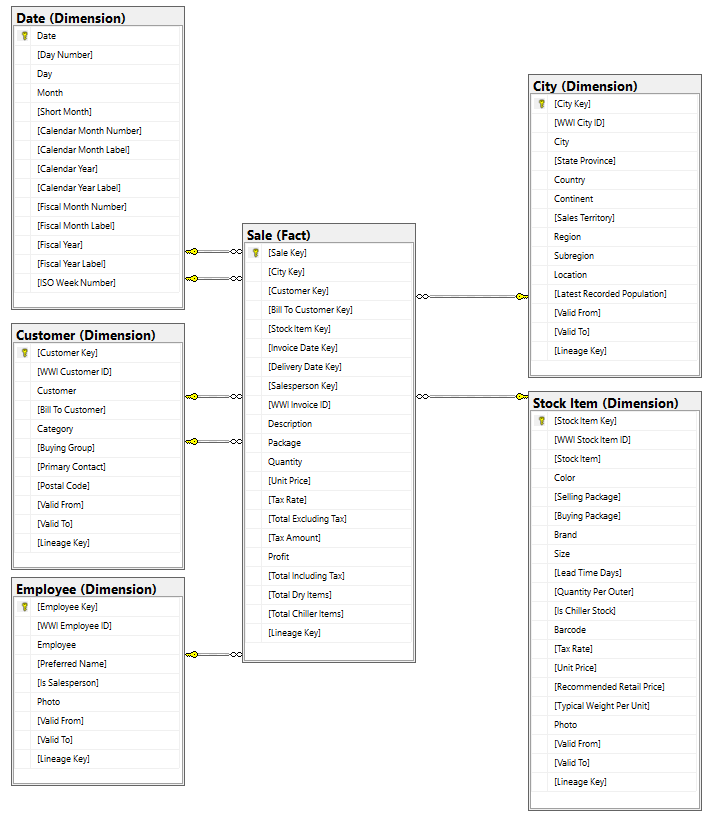
Während das WWI-Dimensionsmodell zahlreiche Faktentabellen enthält, werden für dieses Tutorial die Sale-Faktentabelle und ihre korrelierten Dimensionen verwendet. Das folgende Beispiel veranschaulicht das WWI-Datenmodell:
Datenfluss und Ablauf der Transformation
Wie bereits beschrieben, werden die Beispieldaten aus der Beispieldatenbank für Wide World Importers (WWI) verwendet, um dieses umfassende Lakehouse zu erstellen. In dieser Implementierung werden die Beispieldaten in einem Azure Data Storage-Konto im Parquet-Dateiformat für alle Tabellen gespeichert. In realen Szenarios stammen Daten jedoch in der Regel aus verschiedenen Quellen und liegen in unterschiedlichen Formaten vor.
Die folgende Abbildung zeigt die Quelle, das Ziel und die Datentransformation:
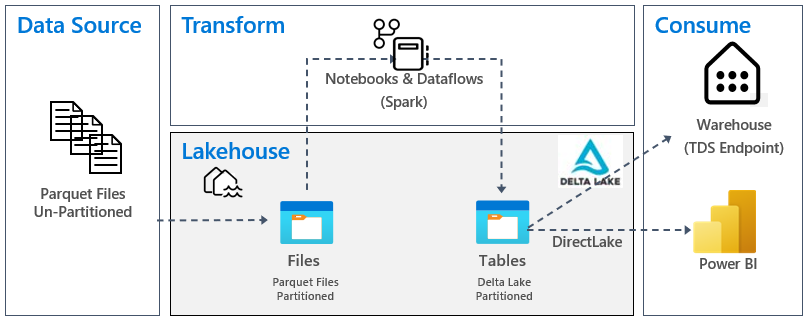
Datenquelle: Die Quelldaten liegen im Parquet-Dateiformat vor und weisen eine nicht partitionierte Struktur auf. Sie werden in einem Ordner für jede Tabelle gespeichert. In diesem Tutorial richten Sie eine Pipeline ein, um die gesamten Verlaufsdaten oder einmaligen Daten im Lakehouse zu erfassen.
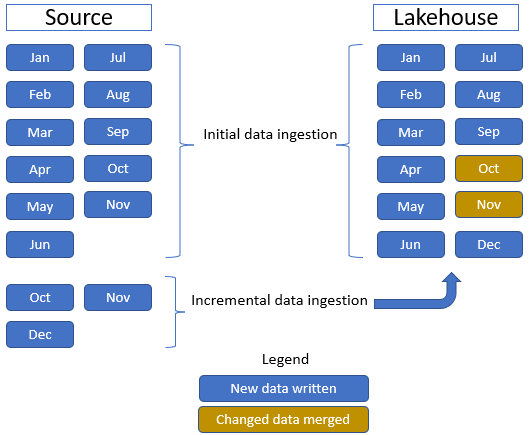
Sie verwenden die Sale-Faktentabelle, die einen übergeordneten Ordner mit Verlaufsdaten für elf Monate (mit einem Unterordner für jeden Monat) und einen anderen Ordner umfasst, der inkrementelle Daten für drei Monate enthält (ein Unterordner für jeden Monat). Während der ersten Datenerfassung werden Daten für einen Zeitraum von elf Monaten in der Lakehouse-Tabelle erfasst. Wenn die inkrementellen Daten jedoch eingefügt werden, enthalten sie aktualisierte Daten für „Oct“ und „Nov“ sowie neue Daten für „Dec“. Die Daten für „Oct“ und „Nov“ werden mit den vorhandenen Daten zusammengeführt, und die neuen Daten für „Dec“ werden wie in der folgenden Abbildung gezeigt in die Lakehouse-Tabelle geschrieben:
Lakehouse: In diesem Tutorial erstellen Sie ein Lakehouse, erfassen Daten im Dateiabschnitt des Lakehouse und erstellen dann Delta Lake-Tabellen im Abschnitt „Tabellen“ des Lakehouse.
Transformieren: Für die Datenaufbereitung und -transformation werden zwei verschiedene Ansätze angezeigt. Die Verwendung von Notebooks und Spark wird für Benutzer*innen erläutert, die einen Code-First-Ansatz bevorzugen, während sich Pipelines und Dataflow für Benutzer*innen eignen, die einen Low-Code- oder No-Code-Ansatz verwenden möchten.
Verwendung: Zur Veranschaulichung der Datennutzung wird erläutert, wie Sie das DirectLake-Feature von Power BI verwenden können, um Berichte und Dashboards zu erstellen und Daten direkt aus dem Lakehouse abzufragen. Darüber hinaus erfahren Sie, wie Sie Ihre Daten mithilfe des TDS-/SQL-Analyseendpunkts für Berichterstellungstools von Drittanbietern verfügbar machen können. Mit diesem Endpunkt können Sie eine Verbindung mit dem Warehouse herstellen und SQL-Abfragen für Analysen ausführen.