Migrieren von Spark-Pools von Azure Synapse Analytics zu Fabric
Während Spark-Pools von Azure Synapse bereitgestellt werden, bietet Fabric Startpools und benutzerdefinierte Pools an. Der Startpool kann eine gute Wahl sein, wenn Sie über einen einzelnen Pool ohne benutzerdefinierte Konfigurationen oder Bibliotheken in Azure Synapse verfügen und wenn die Größe des mittleren Knotens Ihren Anforderungen entspricht. Wenn Sie jedoch mehr Flexibilität mit Ihren Spark-Poolkonfigurationen wünschen, wird die Verwendung von benutzerdefinierten Pools empfohlen. Es folgen zwei Optionen:
- Option 1: Verschieben des Spark-Pools in den Standardpool eines Arbeitsbereichs
- Option 2: Verschieben des Spark-Pools in eine benutzerdefinierte Umgebung in Fabric.
Wenn Sie über mehrere Spark-Pools verfügen und diese in denselben Fabric-Arbeitsbereich verschieben möchten, wird die Verwendung von Option 2 empfohlen, also das Erstellen mehrerer benutzerdefinierter Umgebungen und Pools.
Informationen zu Überlegungen zu Spark-Pools finden Sie unter Unterschiede zwischen Azure Synapse Spark und Fabric.
Voraussetzungen
Erstellen Sie einen Fabric-Arbeitsbereich in Ihrem Mandanten, falls dies noch nicht erfolgt ist.
Option 1: Vom Spark-Pools in den Standardpool eines Arbeitsbereichs.
Sie können einen benutzerdefinierten Spark-Pool aus Ihrem Fabric-Arbeitsbereich erstellen und als Standardpool im Arbeitsbereich verwenden. Der Standardpool wird von allen Notebooks und Spark-Auftragsdefinitionen im selben Arbeitsbereich verwendet.
So wechseln Sie von einem vorhandenen Spark-Pool aus Azure Synapse zu einem Arbeitsbereichsstandardpool:
- Greifen Sie auf den Azure Synapse-Arbeitsbereich zu: Melden Sie sich bei Azure an. Navigieren Sie zu Ihrem Azure Synapse-Arbeitsbereich, wechseln Sie zu Analysepools, und wählen Sie Apache Spark-Pools aus.
- Suchen Sie den Spark-Pool: Suchen Sie aus Apache Spark-Pools den Spark-Pool, den Sie in Fabric verschieben möchten, und überprüfen Sie die Pooleigenschaften.
- Rufen Sie Eigenschaften ab: Rufen Sie die Eigenschaften des Spark-Pools wie die Apache Spark-Version, die Knotengrößenfamilie, die Knotengröße oder die Autoskalierung ab. In den Überlegungen zum Spark-Pool werden die Unterschiede erläutert.
- Erstellen Sie einen benutzerdefinierten Spark-Pool in Fabric:
- Wechseln Sie zu Ihrem Fabric-Arbeitsbereich, und wählen Sie die Arbeitsbereichseinstellungen aus.
- Wählen Sie zu Datentechnik/Data Science, und wählen Sie die Option Spark-Einstellungen aus.
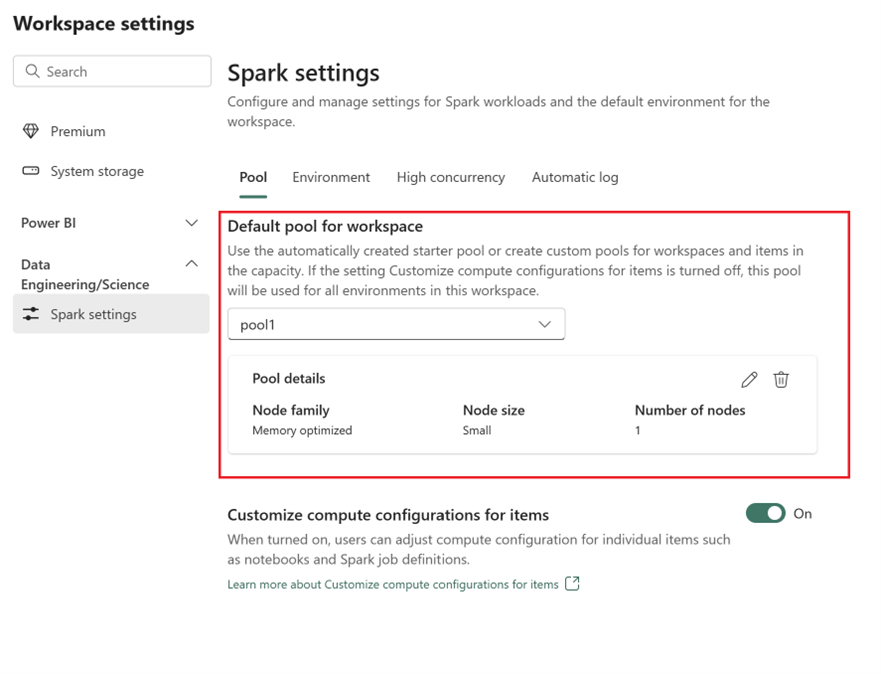
- Erweitern Sie auf der Registerkarte Pool und im Abschnitt Standardpool für Arbeitsbereich das Dropdownmenü, und wählen Sie Neuen Pool erstellen aus.
- Erstellen Sie Ihren benutzerdefinierten Pool mit den entsprechenden Zielwerten. Füllen Sie den Namen, die Knotenfamilie, die Knotengröße, die automatische Skalierung und die Optionen für die dynamische Executorzuordnung aus.
- Wählen Sie die Runtimeversion aus:
- Wechseln Sie zur Registerkarte Umgebung, und wählen Sie die erforderliche Runtimeversion aus. Die verfügbaren Runtimeversionen finden Sie hier.
- Deaktivieren Sie die Option Standardumgebung festlegen.
Hinweis
In dieser Option werden Bibliotheken oder Konfigurationen auf Poolebene nicht unterstützt. Sie können jedoch die Berechnungskonfiguration für einzelne Elemente wie Notebooks und Spark-Auftragsdefinitionen anpassen und Inlinebibliotheken hinzufügen. Wenn Sie einer Umgebung benutzerdefinierte Bibliotheken und Konfigurationen hinzufügen müssen, sollten Sie eine benutzerdefinierte Umgebung in Betracht ziehen.
Option 2: Von Spark-Pool zu benutzerdefinierter Umgebung.
Mit benutzerdefinierten Umgebungen können Sie benutzerdefinierte Spark-Eigenschaften und -Bibliotheken einrichten. So erstellen Sie eine benutzerdefinierte Umgebung:
- Greifen Sie auf den Azure Synapse-Arbeitsbereich zu: Melden Sie sich bei Azure an. Navigieren Sie zu Ihrem Azure Synapse-Arbeitsbereich, wechseln Sie zu Analysepools, und wählen Sie Apache Spark-Pools aus.
- Suchen Sie den Spark-Pool: Suchen Sie aus Apache Spark-Pools den Spark-Pool, den Sie in Fabric verschieben möchten, und überprüfen Sie die Pooleigenschaften.
- Rufen Sie Eigenschaften ab: Rufen Sie die Eigenschaften des Spark-Pools wie die Apache Spark-Version, die Knotengrößenfamilie, die Knotengröße oder die Autoskalierung ab. In den Überlegungen zum Spark-Pool werden die Unterschiede erläutert.
- Erstellen Sie einen benutzerdefinierten Spark-Pool:
- Wechseln Sie zu Ihrem Fabric-Arbeitsbereich, und wählen Sie die Arbeitsbereichseinstellungen aus.
- Wählen Sie zu Datentechnik/Data Science, und wählen Sie die Option Spark-Einstellungen aus.
- Erweitern Sie auf der Registerkarte Pool und im Abschnitt Standardpool für Arbeitsbereich das Dropdownmenü, und wählen Sie Neuen Pool erstellen aus.
- Erstellen Sie Ihren benutzerdefinierten Pool mit den entsprechenden Zielwerten. Füllen Sie den Namen, die Knotenfamilie, die Knotengröße, die automatische Skalierung und die Optionen für die dynamische Executorzuordnung aus.
- Erstellen Sie ein Umgebungselement, wenn Sie nicht über eins verfügen.
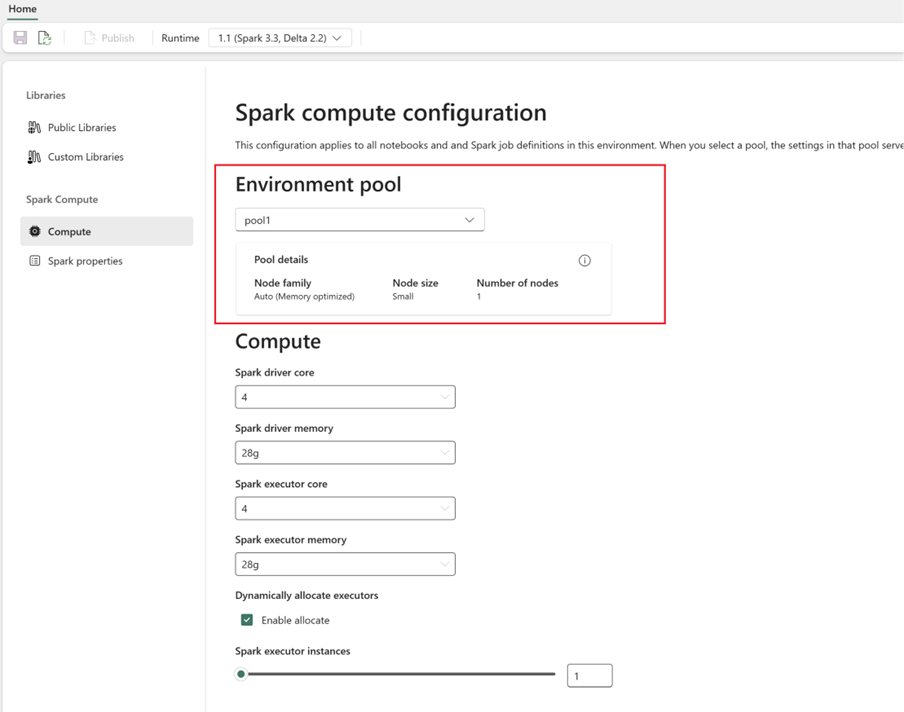
- Konfigurieren Sie Spark-Compute:
- Wechseln Sie in der Umgebung zu Spark-Compute>Compute.
- Wählen Sie den neu erstellten Pool für die neue Umgebung aus.
- Sie können Treiber- und Executorkerne und den Arbeitsspeicher konfigurieren.
- Wählen Sie eine Runtimeversion für die Umgebung aus. Die verfügbaren Runtimeversionen finden Sie hier.
- Klicken Sie auf Änderungen speichern und Veröffentlichen.
Weitere Informationen zum Erstellen und Verwenden einer Umgebung.