Verwalten von Ressourcen für den Apache Spark-Cluster unter Azure HDInsight
Erfahren Sie, wie Sie auf die mit Ihrem Apache Spark-Cluster verknüpften Benutzeroberflächen wie die Apache Ambari-Benutzeroberfläche, die Apache Hadoop YARN-Benutzeroberfläche und den Spark-Verlaufsserver zugreifen, und wie Sie den Cluster für optimale Leistung konfigurieren.
Öffnen des Spark-Verlaufsservers
Der Spark-Verlaufsserver ist die Webbenutzeroberfläche für abgeschlossene und ausgeführte Spark-Anwendungen. Er stellt eine Erweiterung der Webbenutzeroberfläche von Spark dar. Ausführliche Informationen finden Sie unter Spark-Verlaufsserver.
Öffnen der YARN-Benutzeroberfläche
Auf der YARN-Benutzeroberfläche können Anwendungen überwachen, die derzeit auf dem Spark-Cluster ausgeführt werden.
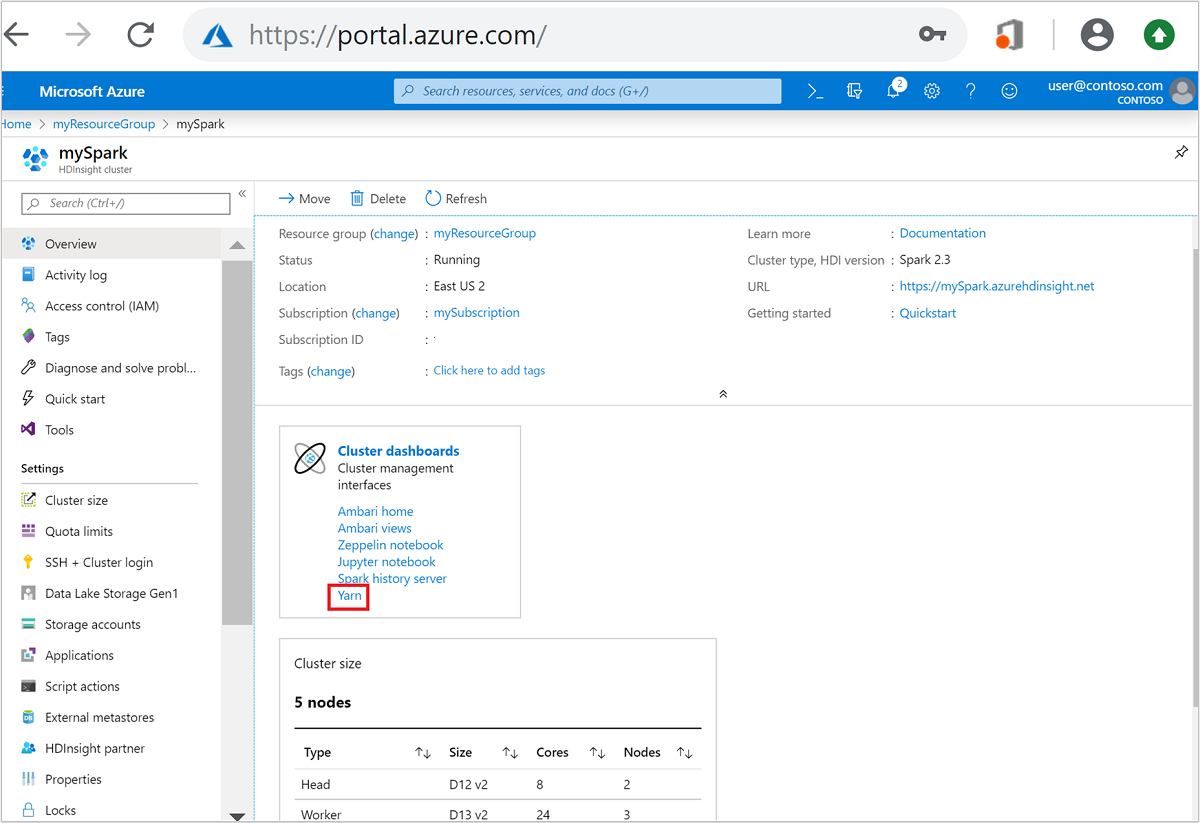
Öffnen Sie im Azure-Portal den Spark-Cluster. Weitere Informationen finden Sie unter Auflisten und Anzeigen von Clustern.
Wählen Sie unter Cluster-Dashboards die Option YARN aus. Geben Sie bei Aufforderung die Anmeldeinformationen für den Spark-Cluster ein.
Tipp
Alternativ können Sie die YARN-Benutzeroberfläche auch über die Ambari-Benutzeroberfläche starten. Navigieren Sie auf der Ambari-Benutzeroberfläche zu YARN>Quicklinks>Aktiv>Resource Manager UI (Benutzeroberfläche des Ressourcen-Managers).
Optimieren von Clustern für Spark-Anwendungen
Die drei wichtigsten Parameter, die je nach Anwendungsanforderungen für die Spark-Konfiguration verwendet werden können, sind spark.executor.instances, spark.executor.cores und spark.executor.memory. Ein Executor ist ein Prozess, der für eine Spark-Anwendung gestartet wird. Er wird auf dem Workerknoten ausgeführt und ist für die Ausführung der Aufgaben für die Anwendung zuständig. Die Standardanzahl von Executors und die Executorgrößen für jeden Cluster werden basierend auf der Anzahl von Workerknoten und der Größe der Workerknoten berechnet. Diese Informationen werden in spark-defaults.conf in den Clusterhauptknoten gespeichert.
Die drei Konfigurationsparameter können auf Clusterebene (für alle Anwendungen, die im Cluster ausgeführt werden) konfiguriert werden oder für jede einzelne Anwendung angegeben werden.
Ändern der Parameter mit der Ambari-Benutzeroberfläche
Navigieren Sie auf der Ambari-Benutzeroberfläche zu Spark 2>Konfigurationen>Benutzerdefinierte Spark2-Standards.
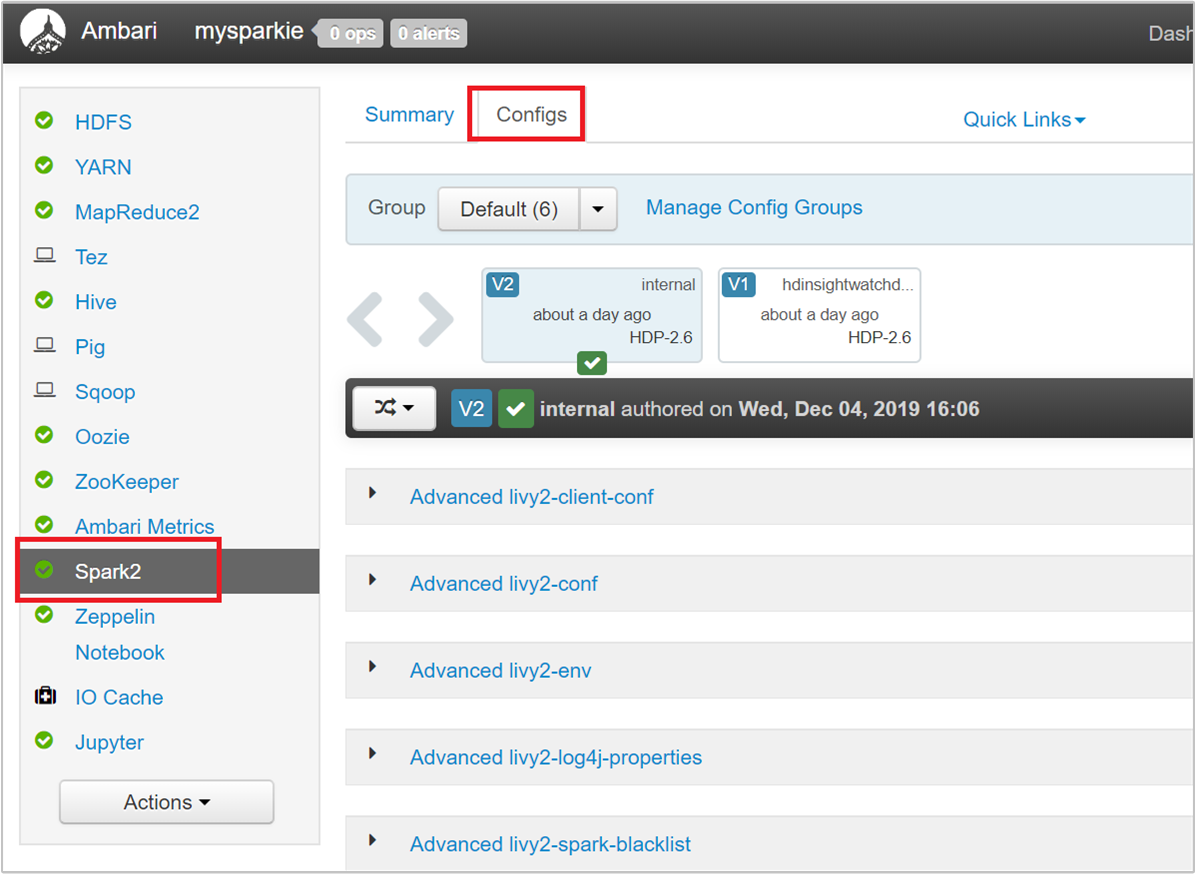
Die Standardwerte sind gut geeignet, um vier Spark-Anwendungen gleichzeitig im Cluster auszuführen. Sie können diese Werte über die Benutzeroberfläche ändern, wie im folgenden Screenshot dargestellt wird:
Wählen Sie Speichern aus, um die Änderungen an der Konfiguration zu speichern. Oben auf der Seite werden Sie aufgefordert, alle betroffenen Dienste neu zu starten. Wählen Sie Neu starten aus.
Ändern der Parameter für eine Anwendung, die im Jupyter Notebook ausgeführt wird
Für Anwendungen, die im Jupyter Notebook ausgeführt werden, können Sie die %%configure-Magic für Konfigurationsänderungen verwenden. Im Idealfall nehmen Sie diese Änderungen am Anfang der Anwendung vor, bevor Sie die erste Codezelle ausführen. Dadurch wird sichergestellt, dass die Konfiguration auf die Livy-Sitzung angewendet wird, wenn sie erstellt wird. Wenn Sie die Konfiguration zu einem späteren Zeitpunkt in der Anwendung ändern möchten, müssen Sie den Parameter -f verwenden. Allerdings geht dadurch der gesamte Status in der Anwendung verloren.
Der folgende Ausschnitt zeigt, wie die Konfiguration für eine in Jupyter ausgeführte Anwendung geändert wird.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Konfigurationsparameter müssen als JSON-Zeichenfolge übergeben werden und in der nächsten Zeile nach dem Magic-Befehl stehen, wie in der Beispielspalte gezeigt.
Ändern der Parameter für eine Anwendung, die mit „spark-submit“ übermittelt wird
Der folgende Befehl ist ein Beispiel dafür, wie die Konfigurationsparameter für eine Batchanwendung geändert werden, die mithilfe von spark-submitübermittelt wird.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
Ändern der Parameter für eine Anwendung, die mit „cURL“ übermittelt wird
Der folgende Befehl ist ein Beispiel dafür, wie die Konfigurationsparameter für eine Batchanwendung geändert werden, die mithilfe von „cURL“ übermittelt wird.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Hinweis
Kopieren Sie die JAR-Datei in das Speicherkonto Ihres Clusters. Kopieren Sie die JAR-Datei nicht direkt auf den Hauptknoten.
Ändern dieser Parameter auf einem Spark Thrift-Server
Der Spark Thrift-Server bietet JDBC/ODBC-Zugriff auf einen Spark-Cluster und wird verwendet, um Spark-SQL-Abfragen zu verarbeiten. Tools wie Power BI, Tableau usw. verwenden das ODBC-Protokoll zur Kommunikation mit dem Spark Thrift-Server, um Spark-SQL-Abfragen als Spark-Anwendung auszuführen. Wenn ein Spark-Cluster erstellt wird, werden zwei Instanzen des Spark Thrift-Servers gestartet, eine auf jedem Hauptknoten. Jeder Spark Thrift-Server wird als Spark-Anwendung auf der YARN-Benutzeroberfläche angezeigt.
Der Spark Thrift-Server nutzt die dynamische Executorzuordnung in Spark, und somit wird spark.executor.instances nicht verwendet. Der Spark Thrift-Server verwendet stattdessen spark.dynamicAllocation.maxExecutors und spark.dynamicAllocation.minExecutors, um die Executoranzahl anzugeben. Die Konfigurationsparameter spark.executor.cores und spark.executor.memory werden verwendet, um die Executorgröße zu ändern. Sie können diese Parameter ändern, wie in den folgenden Schritten dargestellt:
Erweitern Sie die Kategorie Advanced spark2-thrift-sparkconf, um die Parameter
spark.dynamicAllocation.maxExecutorsundspark.dynamicAllocation.minExecutorszu aktualisieren.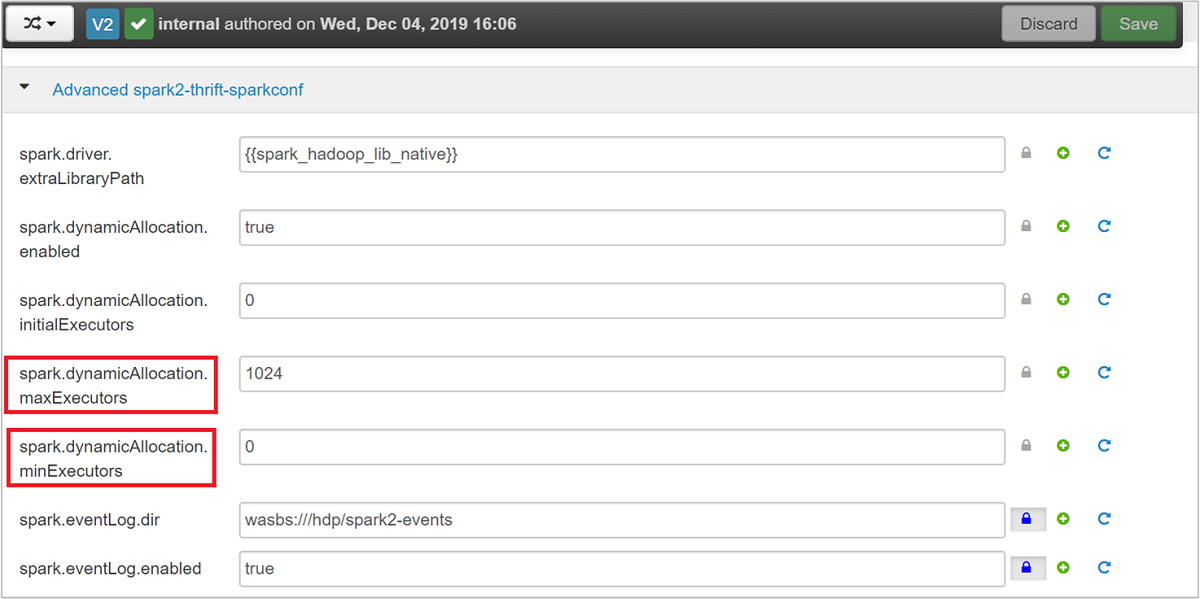
Erweitern Sie die Kategorie Custom spark2-thrift-sparkconf, um die Parameter
spark.executor.coresundspark.executor.memoryzu aktualisieren.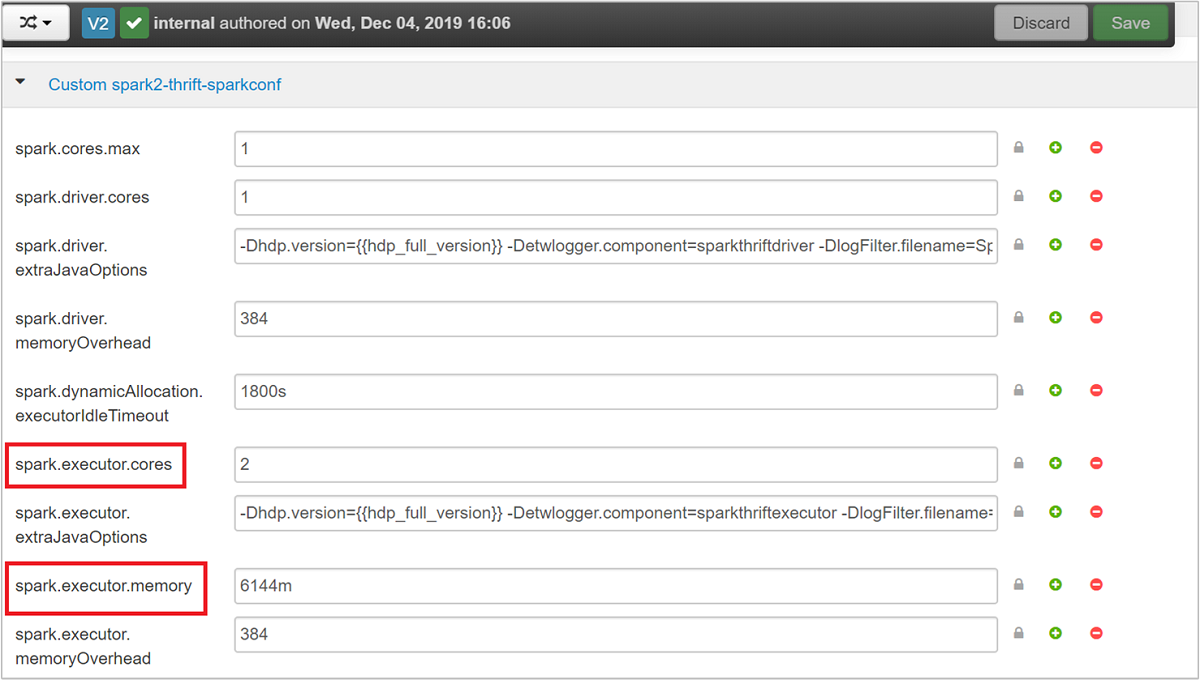
Ändern des Treiberspeichers des Spark Thrift-Servers
Der Treiberspeicher des Spark Thrift-Servers ist so konfiguriert, dass er 25 % der RAM-Größe des Hauptknotens umfasst, vorausgesetzt, dass die RAM-Gesamtgröße des Hauptknotens über 14 GB liegt. Sie können mit der Ambari-Benutzeroberfläche die Treiberspeicherkonfiguration ändern, wie im folgenden Screenshot dargestellt wird:
Navigieren Sie auf der Ambari-Benutzeroberfläche zu Spark2>Configs (Konfigurationen)>Advanced spark2-env. Geben Sie dann den Wert für spark_thrift_cmd_opts an.
Freigeben von Spark-Clusterressourcen
Da die dynamische Zuteilung von Spark verwendet wird, werden nur die Ressourcen für die beiden Anwendungsmaster vom Thrift-Server genutzt. Um diese Ressourcen freizugeben, müssen Sie die im Cluster ausgeführten Dienste des Thrift-Servers beenden.
Wählen Sie auf der Ambari-Benutzeroberfläche im linken Bereich Spark2 aus.
Wählen Sie auf der nächsten Seite Spark 2-Thrift-Server aus.
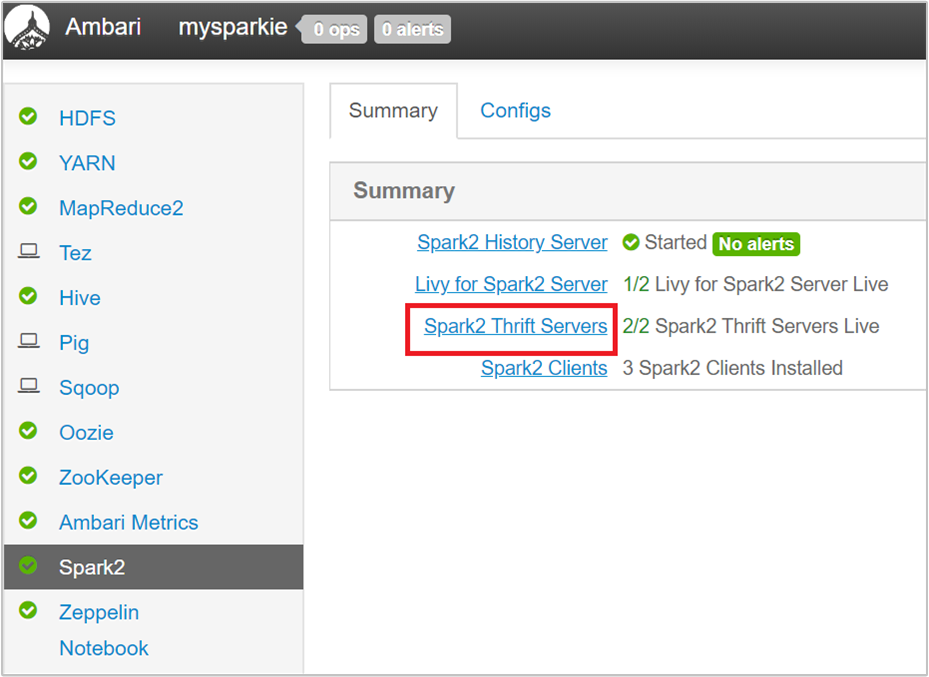
Sie sollte zwei Hauptknoten sehen, auf denen der Spark 2-Thrift-Server ausgeführt wird. Wählen Sie einen der Hauptknoten aus.
Auf der nächsten Seite werden alle auf diesem Hauptknoten ausgeführten Dienste aufgeführt. Wählen Sie in der Liste neben „Spark 2-Thrift-Server“ die Dropdownschaltfläche und dann Beenden aus.
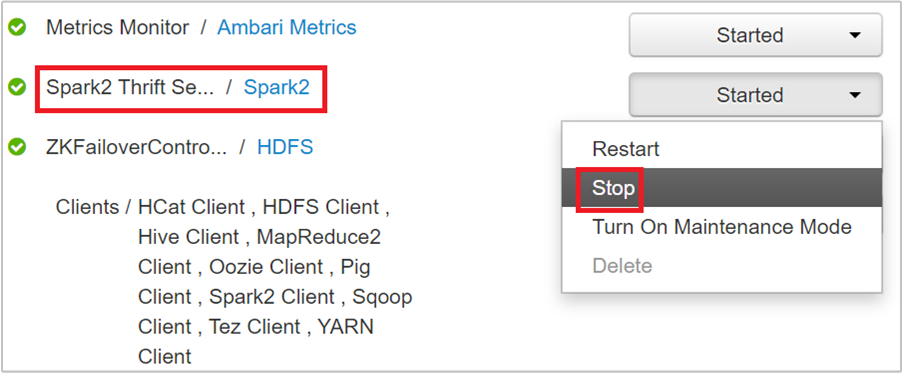
Wiederholen Sie diese Schritte auch auf dem anderen Hauptknoten.
Neustarten des Jupyter-Diensts
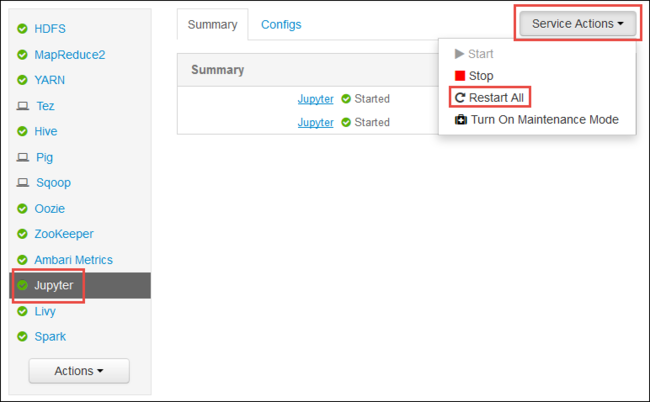
Starten Sie die Ambari-Webbenutzeroberfläche, wie am Anfang des Artikels beschrieben wird. Wählen Sie im linken Navigationsbereich Jupyter, Dienstaktionen und dann Alle neu starten aus. Dadurch wird der Jupyter-Dienst auf allen Hauptknoten gestartet.
Überwachen von Ressourcen
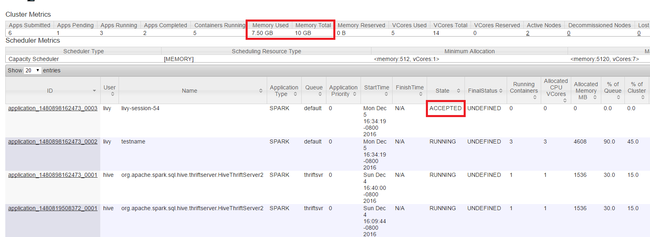
Starten Sie die YARN-Benutzeroberfläche, wie am Anfang des Artikels beschrieben wird. Überprüfen Sie im oberen Bildschirmbereich in der Tabelle mit den Clustermetriken die Werte in den Spalten Memory Used (Verwendeter Arbeitsspeicher) und Memory Total (Arbeitsspeicher gesamt). Wenn die beiden Werte dicht beieinander liegen, sind unter Umständen nicht genügend Ressourcen für den Start der nächsten Anwendung vorhanden. Gleiches gilt für die Spalten VCores Used (Verwendete virtuelle Kerne) und VCores Total (Virtuelle Kerne gesamt). Falls in der Hauptansicht eine Anwendung mit dem Zustand AKZEPTIERT nicht in den Zustand RUNNING (AUSGEFÜHRT) oder FEHLER übergeht, kann dies ebenfalls ein Hinweis darauf sein, dass nicht genügend Ressourcen zum Starten der Anwendung zur Verfügung stehen.
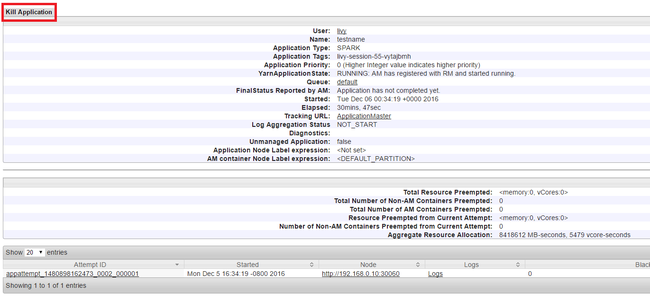
Beenden der Anwendungsausführung
Wählen Sie im linken Bereich der Benutzeroberfläche von YARN Running (Ausgeführt) aus. Suchen Sie in der Liste mit den ausgeführten Anwendungen nach der Anwendung, die Sie beenden möchten, und wählen Sie die ID aus.
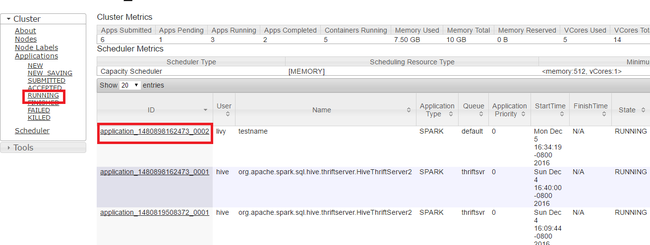
Wählen Sie rechts oben Kill Application (Anwendung beenden) und anschließend OK aus.
Weitere Informationen
Für Datenanalysten
- Apache Spark mit Machine Learning: Analysieren von Gebäudetemperaturen mithilfe von Spark in HDInsight und HVAC-Daten
- Apache Spark mit Machine Learning: Vorhersage von Lebensmittelkontrollergebnissen mithilfe von Spark in HDInsight
- Websiteprotokollanalyse mithilfe von Apache Spark in HDInsight
- Analysieren von Application Insights-Telemetriedaten mit Apache Spark in HDInsight
Für Apache Spark-Entwickler
- Erstellen einer eigenständigen Anwendung mit Scala
- Ausführen von Remoteaufträgen in einem Apache Spark-Cluster mithilfe von Apache Livy
- Verwenden des HDInsight-Tools-Plug-Ins für IntelliJ IDEA zum Erstellen und Übermitteln von Spark Scala-Anwendungen
- Verwenden des HDInsight-Tools-Plug-Ins für IntelliJ IDEA zum Remotedebuggen von Apache Spark-Anwendungen
- Verwenden von Apache Zeppelin Notebooks mit einem Apache Spark-Cluster unter HDInsight
- Kernel für Jupyter Notebook in Apache Spark-Clustern für HDInsight
- Verwenden von externen Paketen mit Jupyter Notebooks
- Installieren von Jupyter Notebook auf Ihrem Computer und Herstellen einer Verbindung zum Apache Spark-Cluster in Azure HDInsight (Vorschau)