Migrieren von Metadaten des Hive-Metastores von Azure Synapse zu Fabric
Der erste Schritt bei der Migration des Hive-Metastore (HMS) umfasst die Ermittlung der Datenbanken, Tabellen und Partitionen, die Sie übertragen möchten. Es ist nicht notwendig, alles zu migrieren; Sie können auch nur bestimmte Datenbanken auswählen. Stellen Sie beim Identifizieren von Datenbanken für die Migration sicher, ob verwaltete oder externe Spark-Tabellen vorhanden sind.
Informationen zu HMS-Aspekten finden Sie unter Unterschiede zwischen Azure Synapse Spark und Fabric.
Hinweis
Wenn Ihre ADLS Gen2-Instanz Delta-Tabellen enthält, können Sie alternativ eine OneLake-Verknüpfung mit einer Delta-Tabelle in ADLS Gen2 erstellen.
Voraussetzungen
- Erstellen Sie einen Fabric-Arbeitsbereich in Ihrem Mandanten, falls dies noch nicht erfolgt ist.
- Erstellen Sie ein Fabric Lakehouse in Ihrem Arbeitsbereich, falls dies noch nicht erfolgt ist.
Option 1: Exportieren und Importieren eines HMS in den Lakehouse-Metastore
Führen Sie die folgenden wichtigen Schritte für die Migration aus:
- Schritt 1: Exportieren von Metadaten aus dem Quell-HMS
- Schritt 2: Importieren von Metadaten in das Fabric-Lakehouse
- Schritte nach der Migration: Überprüfen von Inhalten
Hinweis
Skripts kopieren nur Spark-Katalogobjekte in das Fabric-Lakehouse. Es wird angenommen, dass die Daten bereits kopiert wurden (z. B. vom Warehousespeicherort in ADLS Gen2) oder für verwaltete und externe Tabellen (z. B. über Verknüpfungen – die bevorzugte Methode) im Fabric-Lakehouse verfügbar sind.
Schritt 1: Exportieren von Metadaten aus dem Quell-HMS
Der Schwerpunkt von Schritt 1 liegt auf dem Exportieren der Metadaten aus dem Quell-HMS in den Abschnitt „Dateien“ Ihres Fabric-Lakehouse. Der Prozess lautet wie folgt:
1.1) Importieren Sie das Notebook für den HMS-Metadatenexport in Ihren Azure Synapse-Arbeitsbereich. Dieses Notebook fragt HMS-Metadaten von Datenbanken, Tabellen und Partitionen ab und exportiert sie in ein Zwischenverzeichnis in OneLake (Funktionen sind noch nicht enthalten). Die interne Spark-Katalog-API wird in diesem Skript verwendet, um Katalogobjekte zu lesen.
1.2) Konfigurieren Sie die Parameter im ersten Befehl zum Exportieren von Metadateninformationen in einen Zwischenspeicher (OneLake). Das folgende Codeschnipsel wird verwendet, um die Quell- und Zielparameter zu konfigurieren. Stellen Sie sicher, dass Sie sie durch Ihre eigenen Werte ersetzen.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Führen Sie alle Notebookbefehle aus, um Katalogobjekte nach OneLake zu exportieren. Nach Abschluss der Zellen wird diese Ordnerstruktur unter dem Zwischenausgabeverzeichnis erstellt.
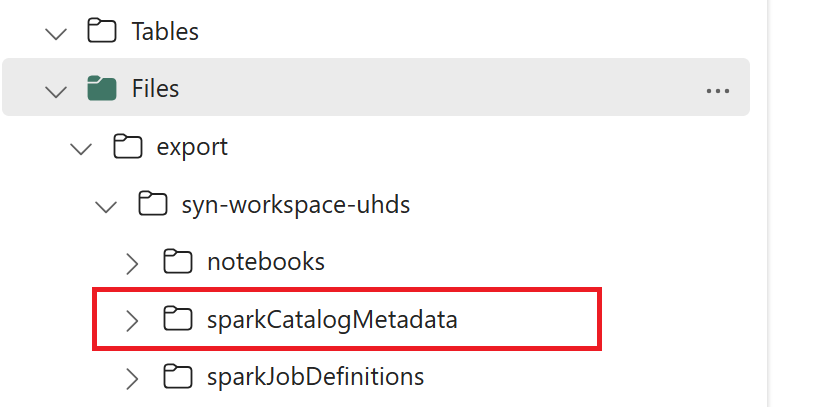
Schritt 2: Importieren von Metadaten in das Fabric-Lakehouse
Schritt 2 erfolgt, wenn die tatsächlichen Metadaten aus dem Zwischenspeicher in das Fabric-Lakehouse importiert werden. Die Ausgabe dieses Schritts besteht darin, dass alle HMS-Metadaten (Datenbanken, Tabellen und Partitionen) migriert werden. Der Prozess lautet wie folgt:
2.1) Erstellen Sie eine Verknüpfung im Abschnitt „Dateien“ des Lakehouse. Diese Verknüpfung muss auf das Spark Warehouse-Quellverzeichnis verweisen und später verwendet werden, um den Ersatz für verwaltete Spark-Tabellen bereitzustellen. Weitere Details finden Sie in den Verknüpfungsbeispielen, die auf das Spark-Warehouseverzeichnis verweisen:
- Verknüpfungspfad zum Azure Synapse Spark-Warehouseverzeichnis:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Verknüpfungspfad zum Azure Databricks-Warehouseverzeichnis:
dbfs:/mnt/<warehouse_dir> - Verknüpfungspfad zum HDInsight Spark-Warehouseverzeichnis:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Verknüpfungspfad zum Azure Synapse Spark-Warehouseverzeichnis:
2.2) Importieren Sie das HMS-Notebook für den Metadatenimport in Ihren Fabric-Arbeitsbereich. Importieren Sie dieses Notebook, um Datenbank-, Tabellen- und Partitionsobjekte aus dem Zwischenspeicher zu importieren. Die interne Spark-Katalog-API wird in diesem Skript verwendet, um Katalogobjekte in Fabric zu erstellen.
2.3) Konfigurieren Sie die Parameter im ersten Befehl. Wenn Sie eine verwaltete Tabelle in Apache Spark erstellen, werden die Daten für diese Tabelle an einem von Spark selbst verwalteten Speicherort gespeichert, der sich in der Regel innerhalb des Spark-Warehouseverzeichnisses befindet. Die genaue Position wird von Spark bestimmt. Dies steht im Gegensatz zu externen Tabellen, bei denen Sie den Speicherort angeben und die zugrunde liegenden Daten verwalten. Wenn Sie die Metadaten einer verwalteten Tabelle migrieren (ohne die tatsächlichen Daten zu verschieben), enthalten die Metadaten weiterhin die ursprünglichen Speicherortinformationen, die auf das alte Spark-Warehouseverzeichnis verweisen. Daher wird für verwaltete Tabellen
WarehouseMappingsfür die Ersetzung mithilfe der in Schritt 2.1 erstellten Verknüpfung verwendet. Alle verwalteten Quelltabellen werden mithilfe dieses Skripts in externe Tabellen konvertiert.LakehouseIdbezieht sich auf das Lakehouse, das in Schritt 2.1 erstellt wurde, das Verknüpfungen enthält.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Führen Sie alle Notebookbefehle aus, um Katalogobjekte aus dem Zwischenpfad zu importieren.
Hinweis
Beim Importieren mehrerer Datenbanken können Sie (i) ein Lakehouse pro Datenbank erstellen (der hier verwendete Ansatz), oder (ii) alle Tabellen aus verschiedenen Datenbanken in ein einzelnes Lakehouse verschieben. Für die zweite Methode können alle migrierten Tabellen <lakehouse>.<db_name>_<table_name> sein, und Sie müssen das Notebook für den Import entsprechend anpassen.
Schritt 3: Überprüfen von Inhalten
In Schritt 3 überprüfen Sie, ob Metadaten erfolgreich migriert wurden. Sehen Sie sich verschiedene Beispiele an.
Sie können die importierten Datenbanken anzeigen, indem Sie Folgendes ausführen:
%%sql
SHOW DATABASES
Sie können alle Tabellen in einem Lakehouse (Datenbank) überprüfen, indem Sie Folgendes ausführen:
%%sql
SHOW TABLES IN <lakehouse_name>
Sie können die Details einer bestimmten Tabelle anzeigen, indem Sie Folgendes ausführen:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
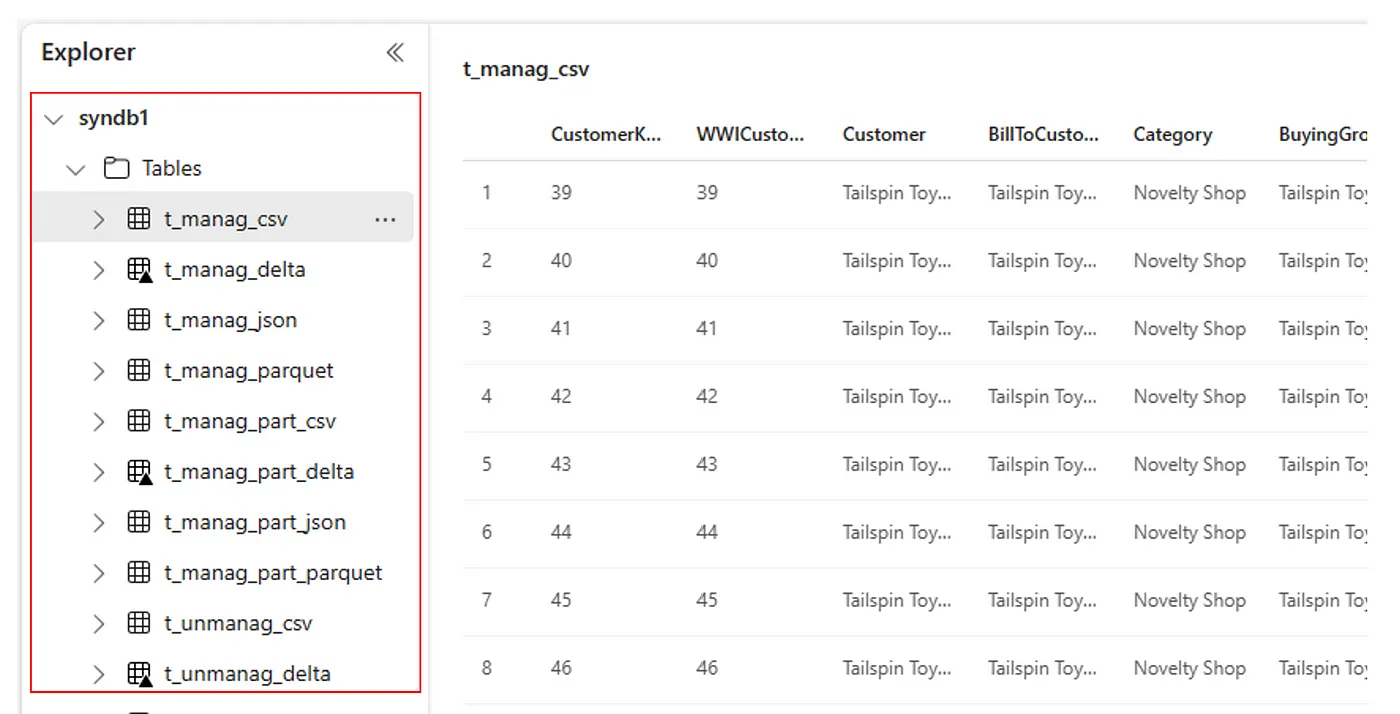
Alternativ sind alle importierten Tabellen im Abschnitt „Tabellen der Benutzeroberfläche“ des Lakehouse-Explorers für jedes Lakehouse sichtbar.
Andere Aspekte
- Skalierbarkeit: Die Lösung verwendet hier die interne Spark-Katalog-API zum Importieren/Exportieren, stellt jedoch keine direkte Verbindung zum HMS her, um Katalogobjekte abzurufen, sodass die Lösung nicht gut skaliert werden kann, wenn der Katalog groß ist. Sie müssen die Exportlogik mithilfe der HMS-Datenbank ändern.
- Datengenauigkeit: Es gibt keine Isolationsgarantie, was bedeutet, dass inkonsistente Daten in das Fabric-Lakehouse eingeführt werden können, wenn die Spark-Compute-Engine gleichzeitige Änderungen am Metastore durchführt, während das Notebook für die Migration ausgeführt wird.
Zugehöriger Inhalt
- Fabric verglichen mit Azure Synapse Spark
- Weitere Informationen zu Migrationsoptionen für Spark-Pools, Konfigurationen, Bibliotheken, Notebooks und die Spark-Auftragsdefinition