Lakehouse-Tutorial: Aufbereiten und Transformieren von Daten im Lakehouse
In diesem Tutorial verwenden Sie Notebooks mit der Spark-Runtime, um Rohdaten in Ihrem Lakehouse zu transformieren und aufzubereiten.
Voraussetzungen
Wenn Sie kein Lakehouse haben, das Daten enthält, müssen Sie:
Vorbereiten von Daten
In den vorherigen Tutorialschritten haben Sie Rohdaten aus der Quelle im Abschnitt Dateien des Lakehouse erfasst. Jetzt können Sie diese Daten transformieren und für die Erstellung von Deltatabellen aufbereiten.
Laden Sie die Notebooks aus dem Ordner Lakehouse Tutorial Source Code herunter.
Wählen Sie über die Option unten links auf dem Bildschirm die Option Datentechnik aus.

Wählen Sie oben auf der Startseite im Abschnitt Neu die Option Notebook importieren aus.
Wählen Sie im Bereich Importstatus, der auf der rechten Seite des Bildschirms geöffnet wird, die Option Hochladen aus.
Wählen Sie alle Notebooks aus, die Sie im ersten Schritt dieses Abschnitts heruntergeladen haben.
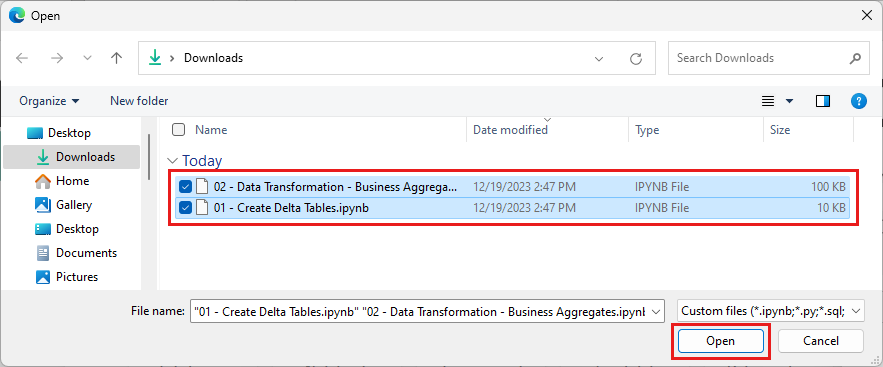
Klicken Sie auf Öffnen. In der oberen rechten Ecke des Browserfensters wird eine Benachrichtigung zum Importstatus angezeigt.
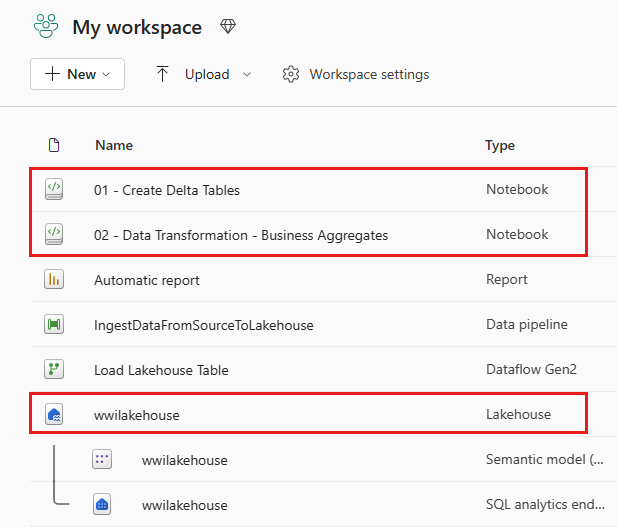
Wenn der Import erfolgreich war, wechseln Sie zur Elementansicht des Arbeitsbereichs, um die neu importierten Notebooks anzuzeigen. Wählen Sie das Lakehouse wwilakehouse aus, um es zu öffnen.
Nachdem das Lakehouse wwilakehouse geöffnet wurde, wählen Sie im oberen Navigationsmenü Notebook öffnen>Vorhandenes Notebook aus.
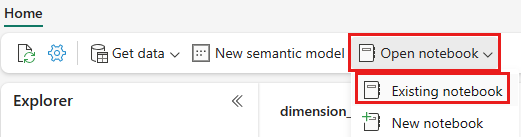
Wählen Sie in der Liste der vorhandenen Notebooks das Notebook 01 – Create Delta Tables aus, und klicken Sie auf Öffnen.
Im geöffneten Notebook im Lakehouse-Explorer sehen Sie, dass das Notebook bereits mit Ihrem geöffneten Lakehouse verknüpft ist.
Hinweis
Fabric bietet die Funktion für die V-Reihenfolge zum Schreiben optimierter Delta-Lake-Dateien. Die V-Reihenfolge verbessert die Komprimierung häufig um das Drei- bis Vierfache und ermöglicht die bis zu 10-fache Leistungsbeschleunigung im Vergleich zu den nicht optimierten Delta-Lake-Dateien. Spark optimiert Partitionen in Fabric dynamisch, während Dateien mit einer Standardgröße von 128 MB generiert werden. Die Zieldateigröße kann je nach Workload-Anforderungen mithilfe von Konfigurationen geändert werden.
Mithilfe der Funktion Schreiben optimieren kann die Apache Spark-Engine die Anzahl der geschriebenen Dateien reduzieren und versuchen, die jeweilige Dateigröße der geschriebenen Daten zu erhöhen.
Bevor Sie Daten als Delta-Lake-Tabellen im Abschnitt Tabellen des Lakehouse schreiben, verwenden Sie zwei Fabric-Features (V-Reihenfolge und Schreiben optimieren) für das optimierte Schreiben von Daten und eine verbesserte Leseleistung. Um diese Features in Ihrer Sitzung zu aktivieren, legen Sie diese Konfigurationen in der ersten Zelle Ihres Notebooks fest.
Um das Notebook zu starten und alle Zellen nacheinander auszuführen, wählen Sie auf dem oberen Menüband (unter Start) die Option Alle ausführen aus. Wenn Sie nur Code aus einer bestimmten Zelle ausführen möchten, wählen Sie das Symbol zum Ausführen aus, das beim Daraufzeigen links neben der Zelle angezeigt wird, oder drücken Sie UMSCHALT+EINGABETASTE auf der Tastatur, während sich das Steuerelement in der Zelle befindet.
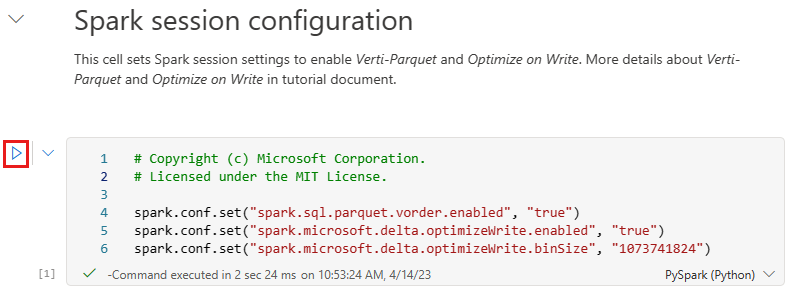
Beim Ausführen einer Zelle mussten Sie die zugrunde liegenden Spark-Pool- oder Clusterdetails nicht angeben, da Fabric sie über „Live Pool“ bereitstellt. Jeder Fabric-Arbeitsbereich enthält einen Spark-Standardpool namens „Live Pool“. Dies bedeutet, dass Sie sich beim Erstellen von Notebooks keine Gedanken über die Angabe von Spark-Konfigurationen oder Clusterdetails machen müssen. Wenn Sie den ersten Notebookbefehl ausführen, ist „Live Pool“ in wenigen Sekunden betriebsbereit. Außerdem wird die Spark-Sitzung eingerichtet, und sie beginnt mit der Ausführung des Codes. Die nachfolgende Codeausführung erfolgt in diesem Notebook nahezu unverzüglich, während die Spark-Sitzung aktiv ist.
Als Nächstes lesen Sie Rohdaten aus dem Abschnitt Dateien des Lakehouse und fügen im Rahmen der Transformation weitere Spalten für verschiedene Datumsteile hinzu. Verwenden Sie schließlich die Partitionierung durch die Spark-API, um die Daten zu partitionieren, bevor Sie sie im Delta-Tabellenformat auf der Grundlage der neu erstellten Datenteilspalten (Jahr und Quartal) schreiben.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)Nachdem die Faktentabellen geladen wurden, können Sie mit dem Laden von Daten für die restlichen Dimensionen fortfahren. Die folgende Zelle erstellt eine Funktion zum Lesen von Rohdaten aus dem Abschnitt Dateien des Lakehouse für jeden Tabellennamen, der als Parameter übergeben wird. Als Nächstes wird eine Liste der Dimensionstabellen erstellt. Schließlich wird die Liste der Tabellen durchlaufen und eine Deltatabelle für jeden Tabellennamen erstellt, der aus dem Eingabeparameter gelesen wird. Beachten Sie, dass das Skript in diesem Beispiel die mit
Photobezeichnete Spalte entfernt, da sie nicht verwendet wird.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Um die erstellten Tabellen zu überprüfen, klicken Sie mit der rechten Maustaste, und wählen Sie die Option zum Aktualisieren für das Lakehouse wwilakehouse aus. Die Tabellen werden angezeigt.
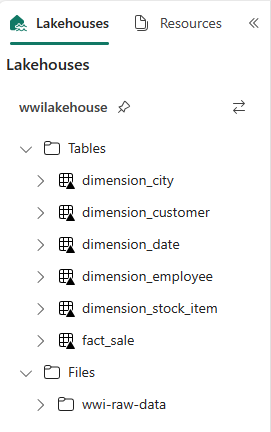
Wechseln Sie erneut in die Elementansicht des Arbeitsbereichs, und wählen Sie das Lakehouse wwilakehouse aus, um es zu öffnen.
Öffnen Sie nun das zweite Notebook. Wählen Sie in der Lakehouse-Ansicht auf dem Menüband Notebook öffnen>Vorhandenes Notebook aus.
Wählen Sie in der Liste der vorhandenen Notebooks das Notebook 02 – Data Transformation – Business aus, um es zu öffnen.
Im geöffneten Notebook im Lakehouse-Explorer sehen Sie, dass das Notebook bereits mit Ihrem geöffneten Lakehouse verknüpft ist.
Möglicherweise verwenden einige technische Fachkräfte für Daten in einer Organisation Scala/Python, andere hingegen SQL (Spark SQL oder T-SQL), wobei alle an derselben Kopie der Daten arbeiten. Fabric ermöglicht die Zusammenarbeit dieser verschiedenen Gruppen mit unterschiedlichen Erfahrungswerten und Präferenzen. Die beiden verschiedenen Ansätze transformieren und generieren Geschäftsaggregationen. Sie können den für Sie geeigneten Ansatz auswählen oder diese Ansätze basierend auf Ihren Präferenzen kombinieren und anpassen, ohne die Leistung zu beeinträchtigen:
Ansatz 1: Verwenden Sie PySpark, um Daten zum Generieren von Geschäftsaggregationen zusammenzufassen und zu aggregieren. Dieser Ansatz eignet sich für Personen, die sich mit der Programmierung befassen (Python oder PySpark).
Ansatz 2: Verwenden Sie Spark SQL, um Daten zum Generieren von Geschäftsaggregationen zusammenzufassen und zu aggregieren. Dieser Ansatz eignet sich für Personen mit SQL-Hintergrund beim Wechsel zu Spark.
Ansatz 1 (sale_by_date_city): Verwenden Sie PySpark, um Daten zum Generieren von Geschäftsaggregationen zusammenzufassen und zu aggregieren. Mit dem folgenden Code erstellen Sie drei verschiedene Spark-Dataframes, die jeweils auf eine vorhandene Deltatabelle verweisen. Anschließend verknüpfen Sie diese Tabellen mithilfe der Dataframes, gruppieren sie, um eine Aggregation zu generieren, benennen einige Spalten um und schreiben sie schließlich als Deltatabelle im Abschnitt Tabellen des Lakehouse, um die Daten beizubehalten.
In dieser Zelle erstellen Sie drei verschiedene Spark-Dataframes, die jeweils auf eine vorhandene Deltatabelle verweisen.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Fügen Sie der gleichen Zelle den folgenden Code hinzu, um diese Tabellen mithilfe der zuvor erstellten Datenframes zu verknüpfen. Verwenden Sie „Gruppieren nach“, um Aggregation zu generieren, benennen Sie einige der Spalten um, und schreiben Sie sie schließlich als Delta-Tabelle in den Tables-Abschnitt des Lakehouse.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Ansatz 2 (sale_by_date_employee): Verwenden Sie Spark SQL, um Daten zum Generieren von Geschäftsaggregationen zusammenzufassen und zu aggregieren. Mit dem folgenden Code erstellen Sie eine temporäre Spark-Ansicht, indem Sie drei Tabellen verknüpfen, sie gruppieren, um eine Aggregation zu generieren, und einige der Spalten umbenennen. Schließlich lesen Sie Daten aus der temporären Spark-Ansicht und schreiben sie schließlich als Deltatabelle im Abschnitt Tabellen des Lakehouse, um die Daten beizubehalten.
In dieser Zelle erstellen Sie eine temporäre Spark-Ansicht, indem Sie drei Tabellen verknüpfen, sie gruppieren, um eine Aggregation zu generieren, und einige der Spalten umbenennen.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCIn dieser Zelle lesen Sie Daten aus der temporären Spark-Ansicht, die in der vorherigen Zelle erstellt wurde, und schreiben sie schließlich als Deltatabelle im Abschnitt Tabellen des Lakehouse.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Um die erstellten Tabellen zu überprüfen, klicken Sie mit der rechten Maustaste, und wählen Sie die Option zum Aktualisieren für das Lakehouse wwilakehouse aus. Die Aggregationstabellen werden angezeigt.
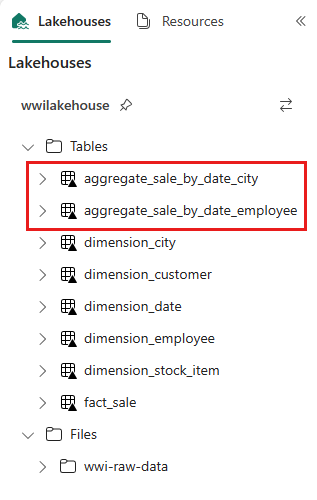
Die beiden Ansätze führen zu einem ähnlichen Ergebnis. Um die Notwendigkeit zu minimieren, eine neue Technologie zu erlernen oder Kompromisse bei der Leistung einzugehen, wählen Sie den Ansatz, der am besten zu Ihrem Hintergrund und Ihren Vorlieben passt.
Vielleicht fällt Ihnen auf, dass Sie die Daten als Delta Lake-Dateien schreiben. Das Feature für die automatische Tabellenermittlung und -registrierung von Fabric erfasst sie und registriert sie im Metastore. Sie müssen CREATE TABLE-Anweisungen nicht explizit aufrufen, um Tabellen für die Verwendung mit SQL zu erstellen.