Verwenden der erweiterten Features des Apache Spark-Verlaufsservers zum Debuggen und Diagnostizieren von Spark-Anwendungen
In diesem Artikel erfahren Sie, wie Sie die erweiterten Features des Apache Spark-Verlaufsservers verwenden, um abgeschlossene oder ausgeführte Spark-Anwendungen zu debuggen und zu diagnostizieren. Die Erweiterung umfasst folgende Registerkarten: Daten, Graph und Diagnose. Auf der Registerkarte Daten können Sie die Eingabe- und Ausgabedaten des Spark-Auftrags überprüfen. Auf der Registerkarte Graph können Sie den Datenfluss überprüfen und den Auftragsgraph wiedergeben. Auf der Registerkarte Diagnose finden Sie die Features Datenschiefe, Zeitabweichung und Executor Usage Analysis (Analyse zur Executorauslastung).
Zugreifen auf den Spark-Verlaufsserver
Der Spark-Verlaufsserver ist die Webbenutzeroberfläche für abgeschlossene und ausgeführte Spark-Anwendungen. Sie können ihn entweder über das Azure-Portal oder über eine URL aufrufen.
Öffnen der Webbenutzeroberfläche des Spark-Verlaufsservers über das Azure-Portal
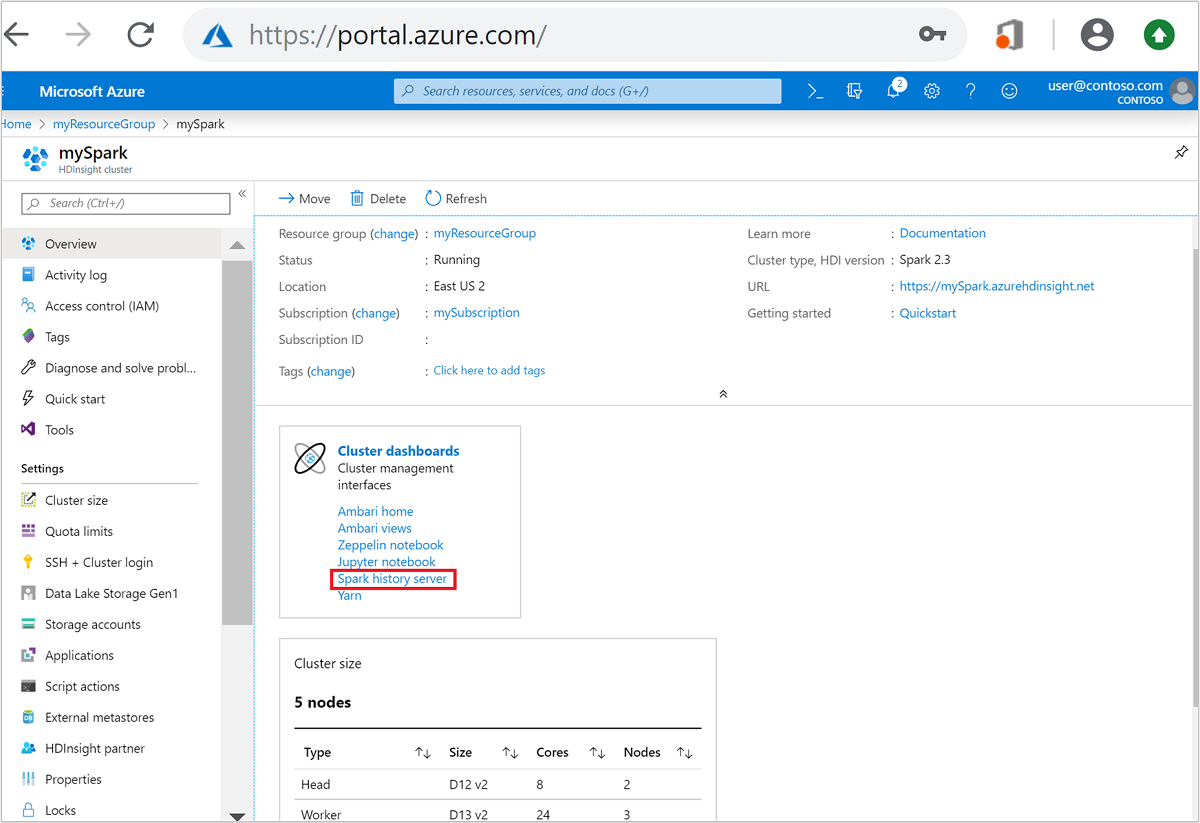
Öffnen Sie im Azure-Portal den Spark-Cluster. Weitere Informationen finden Sie unter Auflisten und Anzeigen von Clustern.
Wählen Sie unter Cluster-Dashboards die Option Spark-Verlaufsserver aus. Geben Sie bei Aufforderung die Anmeldeinformationen für den Spark-Cluster ein.
 border="true":::
border="true":::
Öffnen der Webbenutzeroberfläche des Spark-Verlaufsservers über eine URL
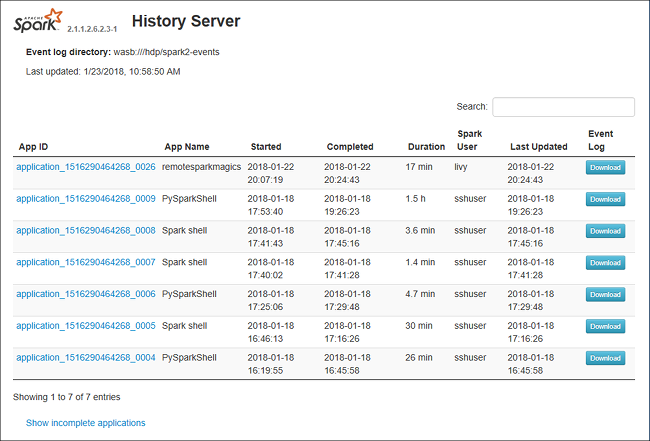
Öffnen Sie den Spark-Verlaufsserver, indem Sie zu https://CLUSTERNAME.azurehdinsight.net/sparkhistory navigieren. Dabei entspricht CLUSTERNAME dem Namen Ihres Spark-Clusters.
Die Webbenutzeroberfläche des Spark-Verlaufsservers ähnelt der folgenden Abbildung:
Verwenden der Registerkarte „Daten“ des Spark-Verlaufsservers
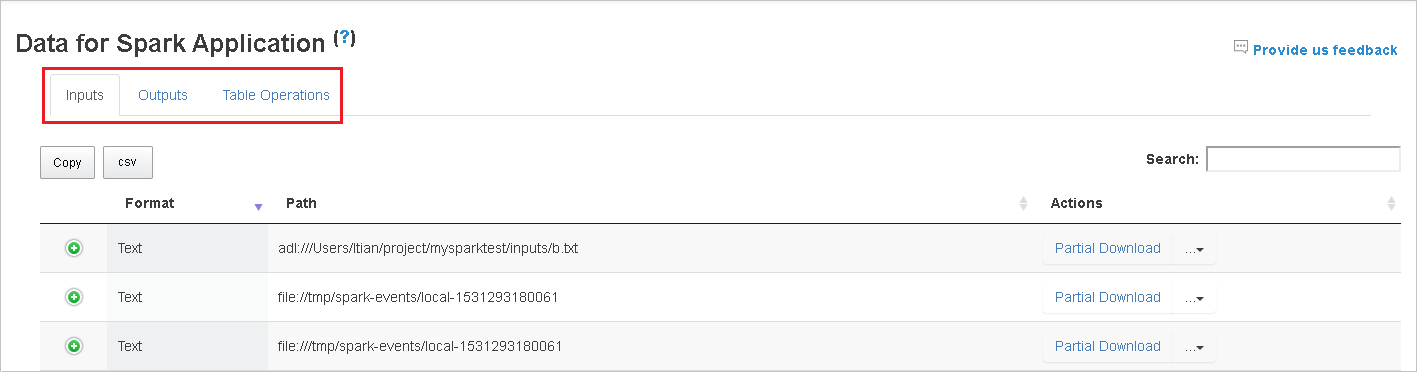
Wählen Sie die Auftrags-ID aus, und klicken Sie dann im Toolmenü auf Daten, um die Datenansicht anzuzeigen.
Überprüfen Sie die Eingaben, Ausgaben und Tabellenvorgänge, indem Sie die jeweiligen Registerkarten auswählen.
Kopieren Sie alle Zeilen, indem Sie auf Kopieren klicken.
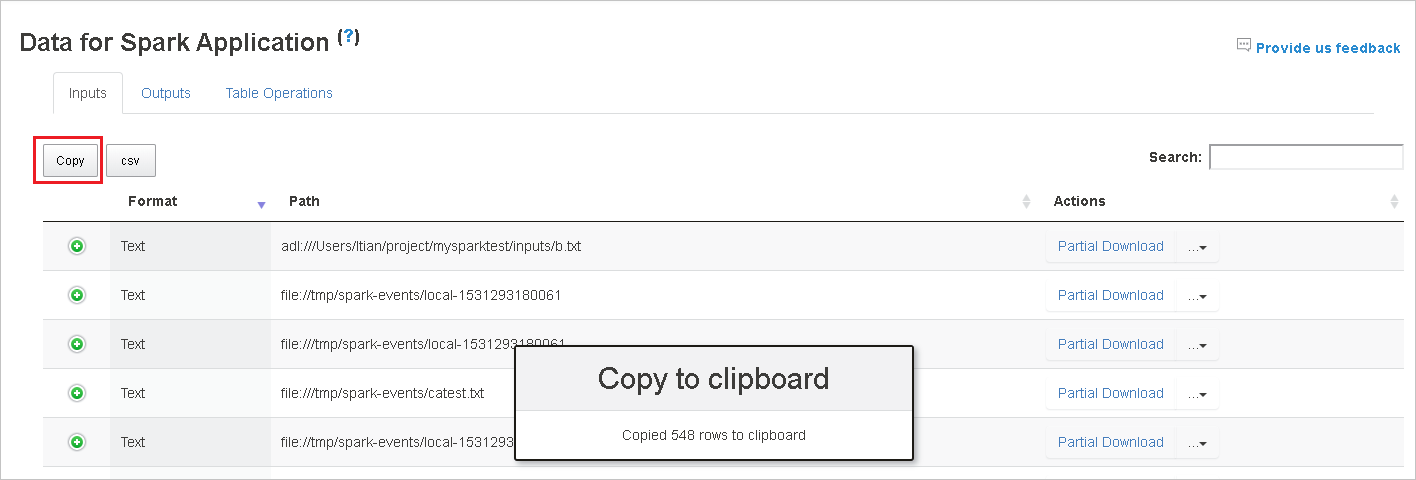
Speichern Sie alle Daten als eine CSV-Datei, indem Sie auf die CSV-Schaltfläche klicken.
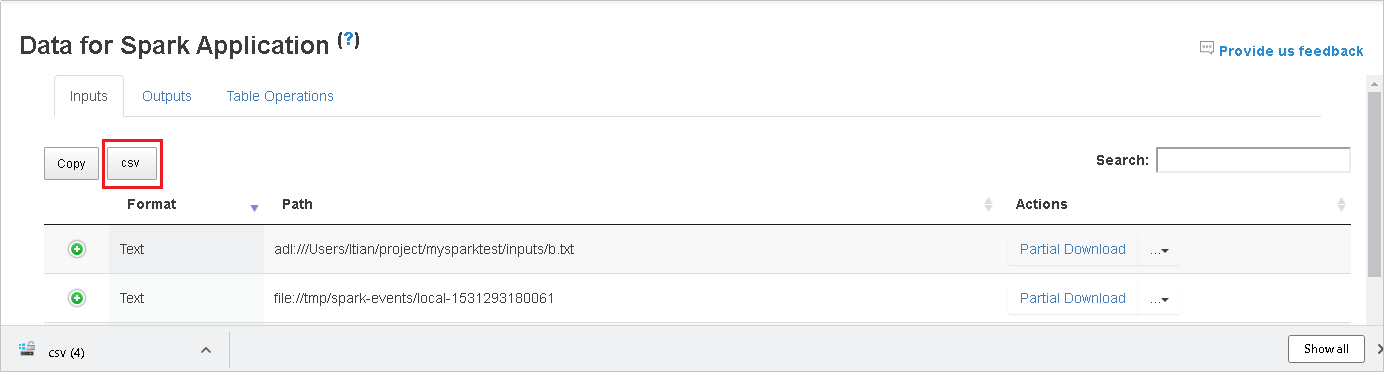
Durchsuchen Sie die Daten, indem Sie Schlüsselwörter in das Feld Suche eingeben. Die Suchergebnisse werden sofort angezeigt.
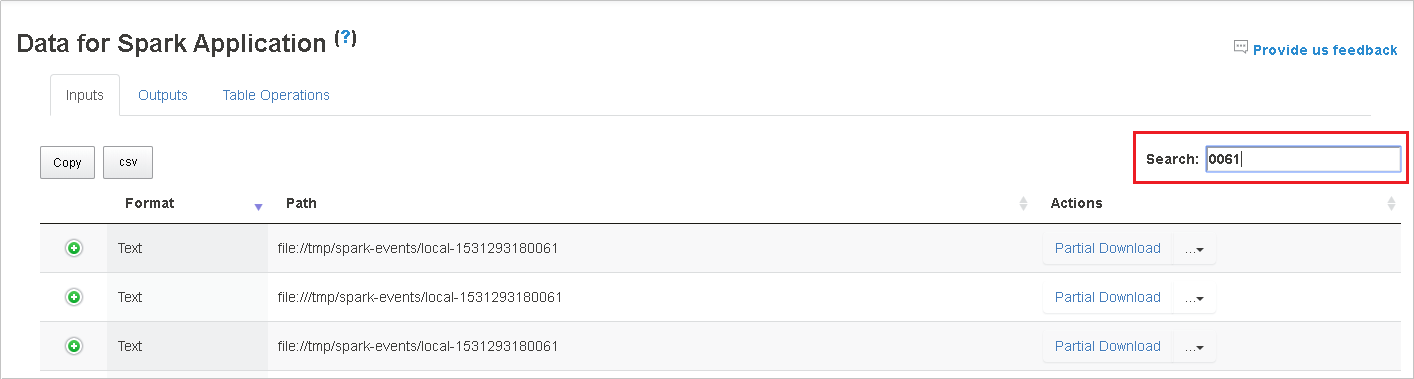
Klicken Sie auf die Spaltenüberschrift, um die Tabelle zu sortieren. Klicken Sie auf das Pluszeichen, um eine Zeile zu erweitern und somit weitere Details anzuzeigen. Klicken Sie auf das Minuszeichen, um eine Zeile zu reduzieren.
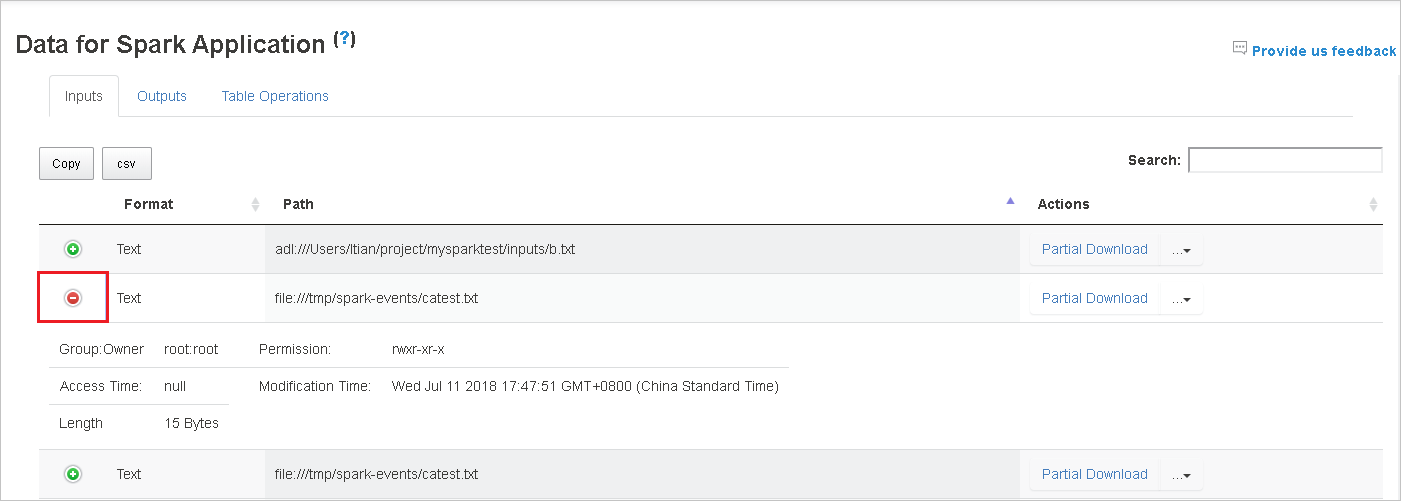
Laden Sie ein einzelne Datei herunter, indem Sie rechts auf Unvollständiger Download klicken. Die ausgewählte Datei wird lokal heruntergeladen. Wenn die Datei nicht mehr vorhanden ist, wird eine neue Registerkarte geöffnet, auf der die Fehlermeldungen angezeigt werden.
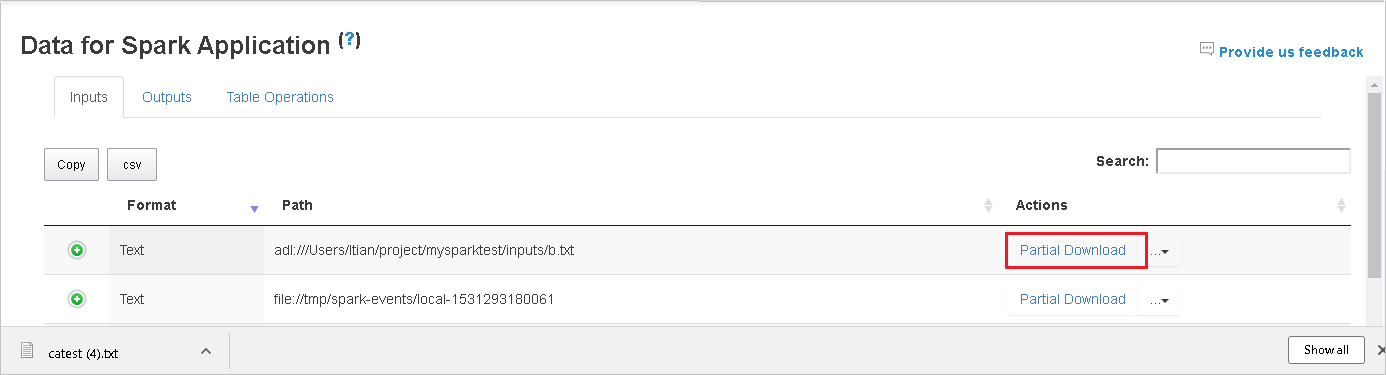
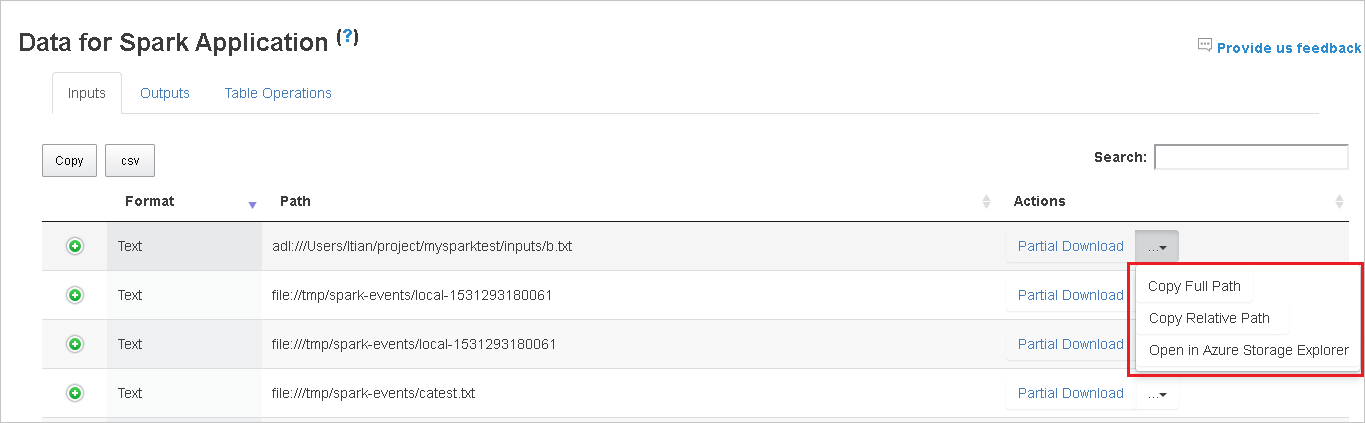
Kopieren Sie einen vollständigen oder relativen Pfad, indem Sie entweder Vollständigen Pfad kopieren oder Relativen Pfad kopieren im erweiterten Downloadmenü auswählen. Klicken Sie bei Azure Data Lake Storage-Dateien auf In Azure Storage-Explorer öffnen, um den Azure Storage-Explorer zu starte und den Ordner nach den Anmeldung aufzurufen.
Wenn so viele Zeilen vorhanden sind, dass sie nicht auf einer einzelnen Seite angezeigt werden können, klicken Sie zum Navigieren auf die Seitenzahlen unten in der Tabelle.

Für weitere Informationen zeigen oder klicken Sie auf das Fragezeichen neben Daten für Spark-Anwendung, um die QuickInfo anzuzeigen.
Klicken Sie auf Feedback senden, um Feedback zu Problemen zu übermitteln.
Verwenden der Registerkarte „Graph“ des Spark-Verlaufsservers
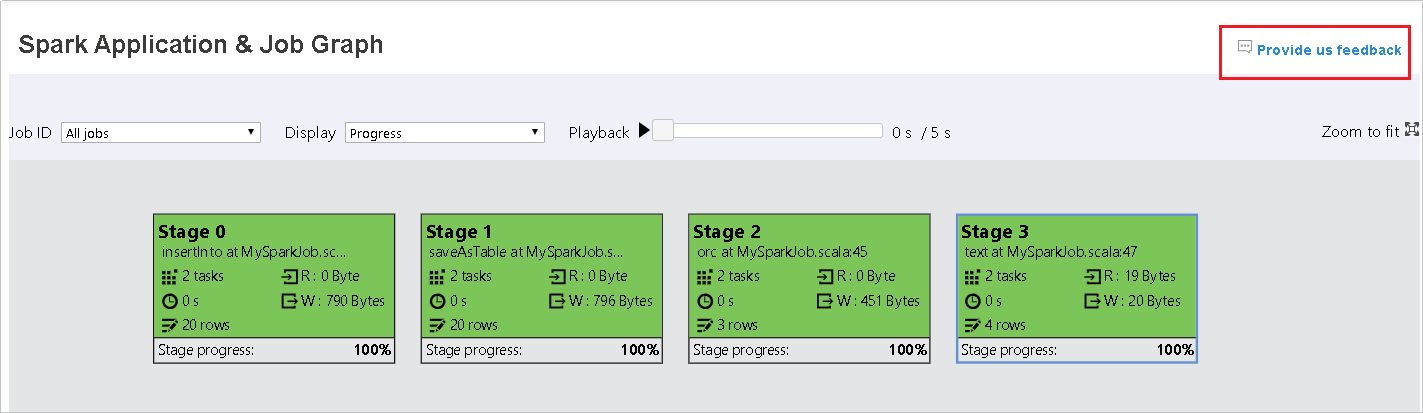
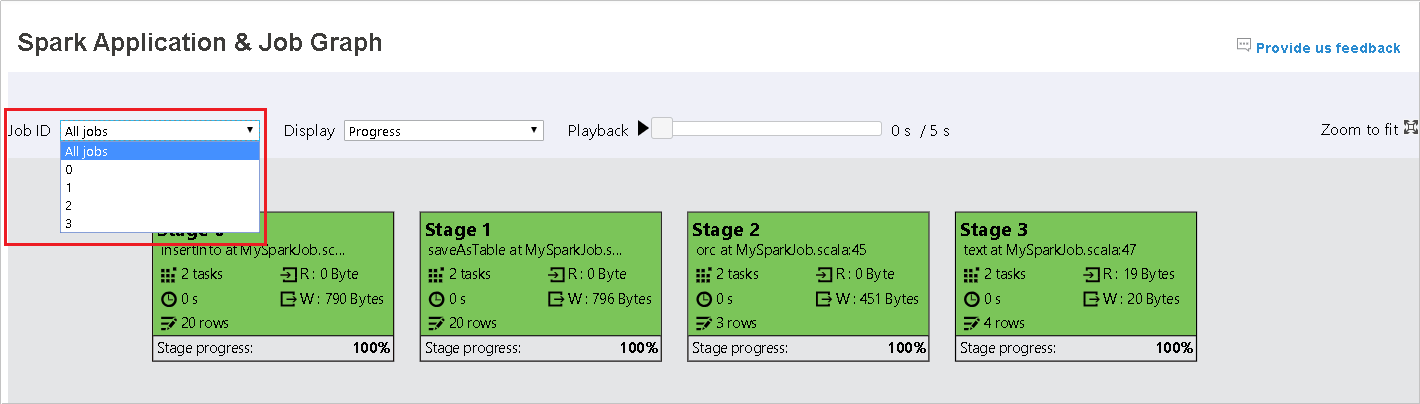
Wählen Sie die Auftrags-ID aus, und klicken Sie dann im Toolmenü auf Graph, um den Auftragsgraph anzuzeigen. Der Graph zeigt standardmäßig alle Aufträge an. Filtern Sie die Ergebnisse mithilfe des Dropdownmenüs Auftrags-ID.
Standardmäßig ist die Anzeigeoption Fortschritt ausgewählt. Überprüfen Sie den Datenfluss, indem Sie Read (Gelesen) oder Written (Geschrieben) im Dropdownmenü Anzeigen auswählen.
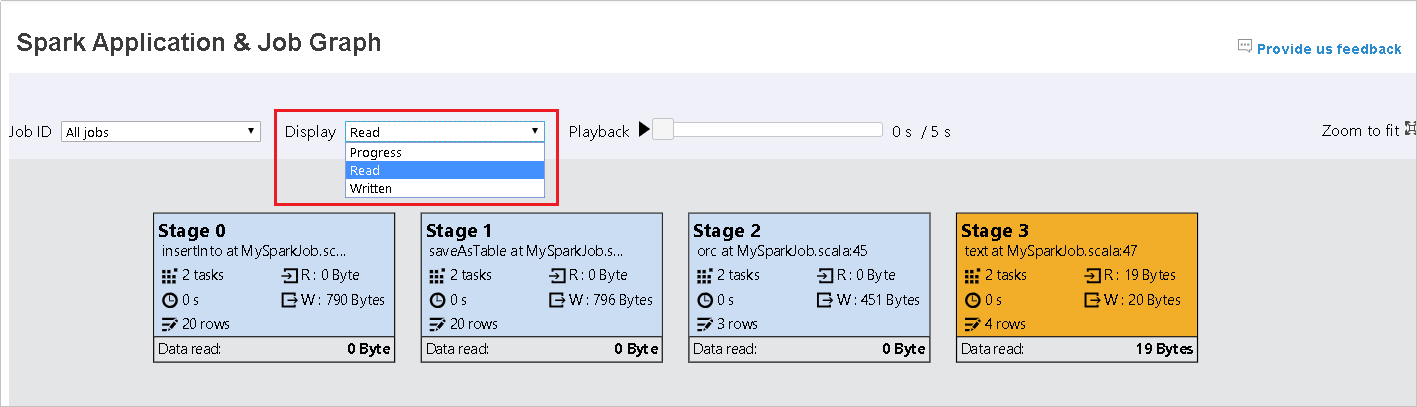
Die Hintergrundfarbe eines jeden Auftrags entspricht einem Wärmebild.

Color BESCHREIBUNG Grün die abgeschlossen wurden. Orange Die Aufgabe ist fehlgeschlagen. Dies wirkt sich jedoch nicht auf das Endergebnis des Auftrags aus. Für diese Aufgaben gibt es doppelte oder Wiederholungsinstanzen, die später erfolgreich durchgeführt werden können. Blau die gerade ausgeführt werden. White deren Ausführung noch ansteht oder bei denen eine Phase übersprungen wurde. Red fehlgeschlagene Aufträge. 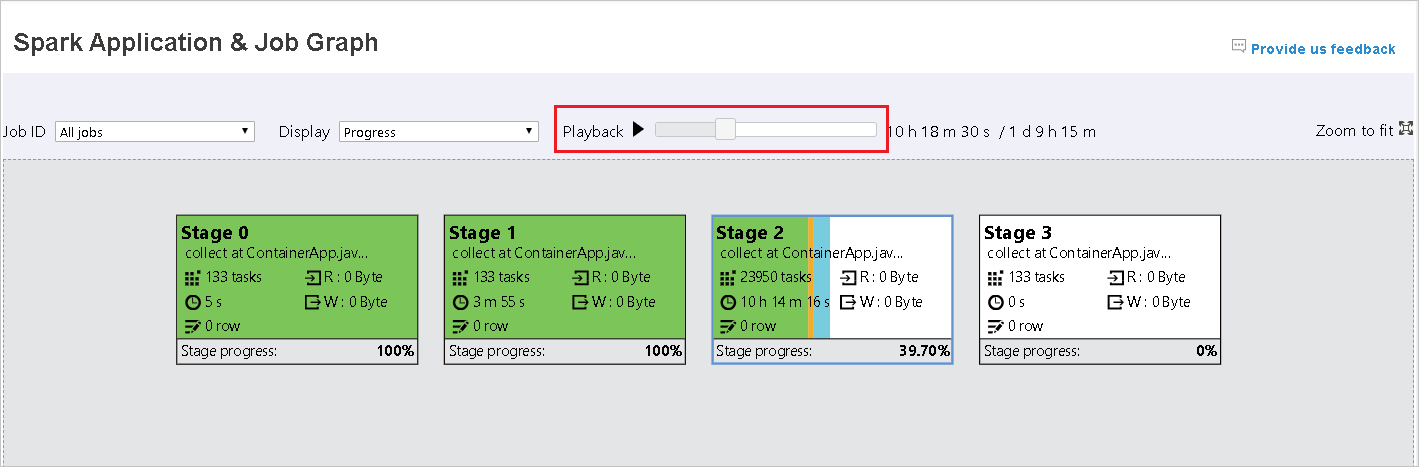
Übersprungene Phasen werden in weiß angezeigt.
Hinweis
Für abgeschlossene Aufträge ist die Wiedergabefunktion verfügbar. Klicken Sie auf die Schaltfläche Wiedergabe, um den Auftrag wiederzugeben. Sie können den Auftrag jederzeit mit der Stoppschaltfläche beenden. Bei der Wiedergabe eines Auftrags wird der Status der einzelnen Aufgaben durch die Farbe angegeben. Für unvollständige Aufträge wird die Wiedergabe nicht unterstützt.
Scrollen Sie, um in den Auftragsgraph hinein oder heraus zu zoomen, oder klicken Sie auf Zoom anpassen, um den Graph an die Anzeige anzupassen.
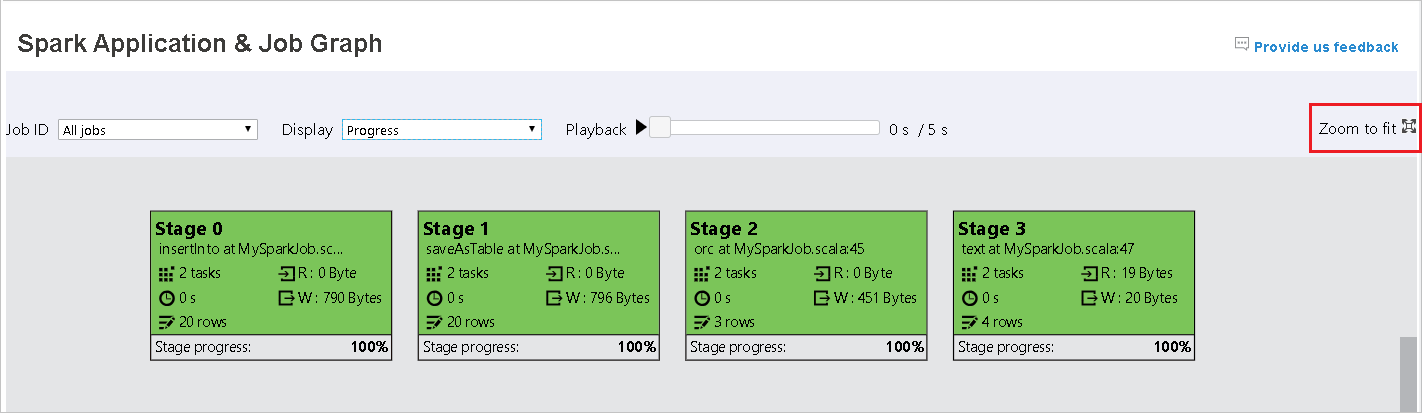
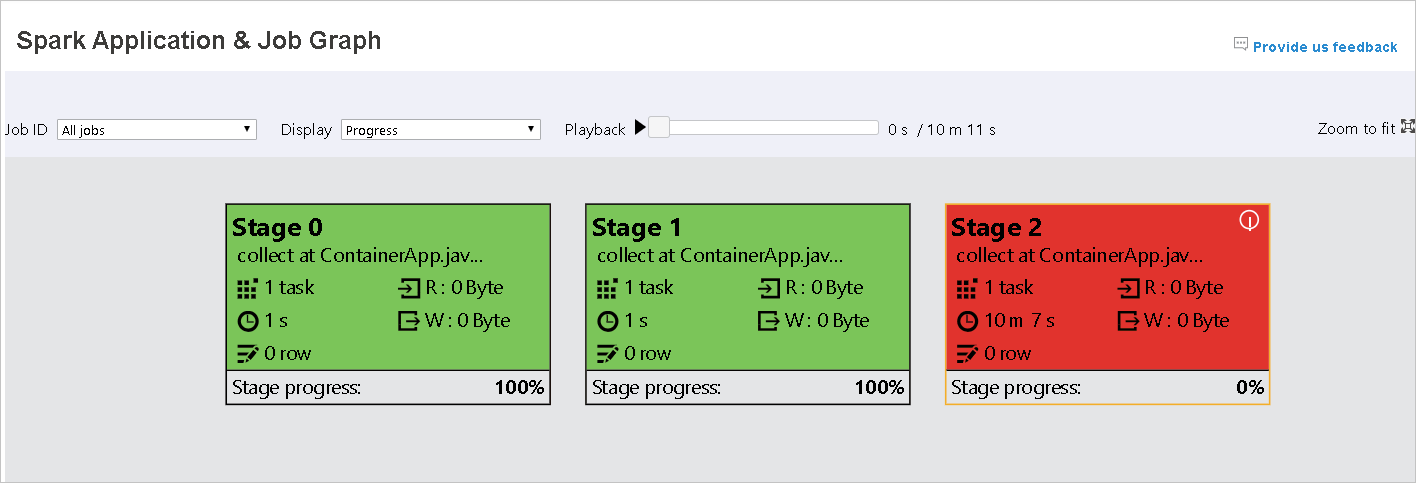
Wenn Aufgaben fehlschlagen, können Sie auf den Graphknoten zeigen, um die QuickInfo anzuzeigen. Klicken Sie anschließend auf die Phase, um sie in einer neuen Seite zu öffnen.
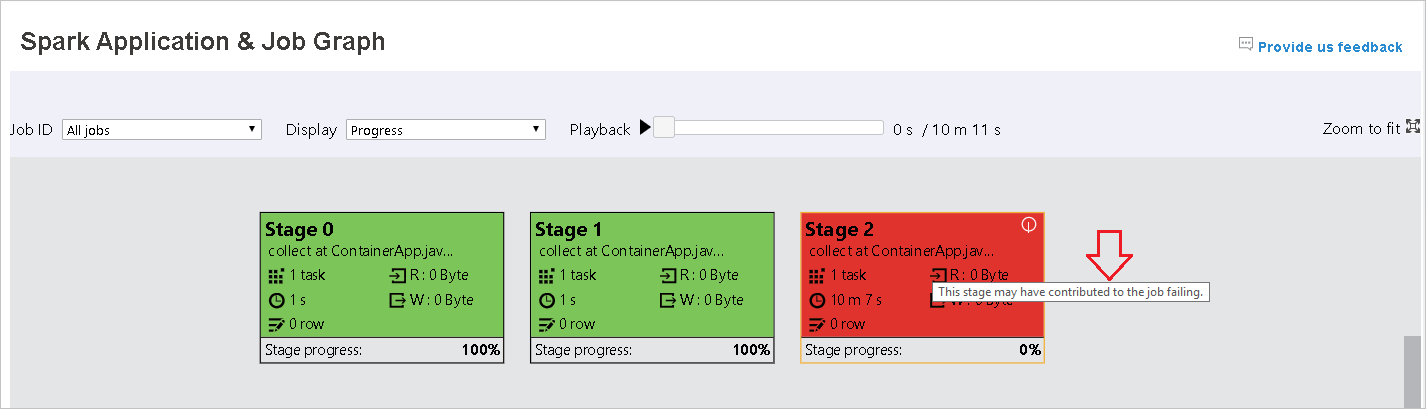
Die Phasen auf der Seite „Spark Application & Job Graph“ (Spark-Anwendung & Auftragsgraph) zeigen QuickInfos und kleine Symbole an, wenn die Aufgaben die folgenden Bedingungen erfüllen:
Datenschiefe: Lesegröße der Daten > durchschnittliche Lesegröße der Daten aller Aufträge innerhalb dieser Phase × 2 und Lesegröße der Daten > 10 MB
Zeitabweichung: Ausführungszeit > durchschnittliche Ausführungszeit aller Aufgaben in dieser Phase × 2 und Ausführungszeit > 2 Minuten
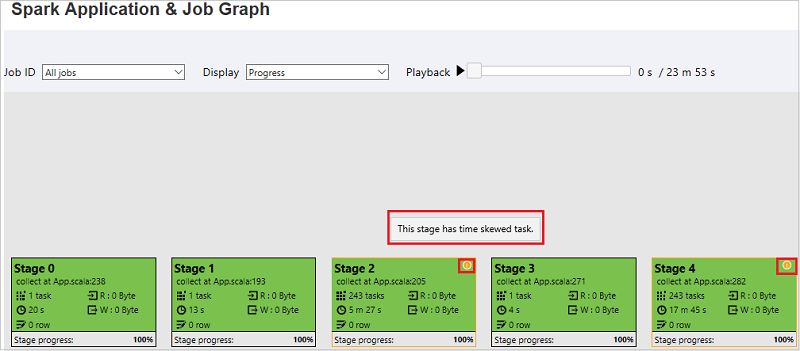
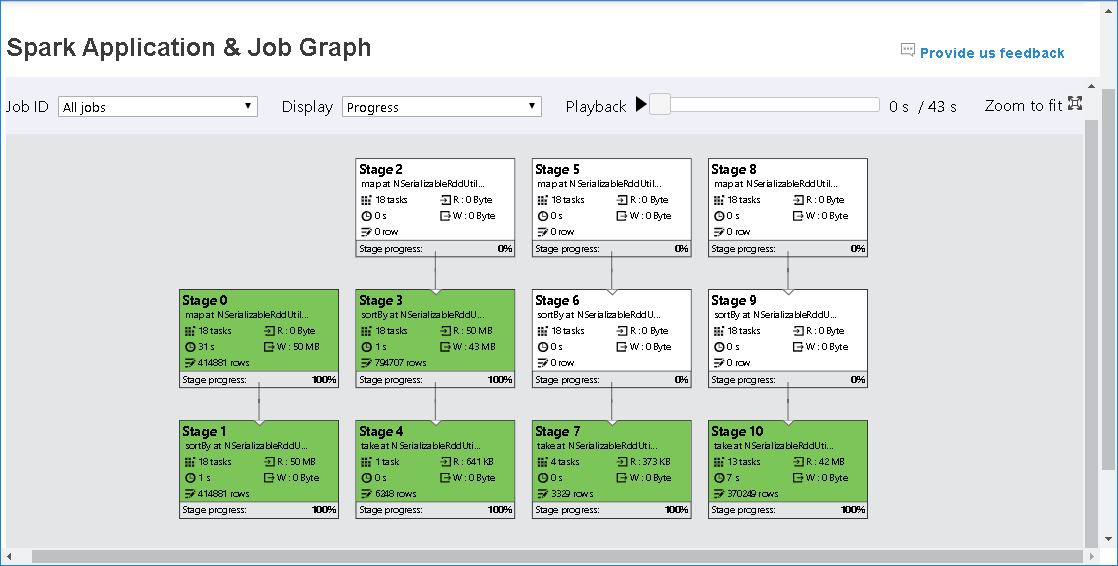
Der Auftragsgraphknoten zeigt die folgenden Informationen zu den einzelnen Phasen an:
id
Name oder Beschreibung
Anzahl der Aufgaben insgesamt
Gelesene Daten: die Summe der Eingabegröße und der Shuffle-Lesegröße
Geschriebene Daten: die Summe der Ausgabegröße und der Shuffle-Schreibgröße
Ausführungszeit: die Zeit zwischen der Startzeit des ersten Versuchs und der Endzeit des letzten Versuchs
Zeilenanzahl: die Summe der Eingabe- und Ausgabedatensätze sowie die Datensätze der Shuffle-Lesevorgänge und -Schreibvorgänge
Status
Hinweis
Standardmäßig zeigt der Auftragsdiagrammknoten Informationen zum letzten Versuch der einzelnen Phasen an (mit Ausnahme der Phase „Ausführungszeit“). Während der Wiedergabe zeigt der Auftragsgraphknoten jedoch Informationen zu jedem Versuch an.
Hinweis
Für die Datengrößen bei Lese- und Schreibvorgänge wird 1 MB = 1.000 KB = 1.000 × 1.000 Byte verwendet.
Senden Sie Ihr Feedback zu Problemen, indem Sie auf Feedback senden klicken.
Verwenden der Registerkarte „Diagnose“ des Spark-Verlaufsservers
Wählen Sie die Auftrags-ID und dann im Menü „Extras“ die Option Diagnose aus, um die Ansicht der Auftragsdiagnose aufzurufen. Die Registerkarte Diagnose umfasst die Registerkarten Datenschiefe, Zeitabweichung und Executor Usage Analysis (Analyse zur Executorauslastung).
Überprüfen Sie die Datenschiefe, Zeitabweichung und Executor-Nutzungsanalyse, indem Sie die entsprechenden Registerkarten auswählen.
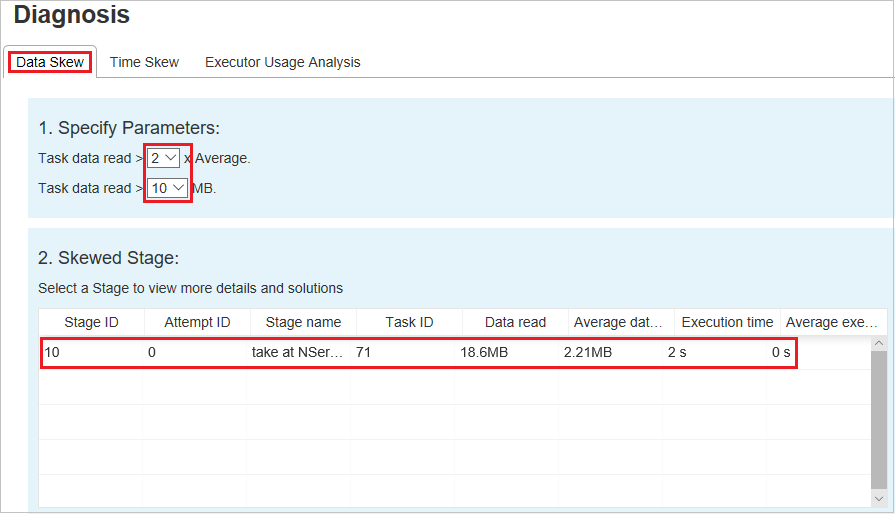
Datenschiefe
Klicken Sie auf die Registerkarte Datenschiefe. Daraufhin werden die entsprechenden Aufgaben mit Abweichungen basierend auf den angegebenen Parametern angezeigt.
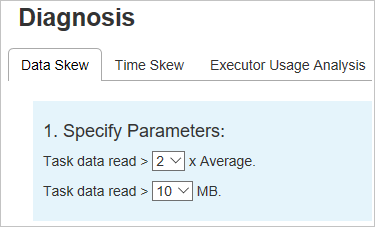
Angeben von Parametern
Im Abschnitt Parameter festlegen werden die Parameter angezeigt, die zum Ermitteln der Datenschiefe verwendet werden. Die Standardregel lautet wie folgt: Die gelesenen Aufgabendaten ist dreimal so groß wie die durchschnittlichen gelesenen Aufgabendaten, und die gelesenen Aufgabendaten sind größer als 10 MB. Wenn Sie Ihre eigene Regel für Aufgaben mit Abweichungen definieren möchten, können Sie die Parameter selbst festlegen. Die Abschnitte Schiefe Phase und Skew Chart (Abweichungsdiagramm) werden entsprechend aktualisiert.
Schiefe Phase
Im Abschnitt Schiefe Phase werden Phasen angezeigt, die Aufgaben mit Abweichungen enthalten, die die angegebenen Kriterien erfüllen. Wenn eine Phase mehrere Aufgaben mit Abweichungen enthält, zeigt der Abschnitt Schiefe Phase nur die Aufgabe mit der größten Abweichung an (d. h. die größten Daten für die Datenschiefe).
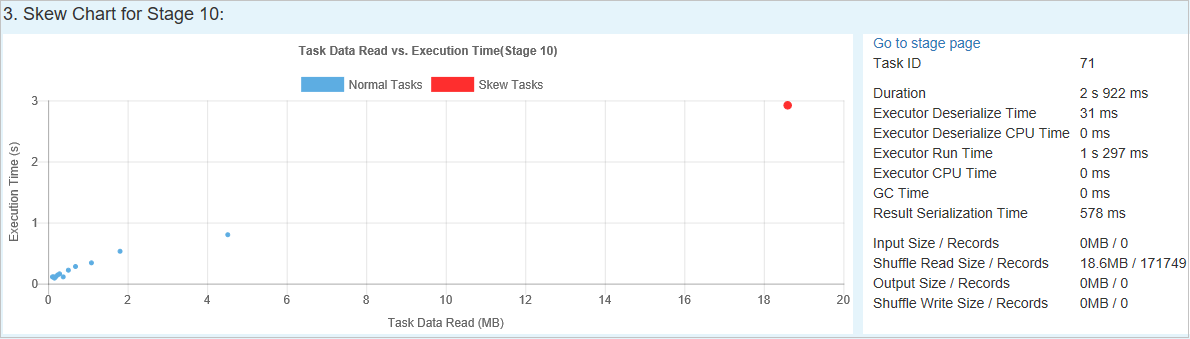
Skew Chart (Abweichungsdiagramm)
Wenn Sie eine Zeile in der Tabelle Schiefe Phase auswählen, zeigt das Abweichungsdiagramm basierend auf den gelesenen Daten und der Ausführungszeit mehr Informationen zur Aufgabenverteilung an. Die Aufgaben mit Abweichungen sind rot und die normalen Aufgaben sind blau markiert. Aus Leistungsgründen werden im Diagramm bis zu 100 Beispielaufgaben angezeigt. Die Aufgabendetails werden im Bereich unten rechts angezeigt.
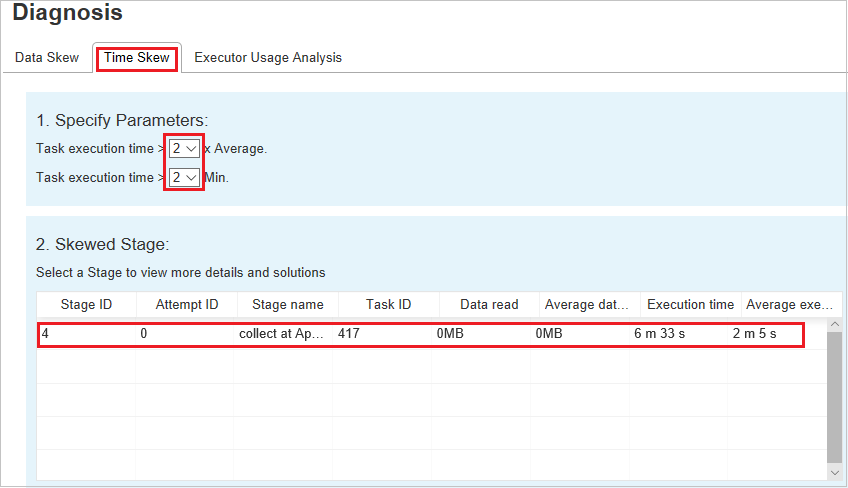
Zeitabweichung
Auf der Registerkarte Time Skew (Zeitabweichung) werden schiefe Aufträge basierend auf ihrer Ausführungszeit angezeigt.
Angeben von Parametern
Im Abschnitt Parameter festlegen werden die Parameter angezeigt, die zum Ermitteln der Zeitabweichung verwendet werden. Die Standardregel lautet wie folgt: Die Aufgabenausführungszeit ist dreimal so lang wie die durchschnittliche Ausführungszeit, und die Aufgabenausführungszeit ist länger als 30 Sekunden. Sie können die Parameter Ihren Anforderungen entsprechend anpassen. Die schiefe Phase und das Abweichungsdiagramm zeigen die entsprechenden Phasen- und Aufgabeninformationen wie auf der Registerkarte Datenschiefe an.
Wenn Sie die Zeitabweichung auswählen, wird das gefilterte Ergebnis im Abschnitt Schiefe Phase entsprechend der Parameter angezeigt, die im Abschnitt Parameter festlegen festgelegt wurden. Wenn Sie ein Element im Abschnitt Schiefe Phase auswählen, wird das entsprechende Diagramm im dritten Abschnitt und die Aufgabendetails werden im Bereich unten rechts angezeigt.
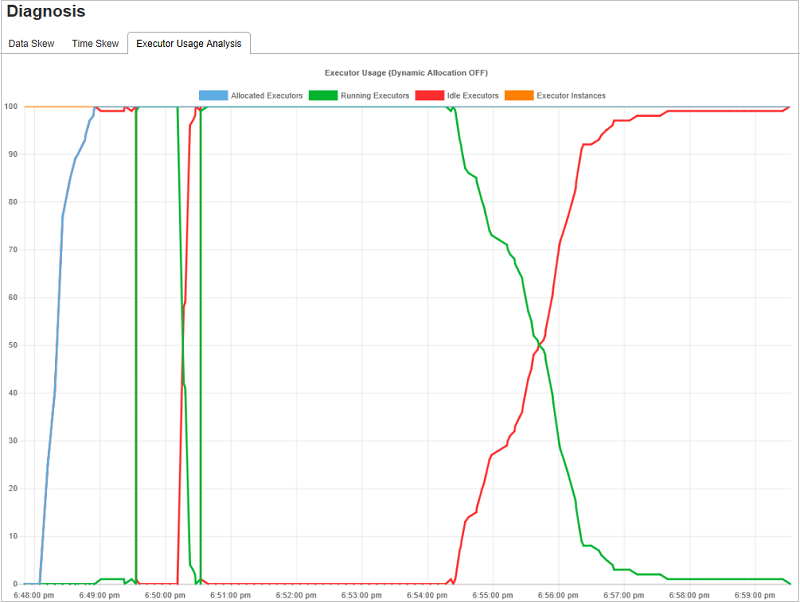
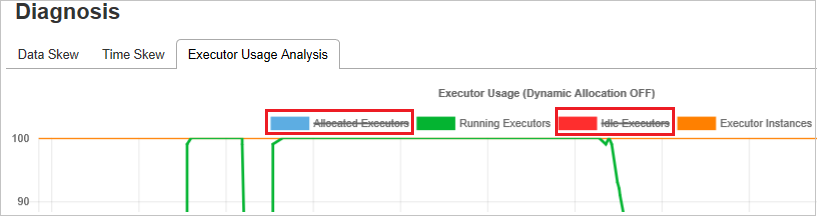
Graph für die Analyse der Executorauslastung
Der Graph für die Executorauslastung zeigt die tatsächliche Executorzuteilung und den Ausführungsstatus des Auftrags an.
Wenn Sie die Analyse der Executorauslastung aufrufen, werden vier verschiedene Funktionsgraphen zur Executorauslastung dargestellt: Allocated Executors (Zugewiesene Executors), Running Executors (Ausgeführte Executors), Idle Executors (Excutors im Leerlauf) und Max Executor Instances (Höchstanzahl der Executorinstanzen). Durch jedes Ereignis, bei dem ein Executor hinzugefügt oder ein Executor entfernt wird, wird die Anzahl der zugewiesenen Executors erhöht oder verringert. Weitere Vergleiche finden Sie im Ereignisverlauf auf der Registerkarte Aufträge.
Wählen Sie das Farbsymbol aus, um den entsprechenden Inhalt in allen Entwürfen auszuwählen oder die Auswahl aufzuheben.
Häufig gestellte Fragen
Wie stelle ich die Communityversion wieder her?
Führen Sie die folgenden Schritte aus, um die Communityversion wiederherzustellen.
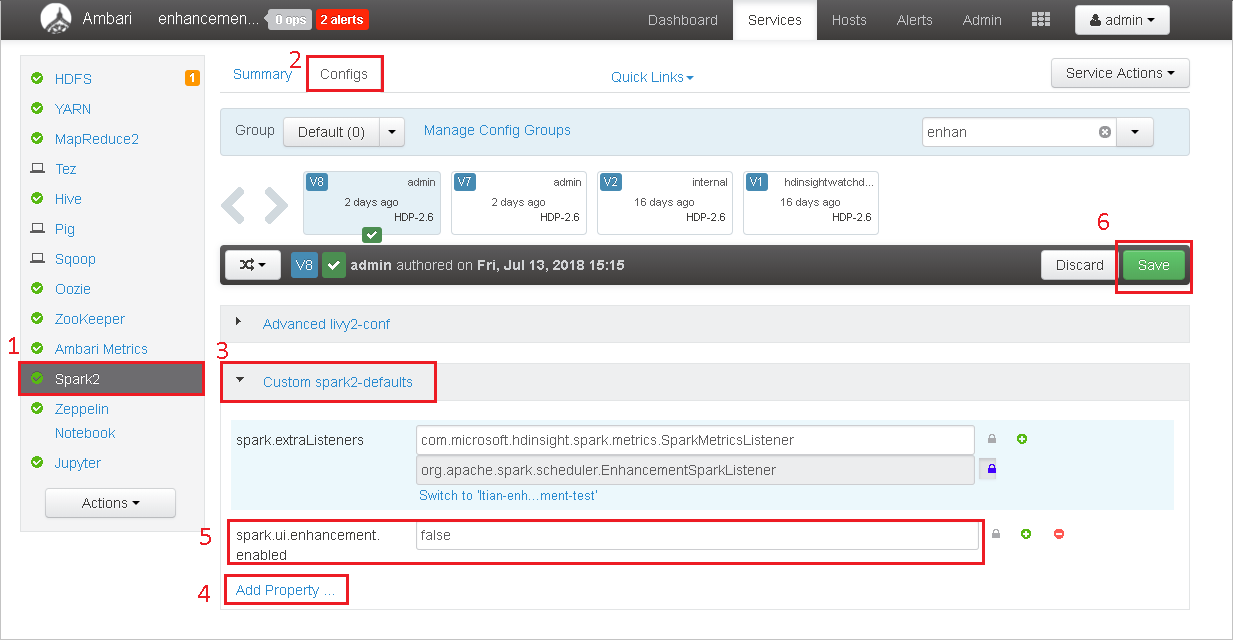
Öffnen Sie den Cluster in Ambari.
Navigieren Sie zu Spark2>Configs.
Wählen Sie Custom Spark2-defaults aus.
Klicken Sie auf Add Property ... (Eigenschaft hinzufügen).
Fügen Sie spark.ui.enhancement.enabled=false hinzu, und speichern Sie diese Änderung.
Die Eigenschaft ist jetzt auf false festgelegt.
Wählen Sie zum Speichern der Konfiguration Speichern aus.
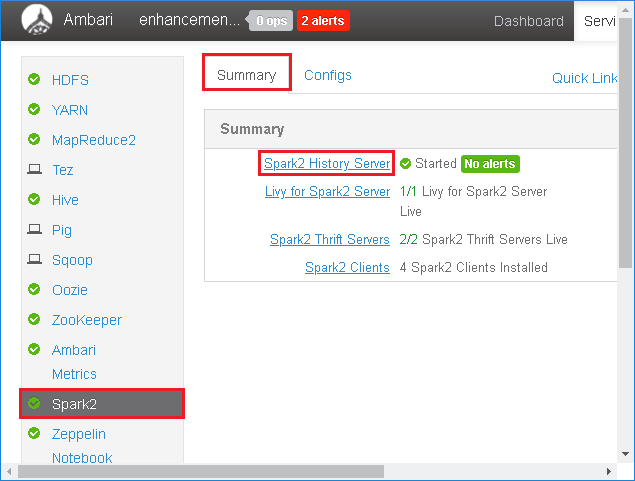
Klicken Sie im linken Bereich auf Spark2. Klicken Sie dann auf der Registerkarte Summary (Zusammenfassung) auf Spark2 History Server (Spark2-Verlaufsserver).
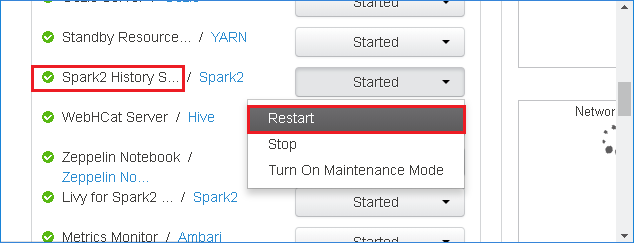
Klicken Sie rechts neben Spark2 History Server (Spark2-Verlaufsserver) auf die Schaltfläche Started (Gestartet), und wählen Sie dann im Dropdownmenü die Option Restart (Neu starten) aus, um den Spark-Verlaufsserver neu zu starten.
Aktualisieren Sie die Webbenutzeroberfläche des Spark-Verlaufsservers. Dadurch wird die Communityversion wiederhergestellt.
Wie lade ich ein Spark-Verlaufsserverereignis hoch, um es als Problem zu melden?
Führen Sie die folgenden Schritte zum Melden des Ereignisses durch, wenn ein Fehler beim Spark-Verlaufsserver auftritt:
Laden Sie das Ereignis herunter, indem Sie in der Webbenutzeroberfläche des Spark-Verlaufsservers auf Download klicken.
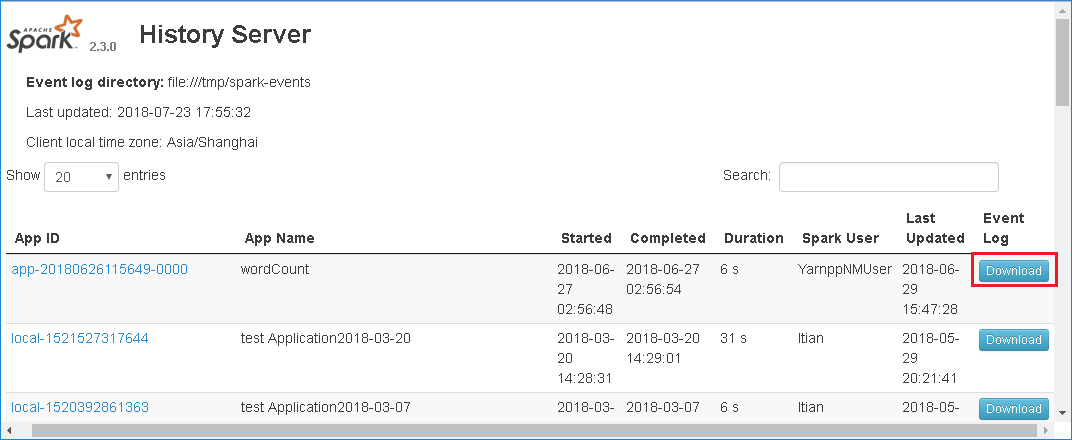
Klicken Sie auf der Seite Spark Application & Job Graph (Spark-Anwendung und Auftragsgraph) auf Feedback senden.
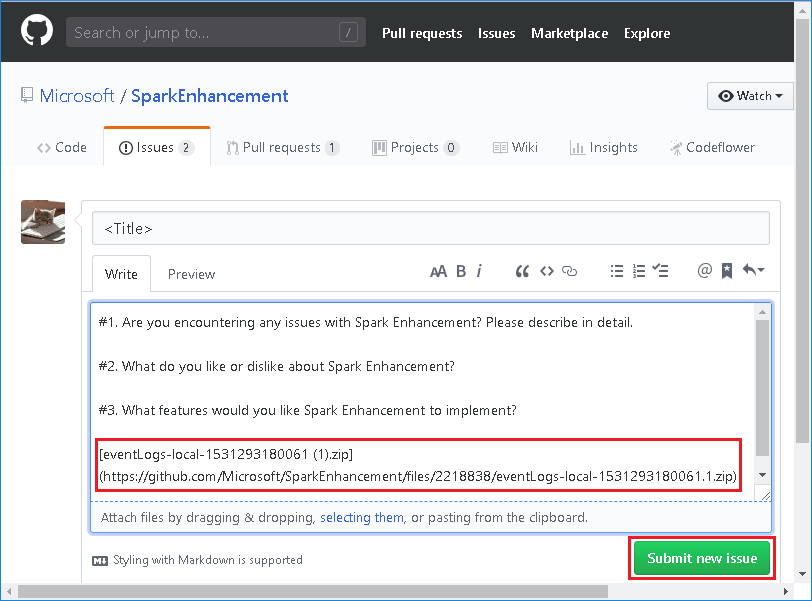
Geben Sie einen Titel und eine Beschreibung für den Fehler an. Ziehen Sie dann die ZIP-Datei auf das Feld „Bearbeiten“, und wählen Sie Submit new issue (Neues Problem melden) aus.
Wie führe ich in einem Hotfixszenario ein Upgrade für eine JAR-Datei durch?
Wenn Sie ein Upgrade mit einem Hotfix durchführen möchten, verwenden Sie das folgende Skript, das ein Upgrade für spark-enhancement.jar* durchführt.
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
Verwendung
upgrade_spark_enhancement.sh https://${jar_path}
Beispiel
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Verwenden der Bash-Datei über das Azure-Portal
Starten Sie das Azure-Portal, und wählen Sie dann Ihren Cluster aus.
Führen Sie eine Skriptaktion mit den folgenden Parametern aus:
Eigenschaft Wert Skripttyp --Benutzerdefiniert Name UpgradeJar Bash-Skript-URI https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shKnotentyp(en) Hauptknoten, Workerknoten Parameter https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar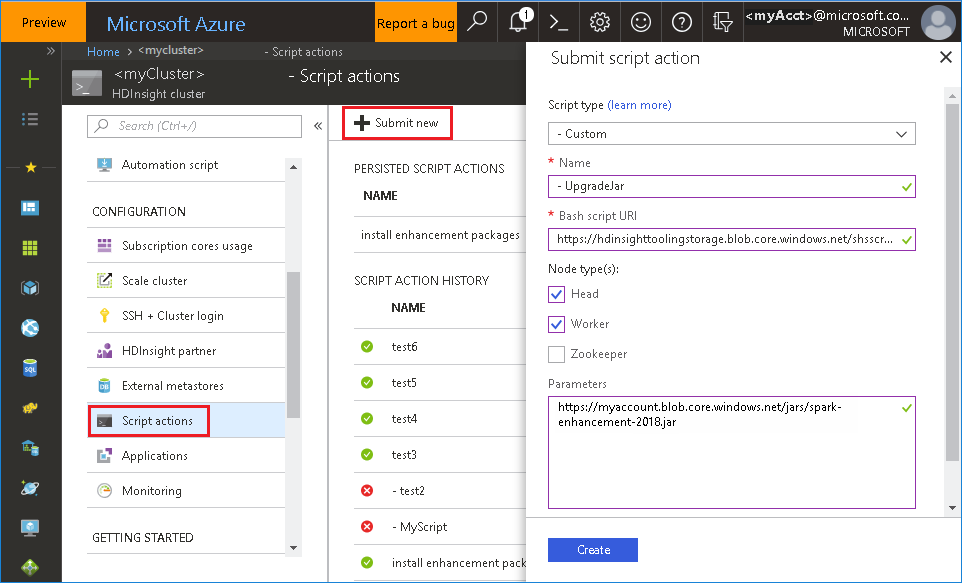
Bekannte Probleme
Derzeit funktioniert der Spark-Verlaufsserver nur mit Spark 2.3 und 2.4.
Eingabe- und Ausgabedaten, die RDD nutzen, werden nicht auf der Registerkarte Daten angezeigt.
Nächste Schritte
- Verwalten von Ressourcen für den Apache Spark-Cluster unter HDInsight
- Konfigurieren von Apache Spark-Einstellungen
Vorschläge
Wenn Sie Feedback abgeben möchten oder bei der Verwendung des Tools Probleme auftreten, senden Sie eine E-Mail an hdivstool@microsoft.com.