Ereignisaggregation und -sammlung mit der Windows Azure-Diagnose
Bei Verwendung eines Azure Service Fabric-Clusters empfiehlt es sich, die Protokolle aller Knoten an einem zentralen Ort zu sammeln. Das Sammeln der Protokolle an einem zentralen Ort hilft Ihnen bei Analyse und Behandlung von Problemen, die ggf. in Ihrem Cluster oder in den Anwendungen und Diensten des Clusters auftreten.
Eine Möglichkeit zum Hochladen und Sammeln von Protokollen ist die Verwendung der Windows Azure-Diagnose (WAD)-Erweiterung, mit der Protokolle in Azure Storage hochgeladen und an Azure Application Insights oder Event Hubs gesendet werden können. Sie können zudem einen externen Prozess verwenden, um die Ereignisse aus dem Speicher zu lesen und in einem Analyseplattformprodukt wie Azure Monitor-Protokolle oder in einer anderen Protokollanalyselösung zu verwenden.
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Voraussetzungen
In diesem Artikel werden folgende Tools verwendet:
Service Fabric-Plattformereignisse
Service Fabric richtet einige vorgefertigte Protokollierungskanäle ein. Folgende dieser Kanäle sind mit der Erweiterung vorkonfiguriert, um Überwachungs- und Diagnosedaten an eine Speichertabelle oder an einen anderen Speicherort zu senden:
- Betriebsereignisse: Vorgänge einer höheren Ebene, die von der Service Fabric-Plattform ausgeführt werden. Beispiele hierfür wären die Erstellung von Anwendungen und Diensten, Knotenzustandsänderungen und Upgradeinformationen. Diese werden als ETW-Protokolle (Event Tracing for Windows, Ereignisablaufverfolgung für Windows-Ereignisse) ausgegeben.
- Ereignisse des Reliable Actors-Programmiermodells
- Ereignisse des Reliable Services-Programmiermodells
Bereitstellen der Diagnoseerweiterung über das Portal
Zum Sammeln von Protokollen muss zunächst die Diagnoseerweiterung auf den VM-Skalierungsgruppenknoten des Service Fabric-Clusters bereitgestellt werden. Die Diagnoseerweiterung sammelt Protokolle auf allen VMs und lädt sie in das angegebene Speicherkonto hoch. Die folgenden Schritte zeigen die entsprechende Vorgehensweise für neue und vorhandene Cluster über das Azure-Portal und unter Verwendung von Azure Resource Manager-Vorlagen.
Bereitstellen der Diagnoseerweiterung im Rahmen der Clustererstellung über das Azure-Portal
Erweitern Sie bei der Clustererstellung im Schritt für die Clusterkonfiguration die optionalen Einstellungen, und vergewissern Sie sich, dass die Diagnose auf Ein (Standardeinstellung) festgelegt ist.
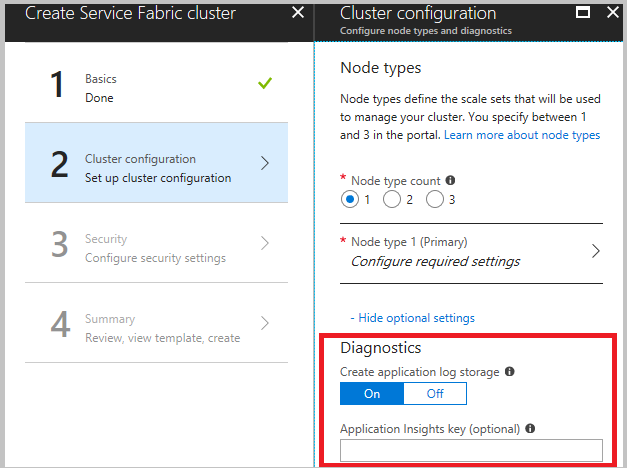
Es empfiehlt sich, die Vorlage vor dem Klicken auf „Erstellen“ im letzten Schritt herunterzuladen. Ausführliche Informationen finden Sie unter Erstellen eines Service Fabric-Clusters in Azure mithilfe von Azure Resource Manager. Sie benötigen die Vorlage, um die Kanäle zu ändern, für die Daten erfasst werden sollen. (Die Kanäle sind weiter oben aufgeführt.)
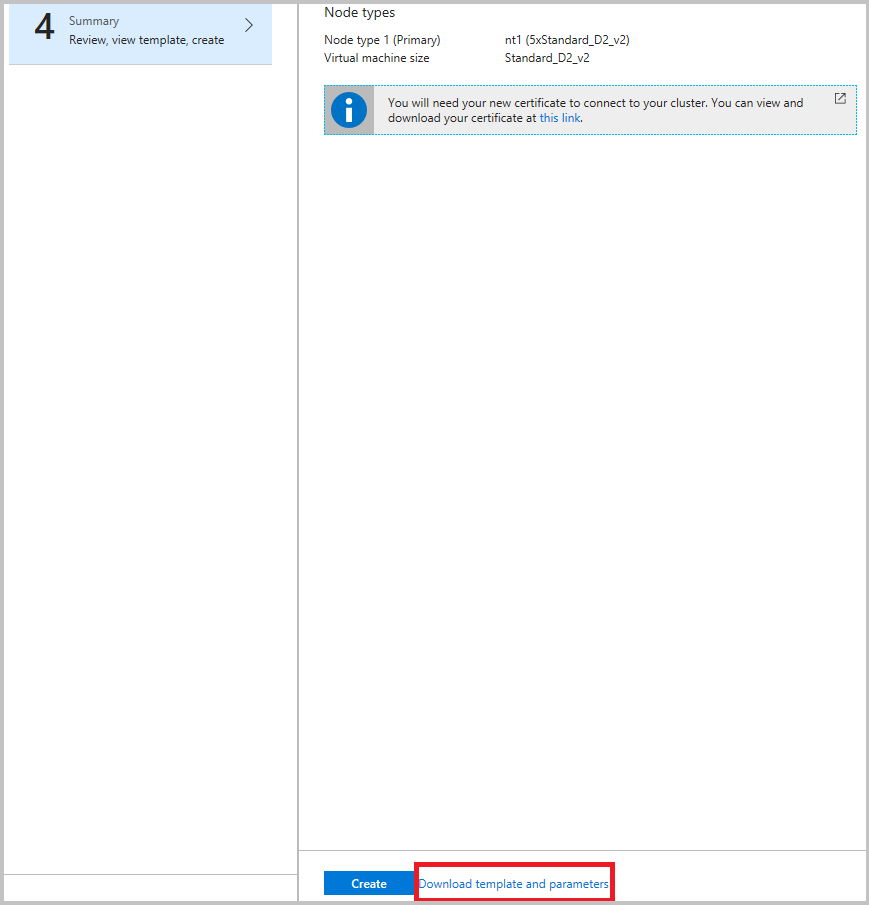
Nachdem nun Ereignisse in Azure Storage aggregiert werden, können Sie Azure Monitor-Protokolle einrichten, um Erkenntnisse zu erhalten und diese im Portal für Azure Monitor-Protokolle abzufragen.
Hinweis
Es gibt derzeit keine Möglichkeit, die an die Tabellen gesendeten Ereignisse zu filtern oder zu optimieren. Wenn Sie keinen Prozess zum Entfernen von Ereignissen aus der Tabelle implementieren, wächst die Tabelle weiter an. (Die Größe ist standardmäßig auf 50 GB beschränkt.) Eine Anleitung zum Ändern dieser Einstellung finden Sie weiter unten in diesem Artikel. Im Watchdog-Beispiel finden Sie außerdem ein Beispiel für die Ausführung eines Datenbereinigungsdiensts. Die Erstellung eines solchen Diensts wird empfohlen, sofern Sie Protokolle nicht aus einem triftigen Grund länger als 30 oder 90 Tage speichern müssen.
Bereitstellen der Diagnoseerweiterung über Azure Resource Manager
Erstellen eines Clusters mit der Diagnoseerweiterung
Wenn Sie einen Cluster mithilfe von Resource Manager erstellen möchten, müssen Sie der vollständigen Resource Manager-Vorlage den JSON-Code für die Diagnosekonfiguration hinzufügen. Die Resource Manager-Vorlagenbeispiele enthalten eine Beispielvorlage mit hinzugefügter Diagnosekonfiguration für einen Cluster mit fünf VMs. Sie können sie hier im Azure-Beispielkatalog anzeigen: Cluster mit fünf Knoten mit der Resource Manager-Beispielvorlage für die Diagnose.
Öffnen Sie die Datei „azuredeploy.json“ und suchen nach IaaSDiagnostics, um die Diagnoseeinstellung in der Resource Manager-Vorlage anzuzeigen. Klicken Sie zum Erstellen eines Clusters mit dieser Vorlage einfach auf die Schaltfläche In Azure bereitstellen (unter dem oben angegebenen Link).
Alternativ können Sie das Resource Manager-Beispiel herunterladen, anpassen und den Befehl New-AzResourceGroupDeployment in einem Azure PowerShell-Fenster ausführen, um einen Cluster mit der geänderten Vorlage zu erstellen. Im folgenden Code finden Sie die Parameter, die Sie an den Befehl übergeben. Ausführliche Informationen zum Bereitstellen einer Ressourcengruppe mit PowerShell finden Sie im Artikel Bereitstellen einer Ressourcengruppe mit einer Azure Resource Manager-Vorlage.
Hinzufügen der Diagnoseerweiterung zu einem vorhandenen Cluster
Wenn Sie bereits über einen Cluster ohne Diagnosebereitstellung verfügen, können Sie sie mithilfe der Clustervorlage hinzufügen oder den Cluster aktualisieren. Ändern Sie die zum Erstellen des vorhandenen Clusters verwendete Resource Manager-Vorlage, oder laden Sie die Vorlage, wie oben beschrieben, aus dem Portal herunter. Ändern Sie die Datei „template.json“ wie folgt:
Fügen Sie der Vorlage eine neue Speicherressource hinzu, indem Sie sie dem Ressourcenabschnitt hinzufügen.
{
"apiVersion": "2018-07-01",
"type": "Microsoft.Storage/storageAccounts",
"name": "[parameters('applicationDiagnosticsStorageAccountName')]",
"location": "[parameters('computeLocation')]",
"sku": {
"name": "[parameters('applicationDiagnosticsStorageAccountType')]"
"tier": "standard"
},
"tags": {
"resourceType": "Service Fabric",
"clusterName": "[parameters('clusterName')]"
}
},
Ergänzen Sie als Nächstes den Parameterabschnitt direkt nach den Speicherkontodefinitionen (zwischen supportLogStorageAccountName). Ersetzen Sie den Platzhaltertext storage account name goes here durch den Namen des gewünschten Speicherkontos.
"applicationDiagnosticsStorageAccountType": {
"type": "string",
"allowedValues": [
"Standard_LRS",
"Standard_GRS"
],
"defaultValue": "Standard_LRS",
"metadata": {
"description": "Replication option for the application diagnostics storage account"
}
},
"applicationDiagnosticsStorageAccountName": {
"type": "string",
"defaultValue": "**STORAGE ACCOUNT NAME GOES HERE**",
"metadata": {
"description": "Name for the storage account that contains application diagnostics data from the cluster"
}
},
Aktualisieren Sie dann den Abschnitt VirtualMachineProfile der template.json-Datei durch Hinzufügen des folgenden Codes innerhalb des Arrays „extensions“. Achten Sie darauf, ein Komma am Anfang oder Ende hinzuzufügen – je nach Einfügeposition.
{
"name": "[concat(parameters('vmNodeType0Name'),'_Microsoft.Insights.VMDiagnosticsSettings')]",
"properties": {
"type": "IaaSDiagnostics",
"autoUpgradeMinorVersion": true,
"protectedSettings": {
"storageAccountName": "[parameters('applicationDiagnosticsStorageAccountName')]",
"storageAccountKey": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', parameters('applicationDiagnosticsStorageAccountName')),'2015-05-01-preview').key1]",
"storageAccountEndPoint": "https://core.windows.net/"
},
"publisher": "Microsoft.Azure.Diagnostics",
"settings": {
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": "50000",
"EtwProviders": {
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
{
"provider": "Microsoft-ServiceFabric-Services",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableServiceEventTable"
}
}
],
"EtwManifestProviderConfiguration": [
{
"provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
},
{
"provider": "02d06793-efeb-48c8-8f7f-09713309a810",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
}
]
}
}
},
"StorageAccount": "[parameters('applicationDiagnosticsStorageAccountName')]"
},
"typeHandlerVersion": "1.5"
}
}
Nachdem Sie die Datei „template.json“ wie beschrieben geändert haben, veröffentlichen Sie die Resource Manager-Vorlage erneut. Wenn die Vorlage exportiert wurde, wird sie durch Ausführen der Datei „deploy.ps1“ neu veröffentlicht. Stellen Sie nach der Bereitstellung sicher, dass ProvisioningState den Status Erfolgreich aufweist.
Tipp
Wenn Sie Container in Ihrem Cluster bereitstellen, aktivieren Sie WAD zum Abrufen von Docker-Statistiken, indem Sie sie Ihrem WadCfg > DiagnosticMonitorConfiguration-Abschnitt hinzufügen.
"DockerSources": {
"Stats": {
"enabled": true,
"sampleRate": "PT1M"
}
},
Aktualisieren des Speicherkontingents
Da die von der Erweiterung ausgefüllten Tabellen so lange wachsen, bis das Kontingent erreicht ist, empfiehlt es sich unter Umständen, die Kontingentgröße zu verringern. Der Wert ist standardmäßig auf 50 GB festgelegt und kann in der Vorlage unter dem Feld overallQuotaInMB (unter DiagnosticMonitorConfiguration) konfiguriert werden.
"overallQuotaInMB": "50000",
Protokollsammlungskonfigurationen
Protokolle aus zusätzlichen Kanälen stehen auch für die Sammlung zur Verfügung. Im Folgenden finden Sie einige der am häufigsten verwendeten Konfigurationen, die Sie in der Vorlage für Cluster vornehmen können, die in Azure ausgeführt werden.
Betriebskanal – Basis: Standardmäßig aktiviert, von Service Fabric und im Cluster ausgeführte Vorgänge auf höchster Ebene, einschließlich Ereignisse für einen gestarteten Knoten, eine neu bereitgestellte Anwendung, ein Rollback für ein Upgrade usw. Eine Liste von Ereignissen finden Sie unter Betriebskanal.
"scheduledTransferKeywordFilter": "4611686018427387904"Betriebskanal – ausführlich: Dies schließt Integritätsberichte und Lastenausgleichsentscheidungen sowie alle Elemente im Basisbetriebskanal ein. Diese Ereignisse werden entweder vom System oder von Ihrem Code mithilfe der APIs zum Melden der Integrität oder Auslastung (beispielsweise ReportPartitionHealth oder ReportLoad) generiert. Diese Ereignisse können Sie in der Diagnoseereignisansicht von Visual Studio anzeigen, indem Sie „Microsoft-ServiceFabric:4:0x4000000000000008“ zur Liste mit den ETW-Anbietern hinzufügen.
"scheduledTransferKeywordFilter": "4611686018427387912"Daten- und Messagingkanal – Basis: Wichtige Protokolle und im Messaging- und Datenpfad (zurzeit nur ReverseProxy) zusätzlich zu detaillierten Betriebskanalprotokollen generierte Ereignisse. Diese Ereignisse sind Fehler bei Verarbeitungsanforderungen und andere wichtige Probleme bei ReverseProxy sowie verarbeitete Anforderungen. Dies ist unsere Empfehlung für umfassende Protokollierung. Diese Ereignisse können Sie in der Diagnoseereignisanzeige von Visual Studio anzeigen, indem Sie „Microsoft-ServiceFabric4:0x4000000000000010“ der Liste mit den ETW-Anbietern hinzufügen.
"scheduledTransferKeywordFilter": "4611686018427387928"Daten- und Messagingkanal – ausführlich: Kanal mit Details zu allen weniger wichtigen Protokollen von Daten und Messaging im Cluster und dem ausführlichen Betriebskanal. Eine ausführliche Problembehandlung aller Reverseproxyereignisse finden Sie im Reverseproxy-Diagnosehandbuch. Diese Ereignisse können Sie in der Diagnoseereignisansicht von Visual Studio anzeigen, indem Sie „Microsoft-ServiceFabric:4:0x4000000000000020“ der Liste mit den ETW-Anbietern hinzufügen.
"scheduledTransferKeywordFilter": "4611686018427387944"
Hinweis
Dieser Kanal hat ein sehr hohes Ereignisvolumen, sodass bei Aktivierung der Sammlung von Ereignissen aus diesem ausführlichen Kanal schnell zahlreiche Ablaufverfolgungen erstellt werden, und kann viel Speicherkapazität verbrauchen. Aktivieren Sie dies also nur, wenn es unbedingt erforderlich ist.
Um den Basisbetriebskanal unserer Empfehlung für umfassende Protokollierung bei geringstmöglichen Störungen zu aktivieren, würde die EtwManifestProviderConfiguration in WadCfg Ihrer Vorlage wie folgt aussehen:
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": "50000",
"EtwProviders": {
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
{
"provider": "Microsoft-ServiceFabric-Services",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableServiceEventTable"
}
}
],
"EtwManifestProviderConfiguration": [
{
"provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
},
{
"provider": "02d06793-efeb-48c8-8f7f-09713309a810",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
}
]
}
}
},
Erfassen aus neuen EventSource-Kanälen
Wenn Sie die Diagnose aktualisieren möchten, um Protokolle aus neuen EventSource-Kanälen zu sammeln, die eine neu bereitzustellende Anwendung darstellen, führen Sie die Schritte aus, die zuvor für die Einrichtung der Diagnose für einen vorhandenen Cluster beschrieben wurden.
Aktualisieren Sie den Abschnitt EtwEventSourceProviderConfiguration in der template.json-Datei, und fügen Sie Einträge für die neuen EventSource-Kanäle hinzu, bevor Sie das Konfigurationsupdate mithilfe des PowerShell-Befehls New-AzResourceGroupDeployment anwenden. Der Name der Ereignisquelle wird als Teil des Codes in der von Visual Studio generierten Datei „ServiceEventSource.cs“ definiert.
Wenn Ihre Ereignisquelle beispielsweise My-Eventsource heißt, fügen Sie folgenden Code hinzu, um Ereignisse aus My-Eventsource in eine Tabelle namens MyDestinationTableName zu platzieren.
{
"provider": "My-Eventsource",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "MyDestinationTableName"
}
}
Um Leistungsindikatoren oder Ereignisprotokolle zu sammeln, ändern Sie die Resource Manager-Vorlage anhand der Beispiele unter Erstellen eines virtuellen Windows-Computers mit Überwachung und Diagnose mithilfe von Azure Resource Manager-Vorlagen. Veröffentlichen Sie die Resource Manager-Vorlage dann erneut.
Erfassen von Leistungsindikatoren
Fügen Sie zu „WadCfg“ > „DiagnosticMonitorConfiguration“ in der Resource Manager-Vorlage für Ihren Cluster die Leistungsindikatoren hinzu, um Leistungsmetriken Ihres Clusters zu erfassen. Unter Performance monitoring with Windows Azure Diagnostics extension (Leistungsüberwachung mit der Microsoft Azure-Diagnoseerweiterung) finden Sie Schritte zum Ändern von WadCfg, um bestimmte Leistungsindikatoren zu sammeln. Eine Liste der Leistungsindikatoren, deren Sammlung wir empfehlen, finden Sie unter Leistungsmetriken.
Wenn Sie eine Application Insights-Senke verwenden (siehe dazu den folgenden Abschnitt) und möchten, dass diese Metriken in Application Insights angezeigt werden, dann fügen Sie den Namen der Senke im Abschnitt „sinks“ (s.o.) ein. Dadurch werden die einzeln konfigurierten Leistungsindikatoren automatisch an Ihre Application Insights-Ressource gesendet.
Senden von Protokollen an Application Insights
Konfigurieren von Application Insights mit WAD
Hinweis
Dies gilt gegenwärtig nur für Windows-Cluster.
Es gibt grundsätzlich zwei Möglichkeiten, um Daten von WAD an Azure Application Insights zu senden. Hierzu wird der WAD-Konfiguration über das Azure-Portal oder über eine Resource Manager-Vorlage eine Application Insights-Senke hinzugefügt.
Hinzufügen eines Application Insights-Instrumentierungsschlüssels beim Erstellen eines Clusters im Azure-Portal
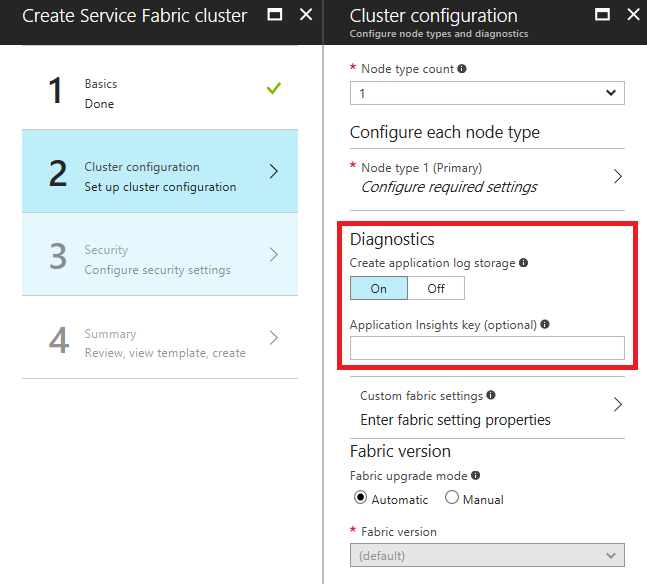
Wenn beim Erstellen eines Clusters die Diagnose aktiviert ist („Ein“), wird ein optionales Feld angezeigt, in dem ein Application Insights-Instrumentierungsschlüssel eingegeben werden kann. Wenn Sie hier Ihren Application Insights-Schlüssel einfügen, wird die Application Insights-Senke automatisch in der Resource Manager-Vorlage konfiguriert, die zum Bereitstellen Ihres Clusters verwendet wird.
Hinzufügen der Application Insights-Senke zur Resource Manager-Vorlage
Fügen Sie in „WadCfg“ der Resource Manager-Vorlage durch Einfügen der folgenden beiden Änderungen eine Senke („Sink“) hinzu:
Fügen Sie die Konfiguration der Senke hinzu, sobald das Deklarieren von
DiagnosticMonitorConfigurationabgeschlossen ist:"SinksConfig": { "Sink": [ { "name": "applicationInsights", "ApplicationInsights": "***ADD INSTRUMENTATION KEY HERE***" } ] }Nehmen Sie die Senke in
DiagnosticMonitorConfigurationauf, indem Sie die folgende Zeile inDiagnosticMonitorConfigurationvonWadCfghinzufügen (unmittelbar bevorEtwProvidersdeklariert werden):"sinks": "applicationInsights"
In den beiden obigen Codeausschnitten wurde für die Senke der Name „applicationInsights“ verwendet. Dieser Name muss nicht verwendet werden. Solange der Name der Senke in „sinks“ eingefügt wird, können Sie eine beliebige Zeichenfolge als Name festlegen.
Protokolle aus dem Cluster werden derzeit als Ablaufverfolgungen in der Application Insights-Protokollanzeige angezeigt. Da die meisten Ablaufverfolgungen, die von der Plattform stammen, als „Information“ eingestuft sind, haben Sie auch die Möglichkeit, die Senkenkonfiguration so zu ändern, dass nur Protokolle vom Typ „Warnung“ und „Fehler“ gesendet werden. Dazu können Sie „Kanäle“ zu Ihrer Senke hinzufügen, wie es in diesem Artikel erklärt wird.
Hinweis
Wenn Sie im Portal oder in der Resource Manager-Vorlage einen falschen Application Insights-Schlüssel verwenden, müssen Sie ihn manuell ändern und den Cluster aktualisieren und erneut bereitstellen.
Nächste Schritte
Wenn Sie die Azure-Diagnose richtig konfiguriert haben, enthalten Ihre Speichertabellen Daten aus den ETW- und EventSource-Protokollen. Wenn Sie Azure Monitor-Protokolle, Kibana oder eine andere Plattform zur Datenanalyse und -visualisierung verwenden möchten, die in der Resource Manager-Vorlage nicht direkt konfiguriert ist, richten Sie die gewünschte Plattform so ein, dass sie die Daten aus diesen Speichertabellen liest. Für Azure Monitor-Protokolle ist dies recht einfach zu erreichen. Informationen dazu finden Sie unter Ereignis- und Protokollanalyse. Bei Application Insights verhält sich dies ein wenig anders, da es bei der Konfiguration der Diagnoseerweiterung konfiguriert werden kann. Wenn Sie also AI verwenden möchten, lesen Sie die Informationen im entsprechenden Artikel.
Hinweis
Es gibt derzeit keine Möglichkeit, die an die Tabelle gesendeten Ereignisse zu filtern oder zu optimieren. Wenn Sie keinen Prozess zum Entfernen von Ereignissen aus der Tabelle implementieren, wächst die Tabelle weiter an. Im Watchdog-Beispiel finden Sie derzeit ein Beispiel für einen ausgeführten Datenbereinigungsdienst. Die Erstellung eines solchen Diensts wird empfohlen, sofern Sie Protokolle nicht aus einem triftigen Grund länger als 30 oder 90 Tage speichern müssen.
- Erfahren Sie, wie Sie Leistungsindikatoren oder Protokolle mithilfe der Diagnoseerweiterung sammeln können.
- Ereignisanalyse und Visualisierung mit Application Insights
- Ereignisanalyse und -visualisierung mit Azure Monitor-Protokollen
- Ereignisanalyse und Visualisierung mit Application Insights
- Ereignisanalyse und -visualisierung mit Azure Monitor-Protokollen