Erstellen von Apache Spark-Anwendungen für einen HDInsight-Cluster mit dem Azure-Toolkit für IntelliJ
In diesem Artikel wird gezeigt, wie Sie mit dem Azure-Toolkit-Plug-In für die IntelliJ-IDE Apache Spark-Anwendungen in Azure HDInsight entwickeln. Azure HDInsight ist ein verwalteter Open-Source-Analysedienst in der Cloud. Der Dienst ermöglicht Ihnen die Verwendung von Open-Source-Frameworks wie Hadoop, Apache Spark, Apache Hive und Apache Kafka.
Sie können das Azure-Toolkit-Plug-In auf mehrere Arten verwenden:
- Entwickeln und Übermitteln Sie eine Scala Spark-Anwendung an einen HDInsight Spark-Cluster.
- Zugreifen auf Ihre Azure HDInsight Spark-Clusterressourcen
- Entwickeln und lokales Ausführen einer Scala Spark-Anwendung
In diesem Artikel werden folgende Vorgehensweisen behandelt:
- Verwenden des Plug-Ins „Azure-Toolkit für IntelliJ“
- Entwickeln von Apache Spark-Anwendungen
- Übermitteln einer Anwendung an einen Azure HDInsight-Cluster
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight. Nur HDInsight-Cluster in öffentlichen Clouds werden unterstützt, während andere sichere Cloud-Typen (z. B. staatliche Clouds) nicht unterstützt werden.
Oracle Java Development Kit. In diesem Artikel wird die Java-Version 8.0.202 verwendet.
IntelliJ IDEA. Dieser Artikel verwendet IntelliJ IDEA Community 2018.3.4.
Azure-Toolkit für IntelliJ. Weitere Informationen finden Sie unter Installieren des Azure-Toolkits für IntelliJ.
Installieren des Scala-Plug-Ins für IntelliJ IDEA
Schritte zum Installieren des Scala-Plug-Ins:
Öffnen Sie IntelliJ IDEA.
Navigieren Sie auf der Willkommensseite zu Konfigurieren>Plug-Ins, um das Fenster Plug-Ins zu öffnen.
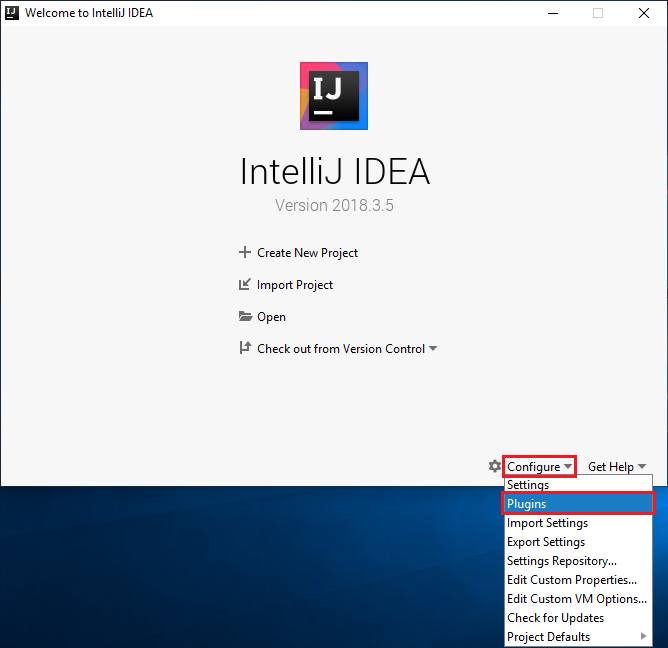
Wählen Sie für das in dem neuen Fenster empfohlene Scala-Plug-In die Option Installieren aus.
Nach erfolgreicher Plug-In-Installation müssen Sie die IDE neu starten.
Erstellen einer Spark Scala-Anwendung für einen HDInsight Spark-Cluster
Starten Sie IntelliJ IDEA, und wählen Sie Create New Project (Neues Projekt erstellen) aus, um das Fenster New Project (Neues Projekt) zu öffnen.
Wählen Sie im linken Bereich Azure Spark/HDInsight aus.
Wählen Sie im Hauptfenster Spark Project (Scala) (Spark-Projekt (Scala)) aus.
Wählen Sie in der Dropdownliste Buildtool eine der folgenden Optionen aus:
Maven für die Unterstützung des Scala-Projekterstellungs-Assistenten
SBT zum Verwalten von Abhängigkeiten und Erstellen für das Scala-Projekt
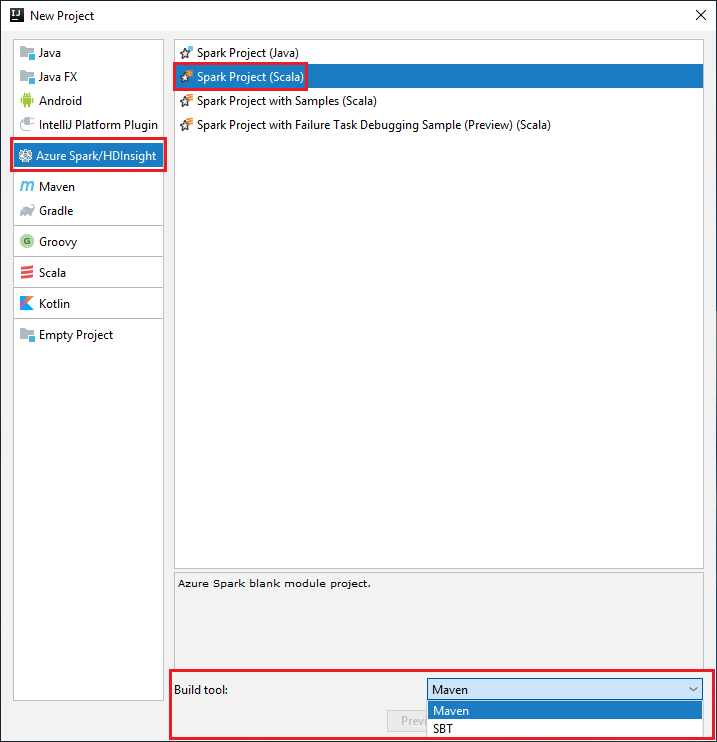
Wählen Sie Weiter aus.
Geben Sie im Fenster New Project (Neues Projekt) die folgenden Informationen an:
Eigenschaft BESCHREIBUNG Projektname Geben Sie einen Namen ein. In diesem Artikel wird myAppverwendet.Projektspeicherort Geben Sie den Speicherort für Ihr Projekt ein. Project SDK (Projekt-SDK) Dieses Feld ist bei der erstmaligen Verwendung von IDEA möglicherweise leer. Wählen Sie New... (Neu...) aus, und navigieren Sie zu Ihrem JDK. Spark-Version Der Erstellungs-Assistent integriert die passende Version für das Spark-SDK und das Scala-SDK. Wenn Sie eine ältere Spark-Clusterversion als 2.0 verwenden, wählen Sie Spark 1.x aus. Wählen Sie andernfalls Spark 2.x aus. In diesem Beispiel wird Spark 2.3.0 (Scala 2.11.8) verwendet. 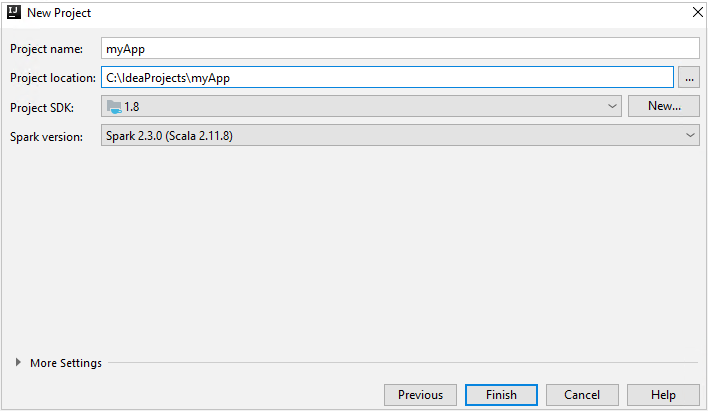
Wählen Sie Fertig stellenaus. Es kann einige Minuten dauern, bis das Projekt verfügbar ist.
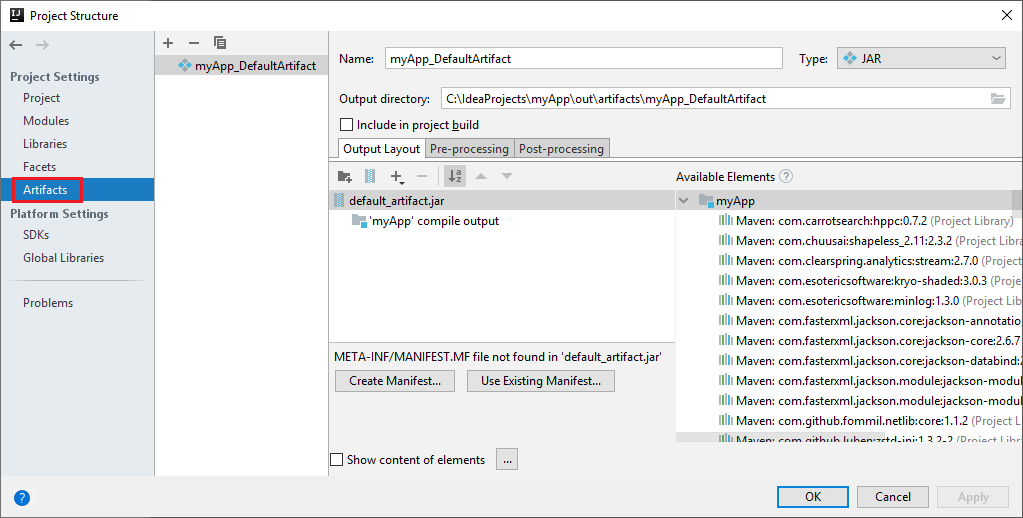
Das Spark-Projekt erstellt automatisch ein Artefakt. Führen Sie die folgenden Schritte aus, um sich das Artefakt anzeigen zu lassen:
a. Navigieren Sie auf der Menüleiste zu Datei>Projektstruktur.
b. Wählen Sie im Fenster Projektstruktur die Option Artefakte aus.
c. Wählen Sie Abbrechen aus, nachdem Sie sich das Artefakt angesehen haben.
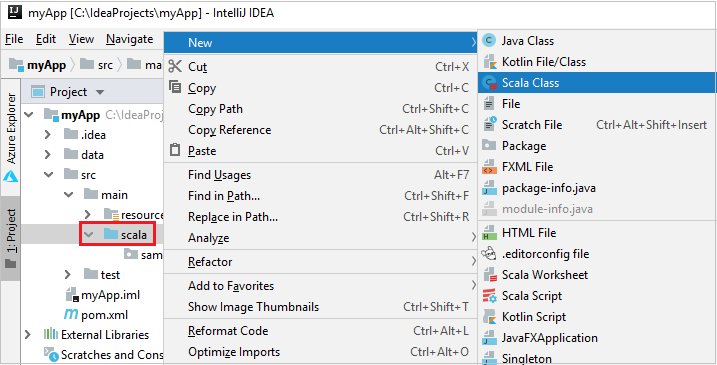
Fügen Sie den Quellcode der Anwendung über die folgenden Schritte hinzu:
a. Navigieren Sie in Project zu myApp>src>main>scala.
b. Klicken Sie mit der rechten Maustaste auf scala, und navigieren Sie dann zu New>Scala Class (Neu > Scala-Klasse).
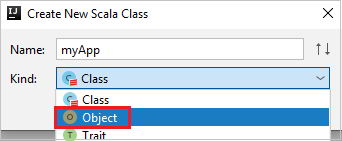
c. Geben Sie im Dialogfeld Create New Scala Class (Neue Scala-Klasse erstellen) einen Namen ein. Wählen Sie im Dropdownfeld Kind (Art) die Option Object aus, und wählen Sie dann OK aus.
d. Die Datei myApp.scala wird dann in der Hauptansicht geöffnet. Ersetzen Sie den Standardcode durch den folgenden Code:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Der Code liest die Daten aus der Datei „HVAC.csv“ (die für alle HDInsight Spark-Cluster verfügbar ist), ruft die Zeilen ab, die nur eine Ziffer in der siebten Spalte der CSV-Datei enthalten, und schreibt die Ausgabe in
/HVACOutunter dem Standardspeichercontainer für den Cluster.
Herstellen einer Verbindung mit Ihrem HDInsight-Cluster
Der Benutzer kann sich bei Ihrem Azure-Abonnement anmelden oder einen HDInsight-Cluster verknüpfen. Verwenden Sie zum Herstellen einer Verbindung mit Ihrem HDInsight-Cluster den Ambari-Benutzernamen mit dem zugehörigen Kennwort oder die Anmeldeinformationen für eine eingebundene Domäne.
Melden Sie sich bei Ihrem Azure-Abonnement an.
Navigieren Sie in der Menüleiste zu Ansicht>Toolfenster>Azure Explorer.
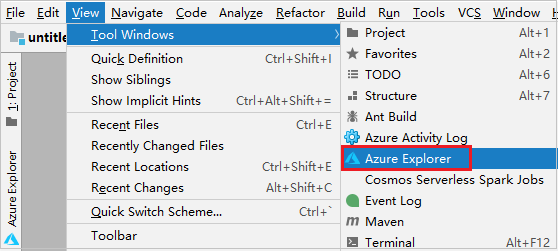
Klicken Sie im Azure Explorer mit der rechten Maustaste auf den Knoten Azure, und wählen Sie dann Anmelden aus.
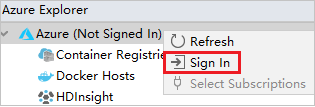
Wählen Sie im Dialogfeld Azure Sign In (Azure-Anmeldung) die Option Device Login (Geräteanmeldung) aus, und klicken Sie dann auf Sign in (Anmelden).
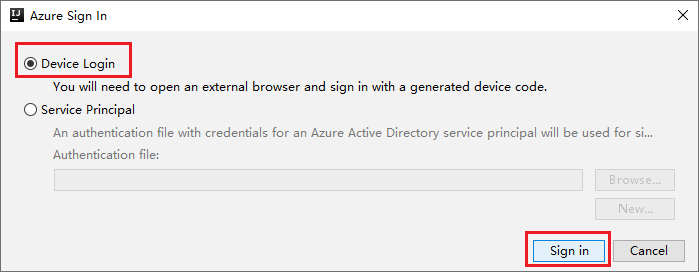
Klicken Sie im Dialogfeld Azure Device Login (Azure-Geräteanmeldung) auf Copy&Open (Kopieren und öffnen).
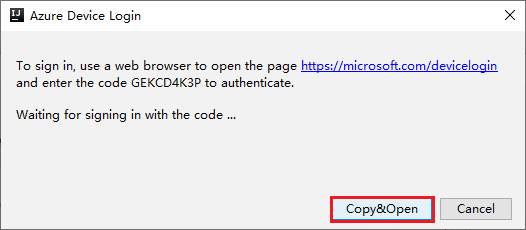
Fügen Sie den Code auf der Benutzeroberfläche des Browsers ein, und klicken Sie auf Next (Weiter).
Geben Sie Ihre Azure-Anmeldeinformationen ein, und schließen Sie den Browser.
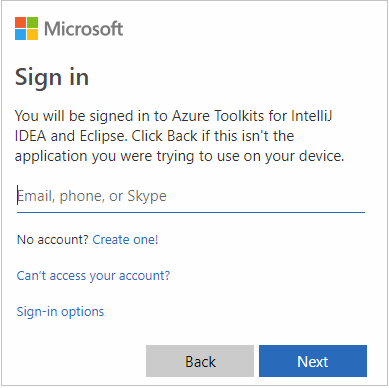
Nachdem Sie sich angemeldet haben, werden im Dialogfeld Abonnements auswählen alle Azure-Abonnements aufgelistet, die den Anmeldeinformationen zugeordnet sind. Wählen Sie das Abonnement aus, und klicken Sie dann auf die Schaltfläche Auswählen.
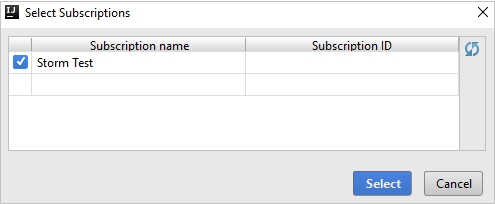
Erweitern Sie im Azure Explorer die Option HDInsight, um die HDInsight Spark-Cluster anzuzeigen, die sich in Ihren Abonnements befinden.
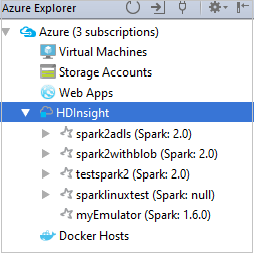
Um die dem Cluster zugeordneten Ressourcen (z.B. Speicherkonten) anzuzeigen, können Sie einen Clusternamenknoten noch einmal erweitern.
Verknüpfen eines Clusters
Sie können einen HDInsight-Cluster mithilfe des verwalteten Apache Ambari-Benutzernamens verknüpfen. In ähnlicher Weise können Sie einen in eine Domäne eingebundenen HDInsight-Cluster unter Verwendung von Domäne und Benutzername verknüpfen, wie etwa user1@contoso.com. Sie können auch einen Livy-Dienstcluster verknüpfen.
Navigieren Sie in der Menüleiste zu Ansicht>Toolfenster>Azure Explorer.
Klicken Sie im Azure Explorer mit der rechten Maustaste auf den Knoten HDInsight, und wählen Sie dann Cluster verknüpfen aus.
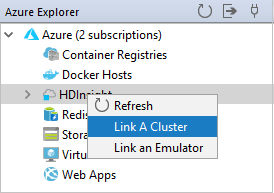
Die verfügbaren Optionen im Fenster Cluster verknüpfen variieren je nach dem Wert, den Sie in der Dropdownliste Ressourcentyp verknüpfen auswählen. Geben Sie Ihre Werte ein, und klicken Sie anschließend auf OK.
HDInsight-Cluster
Eigenschaft Wert Ressourcentyp verknüpfen Wählen Sie HDInsight-Cluster aus der Dropdownliste aus. Clustername/-URL Geben Sie einen Clusternamen ein. Authentifizierungstyp Lassen Sie die Standardauthentifizierung festgelegt. Benutzername Geben Sie den Clusterbenutzernamen ein. Der Standardwert lautet „admin“. Kennwort Geben Sie das Kennwort für den Benutzernamen ein. 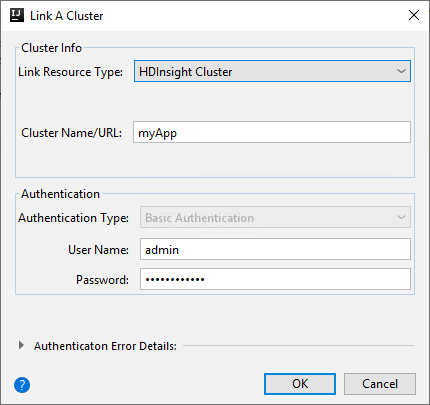
Livy Service
Eigenschaft Wert Ressourcentyp verknüpfen Wählen Sie Livy Service aus der Dropdownliste aus. Livy-Endpunkt Livy-Endpunkt eingeben Clustername Geben Sie einen Clusternamen ein. Yarn-Endpunkt Optional. Authentifizierungstyp Lassen Sie die Standardauthentifizierung festgelegt. Benutzername Geben Sie den Clusterbenutzernamen ein. Der Standardwert lautet „admin“. Kennwort Geben Sie das Kennwort für den Benutzernamen ein. 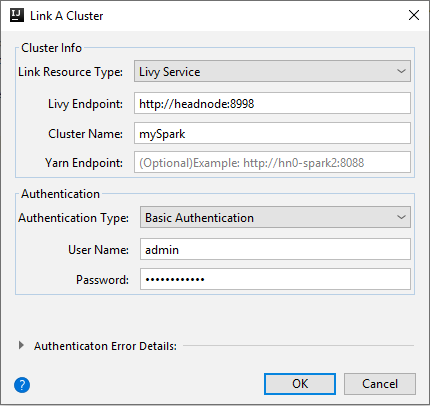
Sie finden Ihren verknüpften Cluster im Knoten HDInsight.
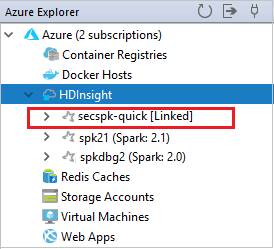
Sie können die Verknüpfung eines Clusters im Azure-Explorer auch aufheben.
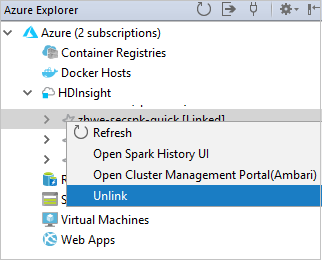
Ausführen einer Spark Scala-Anwendung in einem HDInsight Spark-Cluster
Nachdem Sie eine Scala-Anwendung erstellt haben, können Sie diese an den Cluster übermitteln.
Navigieren Sie in „Project“ (Projekt) zu myApp>src>main>scala>myApp. Klicken Sie mit der rechten Maustaste auf myApp, und wählen Sie Submit Spark Application (Spark-Anwendung übermitteln, wahrscheinlich am Listenende).
Wählen Sie im Dialogfeld Submit Spark Application (Spark-Anwendung übermitteln) die Option 1. Spark für HDInsight aus.
Geben Sie im Fenster Edit configuration (Konfiguration bearbeiten) die folgenden Werte an, und klicken Sie dann auf OK:
Eigenschaft Wert „Spark clusters (Linux only)“ (Spark-Cluster (nur Linux)) Wählen Sie den HDInsight Spark-Cluster aus, auf dem Sie Ihre Anwendung ausführen möchten. Select an Artifact to submit (Auswahl eines zu übermittelnden Artefakts) Behalten Sie die Standardeinstellung bei. „Main class name“ (Name der Hauptklasse) Der Standardwert ist die Hauptklasse der ausgewählten Datei. Sie können die Klasse ändern, indem Sie die Schaltfläche mit den Auslassungspunkten ( … ) und anschließend eine andere Klasse auswählen. Job configurations (Auftragskonfigurationen) Sie können die Standardschlüssel und die Werte ändern. Weitere Informationen finden Sie unter Apache Livy-REST-API. Befehlszeilenargumente Sie können bei Bedarf durch Leerzeichen getrennte Argumente für die Hauptklasse eingeben. Referenced Jars and Referenced Files („Referenzierte JARs“ und „Referenzierte Dateien“) Sie können bei Bedarf die Pfade für die JAR-Dateien und für die anderen Dateien eingeben, auf die verwiesen wird. Sie können auch Dateien im virtuellen Dateisystem von Azure durchsuchen, das derzeit nur ADLS Gen 2-Cluster unterstützt. Weitere Informationen finden Sie unter: Apache Spark Configuration (Apache Spark-Konfiguration). Lesen Sie auch die Informationen zum Hochladen von Ressourcen in einen Cluster. Job Upload Storage (Speicher für Auftragsupload) Erweitern Sie die Option, um zusätzliche Optionen anzuzeigen. Speichertyp Wählen Sie Use Azure Blob to upload (Azure-Blob für Upload verwenden) aus der Dropdownliste aus. Speicherkonto Geben Sie Ihr Speicherkonto ein. Storage Key (Speicherschlüssel) Geben Sie Ihren Speicherschlüssel ein. Speichercontainer Wählen Sie Ihren Speichercontainer aus der Dropdownliste aus, nachdem Sie Storage Account (Speicherkonto) und Storage Key (Speicherschlüssel) eingegeben haben. 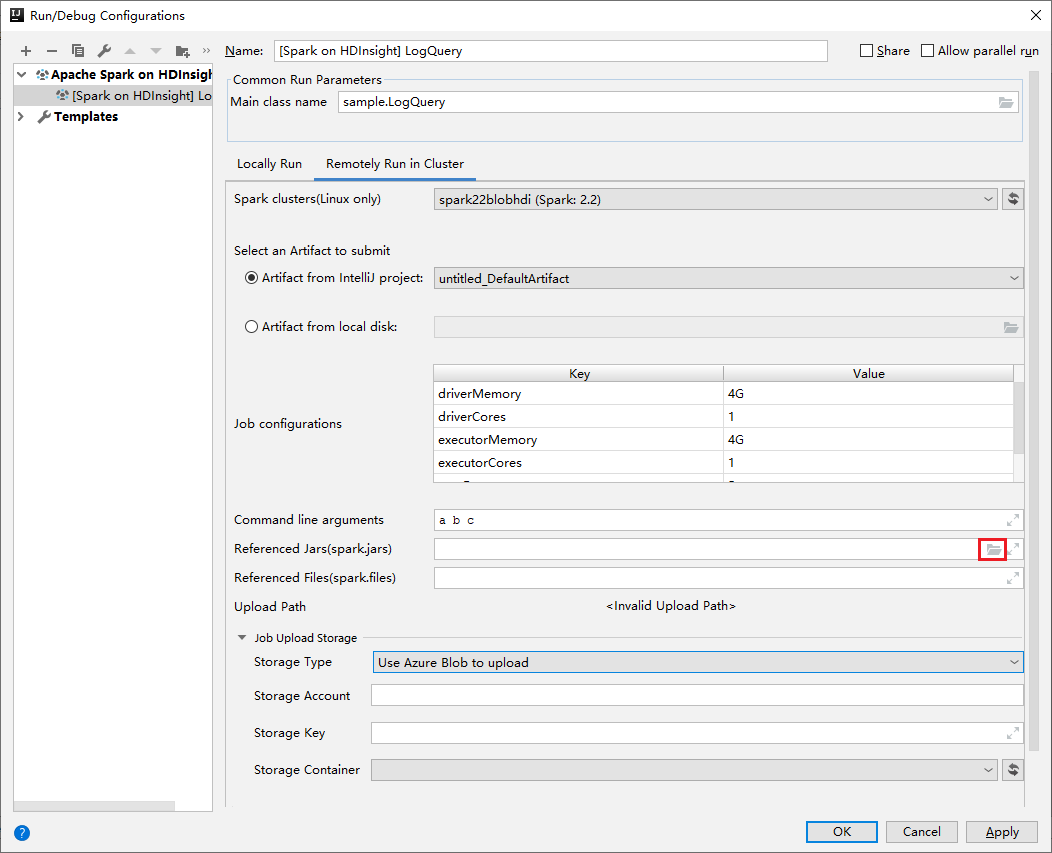
Klicken Sie auf SparkJobRun, um das Projekt an den ausgewählten Cluster zu übermitteln. Auf der Registerkarte Remote Spark Job in Cluster (Remote-Spark-Auftrag auf Cluster) wird im unteren Bereich der Fortschritt der Auftragsausführung angezeigt. Sie können die Anwendung anhalten, indem Sie auf die rote Schaltfläche klicken.
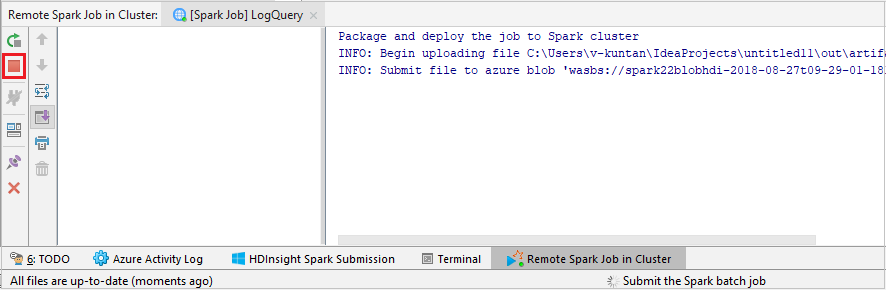
Lokales oder Remotedebuggen von Apache Spark-Anwendungen in einem HDInsight-Cluster
Es wird noch eine andere Möglichkeit der Übermittlung von Spark Anwendungen an den Cluster empfohlen. Dazu werden die Parameter in der IDE Run/Debug Configurations (Ausführen/Debugkonfigurationen) festgelegt. Weitere Informationen finden Sie unter Lokales oder Remotedebuggen von Apache Spark-Anwendungen in einem HDInsight-Cluster mit dem Azure-Toolkit für IntelliJ per SSH.
Zugreifen auf und Verwalten von HDInsight Spark-Clustern mit dem Azure-Toolkit für IntelliJ
Sie können mit dem Azure-Toolkit für IntelliJ verschiedene Vorgänge durchführen. Die meisten Vorgänge werden über den Azure Explorer gestartet. Navigieren Sie in der Menüleiste zu Ansicht>Toolfenster>Azure Explorer.
Zugreifen auf die Auftragsansicht
Navigieren Sie im Azure Explorer zu HDInsight><Ihr Cluster>>Aufträge.
Im rechten Bereich werden auf der Registerkarte Spark Job View (Spark-Auftragsansicht) alle Anwendungen angezeigt, die in dem Cluster ausgeführt wurden. Wählen Sie den Namen der Anwendung aus, zu der Sie weitere Details anzeigen möchten.
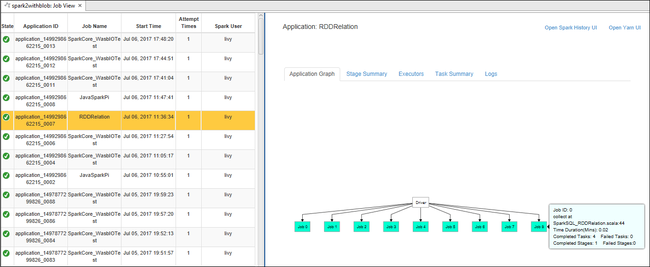
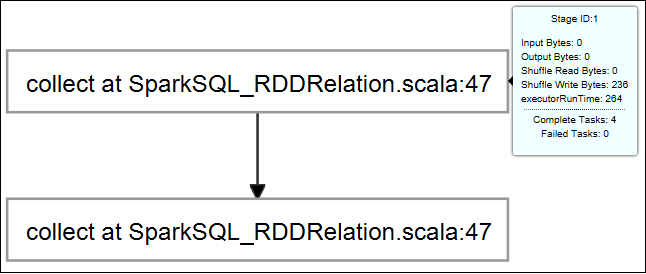
Wenn Sie grundlegende Informationen zum ausgeführten Auftrag anzeigen möchten, zeigen Sie auf das Auftragsdiagramm. Um das Phasendiagramm und von den einzelnen Aufträgen generierte Informationen anzuzeigen, wählen Sie einen Knoten im Auftragsdiagramm aus.
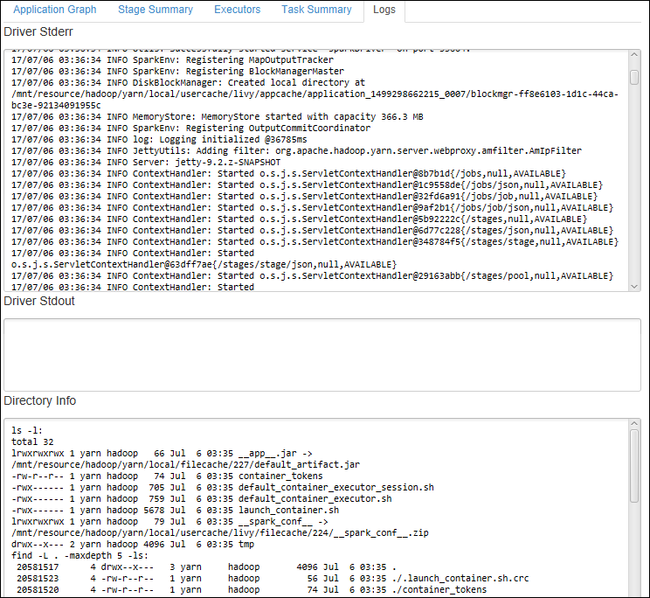
Um häufig verwendete Protokolle anzuzeigen, z.B. Driver Stderr, Driver Stdout oder Directory Info, wählen Sie die Registerkarte Log (Protokoll) aus.
Sie können die Benutzeroberfläche für den Spark-Verlauf und die YARN-Benutzeroberfläche (auf Anwendungsebene) anzeigen. Wählen Sie oben im Fenster einen Link aus.
Zugreifen auf den Spark-Verlaufsserver
Erweitern Sie im Azure Explorer die Option HDInsight, klicken Sie mit der rechten Maustaste auf den Namen Ihres Spark-Clusters, und wählen Sie dann Open Spark History UI (Spark-Verlaufsbenutzeroberfläche öffnen).
Wenn Sie dazu aufgefordert werden, geben Sie die Administratoranmeldeinformationen für den Cluster ein, die Sie beim Einrichten einer Verbindung mit dem Cluster angegeben haben.
Im Dashboard des Spark-Verlaufsservers können Sie anhand des Anwendungsnamens nach der Anwendung suchen, deren Ausführung Sie gerade beendet haben. Im obigen Code legen Sie den Namen der Anwendung mit
val conf = new SparkConf().setAppName("myApp")fest. Der Name Ihrer Spark-Anwendung lautet myApp.
Starten des Ambari-Portals
Erweitern Sie im Azure Explorer die Option HDInsight, klicken Sie mit der rechten Maustaste auf den Namen Ihres Spark-Clusters, und wählen Sie dann Open Cluster Management Portal (Ambari) (Clusterverwaltungsportal (Ambari) öffnen).
Geben Sie die Anmeldeinformationen für den Cluster ein, wenn Sie dazu aufgefordert werden. Sie haben diese Anmeldeinformationen während der Einrichtung des Clusters angegeben.
Verwalten von Azure-Abonnements
Standardmäßig werden mit dem Azure-Toolkit für IntelliJ die Spark-Cluster Ihrer gesamten Azure-Abonnements aufgelistet. Bei Bedarf können Sie die Abonnements angeben, auf die Sie zugreifen möchten.
Klicken Sie im Azure Explorer mit der rechten Maustaste auf den Hauptknoten Azure, und wählen Sie dann Abonnements auswählen aus.
Deaktivieren Sie im Fenster Abonnements auswählen die Kontrollkästchen neben den Abonnements, auf die Sie nicht zugreifen möchten, und wählen Sie dann Schließen aus.
Spark-Konsole
Sie können „Spark Local Console(Scala)“ (Lokale Spark-Konsole (Scala)) oder „Spark Livy Interactive Session Console(Scala)“ (Spark-Livy-Konsole für interaktive Sitzungen) ausführen.
Spark Local Console(Scala)
Stellen Sie sicher, dass die Voraussetzungen für „WINUTILS.EXE“ erfüllt wurden.
Navigieren Sie in der Menüleiste zu Run (Ausführen)>Edit Configurations... (Konfigurationen bearbeiten…).
Navigieren Sie im Fenster Run/Debug Configurations (Konfigurationen ausführen/debuggen) im linken Bereich zu Apache Spark on HDInsight>[Spark on HDInsight] myApp.
Wählen Sie im Hauptfenster die Registerkarte
Locally Runaus.Geben Sie die folgenden Werte an, und klicken Sie anschließend auf OK:
Eigenschaft Wert „Job main class“ (Hauptklasse des Auftrags) Der Standardwert ist die Hauptklasse der ausgewählten Datei. Sie können die Klasse ändern, indem Sie die Schaltfläche mit den Auslassungspunkten ( … ) und anschließend eine andere Klasse auswählen. Umgebungsvariablen Stellen Sie sicher, dass für HADOOP_HOME der richtige Wert festgelegt ist. „WINUTILS.exe location“ (Speicherort von „WINUTILS.exe“) Stellen Sie sicher, dass der richtige Pfad festgelegt ist. 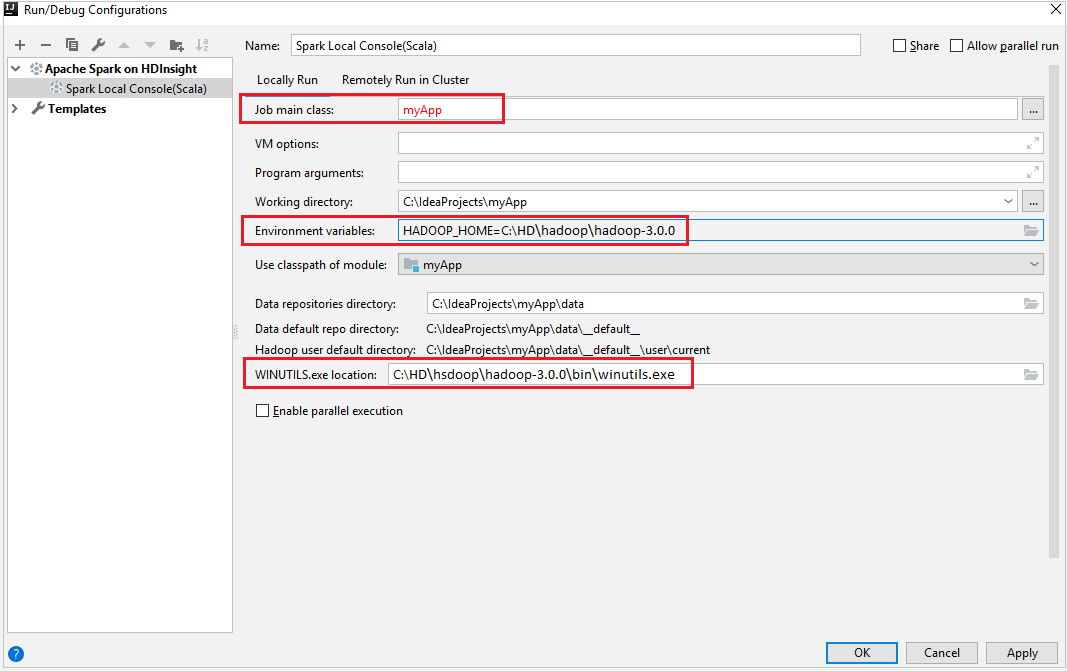
Navigieren Sie in „Project“ (Projekt) zu myApp>src>main>scala>myApp.
Navigieren Sie in der Menüleiste zu Tools>Spark Console (Spark-Konsole)>Run Spark Local Console(Scala) (Lokale Spark-Konsole ausführen (Scala)).
Zwei Dialogfelder werden möglicherweise angezeigt, in denen Sie gefragt werden, ob Probleme mit Abhängigkeiten automatisch behoben werden sollen. Klicken Sie ggf. auf Auto Fix (Automatisch beheben).
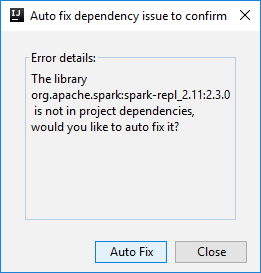
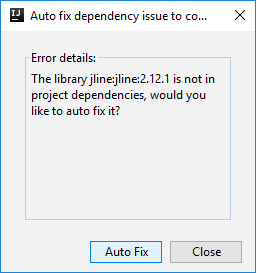
Die Konsole sollte in etwa wie auf dem folgenden Screenshot aussehen. Geben Sie im Konsolenfenster
sc.appNameein, und drücken Sie STRG+EINGABETASTE. Das Ergebnis wird angezeigt. Sie können die lokale Konsole beenden, indem Sie auf die rote Schaltfläche klicken.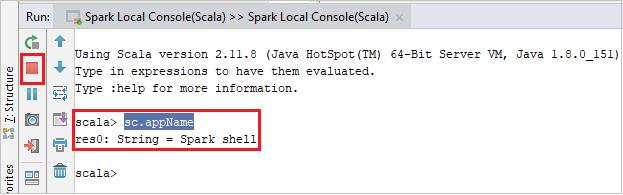
Spark Livy Interactive Session Console (Scala)
Navigieren Sie in der Menüleiste zu Run (Ausführen)>Edit Configurations... (Konfigurationen bearbeiten…).
Navigieren Sie im Fenster Run/Debug Configurations (Konfigurationen ausführen/debuggen) im linken Bereich zu Apache Spark on HDInsight>[Spark on HDInsight] myApp.
Wählen Sie im Hauptfenster die Registerkarte
Remotely Run in Clusteraus.Geben Sie die folgenden Werte an, und klicken Sie anschließend auf OK:
Eigenschaft Wert „Spark clusters (Linux only)“ (Spark-Cluster (nur Linux)) Wählen Sie den HDInsight Spark-Cluster aus, auf dem Sie Ihre Anwendung ausführen möchten. „Main class name“ (Name der Hauptklasse) Der Standardwert ist die Hauptklasse der ausgewählten Datei. Sie können die Klasse ändern, indem Sie die Schaltfläche mit den Auslassungspunkten ( … ) und anschließend eine andere Klasse auswählen. 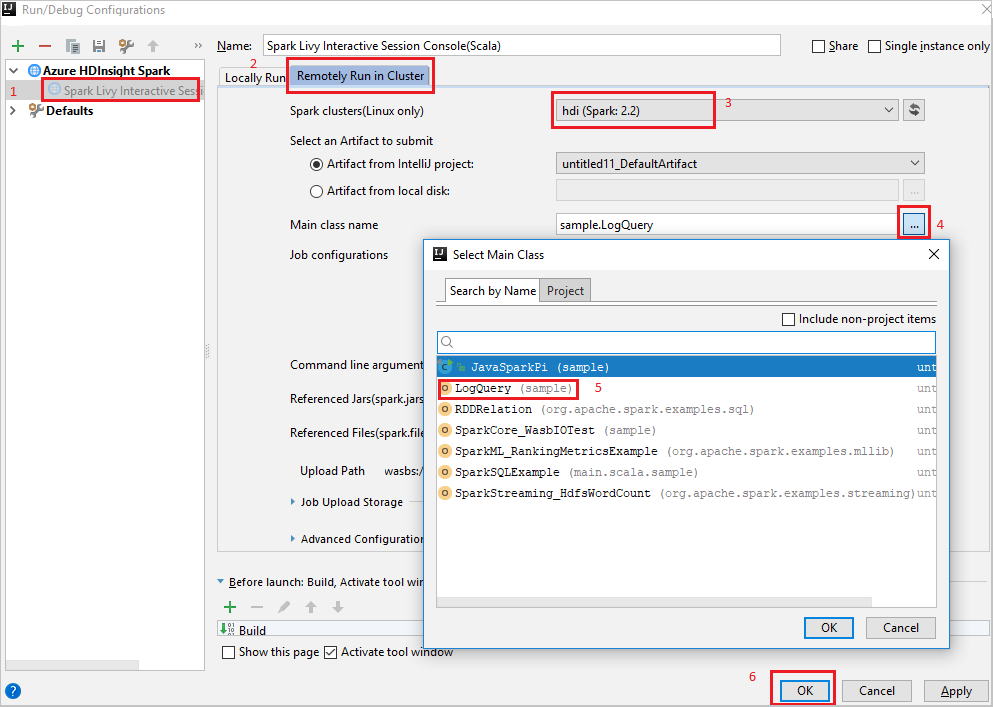
Navigieren Sie in „Project“ (Projekt) zu myApp>src>main>scala>myApp.
Navigieren Sie in der Menüleiste zu Tools>Spark Console (Spark-Konsole)>Run Spark Livy Interactive Session Console(Scala) (Spark-Livy-Konsole für interaktive Sitzungen ausführen).
Die Konsole sollte in etwa wie auf dem folgenden Screenshot aussehen. Geben Sie im Konsolenfenster
sc.appNameein, und drücken Sie STRG+EINGABETASTE. Das Ergebnis wird angezeigt. Sie können die lokale Konsole beenden, indem Sie auf die rote Schaltfläche klicken.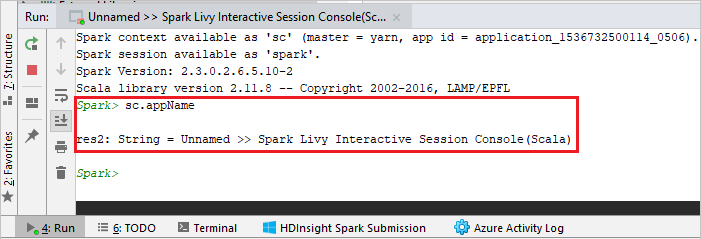
Senden einer Auswahl an die Spark-Konsole
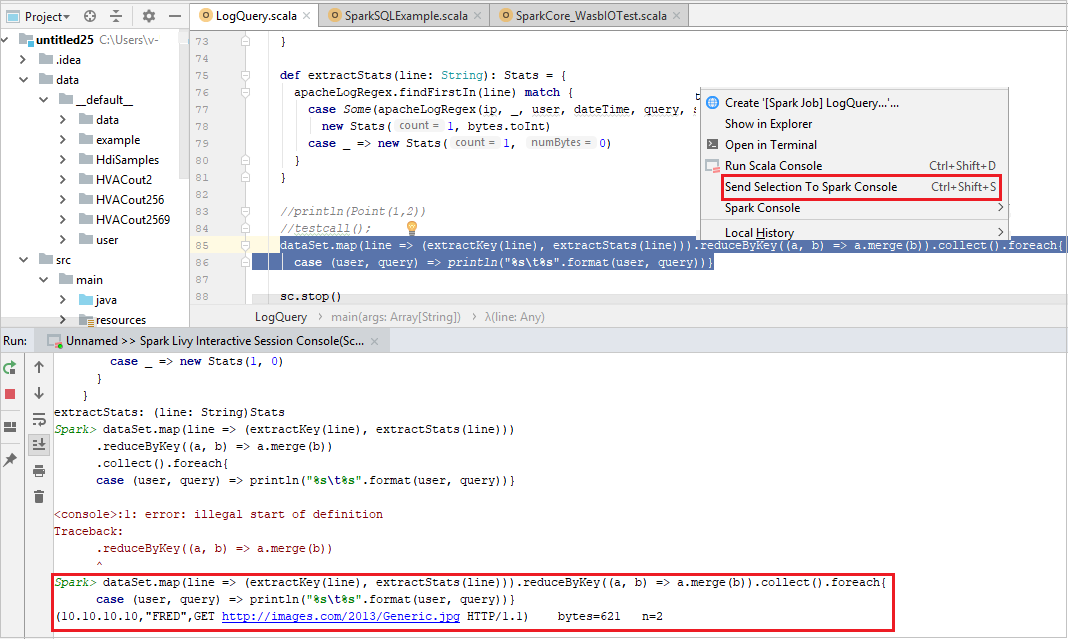
Sie können das Skriptergebnis vorhersagen, indem Sie einfach Code an die lokale Konsole oder die interaktive Livy-Sitzungskonsole (Scala) senden. Markieren Sie dazu Code in der Scala-Datei, und klicken Sie mit der rechten Maustaste auf Send Selection To Spark Console (Auswahl an Spark-Konsole senden). Der ausgewählte Code wird an die Konsole gesendet. Das Ergebnis wird nach dem Code in der Konsole angezeigt. Die Konsole überprüft, ob Fehler vorliegen.
Integrieren in den HDInsight-Identitätsbroker (HIB)
Herstellen einer Verbindung mit Ihrem HDInsight ESP-Cluster mit Identitätsbroker (HIB)
Sie können die normalen Schritte zum Anmelden beim Azure-Abonnement ausführen, um eine Verbindung mit Ihrem HDInsight ESP-Cluster mit Identitätsbroker (HIB) herzustellen. Nach der Anmeldung wird die Clusterliste im Azure Explorer angezeigt. Weitere Anweisungen finden Sie unter Herstellen einer Verbindung mit Ihrem HDInsight-Cluster.
Ausführen einer Spark-Scala-Anwendung in einem HDInsight ESP-Cluster mit Identitätsbroker (HIB)
Sie können die normalen Schritte ausführen, um einen Auftrag an einen HDInsight ESP-Cluster mit Identitätsbroker (HIB) zu übermitteln. Weitere Anweisungen finden Sie unter Ausführen einer Spark Scala-Anwendung in einem HDInsight Spark-Cluster.
Die erforderlichen Dateien werden in einen Ordner mit dem Namen Ihres Anmeldekontos hochgeladen, und Sie können den Uploadpfad in der Konfigurationsdatei sehen.

Spark-Konsole in einem HDInsight ESP-Cluster mit Identitätsbroker (HIB)
Sie können eine lokale Spark-Konsole (Scala) oder eine Spark-Konsole mit interaktiver Livy-Sitzung (Scala) in einem HDInsight ESP-Cluster mit Identitätsbroker (HIB) ausführen. Weitere Anweisungen finden Sie unter Spark-Konsole.
Hinweis
Für einen HDInsight ESP-Cluster mit Identitätsbroker (HIB) wird das Verknüpfen eines Clusters und das Remotedebuggen von Apache Spark-Anwendungen derzeit nicht unterstützt.
Rolle nur mit Leseberechtigung
Wenn Benutzer, die über eine Rolle nur mit Leseberechtigung verfügen, einen Auftrag an einen Cluster übermitteln, sind Ambari-Anmeldeinformationen erforderlich.
Kontextmenü zum Verknüpfen eines Clusters
Melden Sie sich mit einem Konto an, das über eine Rolle nur mit Leseberechtigung verfügt.
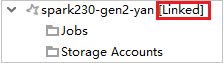
Erweitern Sie im Azure Explorer die Option HDInsight, um die HDInsight-Cluster anzuzeigen, die sich in Ihrem Abonnement befinden. Cluster mit der Kennzeichnung "Role: Reader" verfügen über eine Rolle nur mit Leseberechtigung.
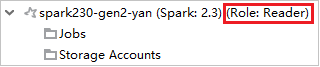
Klicken Sie mit der rechten Maustaste auf den Cluster, der über eine Rolle nur mit Leseberechtigung verfügt. Wählen Sie aus dem Kontextmenü den Eintrag Link this cluster (Diesen Cluster verknüpfen) aus, um den Cluster zu verknüpfen. Geben Sie den Benutzernamen und das Kennwort für Ambari ein.
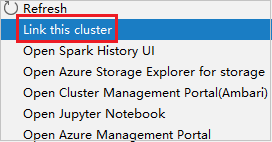
Wenn der Cluster erfolgreich verknüpft wurde, wird HDInsight aktualisiert. Der Status des Clusters ändert sich zu „Linked“ (Verknüpft).
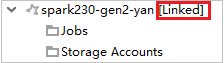
Verknüpfen eines Clusters durch Erweitern des Knotens „Jobs“ (Aufträge)
Klicken Sie auf den Knoten Jobs (Aufträge). Das Fenster Cluster Job Access Denied (Zugriff auf Clusterauftrag verweigert) wird angezeigt.
Klicken Sie auf Link this cluster (Diesen Cluster verknüpfen), um den Cluster zu verknüpfen.

Verknüpfen eines Clusters über das Fenster „Run/Debug Configurations“ (Konfigurationen ausführen/debuggen)
Erstellen Sie eine HDInsight-Konfiguration. Wählen Sie dann Remotely Run in Cluster (Im Cluster remote ausführen) aus.
Wählen Sie unter Spark clusters (Linux only) (Spark-Cluster (nur Linux)) einen Cluster aus, der über eine Rolle nur mit Leseberechtigung verfügt. Es wird eine Warnmeldung angezeigt. Sie können auf Link this cluster (Diesen Cluster verknüpfen) klicken, um den Cluster zu verknüpfen.
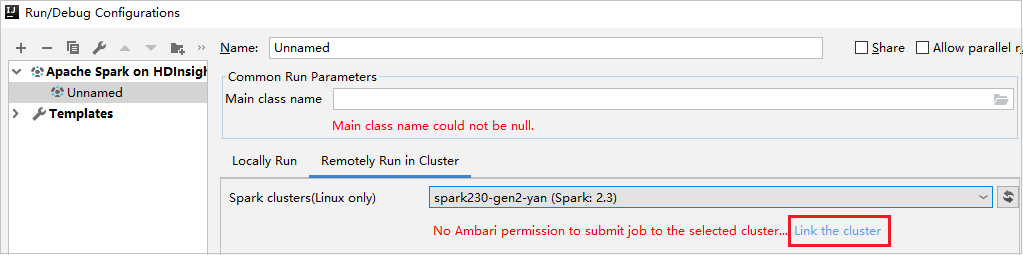
Anzeigen von Speicherkonten
Klicken Sie in einem Cluster, der über eine Rolle nur mit Leseberechtigung verfügt, auf den Knoten Storage Accounts (Speicherkonten). Das Fenster Storage Access Denied (Zugriff auf Speicher verweigert) wird angezeigt. Sie können auf Open Azure Storage Explorer (Azure Storage-Explorer öffnen) klicken, um den Storage-Explorer zu öffnen.
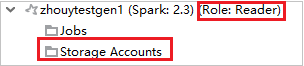

Klicken Sie in einem verknüpften Cluster auf den Knoten Storage Accounts (Speicherkonten). Das Fenster Storage Access Denied (Zugriff auf Speicher verweigert) wird angezeigt. Sie können auf Open Azure Storage (Azure Storage öffnen) klicken, um den Storage-Explorer zu öffnen.

Konvertieren vorhandener IntelliJ IDEA-Anwendungen für die Verwendung des Azure-Toolkits für IntelliJ
Sie können die vorhandenen Spark Scala-Anwendungen, die Sie in IntelliJ IDEA erstellt haben, so umwandeln, dass sie mit dem Azure-Toolkit für IntelliJ kompatibel sind. Anschließend können Sie das Plug-In verwenden, um die Anwendungen an einen HDInsight Spark-Cluster zu übermitteln.
Öffnen Sie die
.iml-Datei für eine vorhandene Spark-Scala-Anwendung, die mit IntelliJ IDEA erstellt wurde.Auf der Stammebene befindet sich ein module-Element, das dem folgenden Text ähnelt:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Fügen Sie dem Element
UniqueKey="HDInsightTool"hinzu, sodass das module-Element wie der folgende Text aussieht:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Speichern Sie die Änderungen. Ihre Anwendung sollte jetzt mit dem Azure-Toolkit für IntelliJ kompatibel sein. Sie können dies testen, indem Sie in Project mit der rechten Maustaste auf den Projektnamen klicken. Im Popupmenü ist jetzt die Option Submit Spark Application to HDInsight (Spark-Anwendung an HDInsight übermitteln) verfügbar.
Bereinigen von Ressourcen
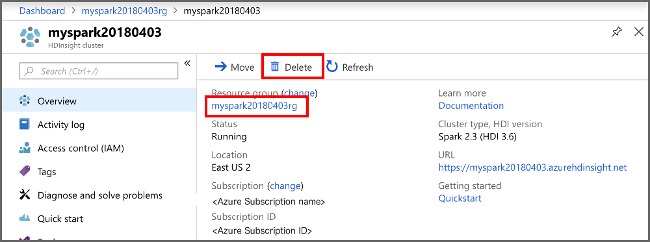
Wenn Sie diese Anwendung nicht mehr benötigen, gehen Sie wie folgt vor, um den erstellten Cluster zu löschen:
Melden Sie sich beim Azure-Portal an.
Geben Sie oben im Suchfeld den Suchbegriff HDInsight ein.
Wählen Sie unter Dienste die Option HDInsight-Cluster aus.
Klicken Sie in der daraufhin angezeigten Liste mit den HDInsight-Clustern neben dem Cluster, den Sie für diesen Artikel erstellt haben, auf die Auslassungspunkte ( ... ).
Klicken Sie auf Löschen. Wählen Sie Ja aus.
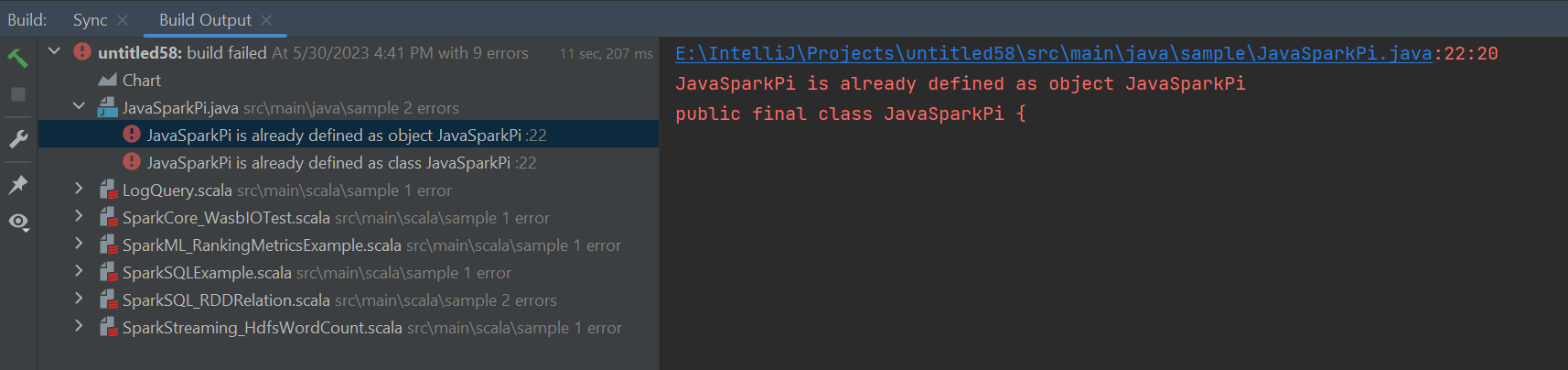
Fehler und Lösung
Heben Sie die Markierung des Ordners „src“ als Quellen auf, wenn Buildfehler wie unten angezeigt werden:
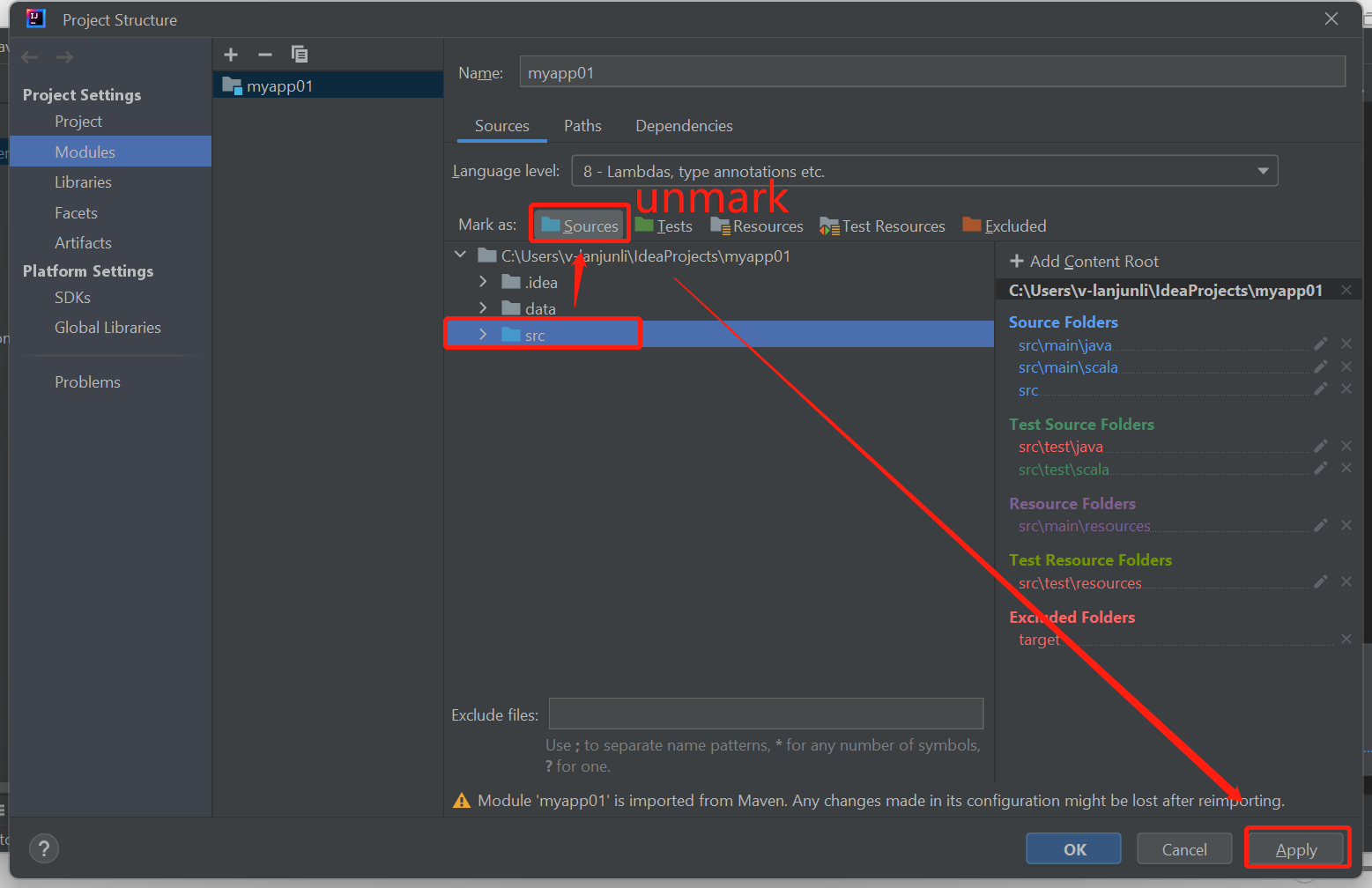
Heben Sie die Markierung des Ordners „src“ als Quellen auf, um dieses Problem zu beheben:
Navigieren Sie zu Datei, und wählen Sie Projektstruktur aus.
Wählen Sie unter „Projekteinstellungen“ die Option Module aus.
Wählen Sie die Datei src aus, und heben Sie die Markierung als Quellen auf.
Klicken Sie auf die Schaltfläche „Anwenden“ und anschließend auf die Schaltfläche „OK“, um das Dialogfeld zu schließen.
Nächste Schritte
In diesem Artikel haben Sie erfahren, wie Sie mit dem Azure-Toolkit für IntelliJ-Plug-In Apache Spark-Anwendungen entwickeln, die in Scala geschrieben werden. Anschließend haben Sie sie direkt aus der IntelliJ-IDE (Integrated Development Environment) an einen HDInsight Spark-Cluster übermittelt. Fahren Sie mit dem nächsten Artikel fort, um zu erfahren, wie die in Apache Spark registrierten Daten in ein BI-Analyse-Tool wie Power BI gezogen werden können.