Erste Schritte mit DICOM-Daten in Analyseworkloads
In diesem Artikel wird beschrieben, wie Sie mit DICOM-Daten® in Analyseworkloads mit Azure Data Factory und Microsoft Fabric beginnen.
Voraussetzungen
Bevor Sie beginnen, führen Sie die folgenden Schritte aus:
- Erstellen Sie ein Speicherkonto mit Azure Data Lake Storage Gen2-Funktionen, indem Sie einen hierarchischen Namespace aktivieren:
- Erstellen Sie einen Container zum Speichern von DICOM-Metadaten, z. B. mit dem Namen
dicom.
- Erstellen Sie einen Container zum Speichern von DICOM-Metadaten, z. B. mit dem Namen
- Stellen Sie eine Instanz des DICOM-Diensts bereit.
- (Optional) Stellen Sie den DICOM-Dienst mit Data Lake Storage bereit, um direkten Zugriff auf DICOM-Dateien zu ermöglichen.
- Erstellen Sie eine Data Factory-Instanz:
- Aktivieren Sie eine systemseitig zugewiesenen verwalteten Identität.
- Erstellen Sie ein Lakehouse in Fabric.
- Fügen Sie Rollenzuweisungen zur vom Data Factory-System zugewiesenen verwalteten Identität für den DICOM-Dienst und das Data Lake Storage Gen2-Speicherkonto hinzu:
- Fügen Sie die Rolle DICOM-Datenleser hinzu, um dem DICOM-Dienst die Berechtigung zu erteilen.
- Fügen Sie die Rolle Storage Blob Data Contributor hinzu, um dem Data Lake Storage Gen2-Konto die Berechtigung zu erteilen.
Konfigurieren einer Data Factory-Pipeline für den DICOM-Dienst
In diesem Beispiel wird eine Data Factory-Pipeline verwendet, um DICOM-Attribute für Instanzen, Datenreihen und Studien in ein Speicherkonto in einem Delta-Tabellenformat zu schreiben.
Öffnen Sie im Azure-Portal die Data Factory-Instanz, und wählen Sie Studio starten aus, um zu beginnen.

Erstellen von verknüpften Diensten
Data Factory-Pipelines werden aus Datenquellen gelesen und in Datensenken geschrieben, die in der Regel andere Azure-Dienste sind. Diese Verbindungen mit anderen Diensten werden als verknüpfte Dienste verwaltet.
Die Pipeline in diesem Beispiel liest Daten aus einem DICOM-Dienst und schreibt die Ausgabe in ein Speicherkonto, sodass ein verknüpfter Dienst für beides erstellt werden muss.
Erstellen eines verknüpften Diensts für den DICOM-Dienst
Wählen Sie in Azure Data Factory Studio im Menü auf der linken Seite Verwalten aus. Wählen Sie unter Verbindungen die Option Verknüpfte Dienste und dann Neu aus.

Suchen Sie im Bereich Neuer verknüpfter Dienst nach REST. Wählen Sie die REST-Kachel und dann Weiter aus.

Geben Sie einen Namen und eine Beschreibung des verknüpften Diensts ein.

Geben Sie im Feld Basis-URL die Dienst-URL für Ihren DICOM-Dienst ein. Ein DICOM-Dienst, der im
contosoclinicArbeitsbereichcontosohealthgenannt wird, hat zum Beispiel die Dienst-URLhttps://contosohealth-contosoclinic.dicom.azurehealthcareapis.com.Wählen Sie für den Authentifizierungstyp die Option Vom System zugewiesene verwaltete Identität aus.
Geben Sie für die AAD-Ressourceein
https://dicom.healthcareapis.azure.com. Diese URL ist für alle DICOM-Dienstinstanzen identisch.Nachdem Sie die erforderlichen Felder ausgefüllt haben, wählen Sie Verbindung testen aus, um sicherzustellen, dass die Rollen der Identität ordnungsgemäß konfiguriert sind.
Wenn der Verbindungstest erfolgreich ist, wählen Sie Erstellen aus.



Erstellen eines verknüpften Diensts für Azure Data Lake Storage Gen2
Wählen Sie in Data Factory Studio im Menü auf der linken Seite Verwalten aus. Wählen Sie unter Verbindungen die Option Verknüpfte Dienste und dann Neu aus.
Suchen Sie im Bereich Neuer verknüpfter Dienst nach Azure Data Lake Storage Gen2. Wählen Sie die Kachel Azure Data Lake Storage Gen2 und dann Fortfahren aus.
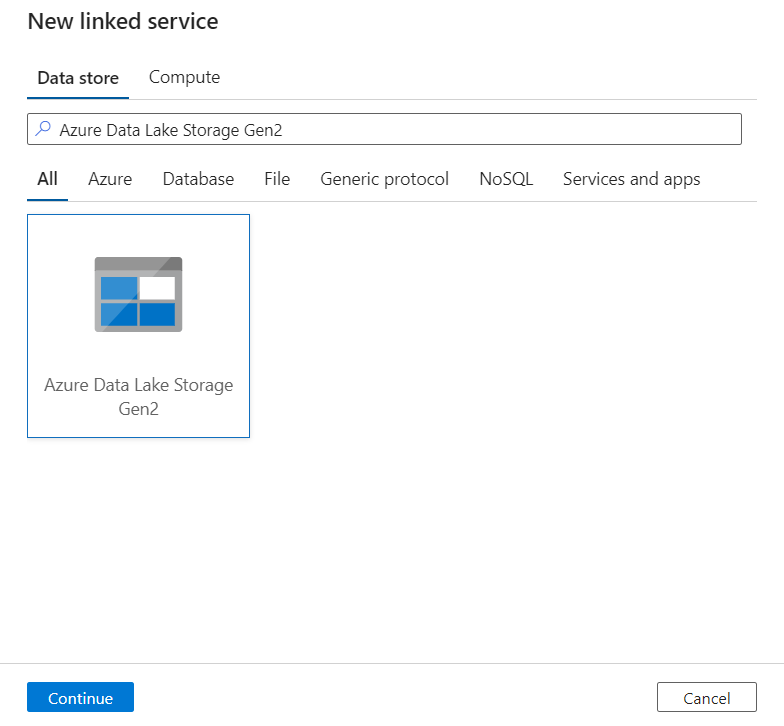
Geben Sie einen Namen und eine Beschreibung des verknüpften Diensts ein.

Wählen Sie für den Authentifizierungstyp die Option Vom System zugewiesene verwaltete Identität aus.
Geben Sie die Details des Speicherkontos ein, indem Sie die URL zum Speicherkonto manuell eingeben. Sie können auch das Azure-Abonnement und das Speicherkonto aus den Dropdownlisten auswählen.
Nachdem Sie die erforderlichen Felder ausgefüllt haben, wählen Sie Verbindung testen aus, um sicherzustellen, dass die Rollen der Identität ordnungsgemäß konfiguriert sind.
Wenn der Verbindungstest erfolgreich ist, wählen Sie Erstellen aus.


Erstellen einer Pipeline für DICOM-Daten
Data Factory-Pipelines sind eine Sammlung von Aktivitäten, die eine Aufgabe ausführen, z. B. das Kopieren von DICOM-Metadaten in Delta-Tabellen. In diesem Abschnitt wird die Erstellung einer Pipeline beschrieben, die DICOM-Daten regelmäßig mit Delta-Tabellen synchronisiert, wenn Daten zu einem DICOM-Dienst hinzugefügt, aktualisiert und gelöscht werden.
Wählen Sie im Menü auf der linken Seite Autor aus. Wählen Sie im Bereich Factory-Ressourcen das Pluszeichen (+) aus, um eine neue Ressource hinzuzufügen. Wählen Sie Pipeline und dann im Menü den Vorlagenkatalog aus.

Suchen Sie im Vorlagenkatalognach DICOM. Wählen Sie die DICOM-Metadatenänderungen an ADLS Gen2 in der Delta-Format-Kachel aus und wählen Sie dann Weiter aus.

Wählen Sie im Abschnitt Eingaben die verknüpften Dienste aus, die zuvor für das DICOM-Dienst- und Data Lake Storage Gen2-Konto erstellt wurden.

Wählen Sie Diese Vorlage verwenden aus, um die neue Pipeline zu erstellen.



Erstellen einer Pipeline für DICOM-Daten
Wenn Sie den DICOM-Dienst mit Azure Data Lake Storage erstellt haben, müssen Sie anstelle der Vorlage aus dem Vorlagenkatalog eine benutzerdefinierte Vorlage verwenden, um einen neuen fileName-Parameter in die Metadatenpipeline aufzunehmen. Führen Sie die folgenden Schritte aus, um die Pipeline zu konfigurieren.
Laden Sie die Vorlage von GitHub herunter. Die Vorlagendatei ist ein komprimierter (gezippter) Ordner. Sie müssen die Dateien nicht extrahieren, da sie bereits in komprimierter Form hochgeladen wurden.
Wählen Sie in Azure Data Factory im linken Menü die Option Ersteller aus. Wählen Sie im Bereich Factory-Ressourcen das Pluszeichen (+) aus, um eine neue Ressource hinzuzufügen. Wählen Sie Pipeline und dann Aus Pipelinevorlage importieren aus.
Wählen Sie im Fenster Öffnen die Vorlage aus, die Sie heruntergeladen haben. Klicken Sie auf Öffnen.
Wählen Sie im Abschnitt Eingaben die verknüpften Dienste aus, die für das DICOM-Dienst- und Azure Data Lake Storage Gen2-Konto erstellt wurden.
Wählen Sie Diese Vorlage verwenden aus, um die neue Pipeline zu erstellen.
Planen einer Pipeline
Pipelines werden von Triggern geplant. Es gibt verschiedene Arten von Triggern. Mit Zeitplantriggern können Pipelines zu bestimmten Tageszeiten ausgeführt werden, z. B. stündlich oder jeden Tag um Mitternacht. Manuelle Auslöser lösen Pipelines bei Bedarf aus, d. h. sie werden ausgeführt, wann immer Sie möchten.
In diesem Beispiel wird ein Trigger mit rollierendem Fenster verwendet, um die Pipeline mit einem Startpunkt und einem regelmäßigen Zeitintervall periodisch auszuführen. Weitere Informationen zu Triggern finden Sie unter Pipelineausführung und -Trigger in Azure Data Factory oder Azure Synapse Analytics.
Erstellen Sie einen Trigger mit rollierendem Fenster
Wählen Sie im Menü auf der linken Seite Autor aus. Wählen Sie die Pipeline für den DICOM-Dienst aus und wählen Sie in der Menüleiste Auslöser hinzufügen und Neu/Bearbeiten aus.

Wählen Sie im Bereich Trigger hinzufügen das Dropdownmenü Trigger auswählen und dann Neu aus.
Geben Sie für den Trigger einen Namen und eine Beschreibung ein.
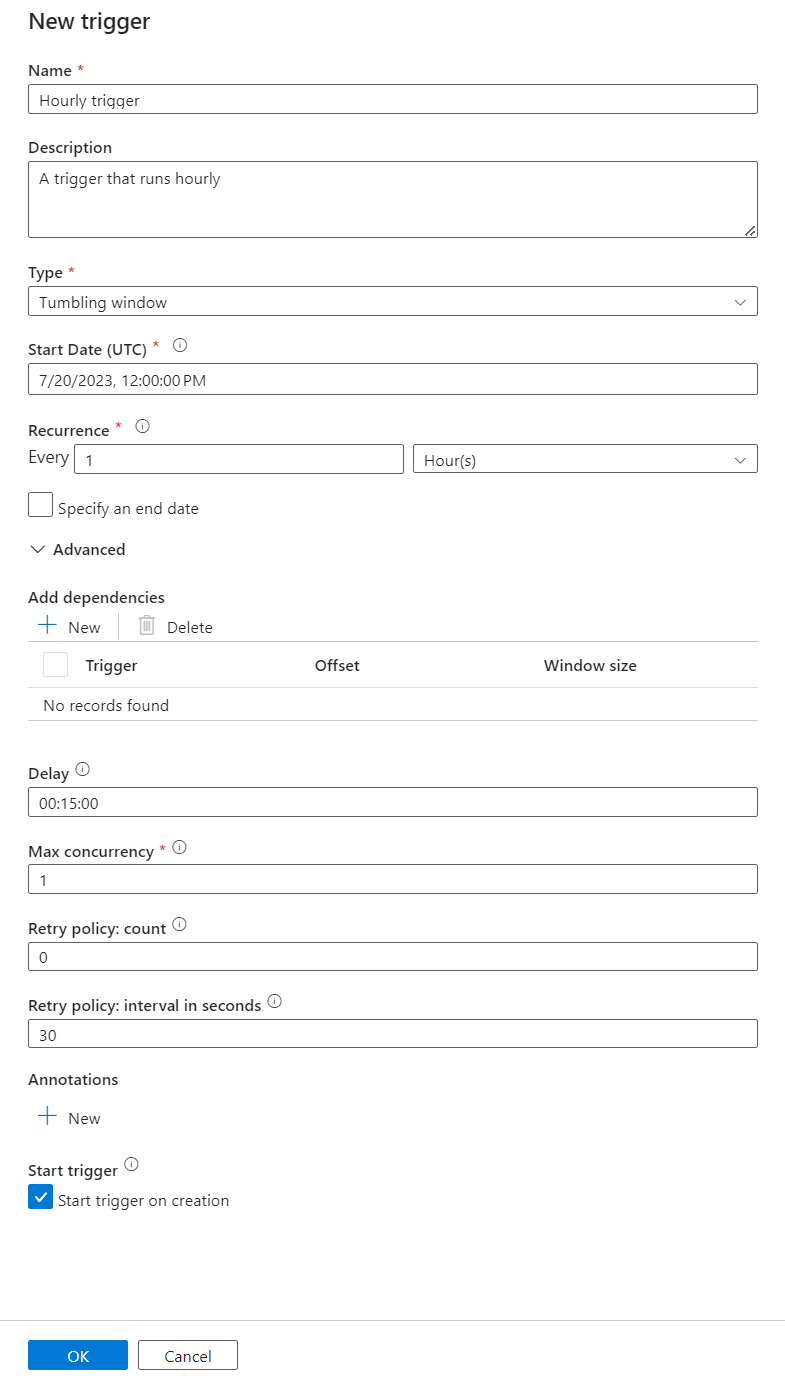
Wählen Sie Rollierendes Fenster als Typ aus.
Um eine Pipeline zu konfigurieren, die stündlich ausgeführt wird, legen Sie die Serie auf 1 Stunde fest.
Erweitern Sie den Abschnitt Erweitert und geben Sie eine Verzögerung von 15 Minuten ein. Mit dieser Einstellung können alle ausstehenden Vorgänge am Ende einer Stunde vor der Verarbeitung abgeschlossen werden.
Legen Sie die Maximale Parallelität auf 1 fest, um die Konsistenz zwischen Tabellen sicherzustellen.
Wählen Sie OK aus, um die Konfiguration der Trigger-Ausführungsparameter fortzusetzen.


Konfigurieren von Trigger-Ausführungsparametern
Trigger definieren, wann eine Pipeline ausgeführt wird. Sie enthalten auch Parameter, die an die Pipelineausführung übergeben werden. Die Vorlage DICOM-Metadatenänderungen in Delta kopieren definiert Parameter, die in der folgenden Tabelle beschrieben werden. Wenn während der Konfiguration kein Wert angegeben wird, so wird der aufgelistete Standardwert für jeden Parameter verwendet.
| Parametername | Beschreibung | Standardwert |
|---|---|---|
| BatchSize | Die maximale Anzahl von Änderungen, die gleichzeitig aus dem Änderungsfeed abgerufen werden sollen (höchstens 200) | 200 |
| ApiVersion | Die API-Version für den Azure DICOM-Dienst (mindestens 2) | 2 |
| StartTime | Die inklusive Startzeit für DICOM-Änderungen | 0001-01-01T00:00:00Z |
| EndTime | Die exklusive Endzeit für DICOM-Änderungen | 9999-12-31T23:59:59Z |
| ContainerName | Der Containername für die resultierenden Delta-Tabellen | dicom |
| InstanceTablePath | Der Pfad, der die Delta-Tabelle für DICOM-SOP-Instanzen im Container enthält | instance |
| SeriesTablePath | Der Pfad, der die Delta-Tabelle für DICOM-Datenreihen im Container enthält | series |
| StudyTablePath | Der Pfad, der die Delta-Tabelle für DICOM-Studien im Container enthält | study |
| RetentionHours | Maximale Aufbewahrung in Stunden für Daten in den Delta-Tabellen | 720 |
Geben Sie im Bereich Parameter auslösen den Wert ContainerName ein, der dem Namen des in den Voraussetzungen erstellten Speichercontainers entspricht.
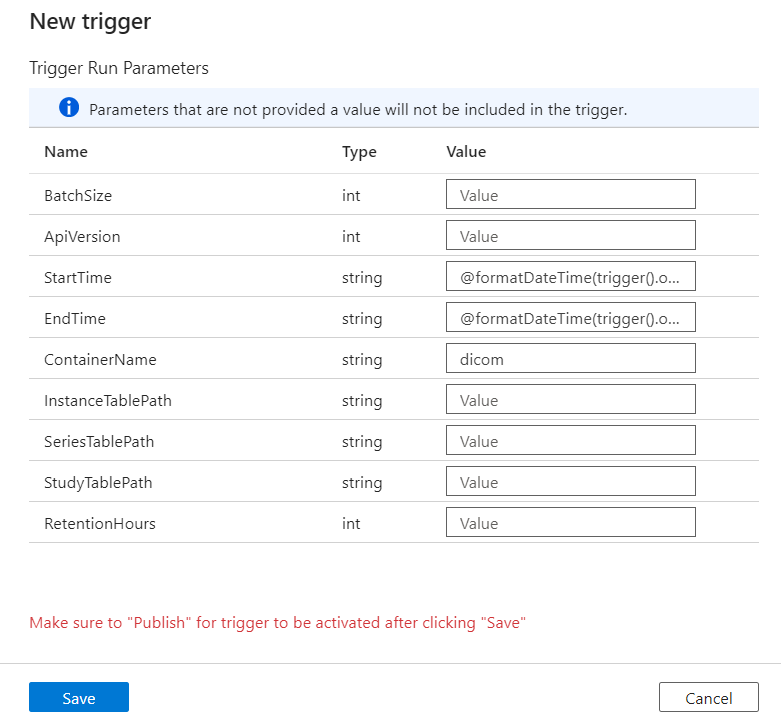
Verwenden Sie für StartTime die Systemvariable
@formatDateTime(trigger().outputs.windowStartTime).Verwenden Sie für EndTime die Systemvariable
@formatDateTime(trigger().outputs.windowEndTime).Hinweis
Nur Trigger mit rollierendem Fenster unterstützen die Systemvariablen:
@trigger().outputs.windowStartTimeund@trigger().outputs.windowEndTime.
Plantrigger verwenden unterschiedliche Systemvariablen:
@trigger().scheduledTimeund@trigger().startTime.
Weitere Informationen über Triggertypen.
Wählen Sie Speichern aus, um den neuen Trigger zu erstellen. Wählen Sie Veröffentlichen aus, um den Trigger zu starten, der im definierten Zeitplan ausgeführt wird.



Nachdem der Trigger veröffentlicht wurde, kann er mithilfe der Option Jetzt auslösen manuell ausgelöst werden. Wenn die Startzeit für einen Wert in der Vergangenheit festgelegt wurde, beginnt die Pipeline sofort.
Überwachen der Pipelineausführungen
Sie können ausgelöste Ausführungen überwachen und deren zugehörige Pipeline auf der Registerkarte Überwachen ausgeführt werden. Hier können Sie durchsuchen, wann jede Pipeline ausgeführt wurde und wie lange die Ausführung dauerte. Sie können auch potenziell Probleme debuggen, die aufgetreten sind.

Microsoft Fabric
Fabric ist eine All-in-One-Analyselösung, die sich auf Microsoft OneLake befindet. Mithilfe eines Fabric Lakehouse können Sie Daten in OneLake an einem einzigen Ort verwalten, strukturieren und analysieren. Alle Daten außerhalb von OneLake, die auf Data Lake Storage Gen2 geschrieben wurden, können mit OneLake als Verknüpfungen verbunden werden, um die Vorteile der Fabric-Toolsammlung zu nutzen.
Erstellen von Verknüpfungen mit Metadatentabellen
Gehen Sie zu dem in den Voraussetzungen erstellten Lakehouse. Wählen Sie in der Ansicht Explorer das Auslassungszeichenmenü (...) neben dem Ordner Tabellen aus.
Wählen Sie Neue Verknüpfung aus, um eine neue Verknüpfung mit dem Speicherkonto zu erstellen, das die DICOM-Analysedaten enthält.

Wählen Sie Azure Data Lake Storage Gen2 als Quelle für die Verknüpfung aus.
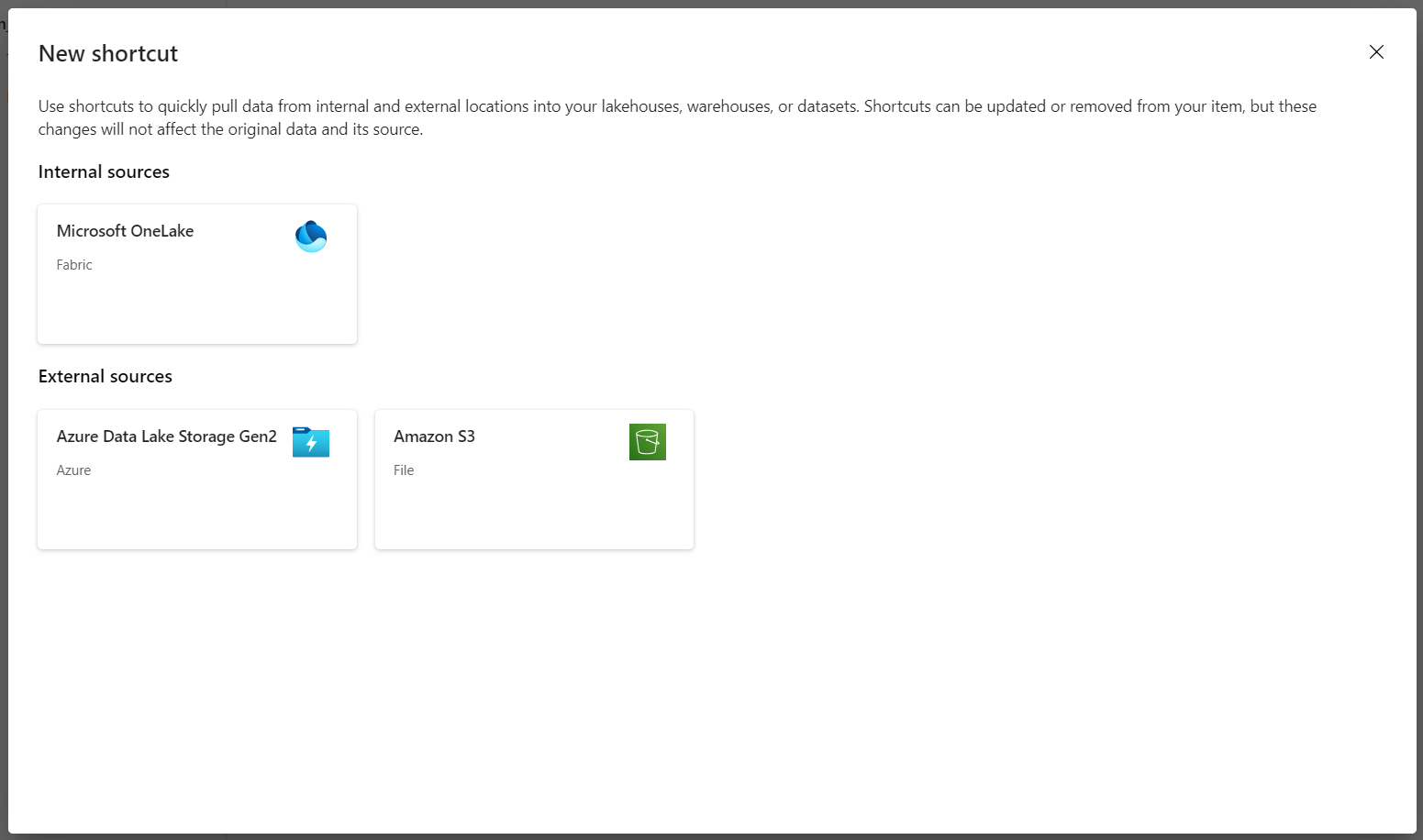
Geben Sie unter Verbindungseinstellungen die URL ein, die Sie im Abschnitt Verknüpfte Dienste verwendet haben.

Wählen Sie eine vorhandene Verbindung aus oder erstellen Sie eine neue Verbindung, indem Sie die Authentifizierungsart auswählen, die Sie verwenden möchten.
Hinweis
Es gibt einige Optionen für die Authentifizierung zwischen Data Lake Storage Gen2 und Fabric. Sie können ein Organisationskonto oder einen Dienstprinzipal verwenden. Es wird nicht empfohlen, Kontoschlüssel oder freigegebene Zugriffssignatur-Token zu verwenden.
Wählen Sie Weiter aus.
Geben Sie einen Verknüpfungsnamen ein, der die von der Data Factory-Pipeline erstellten Daten darstellt. Beispielsweise für die
instanceDelta-Tabelle sollte der Verknüpfungsname vermutlich Instanz sein.Geben Sie den Unterpfad ein, der dem
ContainerNameParameter aus der Ausführungsparameter-Konfiguration und dem Namen der Tabelle für die Verknüpfung entspricht. Verwenden Sie beispielsweise/dicom/instancefür die Delta-Tabelle mit dem Pfadinstanceimdicom-Container.Wählen Sie Erstellen aus, um die Verknüpfung zu erstellen.
Wiederholen Sie die Schritte 2 bis 9, um die verbleibenden Verknüpfungen zu den anderen Delta-Tabellen im Speicherkonto hinzuzufügen (z. B.
seriesundstudy).



Nachdem Sie die Verknüpfungen erstellt haben, erweitern Sie eine Tabelle, um die Namen und Typen der Spalten anzuzeigen.

Erstellen von Verknüpfungen mit Dateien
Wenn Sie einen DICOM-Dienst mit Data Lake Storage verwenden, können Sie zusätzlich eine Verknüpfung mit den im Data Lake gespeicherten DICOM-Dateidaten erstellen.
Gehen Sie zu dem in den Voraussetzungen erstellten Lakehouse. Wählen Sie in der Ansicht Explorer das Auslassungszeichenmenü (…) neben dem Ordner Dateien aus.
Wählen Sie Neue Verknüpfung aus, um eine neue Verknüpfung mit dem Speicherkonto zu erstellen, das die DICOM-Daten enthält.

Wählen Sie Azure Data Lake Storage Gen2 als Quelle für die Verknüpfung aus.
Geben Sie unter Verbindungseinstellungen die URL ein, die Sie im Abschnitt Verknüpfte Dienste verwendet haben.
Wählen Sie eine vorhandene Verbindung aus oder erstellen Sie eine neue Verbindung, indem Sie die Authentifizierungsart auswählen, die Sie verwenden möchten.
Wählen Sie Weiter aus.
Geben Sie einen Verknüpfungsnamen ein, der die DICOM-Daten beschreibt. Beispielsweise contoso-dicom-dateien.
Geben Sie den Unterpfad ein, der dem Namen des vom DICOM-Dienst verwendeten Speichercontainers und Ordners entspricht. Wenn Sie z. B. eine Verknüpfung mit dem Stammordner herstellen möchten, wäre der Unterpfad /dicom/AHDS. Der Stammordner ist immer
AHDS. Sie können aber optional einen Link zu einem untergeordneten Ordner für einen bestimmten Arbeitsbereich oder eine DICOM-Dienstinstanz herstellen.Wählen Sie Erstellen aus, um die Verknüpfung zu erstellen.


Ausführen von Notebooks
Nachdem die Tabellen im Lakehouse erstellt wurden, können Sie diese aus Fabric-Notebooks abfragen. Sie können Notebooks direkt von Lakehouse aus erstellen, indem Sie in der Menüleiste Notebook öffnen auswählen.
Auf der Notebook-Seite kann der Inhalt des Lakehouse auf der linken Seite angezeigt werden, einschließlich neu hinzugefügter Tabellen. Wählen Sie oben auf der Seite die Sprache für das Notebook aus. Die Sprache kann auch für einzelne Zellen konfiguriert werden. Im folgenden Beispiel wird Spark SQL verwendet.
Abfragen von Tabellen mithilfe von Spark SQL
Geben Sie im Zell-Editor eine Spark SQL-Abfrage wie eine SELECT-Anweisung ein.
SELECT * from instance
Diese Abfrage wählt alle Inhalte aus der instance-Tabelle aus. Wenn Sie fertig sind, wählen Sie Zelle ausführen aus, um die Abfrage auszuführen.

Nach ein paar Sekunden werden die Ergebnisse der Abfrage in einer Tabelle unterhalb der Zelle angezeigt, wie im folgenden Beispiel. Es kann länger dauern, wenn diese Spark-Abfrage der erste in der Sitzung ist, da der Spark-Kontext initialisiert werden muss.

Zugriff auf DICOM-Dateidaten in Notebooks
Wenn Sie eine Vorlage verwendet haben, um die Pipeline zu erstellen und eine Verknüpfung mit den DICOM-Dateidaten zu erstellen, können Sie die Spalte filePath in der Tabelle instance verwenden, um Instanzmetadaten mit den Dateidaten zu korrelieren.
SELECT sopInstanceUid, filePath from instance

Zusammenfassung
In diesem Artikel haben Sie Folgendes gelernt:
- Verwenden Sie Data Factory-Vorlagen, um eine Pipeline vom DICOM-Dienst zu einem Data Lake Storage Gen2-Konto zu erstellen.
- Konfigurieren Sie einen Trigger, um DICOM-Metadaten nach einem stündlichen Zeitplan zu extrahieren.
- Verwenden Sie Verknüpfungen, um DICOM-Daten in einem Speicherkonto mit einem Fabric Lakehouse zu verbinden.
- Verwenden Sie Notebooks um DICOM-Daten im Lakehouse abzufragen.
Nächste Schritte
Hinweis
DICOM® ist die eingetragene Marke des National Electrical Manufacturers Association für seine Standards-Publikationen über die digitale Kommunikation medizinischer Informationen.