Prozess für Bereitstellungspipelines
Der Bereitstellungsprozess ermöglicht das Klonen von Inhalten von einer Phase in der Bereitstellungspipeline zu einer anderen – typischerweise von der Entwicklung zum Test und vom Test zur Produktion.
Während der Bereitstellung werden die Inhalte von Microsoft Fabric von der Quellphase in die Zielphase kopiert. Die Verbindungen zwischen den kopierten Elementen werden während des Kopiervorgangs beibehalten. Die konfigurierten Bereitstellungsregeln werden von Fabric auch in der Zielphase auf die aktualisierten Inhalte angewendet. Das Bereitstellen von Inhalten kann je nach Anzahl der bereitgestellten Elemente eine Weile dauern. Während dieser Zeit können Sie zu anderen Seiten im Portal navigieren, allerdings keine Inhalte in der Zielphase nutzen.
Sie können Inhalte auch programmgesteuert bereitstellen, indem Sie die REST-APIs für Bereitstellungspipelines verwenden. Weitere Informationen zu diesem Vorgang finden Sie unter Automatisieren Ihrer Bereitstellungspipeline mit APIs und DevOps.
Hinweis
Die neue Benutzeroberfläche „Bereitstellungspipeline“ befindet sich derzeit in der Vorschau. Informationen zum Aktivieren oder Verwenden der neuen Benutzeroberfläche finden Sie unter Beginnen mit der Verwendung der neuen BEnutzeroberfläche.
Es gibt zwei Hauptteile des Bereitstellungspipelineprozesses:
Definieren der Struktur der Bereitstellungspipeline
Wenn Sie eine Pipeline erstellen, definieren Sie, wie viele Phasen sie aufweisen soll und wie diese heißen sollen. Sie können auch eine oder mehrere Phasen öffentlich machen. Die Anzahl der Phasen und ihre jeweiligen Namen sind dauerhaft und können nach der Erstellung der Pipeline nicht mehr geändert werden. Sie können den öffentlichen Status einer Phase jedoch jederzeit ändern.
Um eine Pipeline zu definieren, befolgen Sie die Anweisungen in Erstellen einer Bereitstellungspipeline.
Hinzufügen von Inhalten zu den Phasen
Sie können einer Pipelinephase auf zwei Arten Inhalte hinzufügen:
- Zuweisen eines Arbeitsbereichs zu einer leeren Phase
- Bereitstellen von Inhalten aus einer Phase in einer anderen Phase
Zuweisen eines Arbeitsbereichs zu einer leeren Phase
Wenn Sie Inhalte einer leeren Phase zuweisen, wird ein neuer Arbeitsbereich mit einer Kapazität für die Phase erstellt, in der die Bereitstellung erfolgt. Alle Metadaten in den Berichten, Dashboards und semantischen Modellen des ursprünglichen Arbeitsbereichs werden in der Phase, in der Sie die Bereitstellung vornehmen, in den neuen Arbeitsbereich kopiert.
Aktualisieren Sie nach Abschluss der Bereitstellung die semantischen Modelle, damit Sie die neu kopierten Inhalte verwenden können. Die Aktualisierung des semantischen Modells ist erforderlich, da Daten nicht von einer Phase in eine andere kopiert werden. Informationen dazu, welche Objekteigenschaften während des Bereitstellungsvorgangs kopiert und welche Elementeigenschaften nicht kopiert werden, finden Sie im Abschnitt Nicht kopierte Elementeigenschaften.
Anweisungen zum Zuweisen und Aufheben der Zuweisung von Arbeitsbereichen zu Bereitstellungspipelinephasen finden Sie unter Zuweisen eines Arbeitsbereichs zu einer Microsoft Fabric-Bereitstellungspipeline.
Erstellen eines Arbeitsbereichs
Wenn Sie Inhalte zum ersten Mal bereitstellen, wird von den Bereitstellungspipelines überprüft, ob Sie über Berechtigungen verfügen.
Wenn Sie über geeignete Berechtigungen verfügen, werden die Inhalte des Arbeitsbereichs in die Phase kopiert, in der Sie eine Bereitstellung durchführen. Außerdem wird mit der Kapazität ein neuer Arbeitsbereich für diese Phase erstellt.
Wenn Sie keine Berechtigungen besitzen, wird der Arbeitsbereich erstellt, ohne dass die Inhalte kopiert werden. Sie können einen Administrator bitten, Ihren Arbeitsbereich einer Kapazität hinzuzufügen, oder bitten Sie um Zuweisungsberechtigungen für die Kapazität. Später, wenn der Arbeitsbereich einer Kapazität zugewiesen wird, können Sie die Inhalte in diesem Arbeitsbereich bereitstellen.
Wenn Sie eine Premium-Einzelbenutzerlizenz verwenden, wird Ihr Arbeitsbereich automatisch Ihrer Einzelbenutzerlizenz zugeordnet. In solchen Fällen sind keine Berechtigungen erforderlich. Wenn Sie jedoch einen Arbeitsbereich mit einer PPU erstellen, können nur andere PPU-Benutzer darauf zugreifen. Darüber hinaus können nur PPU-Benutzer Inhalte nutzen, die in solchen Arbeitsbereichen erstellt wurden.
Arbeitsbereichs- und Inhaltsbesitz
Der*die Benutzer*in, der bzw. die die Bereitstellung durchführt, wird automatisch zum*zur Besitzer*in der geklonten semantischen Modelle und zum*zur einzigen Administrator*in des neuen Arbeitsbereichs.
Bereitstellen von Inhalten aus einer Phase in einer anderen Phase
Es gibt mehrere Möglichkeiten zum Bereitstellen von Inhalten aus einer Phase in eine andere. Sie können die gesamten Inhalte bereitstellen, oder Sie wählen aus, welche Elemente bereitgestellt werden sollen.
Sie können Inhalte in jeder benachbarten Phase in beiden Richtungen bereitstellen.
Das Bereitstellen von Inhalten aus einer aktiven Produktionspipeline in einer Phase mit vorhandenem Arbeitsbereich umfasst folgende Schritte:
Bereitstellen neuer Inhalte als Ergänzung zu den bereits vorhandenen Inhalten.
Bereitstellen aktualisierter Inhalte, um einige der bereits vorhandenen Inhalte zu ersetzen.
Bereitstellungsprozess
Wenn Inhalte aus der Zielphase in die Zielphase kopiert werden, werden vorhandene Inhalte in der Zielphase von Fabric identifiziert und überschrieben. Um zu ermitteln, welche Inhaltselemente überschrieben werden müssen, verwenden Bereitstellungspipelines die Verbindung zwischen dem übergeordneten Element und seinen Klonen. Diese Verbindung wird aufrechterhalten, wenn neue Inhalte erstellt werden. Beim Überschreiben werden nur die Inhalte des Elements überschrieben. ID, URL und Berechtigungen des Elementes bleiben unverändert.
In der Zielphase bleiben nicht kopierte Elementeigenschaften unverändert (wie vor der Bereitstellung) erhalten. Neue Inhalte und neue Elemente werden von der Zielphase in die Zielphase kopiert.
Automatische Bindung
In Fabric sind die Elemente voneinander abhängig, wenn sie verbunden sind. Beispielsweise hängt ein Bericht immer von dem semantischen Modell ab, mit dem er verbunden ist. Ein semantisches Modell kann von einem anderen semantischen Modell abhängen und auch mit mehreren Berichten verbunden sein, die davon abhängig sind. Wenn eine Verbindung zwischen zwei Elementen besteht, versuchen Bereitstellungspipelines immer, diese Verbindung beizubehalten.
Automatisches Binden im selben Arbeitsbereich
Während der Bereitstellung überprüft die Bereitstellungspipeline auf Abhängigkeiten. Die Bereitstellung ist entweder erfolgreich oder fehlerhaft, abhängig vom Speicherort des Elements, das die Daten bereitstellt, von denen das bereitgestellte Element abhängt.
Das verknüpfte Element ist in der Zielphase vorhanden: Bereitstellungspipelines verbinden das bereitgestellte Element automatisch mit dem Element, von dem es in der Bereitstellungsphase abhängt (automatische Bindung). Wenn Sie beispielsweise einen paginierten Bericht aus der Entwicklungs- in die Testphase verschieben und bereitstellen und der Bericht mit einem semantischen Modell verbunden ist, das zuvor in der Testphase bereitgestellt wurde, wird er automatisch mit diesem semantischen Modell in der Testphase verbunden.
Das verknüpfte Element ist nicht in der Zielphase vorhanden: Bereitstellungspipelines können eine Bereitstellung nicht erfolgreich durchführen, wenn ein Element von einem anderen Element abhängt und das Element, das die Daten bereitstellt, nicht bereitgestellt wurde und sich nicht in der Zielphase befindet. Wenn Sie beispielsweise einen Bericht aus der Entwicklungs- in die Testphase verschieben und bereitstellen und die Testphase nicht das zugehörige semantische Modell enthält, schlägt die Bereitstellung fehl. Verwenden Sie die Schaltfläche Zugehörige auswählen, um fehlerhafte Bereitstellungen aufgrund von nicht bereitgestellten abhängigen Elementen zu vermeiden. Mit Zugehörige auswählen werden automatisch alle zugehörigen Elemente ausgewählt, die Abhängigkeiten von den Elementen aufweisen, die Sie bereitstellen möchten.
Die automatische Bindung funktioniert nur mit Elementen, die von Bereitstellungspipelines unterstützt werden und sich in Fabric befinden. Wählen Sie zum Anzeigen der Abhängigkeiten eines Elements im zugehörigen Menü Weitere Optionen die Option Herkunft anzeigen aus.
- Neue Benutzeroberfläche zum Anzeigen der Datenherkunft
- Ursprüngliche Benutzeroberfläche zum Anzeigen der Datenherkunft
Automatisches Binden über Arbeitsbereiche hinweg
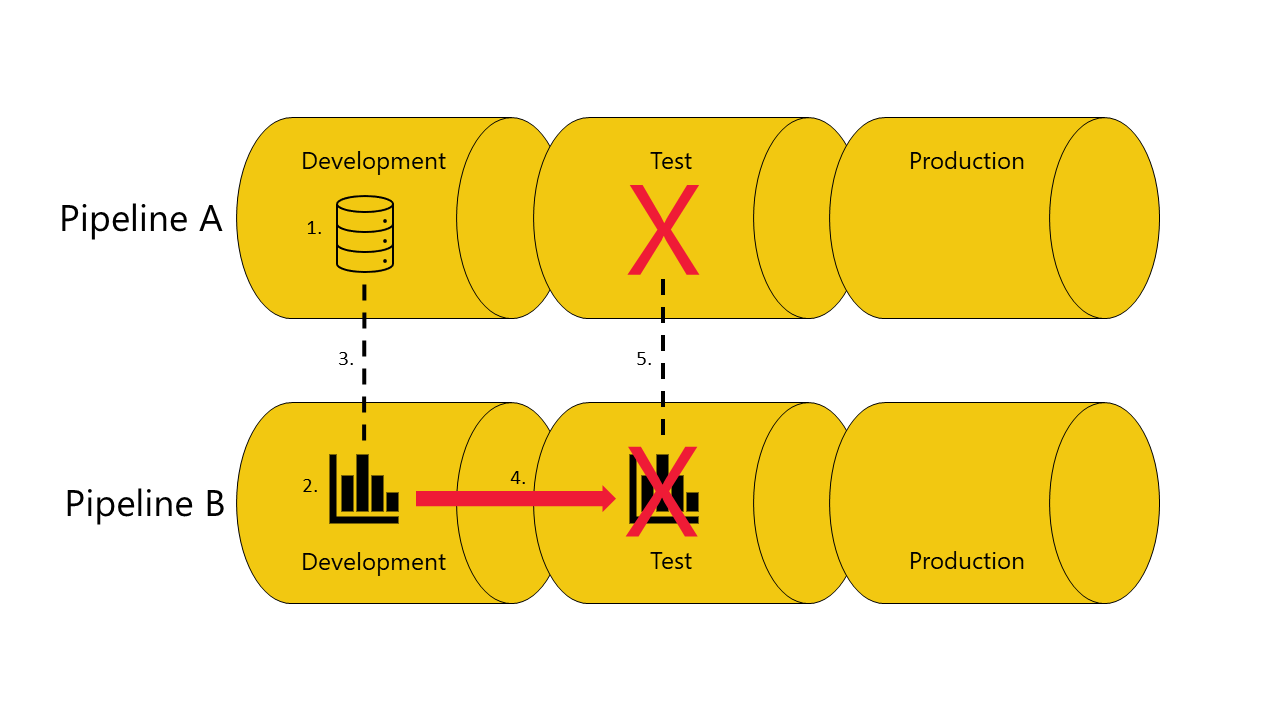
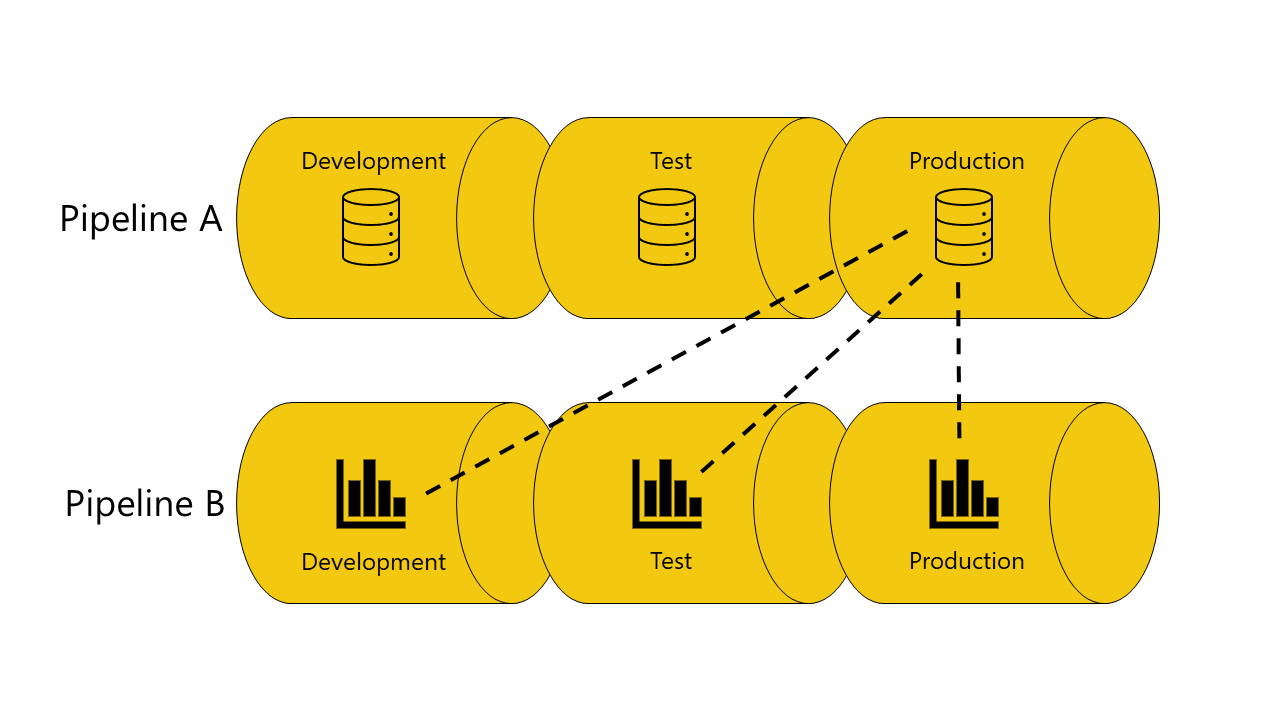
Bereitstellungspipelines binden automatisch Elemente, die pipelineübergreifend verbunden sind, wenn sie sich in derselben Pipelinephase befinden. Wenn Sie solche Elemente bereitstellen, versuchen Bereitstellungspipelines, eine neue Verbindung zwischen dem bereitgestellten Element und dem Element herzustellen, mit dem es in der anderen Pipeline verbunden ist. Haben Sie beispielsweise einen Bericht in der Testphase von Pipeline A, der mit einem semantischen Modell in der Testphase von Pipeline B verbunden ist, erkennen Bereitstellungspipelines diese Verbindung.
Die Abbildungen im folgenden Beispiel veranschaulichen, wie die automatische pipelineübergreifende Bindung funktioniert:
Sie verfügen über ein semantisches Modell in der Entwicklungsphase von Pipeline A.
Außerdem verfügen Sie über einen Bericht in der Entwicklungsphase von Pipeline B.
Ihr Bericht in Pipeline B ist mit Ihrem semantischen Modell in Pipeline A verbunden. Der Bericht hängt von diesem semantischen Modell ab.
Sie stellen den Bericht in Pipeline B von der Entwicklungsphase bis zur Testphase bereit.
Die Bereitstellung ist erfolgreich oder schlägt fehl, je nachdem, ob Sie über eine Kopie des semantischen Modells, von dem der Bericht abhängig ist, in der Testphase von Pipeline A verfügen:
Wenn Sie eine Kopie des semantischen Modells, von dem der Bericht abhängig ist, in der Testphase von Pipeline A haben:
Die Bereitstellung ist erfolgreich, und Bereitstellungspipelines verbinden den Bericht in der Testphase von Pipeline B mit dem semantischen Modell in der Testphase von Pipeline A (automatische Bindung).

Wenn Sie keine Kopie des semantischen Modells, von dem der Bericht abhängig ist, in der Testphase von Pipeline A haben:
Die Bereitstellung schlägt fehl, da Bereitstellungspipelines den Bericht in der Testphase von Pipeline B nicht automatisch an das semantische Modell, von dem der Bericht abhängig ist, in der Testphase von Pipeline A binden können.
Vermeiden der Nutzung der automatischen Bindung
In einigen Fällen sollten Sie die automatische Bindung nicht verwenden. Angenommen, Sie haben eine Pipeline für die Entwicklung von semantischen Organisationsmodellen und eine weitere für die Erstellung von Berichten. In diesem Fall sollen alle Berichte grundsätzlich mit den semantischen Modellen in der Produktionsphase der Pipeline verbunden werden, zu der sie gehören. Vermeiden Sie in diesem Fall die Automatische Bindungsfunktion.
Es gibt drei Methoden, mit denen Sie die automatische Bindung vermeiden können:
Verbinden Sie das Element nicht mit den entsprechenden Phasen. Wenn die Elemente nicht in derselben Phase verbunden sind, behalten Bereitstellungspipelines die ursprüngliche Verbindung bei. Wenn Sie beispielsweise einen Bericht in der Entwicklungsphase von Pipeline B haben, der mit einem semantischen Modell in der Produktionsphase von Pipeline A verbunden ist, bleibt der Bericht mit dem semantischen Modell in der Produktionsphase von Pipeline A verbunden, wenn Sie ihn in der Testphase von Pipeline B bereitstellen.
Definieren Sie eine Parameterregel. Diese Option ist für Berichte nicht verfügbar. Die Verwendung ist nur mit semantischen Modellen und Dataflows möglich.
Verbinden Sie Ihre Berichte, Dashboards und Kacheln mit einem semantischen Proxymodell oder Proxydataflow, das bzw. der nicht mit einer Pipeline verbunden ist.
Automatische Bindung und Parameter
Parameter können verwendet werden, um die Verbindungen zwischen semantischen Modellen oder Dataflows und den Elementen zu steuern, von denen sie abhängen. Wenn die Verbindung über einen Parameter gesteuert wird, erfolgt keine automatische Bindung nach der Bereitstellung, auch wenn die Verbindung einen Parameter enthält, der auf die ID des semantischen Modells oder Dataflows oder die Arbeitsbereichs-ID angewendet wird. In diesen Fällen müssen Sie die Elemente nach der Bereitstellung erneut binden, indem Sie den Parameterwert ändern oder Parameterregeln verwenden.
Hinweis
Wenn Sie Parameterregeln verwenden, um Elemente erneut zu binden, müssen die Parameter vom Typ Textsein.
Daten werden aktualisiert
Daten im Zielelement, z. B. ein semantisches Modell oder Dataflow, werden nach Möglichkeit beibehalten. Wenn keine Änderungen an einem Element vorliegen, das die Daten enthält, werden die Daten wie vor der Bereitstellung beibehalten.
Wenn Sie eine geringfügige Änderung vornehmen, z. B. eine Tabelle hinzufügen oder entfernen, werden die ursprünglichen Daten häufig in Fabric beibehalten. Für spontane Schemaänderungen oder Änderungen in der Datenquellenverbindung ist eine vollständige Aktualisierung erforderlich.
Anforderungen für die Bereitstellung in einer Phase mit vorhandenem Arbeitsbereich
Jeder lizenzierte Benutzer, der Mitwirkender sowohl des Ziel- als auch des Quellarbeitsbereichs für die Bereitstellung ist, kann Inhalte, die in einer Kapazität enthalten sind, in einer Phase mit einem vorhandenen Arbeitsbereich bereitstellen. Weitere Informationen finden Sie im Abschnitt Berechtigungen.
Ordner in Bereitstellungspipelines (Vorschau)
Ordner geben Benutzern die Möglichkeit, Arbeitsbereichselemente effizient und auf vertraute Weise zu organisieren und zu verwalten. Wenn Sie Inhalte bereitstellen, die Ordner in einer anderen Phase beinhalten, wird die Ordnerhierarchie der verwendeten Artikel automatisch angewendet.
Ordnerdarstellung
- Neue Ordnerdarstellung in der Benutzeroberfläche
- Ursprüngliche Ordnerdarstellung in der Benutzeroberfläche
Der Arbeitsbereichsinhalt wird so dargestellt, wie er im Arbeitsbereich strukturiert ist. Ordner werden aufgelistet, und um deren Elemente anzuzeigen, müssen Sie den Ordner auswählen. Der vollständige Pfad eines Elements wird oben in der Elementliste angezeigt. Da es sich bei einer Bereitstellung nur um Elemente handelt, können Sie nur einen Ordner auswählen, der unterstützte Elemente enthält. Das Auswählen eines Ordners für die Bereitstellung bedeutet, dass alle zugehörigen Elemente und Unterordner mit ihren Elementen für eine Bereitstellung ausgewählt werden.
Diese Abbildung zeigt den Inhalt eines Ordners innerhalb des Arbeitsbereichs. Der vollständige Pfadname des Ordners wird oben in der Liste angezeigt.
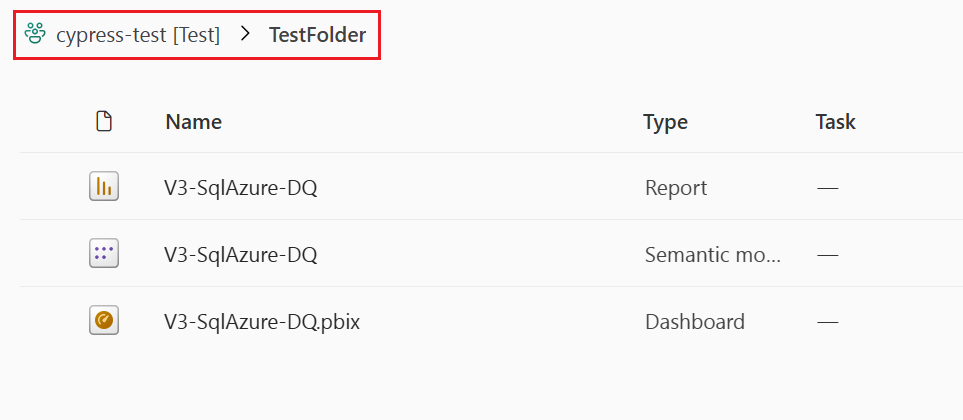
In Bereitstellungspipelines werden Ordner als Teil des Namens eines Artikels angesehen (ein Artikelname enthält seinen vollständigen Pfad). Wenn ein Element bereitgestellt wurde, nachdem sein Pfad geändert wurde (z. B. das Verschieben aus Ordner A in Ordner B), dann wendet die Bereitstellungspipeline diese Änderung auf das gekoppelte Element während der Bereitstellung an – das gekoppelte Element wird ebenfalls in den Ordner B verschoben. Wenn der Ordner B in der Phase, in die wir bereitstellen, nicht existiert, wird er zuerst in seinem Arbeitsbereich erstellt. Ordner können nur auf der Arbeitsbereichsseite angezeigt und verwaltet werden.
Stellen Sie Elemente innerhalb eines Ordners aus diesem Ordner bereit. Elemente aus unterschiedlichen Hierarchien können nicht gleichzeitig bereitgestellt werden.
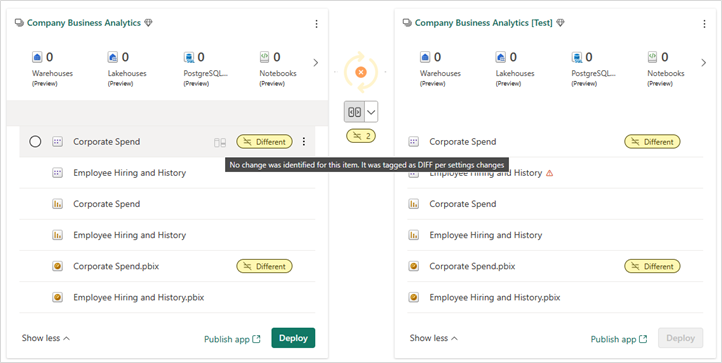
Identifizieren von Artikeln, die in verschiedene Ordner verschoben wurden
Da Ordner als Teil des Namens des Artikels betrachtet werden, werden Artikel, die in einen anderen Ordner im Arbeitsbereich verschoben werden, auf der Bereitstellungspipeline-Seite im Vergleich als Anders identifiziert. Dieses Element wird nicht im Vergleichsfenster angezeigt, da es sich nicht um eine Schemaänderung handelt, sondern sich die Einstellungen ändern.
- Verschobenes Ordnerelement in der neuen Benutzeroberfläche
- Verschobenes Ordnerelement in der ursprünglichen Benutzeroberfläche

Einzelne Ordner können in Bereitstellungspipelines nicht manuell bereitgestellt werden. Die Bereitstellung wird automatisch ausgelöst, wenn mindestens einer der Artikel bereitgestellt wird.
Die Ordnerhierarchie von gekoppelten Artikeln wird nur während der Bereitstellung aktualisiert. Während der Zuordnung nach dem Pairing-Vorgang wird die Hierarchie der gekoppelten Artikel noch nicht aktualisiert.
Da ein Ordner nur bereitgestellt wird, wenn einer seiner Artikel bereitgestellt wird, kann kein leerer Ordner bereitgestellt werden.
Die Bereitstellung eines von mehreren Elementen in einem Ordner führt dazu, dass auch die Struktur der Elemente, die nicht in der Zielphase bereitgestellt werden, aktualisiert wird, obwohl die Elemente selbst nicht bereitgestellt werden.
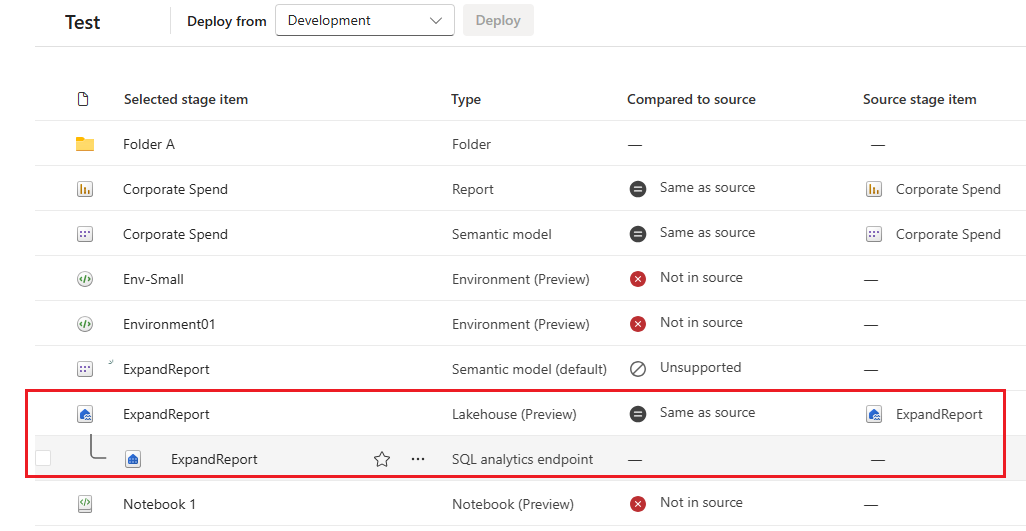
Darstellung von übergeordneten und untergeordneten Elementen
Diese werden nur in der neuen Benutzeroberfläche angezeigt. Sieht wie im Arbeitsbereich aus. Das untergeordnete Element wird nicht bereitgestellt, aber auf der Zielstufe neu erstellt
Während der Bereitstellung kopierte Elementeigenschaften
Eine Liste der unterstützten Elemente finden Sie unter Von der Bereitstellungspipeline unterstützte Elemente.
Während der Bereitstellung werden die folgenden Elementeigenschaften kopiert und überschreiben die Elementeigenschaften in der Zielphase:
Datenquellen (Bereitstellungsregeln werden unterstützt)
Parameter (Bereitstellungsregeln werden unterstützt)
Berichtsvisuals
Berichtsseiten
Dashboardkacheln
Modellmetadaten
Elementbeziehungen
Vertraulichkeitsbezeichnungen werden nur kopiert, wenn eine der folgenden Bedingungen erfüllt ist. Sind diese Bedingungen nicht erfüllt, werden bei der Bereitstellung keine Vertraulichkeitsbezeichnungen kopiert.
Ein neues Element wird bereitgestellt, oder ein vorhandenes Element wird in einer leeren Phase bereitgestellt.
Hinweis
In Fällen, in denen die Standardbeschriftung für den Mandanten aktiviert ist, die Standardbezeichnung gültig ist und es sich beim bereitgestellten Element um ein Semantikmodell oder einen Dataflow handelt, wird die Bezeichnung nur aus dem Quellelement kopiert, wenn für die Bezeichnung der Schutz aktiviert ist. Wenn die Bezeichnung nicht geschützt ist, wird die Standardbezeichnung auf das neu erstellte Zielsemantikmodell oder den Datenfluss angewendet.
Das Quellelement verfügt über eine geschützte Bezeichnung, das Zielelement hingegen nicht. In diesem Fall wird ein Popupfenster angezeigt, in dem Sie aufgefordert werden, der Außerkraftsetzung der Vertraulichkeitsbezeichnungen des Zielelements zuzustimmen.
Nicht kopierte Elementeigenschaften
Die folgenden Elementeigenschaften werden während der Bereitstellung nicht kopiert:
Daten: Daten werden nicht kopiert. Es werden nur Metadaten kopiert
URL
ID
Berechtigungen – für einen Arbeitsbereich oder ein bestimmtes Element
Arbeitsbereichseinstellungen – Jede Phase umfasst einen eigenen Arbeitsbereich
App-Inhalte und -Einstellungen – Informationen zum Aktualisieren Ihrer Apps finden Sie unter Aktualisieren von Inhalten in Power BI-Apps
Die folgenden Eigenschaften des semantischen Modells werden während der Bereitstellung ebenfalls nicht kopiert:
Rollenzuweisung
Aktualisierungszeitplan
Anmeldeinformationen für die Datenquelle
Einstellungen für die Zwischenspeicherung von Abfragen (kann von der Kapazität geerbt werden)
Endorsement-Einstellungen
Unterstützte Features für semantische Modelle
Bereitstellungspipelines unterstützen zahlreiche Features für semantische Modelle. In diesem Abschnitt sind zwei Features für semantische Modelle aufgeführt, die Ihre Bereitstellungspipelines verbessern können:
Inkrementelle Aktualisierung
Bereitstellungspipelines unterstützen die inkrementelle Aktualisierung, ein Feature, mit dem große semantische Modelle schneller, zuverlässiger und mit geringerem Verbrauch aktualisiert werden können.
In Bereitstellungspipelines können Sie Aktualisierungen für ein semantisches Modell mit der inkrementellen Aktualisierung vornehmen, bei denen sowohl Daten als auch Partitionen beibehalten werden. Wenn Sie das semantische Modell bereitstellen, wird die Richtlinie kopiert.
Informationen zum Verhalten der inkrementellen Aktualisierung mit Dataflows finden Sie unter Warum werden mir nach der Verwendung von Dataflowregeln zwei Datenquellen angezeigt, die mit meinem Dataflow verbunden sind?
Hinweis
Inkrementelle Aktualisierungseinstellungen werden in Gen 1 nicht kopiert.
Aktivieren der inkrementellen Aktualisierung in einer Pipeline
Konfigurieren Sie die inkrementelle Aktualisierung in Power BI Desktop, um sie zu aktivieren, und veröffentlichen Sie dann Ihr semantisches Modell. Nach der Veröffentlichung ist die Richtlinie für inkrementelle Aktualisierungen in der gesamten Pipeline ähnlich und kann nur noch in Power BI Desktop bearbeitet werden.
Nachdem die Pipeline mit inkrementeller Aktualisierung konfiguriert wurde, wird der folgende Flow empfohlen:
Änderungen an Ihrer PBIX-Datei nehmen Sie in Power BI Desktop vor. Um lange Wartezeiten zu vermeiden, können Sie Änderungen unter Verwendung einer Stichprobe der Daten vornehmen.
Laden Sie Ihre PBIX-Datei in die erste Phase (in der Regel Entwicklung) hoch.
Stellen Sie Ihre Inhalte in der nächsten Phase bereit. Nach der Bereitstellung gelten die von Ihnen vorgenommenen Änderungen für das gesamte semantische Modell, das Sie verwenden.
Überprüfen Sie die Änderungen, die Sie in jeder Phase vorgenommen haben, und stellen Sie nach der Überprüfung in der nächsten Phase bereit, bis Sie zur endgültigen Phase gelangen.
Anwendungsbeispiele
Im Folgenden finden Sie einige Beispiele für die Integration der inkrementellen Aktualisierung in Bereitstellungspipelines.
Erstellen Sie eine neue Pipeline, und verbinden Sie sie mit einem Arbeitsbereich mit einem semantischen Modell, für das die inkrementelle Aktualisierung aktiviert ist.
Aktivieren Sie die inkrementelle Aktualisierung in einem semantischen Modell, das sich bereits in einem Entwicklungsarbeitsbereich befindet.
Erstellen Sie eine Pipeline in einem Produktionsarbeitsbereich mit einem semantischen Modell, das die inkrementelle Aktualisierung verwendet. Weisen Sie z. B. den Arbeitsbereich der Produktionsstufe einer neuen Pipeline zu, und verwenden Sie die Rückwärtsbereitstellung, um sie in der Testphase bereitzustellen, und dann in der Entwicklungsstufe.
Veröffentlichen Sie ein semantisches Modell, das eine inkrementelle Aktualisierung für einen Arbeitsbereich verwendet, der zu einer vorhandenen Pipeline gehört.
Einschränkungen der inkrementellen Aktualisierung
Für die inkrementelle Aktualisierung unterstützen Bereitstellungspipelines nur semantische Modelle, die erweiterte Metadaten des semantischen Modells verwenden. Alle semantischen Modelle, die mit Power BI Desktop erstellt oder geändert wurden, implementieren automatisch erweiterte Metadaten des semantischen Modells.
Beim erneuten Veröffentlichen eines semantischen Modells in einer aktiven Pipeline mit aktivierter inkrementeller Aktualisierung führen die folgenden Änderungen aufgrund der potenziellen Datenverluste zu einem Bereitstellungsfehler:
Erneutes Veröffentlichen eines semantischen Modells, das die inkrementelle Aktualisierung nicht verwendet, um ein semantisches Modell zu ersetzen, für das die inkrementelle Aktualisierung aktiviert ist.
Umbenennen einer Tabelle mit aktivierter inkrementeller Aktualisierung.
Umbenennen nicht berechneter Spalten in einer Tabelle mit aktivierter inkrementeller Aktualisierung.
Andere Änderungen sind zulässig, z. B. das Hinzufügen einer Spalte, das Entfernen einer Spalte und das Umbenennen einer berechneten Spalte. Wenn die Änderungen jedoch Auswirkungen auf die Anzeige haben, müssen Sie eine Aktualisierung vornehmen, bevor die Änderung sichtbar wird.
Zusammengesetzte Modelle
Mithilfe von zusammengesetzten Modellen können Sie einen Bericht mit mehreren Datenverbindungen einrichten.
Sie können die Funktionalität für zusammengesetzte Modelle verwenden, um ein semantisches Fabric-Modell mit einem externen semantischen Modell wie Azure Analysis Services zu verbinden. Weitere Informationen finden Sie unter Using DirectQuery for Fabric semantic models and Azure Analysis Services (Verwenden von DirectQuery für semantische Fabric-Modelle und Azure Analysis Services).
In einer Bereitstellungspipeline können Sie mithilfe zusammengesetzter Modelle ein semantisches Modell mit einem anderen semantischen Fabric-Modell außerhalb der Pipeline verbinden.
Automatische Aggregationen
Automatische Aggregationen bauen auf benutzerdefinierten Aggregationen auf und verwenden maschinelles Lernen, um semantische DirectQuery-Modell für eine maximale Berichtsabfrageleistung kontinuierlich zu optimieren.
Jedes semantische Modell behält seine automatischen Aggregationen nach der Bereitstellung bei. Bereitstellungspipelines ändern die automatische Aggregation eines semantischen Modells nicht. Dies bedeutet, dass bei der Bereitstellung eines semantischen Modells mit einer automatischen Aggregation die automatische Aggregation in der Zielphase unverändert bleibt und nicht von der automatischen Aggregation überschrieben wird, die aus der Quellphase bereitgestellt wird.
Um automatische Aggregationen zu aktivieren, befolgen Sie die Anweisungen unter Konfigurieren der automatischen Aggregation.
Hybridtabellen
Hybridtabellen sind Tabellen mit inkrementeller Aktualisierung, die sowohl Importpartitionen als auch direkte Abfragepartitionen enthalten können. Während einer neuen Bereitstellung werden sowohl die Aktualisierungsrichtlinie als auch die Hybridtabellenpartitionen kopiert. Bei der Bereitstellung in einer Pipelinephase, die bereits über Hybridtabellenpartitionen verfügt, wird nur die Aktualisierungsrichtlinie kopiert. Aktualisieren Sie die Tabelle, um die Partitionen zu aktualisieren.
Aktualisieren von Inhalten in Power BI-Apps
Power BI-Apps sind die empfohlene Methode zum Verteilen von Inhalten an Fabric-Consumer im Free-Tarif. Sie können die Inhalte Ihrer Power BI-Apps mithilfe einer Bereitstellungspipeline aktualisieren, sodass Sie mehr Kontrolle und Flexibilität im Hinblick auf den Lebenszyklus Ihrer App erhalten.
Erstellen Sie für jede Phase der Bereitstellungspipeline eine App, sodass Sie jedes Update aus der Sicht des Endbenutzers testen können. Verwenden Sie die Schaltfläche zum Veröffentlichen oder Anzeigen in der Arbeitsbereichskarte, um die App in einer bestimmten Pipelinephase zu veröffentlichen oder anzuzeigen.
- Veröffentlichen einer App – neue Benutzeroberfläche
- Veröffentlichen einer App – ursprüngliche Benutzeroberfläche

In der Produktionsphase können Sie auch die App-Seite in Fabric aktualisieren, sodass alle Inhaltsupdates für die benutzenden Personen der App verfügbar werden.
- Aktualisieren der App – neue Benutzeroberfläche
- Aktualisieren der App – ursprüngliche Benutzeroberfläche

Wichtig
Der Bereitstellungsprozess umfasst nicht das Aktualisieren des App-Inhalts oder der App-Einstellungen. Wenn Sie Änderungen an Inhalten oder Einstellungen durchführen möchten, müssen Sie die App in der erforderlichen Pipelinephase manuell aktualisieren.
Berechtigungen
Berechtigungen sind für die Pipeline und für die Arbeitsbereiche erforderlich, die ihr zugewiesen sind. Pipeline- und Arbeitsbereichsberechtigungen werden separat erteilt und verwaltet.
Pipelines verfügen nur über die Berechtigung Administrator, die zum Freigeben, Bearbeiten und Löschen einer Pipeline erforderlich ist.
Arbeitsbereiche verfügen über unterschiedliche Berechtigungen, die auch als Rollen bezeichnet werden. Arbeitsbereichsrollen bestimmen die Zugriffsebene auf einen Arbeitsbereich in einer Pipeline.
Bereitstellungspipelines unterstützen keine Microsoft 365-Gruppen als Pipelineadministrator*innen.
Um die Bereitstellung von einer Phase in einer anderen in der Pipeline zu ermöglichen, müssen Sie Pipelineadministrator und entweder Mitwirkender, Mitglied oder Administrator der Arbeitsbereiche sein, die den beteiligten Phasen zugewiesen sind. So kann beispielsweise ein*e Pipelineadministrator*in, dem bzw. der keine Arbeitsbereichsrolle zugewiesen ist, die Pipeline anzeigen und für andere freigeben. Der Benutzer kann jedoch die Inhalte des Arbeitsbereichs weder in der Pipeline noch im Dienst anzeigen und kann keine Bereitstellungen durchführen.
Berechtigungstabelle
In diesem Abschnitt werden die Berechtigungen für Bereitstellungspipelines beschrieben. Die in diesem Abschnitt aufgeführten Berechtigungen werden in anderen Fabric-Features möglicherweise anders angewendet.
Die niedrigste Berechtigung für Bereitstellungspipelines ist Pipelineadministrator und ist für alle Bereitstellungspipelinevorgänge erforderlich.
| User | Pipelineberechtigungen und Sicherheitsrollen | Kommentare |
|---|---|---|
| Pipelineadministrator |
|
Der Pipelinezugriff gewährt keine Berechtigungen zum Anzeigen oder Ausführen von Aktionen für die Arbeitsbereichsinhalte. |
| Betrachter im Arbeitsbereich (und Pipelineadministrator) |
|
Arbeitsbereichsmitglieder, denen die Rolle „Anzeigender Benutzer“ ohne Berechtigungen zum Erstellen zugewiesen ist, können nicht auf das semantische Modell zugreifen oder Arbeitsbereichsinhalte bearbeiten. |
| Mitwirkender im Arbeitsbereich (und Pipelineadministrator) |
|
|
| Arbeitsbereichsmitglied (und Pipelineadministrator) |
|
Wenn die Einstellung Erneute Veröffentlichung blockieren und Paketaktualisierung deaktivieren im Abschnitt Sicherheit des Semantikmodells des Mandanten aktiviert ist, können semantische Modelle nur von den jeweiligen Besitzer*innen aktualisiert werden. |
| Arbeitsbereichsadministrator (und Pipelineadministrator) |
|
Erteilte Berechtigungen
Wenn Sie Power BI-Elemente bereitstellen, kann sich der Besitz des bereitgestellten Elements ändern. In der folgenden Tabelle wird erläutert, wer die einzelnen Elemente bereitstellen kann und wie sich die Bereitstellung auf den Besitz des Elements auswirkt.
| Fabric-Element | Erforderliche Berechtigung zum Bereitstellen eines vorhandenen Elements | Elementbesitz nach einer erstmaligen Bereitstellung | Elementbesitz nach der Bereitstellung in einer Phase mit dem Element |
|---|---|---|---|
| Semantikmodell | Arbeitsbereichsmitglied | Der Benutzer, der die Bereitstellung vorgenommen hat, wird Besitzer. | Unverändert |
| Datenfluss | Dataflowbesitzer | Der Benutzer, der die Bereitstellung vorgenommen hat, wird Besitzer. | Unverändert |
| Datamart | Datamartbesitzer | Der Benutzer, der die Bereitstellung vorgenommen hat, wird Besitzer. | Unverändert |
| Paginierter Bericht | Arbeitsbereichsmitglied | Der Benutzer, der die Bereitstellung vorgenommen hat, wird Besitzer. | Der Benutzer, der die Bereitstellung vorgenommen hat, wird Besitzer. |
Erforderliche Berechtigungen für beliebte Aktionen
In der folgenden Tabelle sind die erforderlichen Berechtigungen für beliebte Bereitstellungspipelineaktionen aufgeführt. Sofern nicht anders angegeben, benötigen Sie für jede Aktion alle aufgeführten Berechtigungen.
| Aktion | Erforderliche Berechtigungen |
|---|---|
| Anzeigen der Liste der Pipelines in Ihrer Organisation | Keine Lizenz erforderlich (kostenloser Benutzer) |
| Erstellen einer Pipeline | Ein Benutzer mit einer der folgenden Lizenzen:
|
| Löschen einer Pipeline | Pipelineadministrator |
| Hinzufügen oder Entfernen eines Pipelinebenutzers | Pipelineadministrator |
| Zuweisen eines Arbeitsbereichs zu einer Phase |
|
| Aufheben der Zuweisung eines Arbeitsbereichs zu einer Phase | Eine der folgenden Rollen:
|
| Bereitstellen in einer leeren Phase (siehe Hinweis) |
|
| Bereitstellen von Elementen in der nächsten Phase (siehe Hinweis) |
|
| Anzeigen oder Festlegen einer Regel |
|
| Verwalten von Pipelineeinstellungen | Pipelineadministrator |
| Anzeigen einer Pipelinephase |
|
| Anzeigen der Liste der Elemente in einer Phase | Pipelineadministrator |
| Vergleichen von zwei Phasen |
|
| Anzeigen des Bereitstellungsverlaufs | Pipelineadministrator |
Hinweis
Um Inhalte in der GCC-Umgebung bereitzustellen, müssen Sie mindestens Mitglied des Quell- und Zielarbeitsbereichs sein. Die Bereitstellung als mitwirkende Person wird noch nicht unterstützt.
Überlegungen und Einschränkungen
In diesem Abschnitt werden die wichtigsten Einschränkungen in Bereitstellungspipelines aufgeführt.
- Der Arbeitsbereich muss über Fabric-Kapazität verfügen.
- Wenn Sie einen Arbeitsbereich in einem vorhandenen Zielarbeitsbereich in einer anderen Region bereitstellen, wird möglicherweise keine Warnung im Dialogfeld „Bereitstellen“ ausgegeben.
- Die maximale Anzahl von Elementen in einer einzelnen Bereitstellung liegt bei 300.
- Das Herunterladen einer PBIX-Datei nach der Bereitstellung wird nicht unterstützt.
- Microsoft 365-Gruppen werden nicht als Pipelineadministratoren unterstützt.
- Wenn Sie ein Power BI-Element zum ersten Mal bereitstellen, schlägt die Bereitstellung fehl, wenn ein anderes Element in der Zielphase vom Typ und Namen her gleich ist (z. B. wenn beide Dateien Berichte sind).
- Eine Liste der Einschränkungen für Arbeitsbereiche finden Sie unter Einschränkungen für die Arbeitsbereichszuweisung.
- Eine Liste der unterstützten Elemente finden Sie unter Unterstützte Elemente. Alle Elemente, die nicht in der Liste enthalten sind, werden nicht unterstützt.
- Die Bereitstellung schlägt fehl, wenn eines der Elemente Zirkel- oder Selbstabhängigkeiten aufweist (z. B. Element A verweist element B und Element B auf Element B).
- PBIR-Berichte werden nicht unterstützt.
Einschränkung des Semantikmodells
Datasets, die Echtzeitdatenkonnektivität verwenden, können nicht bereitgestellt werden.
Ein semantisches Modell mit dem DirectQuery- oder Composite-Konnektivitätsmodus, das Variationen oder Tabellen für autom. Datum/Uhrzeit verwendet, wird nicht unterstützt. Weitere Informationen finden Sie unter Was kann ich tun, wenn ich über ein Dataset im DirectQuery- oder Composite-Verbindungsmodus verfüge, das Variationen oder Kalendertabellen verwendet?.
Wenn während der Bereitstellung das semantische Zieldmodell eine Liveverbindung verwendet, muss auch das semantische Quellmodell diesen Verbindungsmodus verwenden.
Nach der Bereitstellung wird das Herunterladen eines semantischen Modells (ab der Phase, in der es bereitgestellt wurde) nicht mehr unterstützt.
Unter Einschränkungen von Bereitstellungsregeln finden Sie eine Liste der Einschränkungen von Bereitstellungsregeln.
Wenn die automatische Bindung aktiviert ist, gehen Sie wie folgt vor:
- Systemeigene Abfrage und DirectQuery werden nicht unterstützt. Dazu gehören Proxy-Datasets.
- Die Datenquellenverbindung muss der erste Schritt im Mashup-Ausdruck sein.
Beim Bereitstellen eines Direct Lake-Semantikmodells wird es nicht automatisch an Elemente in der Zielphase gebunden. Wenn beispielsweise ein LakeHouse eine Quelle für ein DirectLake-Semantikmodell ist und beide in der nächsten Phase bereitgestellt werden, wird das DirectLake-Semantikmodell in der Zielphase immer noch an das LakeHouse in der Quellphase gebunden. Verwenden Sie Datenquellregeln, um es an einen Artikel in der Zielphase zu binden. Andere Typen von semantischen Modellen werden automatisch an das gekoppelte Element in der Zielphase gebunden.
Einschränkungen von Dataflows
Inkrementelle Aktualisierungseinstellungen werden in Gen 1 nicht kopiert.
Wird ein Dataflow in einer leeren Phase bereitgestellt, erstellen die Bereitstellungspipelines einen neuen Arbeitsbereich und legen den Dataflowspeicher auf einen Fabric-Blobspeicher fest. Blobspeicher wird auch dann verwendet, wenn der Quellarbeitsbereich für die Verwendung von Azure Data Lake Storage Gen2 (ADLS Gen2) konfiguriert ist.
Dienstprinzipale werden für Dataflows nicht unterstützt.
Die CDM-Bereitstellung (Common Data Model) wird nicht unterstützt.
Informationen zu den Einschränkungen von Bereitstellungspipelineregeln, die sich auf Dataflows auswirken, finden Sie unter Einschränkungen von Bereitstellungsregeln.
Wenn während der Bereitstellung ein Datenfluss aktualisiert wird, schlägt die Bereitstellung fehl.
Wenn Sie Phasen während einer Dataflow-Aktualisierung vergleichen, sind die Ergebnisse unvorhersehbar.
Datenmart-Einschränkungen
Sie können kein Datenmart mit Vertraulichkeitsbezeichnungen bereitstellen.
Zum Bereitstellen eines Datamarts müssen Sie der Datamart-Besitzer sein.