Analysieren von Application Insights-Telemetrieprotokollen mit Apache Spark in HDInsight
Erfahren Sie, wie Sie mit Apache Spark in HDInsight Telemetriedaten von Application Insight analysieren können.
Visual Studio Application Insights ist ein Analysedienst, der Ihre Webanwendungen überwacht. Von Application Insights generierte Telemetriedaten können nach Azure Storage exportiert werden. Sobald sich die Daten in Azure Storage befinden, können sie mit HDInsight analysiert werden.
Voraussetzungen
Eine Anwendung, die zur Verwendung von Application Insights konfiguriert ist.
Sie müssen mit der Erstellung eines Linux-basierten HDInsight-Clusters vertraut sein. Weitere Informationen finden Sie unter Erste Schritte: Erstellen von Apache Spark auf HDInsight.
Ein Webbrowser.
Für Entwicklung und Test dieses Dokuments wurden die folgenden Ressourcen eingesetzt:
Die Application Insights-Telemetriedaten wurden mit einer Node.js-Web-App generiert, die zur Verwendung von Application Insights konfiguriert wurde.
Zur Analyse der Daten wurde ein Linux-basierter Spark in HDInsight-Cluster der Version 3.5 verwendet.
Architektur und Planung
Das folgende Diagramm zeigt die grundlegende Dienstarchitektur für dieses Beispiel:
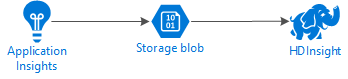
Azure Storage
Application Insights kann für den fortlaufenden Export von Telemetriedaten in Blobs konfiguriert werden. HDInsight kann dann in den Blobs gespeicherte Daten lesen. Es gelten jedoch einige Anforderungen, die erfüllt werden müssen:
Speicherort: Wenn das Speicherkonto und HDInsight sich an verschiedenen Standorten befinden, kann dies die Latenz erhöhen. Gleichzeitig steigen die Kosten, da beim Verschieben von Daten zwischen Regionen Ausgangsgebühren anfallen.
Warnung
Die Verwendung eines Speicherkontos an einem anderen Speicherort als HDInsight wird nicht unterstützt.
Blobtyp: HDInsight unterstützt nur Blockblobs. Application Insights verwendet standardmäßig Blockblobs, deshalb sollten Sie standardmäßig mit HDInsight arbeiten.
Informationen zum Hinzufügen von Speicher zu einem vorhandenen Cluster finden Sie im Dokument Hinzufügen zusätzlicher Speicherkonten.
Datenschema
Application Insights bietet Informationen zum Exportdatenmodell für das Telemetriedatenformat, das in Blobs exportiert wird. In diesem Dokument wird Spark SQL für die Arbeit mit den Daten verwendet. Spark SQL kann automatisch ein Schema für die von Application Insights protokollierte JSON-Datenstruktur generieren.
Exportieren von Telemetriedaten
Führen Sie die Schritte unter Einrichten des fortlaufenden Exports aus, um Application Insights für den Export von Telemetriedaten in einen Azure-Speicherblob zu konfigurieren.
Konfigurieren von HDInsight für den Datenzugriff
Wenn Sie einen HDInsight-Cluster erstellen, fügen Sie das Speicherkonto während der Clustererstellung hinzu.
Verwenden Sie zum Hinzufügen des Azure-Speicherkontos zu einem vorhandenen Cluster die Informationen im Dokument Hinzufügen zusätzlicher Speicherkonten.
Analysieren der Daten: PySpark
Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net/jupyter, wobei CLUSTERNAME der Name Ihres Clusters ist.Wählen Sie oben rechts auf der Jupyter-Seite Neu und anschließend PySpark aus. Eine neue Browserregisterkarte wird geöffnet, die ein Python-basiertes Jupyter Notebook enthält.
Geben Sie in das erste (als Zelle bezeichnete) Feld auf der Seite folgenden Text ein:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Dieser Code konfiguriert Spark für den rekursiven Zugriff auf die Verzeichnisstruktur für die Eingabedaten. Die Application Insights-Telemetriedaten werden in einer Verzeichnisstruktur protokolliert, die
/{telemetry type}/YYYY-MM-DD/{##}/ähnelt.Verwenden Sie UMSCHALT+EINGABE, um den Code auszuführen. Auf der linken Seite der Zelle wird ein „*“ in Klammern angezeigt. Dies weist darauf hin, dass der Code in dieser Zelle ausgeführt wird. Nach Abschluss der Ausführung wird „*“ in eine Zahl geändert, und eine Ausgabe, die dem folgenden Text ähnelt, wird unterhalb der Zelle angezeigt:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Unterhalb der ersten Zelle wird eine neu erstellte Zelle angezeigt. Geben Sie den folgenden Text in die neue Zelle ein. Ersetzen Sie
CONTAINERundSTORAGEACCOUNTdurch den Namen des Azure-Speicherkontos und des BLOB-Containers, der Application Insights-Daten enthält.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Verwenden Sie UMSCHALT+EINGABETASTE, um diese Zelle auszuführen. Ein Ergebnis ähnlich dem folgenden Text wird angezeigt:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Der zurückgegebene WASB-Pfad ist der Speicherort der Application Insights-Telemetriedaten. Ändern Sie die Zeile
hdfs dfs -lsin der Zelle so ab, dass der zurückgegebene WASB-Pfad verwendet wird, und führen Sie dann über UMSCHALT+EINGABE die Zelle erneut aus. Jetzt sollten die Ergebnisse die Verzeichnisse anzeigen, die Telemetriedaten enthalten.Hinweis
Für die verbleibenden Schritte in diesem Abschnitt wurde das Verzeichnis
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestsverwendet. Ihre Verzeichnisstruktur kann anders sein.Geben Sie in der nächsten Zelle den folgenden Code ein: Ersetzen Sie
WASB_PATHdurch den Pfad aus dem vorherigen Schritt.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Dieser Code erstellt einen Datenrahmen aus den JSON-Dateien, die über den fortlaufenden Exportprozess exportiert wurden. Verwenden Sie UMSCHALT+EINGABETASTE, um diese Zelle auszuführen.
Geben Sie in der nächsten Zelle Folgendes ein, und führen Sie die Zelle aus, um das Schema anzuzeigen, das Spark für die JSON-Dateien erstellt hat:
jsonData.printSchema()Das Schema ist für die verschiedenen Telemetriedatentypen unterschiedlich. Das nachfolgende Beispiel ist das Schema, das für Webanforderungen generiert wird (Daten sind im Unterverzeichnis
Requestsgespeichert):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Verwenden Sie den folgenden Code, um den Datenrahmen als temporäre Tabelle zu registrieren und eine Abfrage für die Daten auszuführen:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()Über diese Abfrage werden Informationen zur Stadt für die ersten 20 Datensätze zurückgegeben, bei denen „context.location.city“ nicht NULL ist.
Hinweis
Die context-Struktur ist in allen von Application Insights generierten Telemetriedaten vorhanden. Das city-Element wurde in Ihren Protokolle möglicherweise nicht gefüllt. Verwenden Sie das Schema, um weitere abfragbare Elemente zu identifizieren, die für Ihre Protokolle möglicherweise Daten enthalten.
Die Abfrage gibt Informationen zurück, die folgendem Text ähneln:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Analysieren der Daten: Scala
Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net/jupyter, wobei CLUSTERNAME der Name Ihres Clusters ist.Wählen Sie oben rechts auf der Jupyter-Seite Neu und anschließend Scala aus. Eine neue Browserregisterkarte, die ein Scala-basiertes Jupyter-Notebook enthält, wird angezeigt.
Geben Sie in das erste (als Zelle bezeichnete) Feld auf der Seite folgenden Text ein:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Dieser Code konfiguriert Spark für den rekursiven Zugriff auf die Verzeichnisstruktur für die Eingabedaten. Die Application Insights-Telemetriedaten werden in einer Verzeichnisstruktur protokolliert, die
/{telemetry type}/YYYY-MM-DD/{##}/ähnelt.Verwenden Sie UMSCHALT+EINGABE, um den Code auszuführen. Auf der linken Seite der Zelle wird ein „*“ in Klammern angezeigt. Dies weist darauf hin, dass der Code in dieser Zelle ausgeführt wird. Nach Abschluss der Ausführung wird „*“ in eine Zahl geändert, und eine Ausgabe, die dem folgenden Text ähnelt, wird unterhalb der Zelle angezeigt:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Unterhalb der ersten Zelle wird eine neu erstellte Zelle angezeigt. Geben Sie den folgenden Text in die neue Zelle ein. Ersetzen Sie
CONTAINERundSTORAGEACCOUNTdurch den Namen des Azure-Speicherkontos und des BLOB-Containers, der Application Insights-Protokolle enthält.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Verwenden Sie UMSCHALT+EINGABETASTE, um diese Zelle auszuführen. Ein Ergebnis ähnlich dem folgenden Text wird angezeigt:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Der zurückgegebene WASB-Pfad ist der Speicherort der Application Insights-Telemetriedaten. Ändern Sie die Zeile
hdfs dfs -lsin der Zelle so ab, dass der zurückgegebene WASB-Pfad verwendet wird, und führen Sie dann über UMSCHALT+EINGABE die Zelle erneut aus. Jetzt sollten die Ergebnisse die Verzeichnisse anzeigen, die Telemetriedaten enthalten.Hinweis
Für die verbleibenden Schritte in diesem Abschnitt wurde das Verzeichnis
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestsverwendet. Dieses Verzeichnis ist nur vorhanden, wenn Ihre Telemetriedaten aus einer Web-App stammen.Geben Sie in der nächsten Zelle den folgenden Code ein: Ersetzen Sie
WASB\_PATHdurch den Pfad aus dem vorherigen Schritt.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Dieser Code erstellt einen Datenrahmen aus den JSON-Dateien, die über den fortlaufenden Exportprozess exportiert wurden. Verwenden Sie UMSCHALT+EINGABETASTE, um diese Zelle auszuführen.
Geben Sie in der nächsten Zelle Folgendes ein, und führen Sie die Zelle aus, um das Schema anzuzeigen, das Spark für die JSON-Dateien erstellt hat:
jsonData.printSchemaDas Schema ist für die verschiedenen Telemetriedatentypen unterschiedlich. Das nachfolgende Beispiel ist das Schema, das für Webanforderungen generiert wird (Daten sind im Unterverzeichnis
Requestsgespeichert):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Verwenden Sie den folgenden Code, um den Datenrahmen als temporäre Tabelle zu registrieren und eine Abfrage für die Daten auszuführen:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()Über diese Abfrage werden Informationen zur Stadt für die ersten 20 Datensätze zurückgegeben, bei denen „context.location.city“ nicht NULL ist.
Hinweis
Die context-Struktur ist in allen von Application Insights generierten Telemetriedaten vorhanden. Das city-Element wurde in Ihren Protokolle möglicherweise nicht gefüllt. Verwenden Sie das Schema, um weitere abfragbare Elemente zu identifizieren, die für Ihre Protokolle möglicherweise Daten enthalten.
Die Abfrage gibt Informationen zurück, die folgendem Text ähneln:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Nächste Schritte
Weitere Beispiele zur Verwendung von Apache Spark für die Arbeit mit Daten und Diensten in Azure finden Sie in den folgenden Dokumenten:
- Apache Spark mit BI: Durchführen interaktiver Datenanalysen mithilfe von Spark in HDInsight mit BI-Tools
- Apache Spark mit Machine Learning: Analysieren von Gebäudetemperaturen mithilfe von Spark in HDInsight und HVAC-Daten
- Apache Spark mit Machine Learning: Vorhersage von Lebensmittelkontrollergebnissen mithilfe von Spark in HDInsight
- Websiteprotokollanalyse mithilfe von Apache Spark in HDInsight
Informationen zum Erstellen und Ausführen von Spark-Anwendungen finden Sie in den folgenden Dokumenten: