Verbessern der RAG-Datenpipelinequalität
In diesem Artikel erfahren Sie, wie Sie beim Implementieren von Datenpipelineänderungen in der Praxis mit Datenpipelineoptionen experimentieren.
Wichtige Komponenten der Datenpipeline
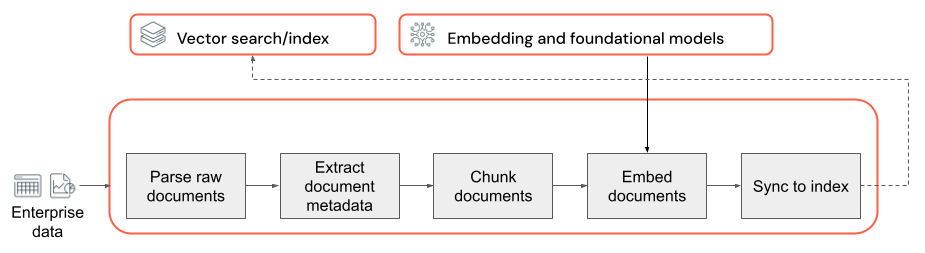
Die Grundlage jeder RAG-Anwendung mit unstrukturierten Daten ist die Datenpipeline. Diese Pipeline dient dazu, die unstrukturierten Daten in einem Format vorzubereiten, das von der RAG-Anwendung effektiv genutzt werden kann. Die Datenpipeline kann beliebig komplex werden. Im Anschluss finden Sie die wichtigsten Komponenten, die bei der Erstellung Ihrer RAG-Anwendung berücksichtigt werden müssen:
- Korpuszusammensetzung: Auswählen der richtigen Datenquellen und Inhalte basierend auf dem jeweiligen Anwendungsfall.
- Analyse: Extrahieren relevanter Informationen aus den Rohdaten mithilfe geeigneter Analysetechniken.
- Segmentierung: Aufteilen der analysierten Daten in kleinere, überschaubare Blöcke, die effizient abgerufen werden können.
- Einbettung: Konvertieren der segmentierten Textdaten in eine numerische Vektordarstellung, die ihre semantische Bedeutung erfasst.
Korpuszusammensetzung
Ohne den richtigen Datenkorpus kann Ihre RAG-Anwendung die erforderlichen Informationen für die Beantwortung einer Benutzerabfrage nicht abrufen. Die richtigen Daten hängen ganz von den spezifischen Anforderungen und Zielen Ihrer Anwendung ab. Daher ist es wichtig, sich genügend Zeit zu nehmen, um sich mit den Nuancen der verfügbaren Daten vertraut zu machen. (Informationen hierzu finden Sie im Abschnitt zur Ermittlung von Anforderungen.)
Wenn Sie beispielsweise einen Kundensupport-Bot erstellen, empfiehlt es sich gegebenenfalls, Folgendes einzubeziehen:
- Dokumente der Wissensdatenbank
- Häufig gestellte Fragen (FAQs)
- Produkthandbücher und -spezifikationen
- Leitfäden zur Problembehandlung
Binden Sie bereits in der Anfangsphase eines Projekts Domänenexperten und Projektbeteiligte ein, um relevante Inhalte zu identifizieren und zu kuratieren, die die Qualität und Abdeckung Ihres Datenkorpus verbessern können. Sie können Einblicke in die Arten von Abfragen geben, die von Benutzern voraussichtlich durchgeführt werden, und Ihnen bei der Priorisierung der wichtigsten einzuschließenden Informationen helfen.
Analyse
Nachdem Sie die Datenquellen für Ihre RAG-Anwendung identifiziert haben, müssen im nächsten Schritt die erforderlichen Informationen aus den Rohdaten extrahiert werden. Dieser als Analyse bezeichnete Prozess beinhaltet das Transformieren der unstrukturierten Daten in ein Format, das von der RAG-Anwendung effektiv genutzt werden kann.
Welche spezifischen Analysetechniken und Tools Sie dabei verwenden, hängt von der Art der Daten ab, mit denen Sie arbeiten. Zum Beispiel:
- Textdokumente (PDFs, Word-Dokumente): Standardbibliotheken wie unstructured und PyPDF2 können verschiedene Dateiformate verarbeiten und bieten Anpassungsoptionen für den Analyseprozesses.
- HTML-Dokumente: Mit HTML-Analysebibliotheken wie BeautifulSoup können relevante Inhalte aus Webseiten extrahiert werden. Sie ermöglichen es, durch die HTML-Struktur zu navigieren, bestimmte Elemente auszuwählen und den gewünschten Text oder die gewünschten Attribute zu extrahieren.
- Bilder und gescannte Dokumente: Für die Extraktion von Text aus Bildern sind üblicherweise OCR-Techniken (Optical Character Recognition; optische Zeichenerkennung) erforderlich. Beliebte OCR-Bibliotheken sind unter anderem Tesseract, Amazon Textract, Azure KI Vision OCR und Google Cloud Vision API.
Bewährte Methoden für die Datenanalyse
Berücksichtigen Sie beim Analysieren Ihrer Daten die folgenden bewährten Methoden:
- Datenbereinigung: Führen Sie für den extrahierten Text eine Vorabverarbeitung durch, um irrelevante oder störende Informationen wie Kopfzeilen, Fußzeilen oder Sonderzeichen zu entfernen. Reduzieren Sie unnötige oder nicht wohlgeformte Informationen, die von Ihrer RAG-Kette verarbeitet werden müssen.
- Behandlung von Fehlern und Ausnahmen: Implementieren Sie Fehlerbehandlungs- und Protokollierungsmechanismen, um während des Analyseprozesses aufgetretene Probleme zu identifizieren und zu beheben. Dadurch können Probleme schnell erkannt und behoben werden. Häufig werden Sie so auf vorgelagerte Probleme mit der Qualität der Quelldaten aufmerksam.
- Anpassung der Analyselogik: Je nach Struktur und Format Ihrer Daten müssen Sie ggf. die Analyselogik anpassen, um die relevantesten Informationen zu extrahieren. Dies kann zwar im Vorfeld einen zusätzlichen Aufwand bedeuten, diese Zeit ist jedoch gut investiert, da sich dadurch häufig viele nachgelagerte Qualitätsprobleme vermeiden lassen.
- Bewertung der Analysequalität: Bewerten Sie regelmäßig die Qualität der analysierten Daten durch manuelle Stichproben der Ausgabe. Dies kann Ihnen dabei helfen, Probleme oder Verbesserungspotenziale im Zusammenhang mit dem Analyseprozess zu identifizieren.
Segmentierung
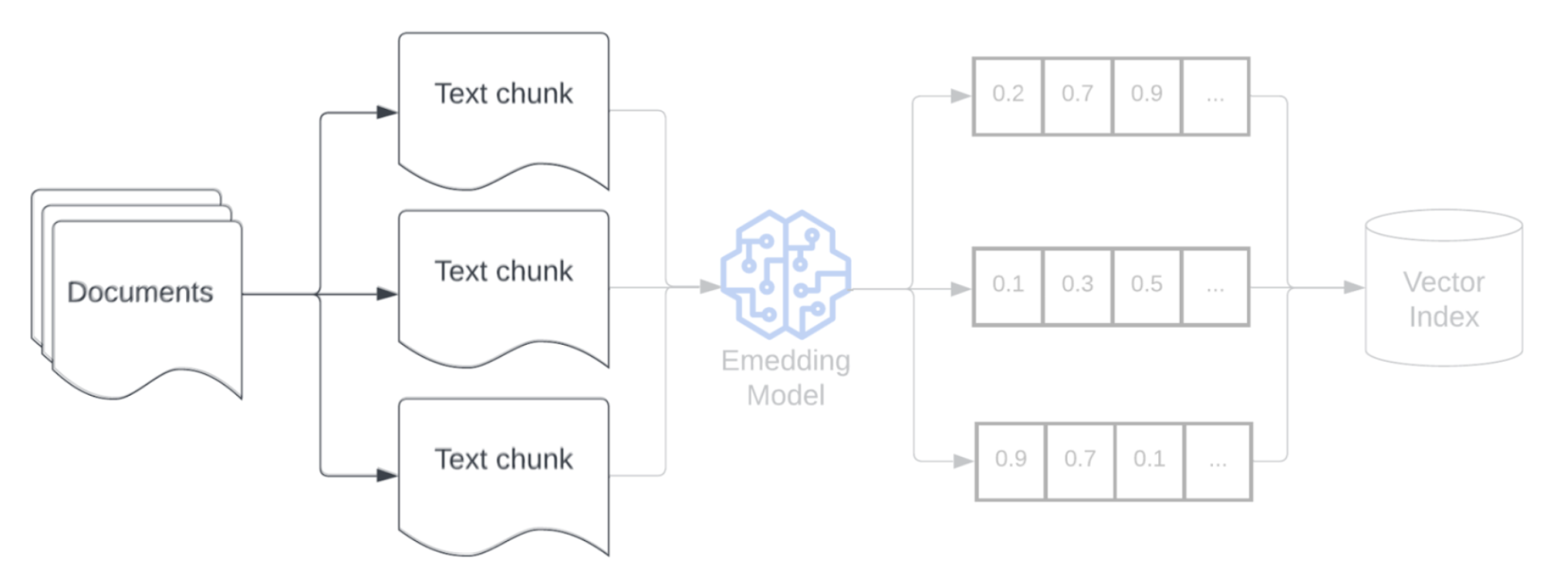
Nachdem die Rohdaten analysiert wurden, um ein strukturierteres Format zu erhalten, besteht der nächste Schritt darin, sie in kleinere, überschaubare Einheiten (sogenannte Blöcke) aufzuteilen. Durch die Segmentierung großer Dokumente in kleinere, semantisch konzentrierte Blöcke wird sichergestellt, dass abgerufene Daten in den Kontext des LLM passen, während gleichzeitig die Einbeziehung ablenkender oder irrelevanter Informationen minimiert wird. Die bei der Segmentierung getroffenen Entscheidungen wirken sich direkt darauf aus, welche abgerufenen Daten für das LLM bereitgestellt werden. Somit handelt es sich hierbei um eine der ersten Optimierungsebenen in einer RAG-Anwendung.
Berücksichtigen Sie bei der Segmentierung Ihrer Daten folgende Faktoren:
- Segmentierungsstrategie: Die Methode, mit der der ursprüngliche Text in Blöcke aufgeteilt wird. Hierzu können einfache Techniken wie die Aufteilung nach Sätzen, Absätzen oder bestimmten Zeichen-/Tokenmengen, aber auch komplexere, dokumentspezifische Aufteilungsstrategien verwendet werden.
- Blockgröße: Kleinere Blöcke konzentrieren sich eher auf bestimmte Details, dadurch gehen jedoch einige umgebende Informationen verloren. Größere Blöcke erfassen ggf. mehr Kontext, können aber auch irrelevante Informationen enthalten.
- Überlappung von Blöcken: Um sicherzustellen, dass bei der Aufteilung der Daten in Blöcke keine wichtigen Informationen verloren gehen, empfiehlt sich gegebenenfalls eine gewisse Überlappung von benachbarten Blöcken. Die Überlappung kann dafür sorgen, dass Kontinuität und Kontext über Blöcke hinweg erhalten bleiben.
- Semantische Kohärenz: Versuchen Sie nach Möglichkeit, semantisch kohärente Blöcke zu erstellen (also Blöcke, die verwandte Informationen enthalten und eine eigenständige sinnvolle Texteinheit darstellen). Berücksichtigen Sie hierzu die Struktur der ursprünglichen Daten wie Absätze, Abschnitte oder Themengrenzen.
- Metadaten: Die Integration relevanter Metadaten in den jeweiligen Block (z. B. Name des Quelldokuments, Abschnittsüberschrift oder Produktnamen) kann den Abrufvorgang verbessern. Diese zusätzlichen Informationen im Block können für den Abgleich von Abrufabfragen mit Datenblöcken hilfreich sein.
Datensegmentierungsstrategien
Die Suche nach der richtigen Segmentierungsmethode ist sowohl iterativ als auch kontextabhängig. Es gibt keine Universallösung. Die optimale Blockgröße und die optimale Segmentierungsmethode hängen vom jeweiligen Anwendungsfall und von der Art der verarbeiteten Daten ab. Ganz allgemein gibt es folgende Segmentierungsstrategien:
- Segmentierung mit fester Größe: Bei dieser Strategie wird der Text in Blöcke mit einer vordefinierten Größe aufgeteilt – also etwa mit einer festen Anzahl von Zeichen oder Token (z. B. LangChain CharacterTextSplitter). Die Aufteilung nach einer beliebigen Anzahl von Zeichen/Token ist zwar schnell und einfach einzurichten, führt aber in der Regel nicht zu konsistenten, semantisch kohärenten Blöcken.
- Absatzbasierte Segmentierung: Bei dieser Strategie werden die natürlichen Absatzgrenzen im Text verwendet, um Blöcke zu definieren. Diese Methode kann dazu beitragen, die semantische Kohärenz der Blöcke zu bewahren, da Absätze häufig verwandte Informationen enthalten (z. B. LangChain RecursiveCharacterTextSplitter).
- Formatspezifische Segmentierung: Formate wie Markdown oder HTML verfügen über eine inhärente Struktur, die zum Definieren von Blockgrenzen verwendet werden kann (z. B. Markdown-Header). Hierzu können Tools wie MarkdownHeaderTextSplitter von LangChain oder HTML-Splitter-Tools auf Basis von Header/Abschnitt verwendet werden.
- Semantische Segmentierung: Techniken wie die Themenmodellierung können angewendet werden, um semantisch kohärente Abschnitte innerhalb des Texts zu identifizieren. Diese Ansätze analysieren den Inhalt oder die Struktur der einzelnen Dokumente, um die am besten geeigneten Blockgrenzen basierend auf thematischen Veränderungen zu ermitteln. Die semantische Segmentierung ist zwar etwas aufwendiger als einfachere Ansätze, kann aber zur Erstellung semantischer Blöcke beitragen, die besser auf die natürliche semantische Aufteilung im Text abgestimmt sind. (Ein entsprechendes Beispiel finden Sie unter LangChain SemanticChunker.)
Beispiel: Blöcke mit fester Größe
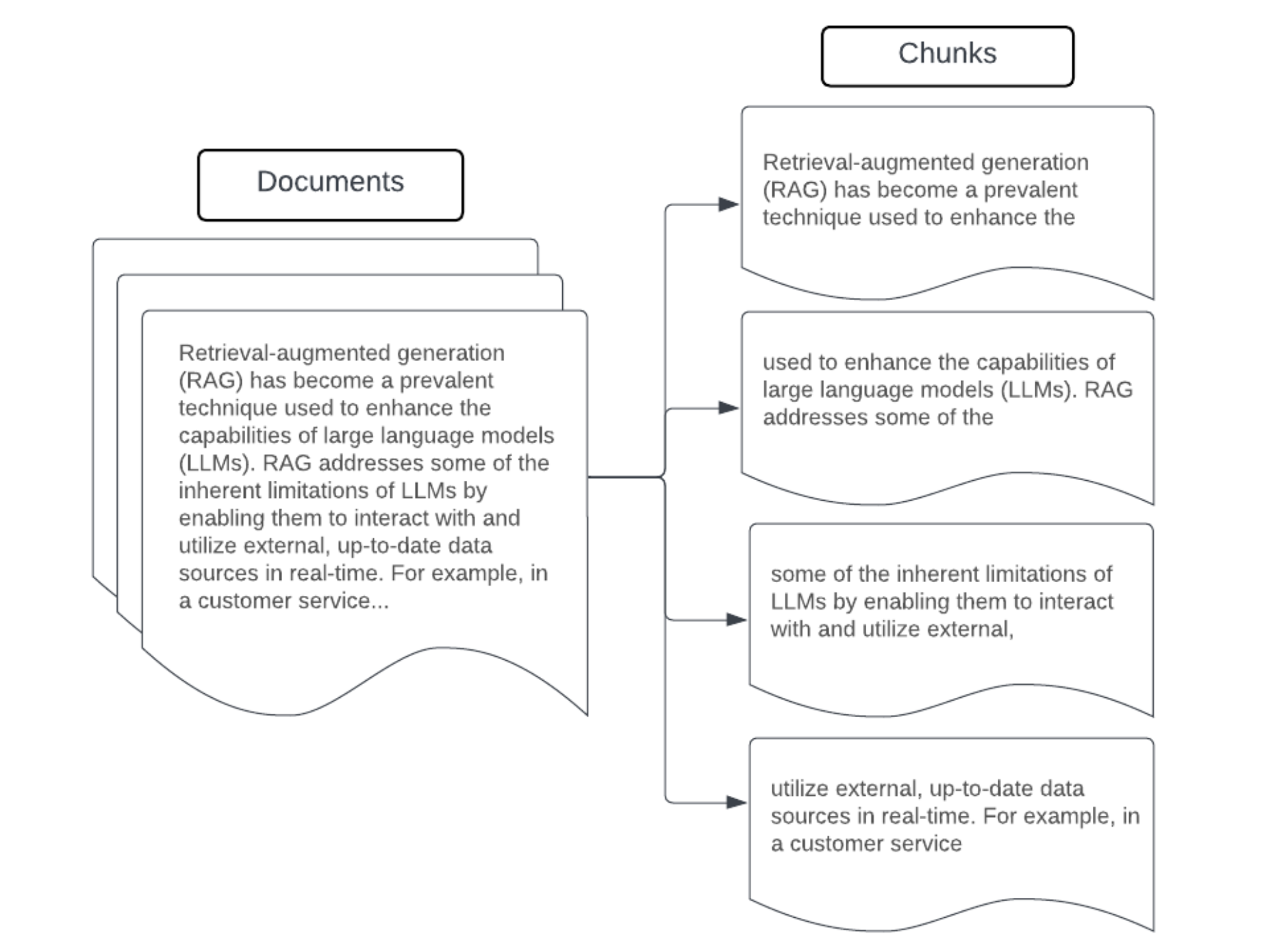
Beispiel für die Segmentierung mit RecursiveCharacterTextSplitter von LangChain mit chunk_size=100 und chunk_overlap=20. Mit ChunkViz können Sie interaktiv visualisieren, wie sich unterschiedliche Blockgrößen und Blocküberlappungswerte für die Zeichenaufteilungen von LangChain auf die resultierenden Blöcke auswirken.
Einbettungsmodell
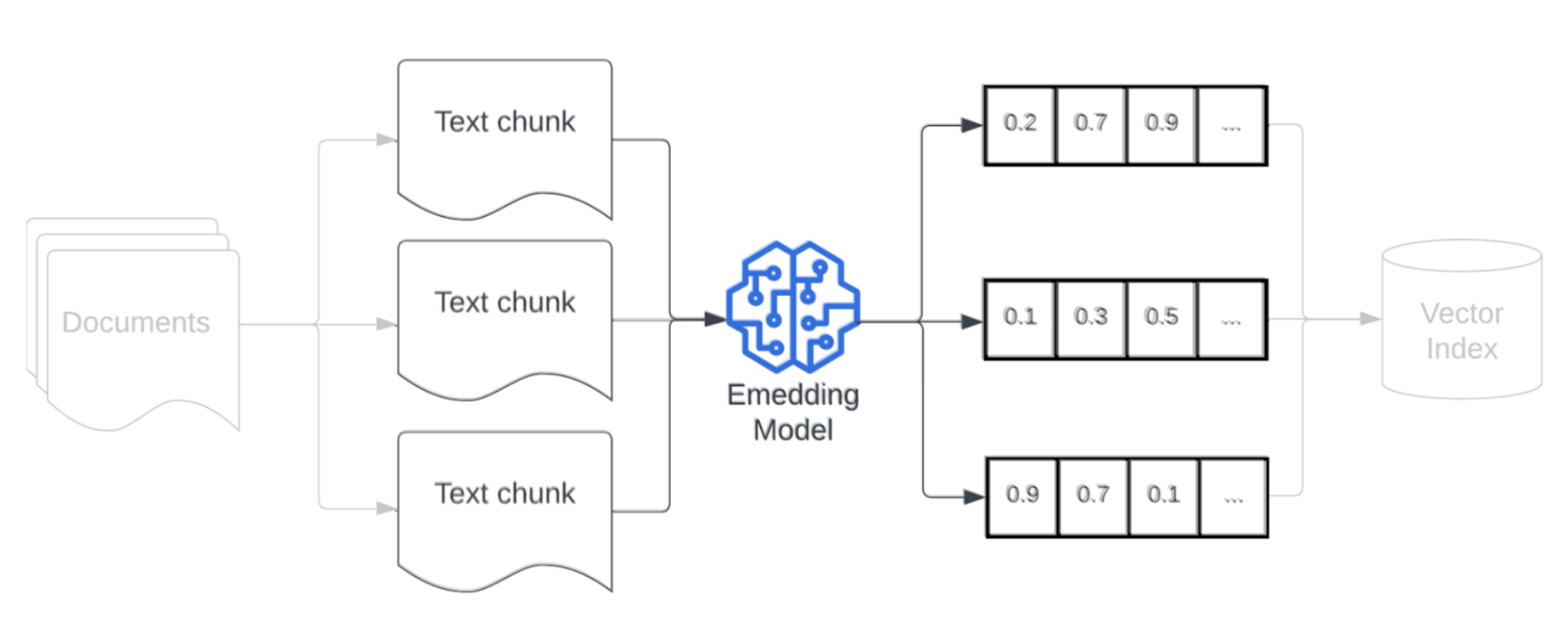
Nach der Segmentierung Ihrer Daten müssen die Textblöcke mithilfe eines Einbettungsmodells in eine Vektordarstellung konvertiert werden. Ein Einbettungsmodell wird verwendet, um die einzelnen Textblöcke in eine Vektordarstellung zu konvertieren, die die jeweilige semantische Bedeutung erfasst. Durch die Darstellung von Blöcken in Form von dichten Vektoren ermöglichen Einbettungen das schnelle und präzise Abrufen der relevantesten Blöcke, basierend auf ihrer semantischen Ähnlichkeit mit einer Abrufabfrage. Zur Abfragezeit wird die Abrufabfrage mithilfe des gleichen Einbettungsmodells transformiert, das für die Einbettung von Datenblöcken in die Datenpipeline verwendet wurde.
Berücksichtigen Sie bei der Wahl eines Einbettungsmodells folgende Faktoren:
- Wahl des Modells: Jedes Einbettungsmodell verfügt über individuelle Nuancen, und die verfügbaren Benchmarks erfassen möglicherweise nicht die spezifischen Merkmale Ihrer Daten. Experimentieren Sie mit verschiedenen Standard-Einbettungsmodellen (auch mit solchen, die ggf. auf Standardbestenlisten wie MTEB niedriger bewertet sind). Hier ein paar Beispiele:
- Maximale Tokenanzahl: Beachten Sie die Tokenobergrenze für das gewählte Einbettungsmodell. Wenn Sie Blöcke übergeben, die diesen Grenzwert überschreiten, werden sie abgeschnitten. Dadurch gehen möglicherweise wichtige Informationen verloren. Die Tokenobergrenze von bge-large-en-v1.5 liegt beispielsweise bei 512 Token.
- Modellgröße: Größere Einbettungsmodelle bieten in der Regel eine bessere Leistung, erfordern jedoch mehr Rechenressourcen. Streben Sie ein ausgewogenes Verhältnis zwischen Leistung und Effizienz unter Berücksichtigung Ihres spezifischen Anwendungsfalls und der verfügbaren Ressourcen an.
- Optimierung: Wenn Ihre RAG-Anwendung mit domänenspezifischer Sprache (z. B. unternehmensinterne Akronyme oder Terminologie) zurechtkommen muss, empfiehlt es sich, das Einbettungsmodell mit domänenspezifischen Daten zu optimieren. Dies kann dazu beitragen, dass das Modell die Feinheiten und die Terminologie Ihrer jeweiligen Domäne besser erfassen kann, und führt häufig zu einer Verbesserung der Abrufleistung.