Empfehlungen zur dienstbasierten automatischen Bezeichnung für die Einhaltung von PSPF durch die australische Regierung
Dieser Artikel enthält Anleitungen für australische Regierungsorganisationen zu Konfigurationen, mit denen Sicherheitsinformationen durch die Verwendung von dienstbasierten Richtlinien für die automatische Vertraulichkeitsbezeichnung geschützt werden können. Ihr Zweck ist es, Regierungsorganisationen bei der Verbesserung ihres Informationssicherheitsstatus zu unterstützen, insbesondere für Szenarien, in denen Informationen zwischen Regierungsorganisationen weitergegeben werden. Die Empfehlungen in diesem Artikel wurden so geschrieben, dass sie den Anforderungen des Schutzsicherheitsrichtlinien-Frameworks (PSPF) (insbesondere PSPF-Richtlinie 8 Anhang F: Australische Regierung Email Schutzkennzeichnung Standard) und dem Handbuch zur Informationssicherheit (ISM) am besten entsprechen.
Der vorherige Artikel, Übersicht über automatische Bezeichnungen, enthält zusätzliche allgemeine Informationen dazu, wo die Verwendung der automatischen Bezeichnung in einer modernen Regierungsarbeitsumgebung geeignet ist und wie sie zur Verringerung von Datensicherheitsrisiken beiträgt.
Die dienstbasierte automatische Bezeichnungsfunktion ermöglicht Folgendes:
-
Überprüfen von E-Mails auf vertrauliche Inhalte und Anwenden von Bezeichnungen während des Transports: Organisationen der australischen Regierung können diese Funktion verwenden, um:
- Gekennzeichnete E-Mails, die von anderen PSPF-Organisationen (Protective Security Policy Framework) oder entsprechenden aktivierten Organisationen empfangen wurden.
- Bezeichnen von E-Mails, die von Nicht-PSPF-fähigen Organisationen über die Erkennung vertraulicher Informationen oder anderer Bezeichner empfangen wurden.
-
Überprüfen vorhandener Elemente an SharePoint-Speicherorten (SharePoint/OneDrive/Teams) auf Schutzmarkierungen oder vertrauliche Inhalte und Anwenden von Bezeichnungen auf diese: Australische Behörden können diese Funktion verwenden, um:
- Kennzeichnen vorhandener Microsoft 365-Daten im Ruhezustand.
- Migrieren von Legacyklassifizierungstools oder Taxonomien
Bezeichnung von E-Mails während des Transports
Dieser Artikel ist eine Erweiterung der Konzepte, die unter E-Mail-Kennzeichnungsstrategien behandelt werden, in denen Methoden zum Anwenden von Markierungen auf E-Mails erläutert werden.
Dienstbasierte automatische Bezeichnungsrichtlinien, die für den Exchange-Dienst konfiguriert sind, überprüfen auf Markierungen in E-Mails und wenden entsprechende Bezeichnungen an. Eingehende E-Mails können Markierungen oder Vertraulichkeitsbezeichnungen aufweisen, die bereits von Absenderorganisationen angewendet wurden, aber diese gelten standardmäßig nicht auf Bezeichnungen basierenden Schutz ihrer Organisationen. Die Konvertierung externer Kennzeichnungen oder Bezeichnungen in interne Bezeichnungen stellt sicher, dass dlp (Data Loss Prevention) und andere relevante Steuerelemente angewendet werden.
Im Kontext der australischen Regierung würde die Identifizierung von Merkmalen von E-Mails in der Regel folgendes umfassen:
- X-Protective-Marking x-Header
- Betreffmarkierungen
- Textbasierte Kopf- und Fußzeilen
Email-basierte Richtlinienkonfiguration
Dienstbasierte Richtlinien für automatische Bezeichnungen werden im Microsoft Purview-Portal unter Information Protection> Richtlinien fürautomatische Bezeichnungen> konfiguriert.
Richtlinien für automatische Bezeichnungen ähneln den zu erstellenden DLP-Richtlinien . Im Gegensatz zu den DLP-Empfehlungen ist jedoch für jede Bezeichnung, die wir für die E-Mail-basierte Konfiguration anwenden möchten, eine einzelne Richtlinie für automatische Bezeichnungen erforderlich.
Richtlinien für die automatische Bezeichnung, die auf PSPF-Markierungen überprüfen, werden aus der benutzerdefinierten Richtlinienvorlage erstellt und basierend auf der Aktion benannt. Beispiel: Bezeichnung eingehender INOFFIZIELLEr Email. Richtlinien sollten auch nur auf den Exchange-Dienst angewendet werden, um sicherzustellen, dass die erforderlichen Optionen wie betreff für die Schnittstelle verfügbar sind.
Um eine hohe PSPF-Reife zu erreichen, sollten Richtlinien für die automatische Bezeichnung implementiert werden, um Folgendes auszuführen:
- Automatische Bezeichnung basierend auf X-Headern, die auf eingehende E-Mails angewendet werden.
- Automatische Bezeichnung basierend auf Betreffmarkierungen, die auf eingehende E-Mails angewendet werden.
- Automatische Bezeichnung basierend auf sensiblen Informationstypen (SITs), die im Textkörper eingehender E-Mails vorhanden sind (optional).
Für jede Bezeichnung ist eine Richtlinie für die automatische Bezeichnung erforderlich, die möglicherweise mehrere Regeln enthält (eine für jedes der oben genannten Szenarien). Einstellungen zum automatischen Ersetzen vorhandener Bezeichnungen sind nicht erforderlich.
Regeln, die auf X-Header überprüfen
Regeln, die zum Überprüfen von X-Protective-Marking-X-Headern für E-Mails erstellt wurden, sollten entsprechend benannt werden, z. B. "Check for OFFICIAL x-header".
Sie benötigen eine Bedingung von Headerüberstimmungsmustern mit dem Headernamen "x-protective-marking" und einem Regulären Ausdruckswert (RegEx), der mit dem x-protective-marking-Header in eingehenden E-Mails übereinstimmen kann. Die Syntax zum Identifizieren von Elementen, die als "OFFICIAL: Sensitive Personal Privacy" gekennzeichnet sind, lautet beispielsweise:
X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Personal-Privacy
In diesem Ausdruck [-: ] entspricht entweder einem Bindestrich, Doppelpunkt oder Leerzeichen, was eine gewisse Flexibilität bei der Anwendung der Header ermöglicht. Beachten Sie, dass der PSPF einen Doppelpunkt angibt.
Mit dem Muster von (?:,)? können Elemente unabhängig davon abgeglichen werden, ob ein Komma zwischen Sicherheitsklassifizierung und IMM enthalten ist.
Regeln zur Überprüfung von Betreffmarkierungen
Richtlinien für automatische Bezeichnungen sollten eine zweite Regel enthalten, die auf antragstellerbasierte Markierungen überprüft. Diese Regeln sollten entsprechend benannt werden, z. B. "Check OFFICIAL subject".
Die Regeln benötigen eine Bedingung, dass muster mit dem Wert eines geeigneten regulären Ausdrucks übereinstimmen . Zum Beispiel:
\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Personal-Privacy
Im vorherigen Beispiel ist das \ Escapezeichen erforderlich, um sicherzustellen, dass die Klammern als Teil des E-Mail-Betreffs und nicht als Teil des regulären Ausdrucks behandelt werden.
Diese Syntax enthält keine schließende Klammer (\]). Dies wird in Ansätzen für mehrere Information Management Marker (IMMs) erläutert.
Regeln für die Überprüfung auf SITs
Bei der Identifizierung vertraulicher Informationen empfehlen wir eine Reihe von SITs, um Schutzmarkierungen zu identifizieren. Diese SITs können auch in Richtlinien für automatische Bezeichnungen verwendet werden, die auf E-Mails angewendet werden. SITs bieten eine dritte Methode zum Identifizieren eingehender E-Mail-Klassifizierungen und helfen auch bei der Behebung von X-Header-Stripping.
Die Logikregeln erfordern eine Bedingung der Inhaltsinhalte, des Typs vertraulicher Informationen und lassen dann die SIT-relevant für die Klassifizierung auswählen.
Tipp
SIT-basierte Regeln können mehr falsch positive Ergebnisse generieren als x-header- oder themenbasierte Ansätze. Regierungsorganisationen, die noch nicht mit diesem Thema vertraut sind, ziehen möglicherweise in Betracht, nur mit X-Header- und themenbasierten Regeln zu arbeiten und dann sit-basierte Regeln hinzuzufügen, wenn es ihnen vertraut ist.
Beispiele für falsch positive Ergebnisse sind Diskussionen über Klassifizierungen und vom Dienst generierte Warnungen, die auf Elementinhalte verweisen oder diese enthalten, z. B. DLP-Warnungen. Aus diesem Grund sollten SIT-basierte Regeln für die automatische Bezeichnung zusätzliche Tests oder einen längeren Überwachungszeitraum vor der vollständigen Implementierung erhalten, um falsch positive Ergebnisse auszusprechen und Ausnahmen anzuwenden. Beispielausnahmen wären die Domäne "microsoft.com", von der dienstbasierte Warnungen gesendet werden.
Die Einbeziehung von SIT-basierten Regeln hat erhebliche Vorteile. Erwägen Sie die Begründung der Bezeichnungsänderung und das Risiko, dass Benutzer die Bezeichnung auf eine E-Mail-Unterhaltung böswillig verringern. Wenn eine PROTECTED-E-Mail auf INOFFIZELL reduziert wird, wir aber "[SEC=PROTECTED]" im Text der E-Mail-Unterhaltung erkennen können, können wir die Bezeichnung PROTECTED automatisch erneut anwenden. Dadurch wird es wieder in den Bereich der PROTECTED DLP-Richtlinien und anderer Steuerelemente des Mandanten aufgenommen. Es gibt Situationen, in denen Elemente absichtlich in einen niedrigeren Zustand umgegliedert werden, z. B. eine Veröffentlichung eines Medienbriefs für Budgetschätzungen, der bis zu einem bestimmten Zeitpunkt als Embargo verhängt wurde, sodass die SIT-Konfiguration diese Anwendungsfälle in der Regierungsorganisation berücksichtigen muss.
SIT-basierte Regeln können auch dazu beitragen, kleinere Regierungsorganisationen zu unterstützen, die E-Mails generieren, aber eine geringere Konformitätsreife haben. In solchen Organisationen könnten erweiterte Kennzeichnungsmethoden wie x-Header fehlen.
Ansätze für mehrere IMMs
Information Management Marker (IMMs) stammen aus dem Australian Government Recordkeeping Metadata Standard (AGRkMS) und sind eine optionale Möglichkeit, Informationen zu identifizieren, die nicht sicherheitsrelevanten Einschränkungen unterliegen. Wie bei der Verwendung mehrerer IMMs eingeführt, definiert AGRkMS einen IMM- oder "Rights Type"-Wert, der als einzelne Eigenschaft aufgezeichnet wird. Einige organisationen der australischen Regierung haben ihre Verwendung von IMMs durch Klassifizierungstaxonomien erweitert, die die Anwendung mehrerer IMMs ermöglichen (z. B. "PROTECTED Personal Privacy Legislative Secrecy").
Die Verwendung mehrerer IMMs kann DLP- und Automatische Bezeichnungskonfigurationen erschweren, da reguläre Ausdrücke, die die auf eingehende Elemente angewendeten Markierungen überprüfen, komplexer sein müssen. Es besteht auch das Risiko, dass E-Mails, die mit mehreren IMMs gekennzeichnet sind, wenn sie an externe Organisationen gesendet werden, durch den Empfang von E-Mail-Gateways falsch interpretiert werden können. Dies erhöht das Risiko von Informationsverlusten. Aus diesen Gründen wurden in den Beispielen, die in taxonomie- und E-Mail-Kennzeichnungsstrategien für Vertraulichkeitsbezeichnungen enthalten sind, nur einzelne IMMs gemäß den AGRkMS-Regeln angewendet.
Organisationen, die nur einzelne IMMs verwenden
Damit Organisationen nur einzelne IMMs verwenden, um von externen Organisationen empfangene E-Mails mit mehreren angewendeten IMMs zu unterstützen, wurden schließende eckige Klammern ("")\] in den regeln für die betreffbasierte automatische Bezeichnung nicht berücksichtigt. Dies ermöglicht es uns, E-Mails basierend auf dem ersten IMM zu bezeichnen, der auf seinen Betreff angewendet wurde. Dieser Ansatz stellt sicher, dass Elemente über bezeichnungsbasierte Steuerelemente geschützt werden, unabhängig davon, ob Ihre Bezeichnungstaxonomie vollständig mit anderen Regierungsorganisationen übereinstimmt, die Ihnen möglicherweise E-Mails senden.
In Bezug auf X-Header-basierte Ansätze ist es wahrscheinlich, dass diejenigen, die mehrere IMMs auf X-Protective-Marking-X-Header anwenden, dies über den folgenden Ansatz tun:
X-Protective-Marking : SEC=<Security Classification>, ACCESS=<First IMM>, ACCESS=<Second IMM>
Wenn in der Syntax "X-Protective-Marking" keine schließenden Klammern enthalten sind, wird das Element basierend auf dem ersten INM bezeichnet, der in der Markierung vorhanden ist. Das Element würde dann über die ersten IMMs-Steuerelemente geschützt, und visuelle Markierungen für den zweiten IMM würden weiterhin auf dem Element vorhanden sein.
Organisationen, die mehrere IMMs anwenden
Diejenigen, die ihre Bezeichnungstaxonomie und andere Konfigurationen erweitern möchten, um mehrere IMMs außerhalb von AGRkMS-Regeln zu unterstützen, müssen sicherstellen, dass ihre Regeln für die automatische Bezeichnung alle möglichen Konflikte berücksichtigen. Beispielsweise muss eine Regel, die auf "SEC=OFFICIAL:Sensitive, ACCESS=Legislative-Secrecy" überprüft wird, alle Werte ausschließen, auf die ein zweiter IMM angewendet wurde, da Elemente andernfalls nur mit dem einzelnen IMM fälschlicherweise bezeichnet werden könnten.
Ausschlüsse können angewendet werden, indem Entweder Ausnahmen zu Regeln für die automatische Bezeichnung hinzugefügt werden. Zum Beispiel:
Es sei denn, der Header stimmt mit Mustern überein:
X-Protective-Marking : SEC=OFFICIAL:Sensitive, ACCESS=Legislative-Secrecy, ACCESS=Personal-Privacy
X-Protective-Marking : SEC=OFFICIAL:Sensitive, ACCESS=Legislative-Secrecy, ACCESS=Legislative-Secrecy
X-Protective-Marking : SEC=OFFICIAL:Sensitive, ACCESS=Legislative-Secrecy, ACCESS=Legal-Privilege
Alternativ können Ausnahmen im RegEx der Regel berücksichtigt werden:
Header stimmt mit Mustern überein:
X-Protective-Marking :SEC=OFFICIAL[-: ]Sensitive, ACCESS=Legislative-Secrecy(?!, ACCESS=)
Bei SIT-basierten Regeln ist die syntax, die in der SIT-Beispielsyntax zum Erkennen von Schutzmarkierungen enthalten ist, nur für einzelne IMMs geeignet. Diese SITs müssten geändert werden, um falsch positive Ergebnisse zu vermeiden, und andere SITs müssten hinzugefügt werden, um den zusätzlichen Bezeichnungen zu entsprechen.
Automatische Bezeichnung von Informationen von ausländischen Regierungen
Viele organisationen der australischen Regierung befassen sich mit markierten oder klassifizierten Informationen von ausländischen Regierungen. Einige dieser Fremdklassifizierungen haben Äquivalenz innerhalb der PSPF-Klassifizierungstaxonomie, die in PSPF-Richtlinie 7: Sicherheitsgovernance für die internationale Freigabe definiert ist. Organisationen, die mit ausländischen Regierungen kommunizieren, können die in diesem Leitfaden beschriebenen Ansätze verwenden, um ausländische Kennzeichnungen in ihre PSPF-Entsprechung zu übersetzen.
Umgang mit Kennzeichnungen des Gesetzlichen Geheimhaltungsgeheimnisses
Das Gesetzesgeheimnis sollte nicht auf Elemente angewendet werden, die keinen Hinweis auf die spezifischen Gesetzlichen Geheimhaltungsanforderungen haben, die für die Informationen gelten:
| Anforderung | Detail |
|---|---|
| PSPF-Richtlinie 8 C.4 – Informationsverwaltungsmarkierungen | Das Gesetzesgeheimnis IMM wird verwendet, um auf die Anwendbarkeit einer oder mehrerer spezifischer Geheimhaltungsbestimmungen aufmerksam zu machen. Die Hauptabteilung des Innern empfiehlt, dass der Empfänger über die spezifische Bestimmung informiert wird, indem er oben oder unten auf jeder Seite eines Dokuments oder im Textkörper einer E-Mail, die die spezifischen Geheimhaltungsbestimmungen, unter denen die Informationen fallen, ausdrücklich identifiziert wird. |
Microsoft empfiehlt die Verwendung von Vertraulichkeitsbezeichnungen über eine Bezeichnung, die direkt an die betreffende Gesetzgebung ausgerichtet ist. Betrachten Sie beispielsweise eine Bezeichnungsstruktur von:
OFFICIAL Vertraulich
- OFFICIAL Vertraulich
- OFFICIAL Sensibles Gesetzesgeheimnis
- OFFICIAL Sensitive Legislative Secrecy Example Act
Mit einer solchen Bezeichnungsstruktur würden Benutzer, die mit Informationen im Zusammenhang mit dem "Beispielgesetz" arbeiten, die Bezeichnung "OFFICIAL Sensitive Legislative Secrecy Example Act" auf relevante Informationen anwenden. Die visuellen Markierungen dieser Bezeichnung sollten auch den betreffenden Akt angeben. Beispielsweise könnten sie Kopf- und Fußzeilen von "OFFICIAL: Sensitive Legislative Secrecy (Example Act)" anwenden.
Hinweis
Bei der Bezeichnung "OFFICIAL Sensitive Legislative Secrecy Example Act" könnte der Anzeigename der Bezeichnung auf "OFFICIAL Sensitive Example Act" gekürzt werden, um die Benutzererfahrung zu verbessern. Die visuelle Kennzeichnung der Bezeichnung müsste jedoch alle Elemente enthalten, um Ansätze für die automatische Bezeichnung zu unterstützen.
Das Etikett und die Kennzeichnungen geben einen Hinweis auf die Sicherheitsklassifizierung, die Tatsache, dass sie für die Gesetzlichen Geheimhaltungsanforderungen relevant ist, und die spezifischen Rechtsvorschriften, auf die verwiesen wird. Markierungen, die in dieser Reihenfolge angewendet werden, ermöglichen es auch externen Organisationen, die die Informationen erhalten, aber nicht die Bezeichnung "Beispielgesetz" konfiguriert haben, die Informationen in Übereinstimmung mit ihrer Legislative Secrecy-Bezeichnung zu identifizieren und zu behandeln. Die Behandlung des "Beispielgesetzes" als Gesetzgebungsgeheimnis ermöglicht es, die eingeschlossenen Informationen zu schützen.
Die Regierung organization, die die Informationen generieren, kann folgendes unterscheiden:
- Ihre Informationen im Zusammenhang mit dem "Beispielgesetz",
- Informationen zu anderen Rechtsvorschriften; und
- Extern generierte Informationen, die sich auf Gesetze beziehen, mit denen andere Abteilungen arbeiten.
Um dies zu implementieren, teilt der Administrator die Regeln für die automatische Bezeichnung in zwei auf und verwendet einen SIT, um Informationen im Zusammenhang mit dem "Beispielgesetz" zu identifizieren:
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf Betriebssystem-LS-x-Header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, ACCESS=Legislative-Secrecy AND Gruppe NOT Inhalt enthält: Typ vertraulicher Informationen Beispiel für DAS ACT-Schlüsselwort SIT, das Folgendes enthält: (Example Act) |
OFFICIAL Sensibles Gesetzesgeheimnis |
| Überprüfen des Betriebssystem-LS-Betreffs | Muster für Antragstellervergleiche:\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Legislative-Secrecy AND Group NOT Inhalt enthält: Vertraulicher Informationstyp: Beispiel für DAS ACT-Schlüsselwort SIT, das Folgendes enthält: (Example Act) |
OFFICIAL Sensibles Gesetzesgeheimnis |
| Überprüfen auf betriebssystembeispiel act x-header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, ACCESS=Legislative-Secrecy AND Inhalt enthält: Typ vertraulicher Informationen Beispiel für DAS ACT-Schlüsselwort SIT, das Folgendes enthält: (Example Act) |
OFFICIAL Sensitive Example Act |
| Überprüfen des Themas "Beispielakte" des Betriebssystems | Muster für Antragstellervergleiche:\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Legislative-Secrecy AND Inhalt enthält: Vertraulicher Informationstyp: Beispiel für DAS ACT-Schlüsselwort SIT, das Folgendes enthält: (Example Act) |
OFFICIAL Sensitive Example Act |
Beispiel für eine E-Mail-basierte Automatische Bezeichnungskonfiguration
Die hier aufgeführten Beispielrichtlinien für automatische Bezeichnungen wenden vertraulichkeitsbezeichnungen automatisch auf eingehende E-Mails an, basierend auf der Markierung, die von externen Behörden angewendet wird.
Die folgenden Beispielrichtlinien sollten nicht die gesamte Konfiguration einer Organisation für die automatische Bezeichnung sein, da auch andere Szenarien berücksichtigt werden sollten, z. B. die aufgeführten, die vorhandene ruhende Elemente bezeichnen .
Richtlinienname: Kennzeichnen eingehender inoffizieller Email
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf UNOFFICIAL x-header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=UNOFFICIAL |
INOFFIZIELL |
| Überprüfen auf INOFFIZIELLE Betreff | Muster für Antragstellervergleiche:\[SEC=UNOFFICIAL\] |
INOFFIZIELL |
Richtlinienname: Eingehende OFFICIAL Email beschriften
Diese Richtlinie muss sicherstellen, dass Elemente, die als OFFICIAL gekennzeichnet sind, nicht fälschlicherweise als OFFICIAL Vertraulich bezeichnet werden. Dazu wird der Nicht-RegEx-Operand (?!) für x-Header und schließende Klammern (\]) in den E-Mail-Betreffzeilen verwendet:
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf OFFICIAL x-header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=OFFICIAL(?![-: ]Sensitive) |
AMTLICH |
| Überprüfen auf OFFIZIELLEn Betreff | Muster für Antragstellervergleiche:\[SEC=OFFICIAL\] |
AMTLICH |
Richtlinienname: Kennzeichnen eingehender OFFICIAL Sensitive Email
Diese Richtlinie muss sicherstellen, dass Elemente, die mit zusätzlichen IMMs (persönlicher Datenschutz usw.) oder Einschränkungen gekennzeichnet sind, nicht fälschlicherweise als OFFICIAL Vertraulich bezeichnet werden. Dazu sucht er nach IMMs oder Einschränkungen, die auf den x-Header und schließende Klammern (\]) im Betreff angewendet werden.
In diesem Beispiel wird überprüft, ob NATIONAL CABINET eine Einschränkung enthält, da dies die einzige Einschränkung ist, die für die Verwendung in Kombination mit OFFICIAL Sensitive in dieser empfohlenen Konfiguration definiert ist. Wenn Ihr organization andere Einschränkungen in der Taxonomie nutzt, sollte die Einschränkung auch im Ausdruck berücksichtigt werden, um sicherzustellen, dass empfangene Elemente mit der richtigen Bezeichnung versehen sind.
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf Betriebssystem-X-Header | Header stimmt mit Muster überein:X-Protective-Marking : OFFICIAL[:\- ]\s?Sensitive(?!, ACCESS)(?!, CAVEAT=SH[-: ]NATIONAL[- ]CABINET) |
OFFICIAL Vertraulich |
| Überprüfen des Betriebssystemantragstellers | Muster für Antragstellervergleiche:\[SEC=OFFICIAL[-: ]Sensitive\] |
OFFICIAL Vertraulich |
Richtlinienname: Kennzeichnen eingehender OFFICIAL Sensitive Personal Privacy Email
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf OS PP x-header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, ACCESS=Personal-Privacy |
OFFICIAL Sensible Privatsphäre |
| Überprüfen des Pp-Betreffs des Betriebssystems | Muster für Antragstellervergleiche:\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Personal-Privacy |
OFFICIAL Sensible Privatsphäre |
Richtlinienname: Kennzeichnen eingehender OFFICIAL Sensitive Legal Privilege Email
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf OS LP x-header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, ACCESS=Legal-Privilege |
OFFICIAL Sensible rechtliche Rechte |
| Überprüfen sie den Lp-Betreff des Betriebssystems. | Muster für Antragstellervergleiche:\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Legal-Privilege |
OFFICIAL Sensible rechtliche Rechte |
Richtlinienname: Beschriftung eingehender OFFICIAL Sensitive Legislative Secrecy
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf Betriebssystem-LS-x-Header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, ACCESS=Legislative-Secrecy |
OFFICIAL Sensibles Gesetzesgeheimnis |
| Überprüfen des Betriebssystem-LS-Betreffs | Muster für Antragstellervergleiche:\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Legislative-Secrecy |
OFFICIAL Sensibles Gesetzesgeheimnis |
Richtlinienname: Beschriftung eingehender OFFICIAL Sensitive NATIONAL CABINET
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf Os NC x-header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, CAVEAT=SH[-: ]NATIONAL[- ]CABINET |
OFFIZIELLEs sensibleS NATIONALES KABINETT |
| Überprüfen auf Betriebssystem-NC-Betreff | Muster für Antragstellervergleiche:\[SEC=OFFICIAL[-: ]Sensitive(?:,)? CAVEAT=SH[-: ]NATIONAL[- ]CABINET |
OFFIZIELLEs sensibleS NATIONALES KABINETT |
Richtlinienname: Eingehende PROTECTED-Email bezeichnen
Diese Richtlinie stellt sicher, dass Elemente, die mit zusätzlichen IMMs oder Einschränkungen gekennzeichnet sind, nicht fälschlicherweise als GESCHÜTZT bezeichnet werden. Dazu sucht er nach IMMs oder Einschränkungen, die auf den x-Header und schließende Klammern (\]) im Betreff angewendet werden.
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf PROTECTED x-header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=PROTECTED(?!, ACCESS)(?!, CAVEAT=SH[-: ]CABINET)(?!, CAVEAT=SH[-: ]NATIONAL[- ]CABINET) |
GESCHÜTZT |
| Überprüfen auf PROTECTED Subject | Muster für Antragstellervergleiche:\[SEC=PROTECTED\] |
GESCHÜTZT |
Richtlinienname: Eingehende protected personal privacy Email
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf PROTECTED PP x-header | Muster für Antragstellervergleiche:X-Protective-Marking : SEC=PROTECTED(?:,)? ACCESS=Personal-Privacy |
GESCHÜTZTer Datenschutz |
| Überprüfen auf PROTECTED PP-Antragsteller | Header stimmt mit Muster überein:\[SEC=PROTECTED(?:,)? ACCESS=Personal-Privacy |
GESCHÜTZTer Datenschutz |
Richtlinienname: Eingehende PROTECTED Legal Privilege-Email bezeichnen
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf PROTECTED LP x-header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=PROTECTED(?:,)? ACCESS=Legal-Privilege |
PROTECTED Legal Privilege |
| Überprüfen auf PROTECTED LP-Betreff | Muster für Antragstellervergleiche:\[SEC=PROTECTED(?:,)? ACCESS=Legal-Privilege |
PROTECTED Legal Privilege |
Richtlinienname: Kennzeichnen eingehender PROTECTED Legislative Secrecy Email
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf PROTECTED LS x-header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=PROTECTED(?:,)? ACCESS=Legislative-Secrecy |
GESCHÜTZTEs Gesetzesgeheimnis |
| Überprüfen auf PROTECTED LS Subject | Muster für Antragstellervergleiche:\[SEC=PROTECTED(?:,)? ACCESS=Legislative-Secrecy |
GESCHÜTZTEs Gesetzesgeheimnis |
Richtlinienname: Eingehende PROTECTED CABINET-Email beschriften
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf P C-x-Header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=PROTECTED, CAVEAT=SH[-: ]CABINET |
GESCHÜTZTER SCHRANK |
| Überprüfen auf PROTECTED C-Betreff | Muster für Antragstellervergleiche:\[SEC=PROTECTED(?:,)? CAVEAT=SH[-: ]CABINET |
GESCHÜTZTER SCHRANK |
Richtlinienname: Eingehende PROTECTED NATIONAL CABINET-Email beschriften
| Regelname | Bedingung | Anzuwendende Bezeichnung |
|---|---|---|
| Überprüfen auf P NC x-header | Header stimmt mit Muster überein:X-Protective-Marking : SEC=PROTECTED, CAVEAT=SH[-: ]NATIONAL[- ]CABINET |
GESCHÜTZTES NATIONALKABINETT |
| Überprüfen auf P NC-Betreff | Muster für Antragstellervergleiche:\[SEC=PROTECTED(?:,)? CAVEAT=SH[-: ]NATIONAL[- ]CABINET |
GESCHÜTZTES NATIONALKABINETT |
SIT-basierte automatische Bezeichnungen werden gemäß den Empfehlungen in der Regelüberprüfung für SITs erstellt.
Bezeichnen vorhandener ruhender Elemente
Richtlinien für automatische Bezeichnungen können so konfiguriert werden, dass Elemente, die sich an OneDrive- und SharePoint-Speicherorten befinden (einschließlich teams-basierter Teams-Websites), auf Schutzmarkierungen oder vertrauliche Informationen überprüft werden. Richtlinien können auf die einzelnen OneDrive-Standorte bestimmter Benutzer, eine Reihe von SharePoint-Websites oder den gesamten Dienst ausgerichtet werden.
Richtlinien können so konfiguriert werden, dass sie nach den einzelnen Methoden zur Informationsidentifizierung suchen, die unter Identifizieren vertraulicher Informationen eingeführt wurden. Dies schließt ein:
- Vordefinierte SITs, z. B. solche, die von Microsoft zur Identifizierung von Informationen im Zusammenhang mit dem Australian Privacy Act oder dem Australian Health Records Act erstellt wurden.
- Benutzerdefinierte SITs, die erstellt werden können, um behörden- oder organization spezifische Informationen zu identifizieren, z. B. Clearance-IDs, FOI-Anforderungsnummer (Freedom of Information) usw.
- Exact Data Match SITs, die basierend auf tatsächlichen Exporten von Informationen generiert wurden.
- Eine beliebige Kombination aus vordefinierten, benutzerdefinierten und/oder exact Data Match-SITs, die vertrauliche Informationen genau identifizieren können.
Es gibt auch neu veröffentlichte kontextbezogene Prädikatfunktionen, die so konfiguriert werden können, dass Elemente anhand der Dokumenteigenschaft, Dateierweiterung oder des Dokumentnamens identifiziert werden. Diese Prädikate sind nützlich für Organisationen, die Klassifizierungen berücksichtigen möchten, die über Nicht-Microsoft-Klassifizierungstools angewendet wurden, die in der Regel Dokumenteigenschaften auf Elemente anwenden. Weitere Informationen zum kontextbezogenen Prädikat finden Sie unter Informationen zum Ermitteln und Schützen Ihrer vertraulichsten Daten durch Microsoft Purview Information Protection.
Der primäre Anwendungsfall für diese Funktionen besteht darin, sicherzustellen, dass vorhandene Informationen mit der richtigen Bezeichnung versehen sind. Dadurch wird Folgendes sichergestellt:
- Legacyinformationen, einschließlich der von lokalen Standorten hochgeladenen Informationen, werden über die bezeichnungsbasierten Steuerelemente von Microsoft Purview geschützt.
- Dateien, die mit historischen Klassifizierungen oder über Nicht-Microsoft-Tools gekennzeichnet sind, verfügen über eine Bezeichnung und werden daher durch bezeichnungsbasierte Steuerelemente geschützt.
SharePoint-basierte Richtlinienkonfiguration
SharePoint-basierte Richtlinien für die automatische Bezeichnung werden innerhalb der Microsoft Purview-Complianceportal unter Information Protection > Richtlinien > für die automatische Bezeichnung konfiguriert.
Richtlinien sollten auf SharePoint-basierte Dienste ausgerichtet sein. Da für jede Vertraulichkeitsbezeichnung, die automatisch angewendet wird, eine Richtlinie erforderlich ist, sollten die Richtlinien entsprechend benannt werden. Beispiel: "SPO – Bezeichnung OFFICIAL Sensitive PP items".
Richtlinien können benutzerdefinierte SITs verwenden, die zum Identifizieren markierter Elemente erstellt wurden. Beispielsweise identifiziert eine SIT, die den folgenden Registrierungsausdruck enthält, OFFICIAL Sensitive Personal Privacy-Markierungen, die entweder durch die textbasierten visuellen Markierungen, die oben und unten in Dokumenten angewendet werden, oder E-Mail-Betreffmarkierungen:
OFFICIAL[:\- ]\s?Sensitive(?:\s|\/\/|\s\/\/\s|,\sACCESS=)Personal[ -]Privacy
In der SIT-Beispielsyntax wurde ein vollständiger Satz von SITs bereitgestellt, die an Denksteinmarkierungen der australischen Regierung ausgerichtet sind , um Schutzmarkierungen zu erkennen.
Die Richtlinie für automatische Bezeichnungen enthält eine Regel mit Inhaltsbedingungen enthält, Typen vertraulicher Informationen*, gefolgt von der SIT, die an der schützenden Markierung ausgerichtet ist.
Nach der Erstellung wird diese Richtlinie im Simulationsmodus ausgeführt, sodass Administratoren die Konfiguration vor jeder automatisierten Anwendung von Bezeichnungen überprüfen können.
Nach der Aktivierung funktioniert die Richtlinie im Hintergrund und wendet Bezeichnungen auf bis zu 25.000 Office-Dokumente pro Tag an.
Beispiel für SharePoint-basierte Richtlinien für automatische Bezeichnungen
Die folgenden Szenarien und Beispielkonfigurationen mindern Informationsrisiken, indem sichergestellt wird, dass alle Elemente im Bereich der geeigneten Datensicherheitskontrollen liegen.
Automatische Bezeichnung nach der Bereitstellung von Vertraulichkeitsbezeichnungen
Nachdem ein organization Vertraulichkeitsbezeichnungen bereitgestellt hat, werden auf alle Dokumente, die von diesem Zeitpunkt an erstellt wurden, Vertraulichkeitsbezeichnungen angewendet. Dies ist auf die obligatorische Bezeichnungskonfiguration zurückzuführen. Elemente, die vor diesem Zeitpunkt erstellt wurden, sind jedoch gefährdet. Um dies zu beheben, können Organisationen eine Reihe von Richtlinien für automatische Bezeichnungen bereitstellen, die nach Markierungen suchen, die auf Dokumente angewendet werden. Wenn eine Markierung identifiziert wird, die an einer Vertraulichkeitsbezeichnung ausgerichtet ist, schließt die Richtlinie diese Bezeichnungsaktivität ab.
In diesen Beispielen für Richtlinien für automatische Bezeichnungen werden die siTs verwendet, die in der SIT-Beispielsyntax definiert sind, um Schutzmarkierungen zu erkennen. Die Richtlinien für die automatische Bezeichnung müssen eine Bedingung enthalten, die den Inhalt enthält, den Typ vertraulicher Informationen enthält, und dann die SIT-Datei einschließen, die an der Richtlinienbezeichnung ausgerichtet ist:
| Richtlinienname | SITZEN | Vertraulichkeitsbezeichnung |
|---|---|---|
| SPO – Bezeichnen VON NICHT OFFIZIELLEN Elementen | INOFFIZIELLE Regex SIT | INOFFIZIELL |
| SPO – Bezeichnung OFFICIAL Items | OFFICIAL Regex SIT | AMTLICH |
| SPO – Bezeichnung OFFICIAL Sensitive items | OFFICIAL Sensitive Regex SIT | OFFICIAL Vertraulich |
| SPO – Bezeichnung OFFICIAL Sensitive PP Items | OFFICIAL Sensitive Personal Privacy Regex SIT | OFFICIAL Sensible Privatsphäre |
| SPO – Bezeichnung OFFICIAL Sensitive LP Items | OFFICIAL Sensitive Legal Privilege Regex SIT | OFFICIAL Sensible rechtliche Rechte |
| SPO – Bezeichnung OFFICIAL Sensitive LS items | OFFICIAL Sensitive Legislative Secrecy Regex SIT | OFFICIAL Sensibles Gesetzesgeheimnis |
| SPO – Bezeichnung OFFICIAL Sensitive NC Items | OFFICIAL Sensitive NATIONAL CABINET Regex SIT | OFFIZIELLEs sensibleS NATIONALES KABINETT |
| SPO : Geschützte Elemente bezeichnen | PROTECTED Regex SIT | GESCHÜTZT |
| SPO : Geschützte PP-Elemente bezeichnen | PROTECTED Personal Privacy Regex SIT | GESCHÜTZTer Datenschutz |
| SPO : Geschützte LP-Elemente bezeichnen | PROTECTED Legal Privilege Regex SIT | PROTECTED Legal Privilege |
| SPO – Beschriftung geschützter LS-Elemente | PROTECTED Legislative Secrecy Regex SIT | GESCHÜTZTEs Gesetzesgeheimnis |
| SPO : Geschützte NC-Elemente bezeichnen | PROTECTED NATIONAL CABINET Regex SIT | GESCHÜTZTES NATIONALKABINETT |
| SPO : Geschützte C-Elemente bezeichnen | PROTECTED CABINET Regex SIT | GESCHÜTZTER SCHRANK |
Automatische Bezeichnung von Elementen mit historischen Klassifizierungen
Wie in Empfehlungen basierend auf historischen Markierungen erläutert, ändern sich die Kennzeichnungsanforderungen der australischen Regierung gelegentlich. Im Jahr 2018 wurden die PSPF-Anforderungen vereinfacht, was die Konsolidierung mehrerer Verbreitungsgrenzmarker (DISSEMINATION Limiting Markers, DLMs) in eine einzige "OFFICIAL: Sensitive"-Kennzeichnung beinhaltete. PSPF-Richtlinie 8 Anhang E enthält eine vollständige Liste der historischen Klassifizierungen und Kennzeichnungen zusammen mit ihren aktuellen Anforderungen an die Handhabung. Einige dieser historischen DLMs weisen im aktuellen Framework entsprechende Markierungen auf. Andere nicht, aber die Verarbeitungsanforderungen gelten weiterhin. Bezeichnungen können hilfreich sein, um Organisationen dabei zu helfen, sicherzustellen, dass sie in der Lage sind, ihre Handhabungsanforderungen zu erfüllen.
Hierfür gibt es zwei mögliche Ansätze:
- Wenden Sie ein modernes Äquivalent der historischen Bezeichnung an.
- Implementieren Sie die Verlaufsbezeichnung transparent. Schließen Sie DLP und andere Richtlinien ein, um die Informationen zu schützen, aber veröffentlichen Sie die Bezeichnung nicht für Benutzer.
Um den ersten dieser Ansätze zu implementieren, muss eine Zuordnungsstrategie entwickelt werden, die die historischen Markierungen durch die organization. Diese Ausrichtung kann komplex sein, da nicht alle Markierungen über eine aktuelle Entsprechung verfügen und einige Regierungsorganisationen Entscheidungen darüber treffen müssen, ob vorhandene Elemente IMMs auf sie angewendet werden sollen. Die folgende Tabelle ist nur als Beispiel angegeben.
| Historische Markierung | Vertraulichkeitsbezeichnung |
|---|---|
| Nur zur offiziellen Verwendung (FOUO) | OFFICIAL Vertraulich |
| Vertraulich | OFFICIAL Vertraulich |
| Sensibel: Rechtliches | OFFICIAL Sensible rechtliche Rechte |
| Sensibel: Persönlich | OFFICIAL Sensible Privatsphäre |
| Vertraulich: Kabinett | GESCHÜTZTER SCHRANK |
Nachdem Organisationen eine Zuordnung definiert haben, müssen SITs erstellt werden, um die verlaufsbezogenen Markierungen zu identifizieren. Bei Markierungen wie "For Official Use Only (FOUO)" ist dies so einfach wie das Erstellen einer Schlüsselwort (keyword) SIT einschließlich dieses Begriffs. Dieser Ansatz eignet sich jedoch möglicherweise nicht für weniger beschreibende Markierungen wie "Sensibel", was wahrscheinlich zu zahlreichen falsch positiven Ergebnissen führt.
Behörden sollten Legacydaten bewerten, um festzustellen, ob es andere Merkmale gibt, die verwendet werden könnten, um verlaufsbezogene Markierungen genauer zu identifizieren, z. B. Haftungsausschlüsse, Dokumenteigenschaften oder andere Marker, die möglicherweise in historischen Elementen vorhanden sind.
Nach der Analyse von Legacydaten, der Erstellung von SITs zum Identifizieren markierter Elemente und der Bereitstellung von Richtlinien für automatische Bezeichnungen können Administratoren eine Simulation ausführen, um die Genauigkeit der Bezeichnungsanwendung und den erwarteten Zeitrahmen für die Fertigstellung zu bestimmen. Die automatische Bezeichnung von Anwendungen in Legacydateien kann dann im Hintergrund ausgeführt werden und wird von Microsoft 365-Organisationsadministratoren überwacht.
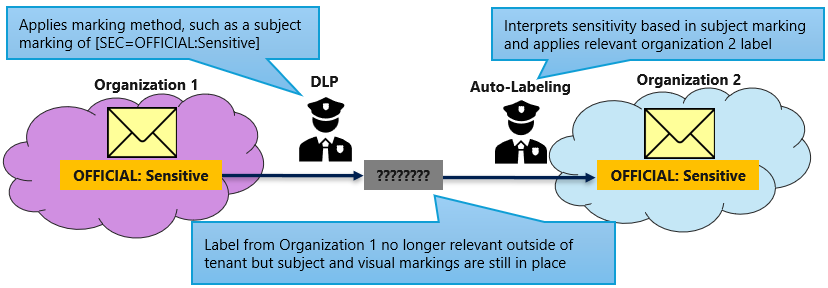
Automatische Bezeichnung nach Änderung der Regierungsbehörden
Änderungen an der Regierungstechnik (MoG) umfassen in der Regel die Verlagerung von Zuständigkeiten und Ressourcen zwischen Regierungsorganisationen. Wenn eine Funktion von einem organization zu einem anderen wechselt, ist es üblich, dass die Informationen, die sich auf diese Funktion beziehen, ebenfalls eine Übergabe erfordern. Da Vertraulichkeitsbezeichnungen nur innerhalb einer einzelnen Microsoft 365-Umgebung relevant sind, wird die angewendete Bezeichnung nicht übernommen, wenn Elemente an eine zweite organization übergeben werden. Schutzmarkierungen werden weiterhin angewendet, aber Kontrollen wie bezeichnungsbasierte DLP- und out-of-place-Datenwarnungen werden wahrscheinlich verrutschen. Um dies zu beheben, können Richtlinien für die automatische Bezeichnung von Inhalten ausgeführt werden, die von externen Quellen empfangen werden, um sicherzustellen, dass die richtigen Bezeichnungen basierend auf den vorhandenen Schutzmarkierungen des Elements angewendet werden.
Die Konfiguration, um dies zu erreichen, ist die gleiche wie unter Automatische Bezeichnung nach der Bereitstellung von Vertraulichkeitsbezeichnungen beschrieben. Die einzige Ausnahme besteht darin, dass Richtlinien auf die spezifischen Speicherorte ausgerichtet sind, an denen empfangene Elemente gespeichert werden.