Verbessern der RAG-Anwendungsqualität
Dieser Artikel enthält eine Übersicht über die Optimierung der einzelnen Komponenten, um die Qualität Ihrer RAG-Anwendung (Retrieval Augmented Generation) zu steigern.
Sowohl für die Offlinedatenpipeline als auch für die Online-RAG-Kette gibt es unzählige Optimierungsmöglichkeiten. Dieser Artikel konzentriert sich jedoch auf die wichtigsten Optionen, die die größten Auswirkungen auf die Qualität Ihrer RAG-Anwendung haben. Databricks empfiehlt, mit diesen Optionen zu beginnen.
Zwei Arten von Qualitätsüberlegungen
Aus konzeptioneller Sicht ist es hilfreich, bei der Betrachtung der RAG-Qualitätsoptionen die beiden wichtigsten Qualitätsaspekte zugrunde zu legen:
Abrufqualität: Werden die relevantesten Informationen für eine bestimmte Abrufabfrage abgerufen?
Es ist schwer, eine qualitativ hochwertige RAG-Ausgabe zu generieren, wenn im Kontext, der für das LLM bereitgestellt wird, wichtige Informationen fehlen oder überflüssige Informationen enthalten sind.
Generierungsqualität: Generiert das LLM auf der Grundlage der abgerufenen Informationen und der ursprünglichen Benutzerabfrage eine möglichst präzise, schlüssige und hilfreiche Antwort?
Probleme können in Form von Halluzinationen oder inkonsistenten Ausgaben auftreten oder dazu führen, dass die Benutzerabfrage nicht direkt beantwortet wird.
RAG-Apps verfügen über zwei Komponenten, die durchlaufen werden können, um Qualitätsprobleme zu bewältigen: die Datenpipeline und die Kette. Gerne würde man von einer klaren Trennung zwischen Abrufproblemen und Generierungsproblemen ausgehen, die sich durch einfaches Aktualisieren der Datenpipeline bzw. durch Aktualisieren der RAG-Kette beheben lassen. Die Realität ist jedoch etwas komplexer. Die Abrufqualität kann sowohl durch die Datenpipeline beeinflusst werden (z. B. Analyse-/Segmentierungsstrategie, Metadatenstrategie, Einbettungsmodell) als auch durch die RAG-Kette (z. B. Benutzerabfragetransformation, Anzahl abgerufener Blöcke, Neubewertung). Analog dazu wird die Generierungsqualität durch eine schlechte Abrufqualität beeinträchtigt (z. B. irrelevante oder fehlende Informationen, die sich auf die Modellausgabe auswirken).
Diese Überschneidung unterstreicht die Notwendigkeit eines ganzheitlichen Ansatzes zur Verbesserung der RAG-Qualität. Wenn Sie verstehen, welche Komponenten sowohl in der Datenpipeline als auch in der RAG-Kette geändert werden müssen und wie sich diese Änderungen auf die Gesamtlösung auswirken, können Sie gezielte Aktualisierungen vornehmen, um die RAG-Ausgabequalität zu verbessern.
Qualitätsüberlegungen im Zusammenhang mit der Datenpipeline
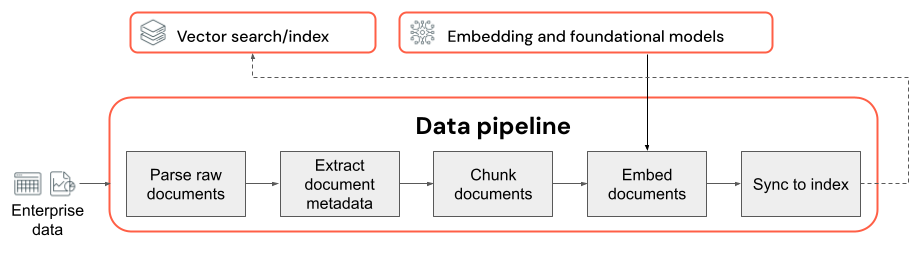
Wichtige Überlegungen im Zusammenhang mit der Datenpipeline:
- Die Zusammensetzung der Eingabedaten.
- Die Art, wie Rohdaten extrahiert und in ein verwendbares Format umgewandelt werden (z. B. Analyse eines PDF-Dokuments).
- Die Art, wie Dokumente in kleinere Blöcke aufgeteilt und diese Blöcke formatiert werden (z. B. Segmentierungsstrategie und Blockgröße).
- Die Metadaten (z. B. Abschnittstitel oder Dokumenttitel), die für die einzelnen Dokumente und/oder Blöcke extrahiert werden. Die Art, wie diese Metadaten in die einzelnen Abschnitte eingeschlossen (oder nicht eingeschlossen) werden.
- Das Einbettungsmodell, das zum Konvertieren von Text in Vektordarstellungen für die Ähnlichkeitssuche verwendet wird.
RAG-Kette
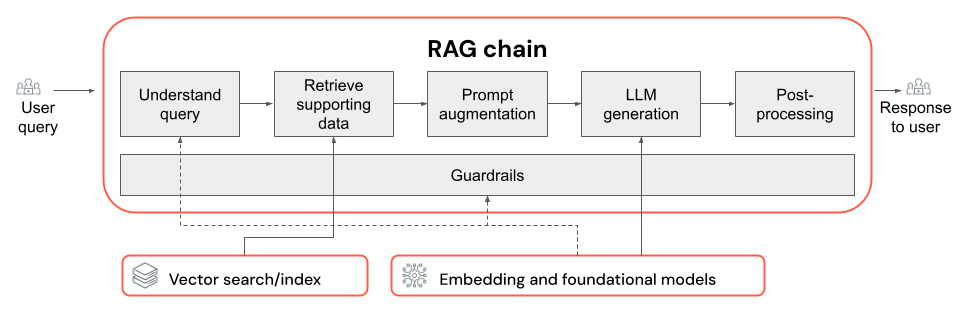
- Die Wahl des LLM und der zugehörigen Parameter (z. B. Temperatur und maximal zulässige Tokenanzahl).
- Die Abrufparameter (z. B. die Anzahl abgerufener Blöcke oder Dokumente).
- Der Abrufansatz (z. B. Schlüsselwortsuche, Hybridsuche oder semantische Suche, Umschreibung der Benutzerabfrage, Transformierung von Benutzerabfragen in Filter oder Neubewertung).
- Art der Formatierung des Prompts mit dem abgerufenen Kontext, um eine qualitativ hochwertige LLM-Ausgabe zu erhalten.