Verbessern der RAG-Kettenqualität
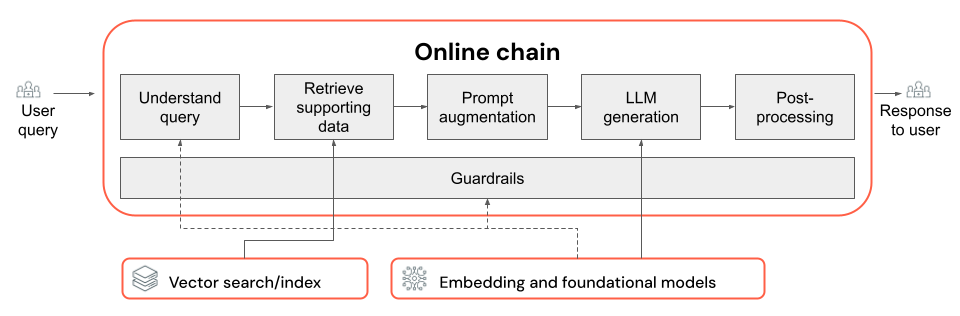
In diesem Artikel erfahren Sie, wie Sie die Qualität der RAG-App mithilfe von Komponenten der RAG-Kette verbessern können.
Die RAG-Kette verwendet eine Benutzerabfrage als Eingabe, ruft relevante Informationen im Zusammenhang mit dieser Abfrage ab und generiert eine entsprechende Antwort, die auf den abgerufenen Daten basiert. Die genauen Schritte innerhalb einer RAG-Kette können zwar je nach Anwendungsfall und Anforderungen stark variieren, folgende wichtige Komponenten müssen jedoch bei der Erstellung einer RAG-Kette berücksichtigt werden:
- Abfrageverständnis: Analysieren und Transformieren von Benutzerabfragen, um die Absicht besser darzustellen und relevante Informationen wie Filter oder Schlüsselwörter zu extrahieren, um den Abrufvorgang zu verbessern.
- Abruf: Suchen nach den relevantesten Informationen im Zusammenhang mit einer Abrufabfrage. Im Falle von unstrukturierten Daten umfasst dies in der Regel eine semantische oder schlüsselwortbasierte Suche oder eine Kombination von beidem.
- Prompt-Erweiterung: Kombinieren einer Benutzerabfrage mit abgerufenen Informationen und Anweisungen, um das LLM bei der Generierung qualitativ hochwertiger Antworten zu unterstützen.
- LLM: Auswählen des am besten geeigneten Modells (und der am besten geeigneten Modellparameter) für Ihre Anwendung, um Leistung, Wartezeit und Kosten zu optimieren bzw. auszubalancieren.
- Nachbearbeitung und Schutzmaßnahmen: Ausführen zusätzlicher Verarbeitungsschritte und Anwenden von Sicherheitsmaßnahmen, um sicherzustellen, dass die LLM-generierten Antworten themenbezogen und sachlich konsistent sind und spezifische Richtlinien oder Einschränkungen einhalten.
Unter Iteratives Implementieren und Auswerten von Qualitätskorrekturen erfahren Sie, wie Sie die Komponenten einer Kette durchlaufen.
Abfrageverständnis
Manche Benutzerabfragen können ggf. direkt als Abrufabfrage verwendet werden. In der Regel empfiehlt es sich jedoch, die Abfrage vor dem Abrufschritt umzuformulieren. Das Abfrageverständnis umfasst mindestens einen Schritt am Anfang einer Kette, der dazu dient, Benutzerabfragen zu analysieren und zu transformieren, um Absichten besser darzustellen, relevante Informationen zu extrahieren und letztendlich den nachfolgenden Abrufprozess zu unterstützen. Für die Transformierung einer Benutzerabfrage zur Verbesserung des Abrufs gibt es mehrere Herangehensweisen:
Umschreiben der Abfrage: Beim Umschreiben der Abfrage wird eine Benutzerabfrage in eine oder mehrere Abfragen übersetzt, die die ursprüngliche Absicht besser darstellen. Das dient dazu, die Abfrage so umzuformulieren, dass sich die Wahrscheinlichkeit dafür erhöht, dass im Abrufschritt die relevantesten Dokumente gefunden werden. Dies kann besonders bei komplexen oder mehrdeutigen Abfragen hilfreich sein, die möglicherweise nicht direkt der Terminologie entsprechen, die in den Abrufdokumenten verwendet wird.
Beispiele:
- Umschreiben des Unterhaltungsverlaufs in einem mehrteiligen Chat
- Korrigieren von Rechtschreibfehlern in der Abfrage des Benutzers
- Ersetzen von Wörtern oder Ausdrücken in der Benutzerabfrage durch Synonyme, um ein breiteres Spektrum relevanter Dokumente zu erfassen
Wichtig
Die Abfrageumschreibung muss mit Änderungen an der Abrufkomponente einhergehen.
Filterextraktion: Manche Benutzerabfragen enthalten bestimmte Filter oder Kriterien, die zur Eingrenzung der Suchergebnisse verwendet werden können. Die Filterextraktion umfasst das Identifizieren und Extrahieren dieser Filter aus der Abfrage und das Übergeben an den Abrufschritt als zusätzliche Parameter. Dies kann dazu beitragen, die Relevanz der abgerufenen Dokumente zu verbessern, indem der Fokus auf bestimmte Teilmengen der verfügbaren Daten gelenkt wird.
Beispiele:
- Extrahieren bestimmter Zeiträume, die in der Abfrage erwähnt werden (z. B. „Artikel aus den letzten sechs Monaten“ oder „Berichte aus dem Jahr 2023“)
- Identifizieren von Erwähnungen bestimmter Produkte, Dienste oder Kategorien in der Abfrage (z. B. „Databricks Professional Services“ oder „Laptops“)
- Extrahieren geografischer Entitäten aus der Abfrage (z. B. Ortsnamen oder Ländercodes)
Hinweis
Die Filterextraktion muss in Verbindung mit Änderungen an der Datenpipeline und der Retriever-Kette der Metadatenextraktion durchgeführt werden. Der Metadatenextraktionsschritt soll sicherstellen, dass die relevanten Metadatenfelder für jedes Dokument bzw. für jeden Block verfügbar sind, und der Abrufschritt muss implementiert werden, um extrahierte Filter zu akzeptieren und anzuwenden.
Neben Abfrageumschreibung und Filterextraktion ist eine weitere wichtige Frage beim Abfrageverständnis, ob ein einzelner LLM-Aufruf verwendet werden soll oder ob mehrere Aufrufe verwendet werden sollen. Bei einem sorgfältig erstellten Prompt kann die Verwendung eines einzelnen Aufrufs durchaus effizient sein, es gibt jedoch Fälle, in denen die Aufteilung des Abfrageverständnisprozesses auf mehrere LLM-Aufrufe zu besseren Ergebnissen führt. Das gilt übrigens immer, wenn Sie versuchen, eine Reihe komplexer Logikschritte in einem einzelnen Prompt zu implementieren.
Sie können z. B. einen LLM-Aufruf verwenden, um die Abfrageabsicht zu klassifizieren, einen weiteren, um relevante Entitäten zu extrahieren, und einen dritten, um die Abfrage basierend auf den extrahierten Informationen umzuschreiben. Dieser Ansatz führt zwar ggf. zu einer gewissen Wartezeit für den gesamten Prozess, ermöglicht aber unter Umständen eine präzisere Steuerung und kann potenziell die Qualität der abgerufenen Dokumente verbessern.
Mehrstufiges Abfrageverständnis für einen Support-Bot
Hier sehen Sie, wie eine mehrstufige Abfrageverständniskomponente beispielsweise nach einem Kundensupport-Bot sucht:
- Absichtsklassifizierung: Verwenden Sie ein LLM, um die Abfrage des Benutzers anhand von vordefinierten Kategorien wie „Produktinformationen“, „Problembehandlung“ oder „Kontoverwaltung“ zu klassifizieren.
- Entitätsextraktion: Verwenden Sie basierend auf der identifizierten Absicht einen weiteren LLM-Aufruf, um relevante Entitäten wie Produktnamen, gemeldete Fehler oder Kontonummern aus der Abfrage zu extrahieren.
- Abfrageumschreibung: Verwenden Sie die extrahierten Absichten und Entitäten, um die ursprüngliche Abfrage in ein spezifischeres und zielgerichteteres Format umzuschreiben. Beispiel: „Meine RAG-Kette wird bei der Modellbereitstellung nicht bereitgestellt, und mir wird der folgende Fehler angezeigt…“.
Abrufen
Die Abrufkomponente der RAG-Kette dient dazu, die relevantesten Informationen im Zusammenhang mit einer Abrufabfrage zu finden. Im Kontext unstrukturierter Daten umfasst der Abruf in der Regel eine semantische Suche, eine schlüsselwortbasierte Suche oder eine Metadatenfilterung bzw. eine Kombination davon. Die Wahl der Abrufstrategie hängt von den spezifischen Anforderungen Ihrer Anwendung, der Art der Daten und den Arten von Abfragen ab, die Sie erwarten. Im Anschluss folgt ein Vergleich dieser Optionen:
- Semantische Suche: Bei der semantischen Suche wird ein Einbettungsmodell verwendet, um die einzelnen Textblöcke in eine Vektordarstellung zu konvertieren, die die jeweilige semantische Bedeutung erfasst. Durch den Vergleich der Vektordarstellung der Abrufabfrage mit den Vektordarstellungen der Blöcke kann die semantische Suche konzeptionell ähnliche Dokumente abrufen, auch wenn sie nicht die genauen Schlüsselwörter aus der Abfrage enthalten.
- Schlüsselwortbasierte Suche: Bei der schlüsselwortbasierten Suche wird zur Bestimmung der Relevanz von Dokumenten die Häufigkeit und Verteilung von Wörtern analysiert, die sowohl in der Abrufabfrage als auch in den indizierten Dokumenten vorkommen. Je häufiger die gleichen Wörter sowohl in der Abfrage als auch in einem Dokument vorkommen, desto höher ist die Relevanzbewertung, die dem entsprechenden Dokument zugewiesen wird.
- Hybridsuche: Bei der Hybridsuche werden im Rahmen eines zweistufigen Abrufprozesses die Vorteile der semantischen Suche mit den Vorteilen der schlüsselwortbasierten Suche kombiniert. Zuerst wird eine semantische Suche durchgeführt, um eine Gruppe konzeptionell relevanter Dokumente abzurufen. Anschließend wird eine schlüsselwortbasierte Suche auf diese reduzierte Gruppe angewendet, um die Ergebnisse basierend auf exakten Schlüsselwortübereinstimmungen weiter einzugrenzen. Abschließend werden die Ergebnisse aus beiden Schritten miteinander kombiniert, um den Dokumenten jeweils einen Rang zuzuweisen.
Vergleich von Abrufstrategien
In der folgenden Tabelle werden die einzelnen Abrufstrategien miteinander verglichen:
| Semantische Suche | Stichwortsuche | Hybridsuche | |
|---|---|---|---|
| Einfache Erläuterung | Wenn in der Abfrage und in einem potenziellen Dokument die gleichen Konzepte vorkommen, sind sie relevant. | Wenn in der Abfrage und in einem potenziellen Dokument die gleichen Wörter vorkommen, sind sie relevant. Je mehr Wörter aus der Abfrage im Dokument vorkommen, desto relevanter ist dieses Dokument. | Führt SOWOHL eine semantische Suche ALS AUCH eine Schlüsselwortsuche durch und kombiniert anschließend die Ergebnisse. |
| Exemplarischer Anwendungsfall | Kundensupport, bei dem Benutzerabfragen nicht den in den Produkthandbüchern verwendeten Wörtern entsprechen. Beispiel: „Wie schalte ich mein Telefon ein?“, wenn der Abschnitt im Handbuch „Ein- und Ausschalten“ heißt. | Kundensupport, bei dem Abfragen bestimmte, nicht beschreibende technische Begriffe enthalten. Beispiel: „Wie funktioniert das Modell HD7-8D?“ | Kundensupportabfragen, die sowohl semantische als auch technische Begriffe enthalten. Beispiel: „Wie schalte ich mein HD7-8D ein?“ |
| Technische Ansätze | Verwendet Einbettungen, um Text in einem fortlaufenden Vektorbereich darzustellen und die semantische Suche zu ermöglichen. | Nutzt diskrete tokenbasierte Methoden wie bag-of-words, TF-IDF und BM25 für den Schlüsselwortabgleich. | Verwendet einen Neubewertungsansatz, um die Ergebnisse miteinander zu kombinieren – z. B. eine reziproke Rangfusion oder ein Neubewertungsmodell. |
| Strengths | Abrufen von Informationen mit ähnlichem Kontext für eine Abfrage, auch wenn nicht die exakten Wörter verwendet werden | Szenarien, die exakte Schlüsselwortübereinstimmungen erfordern (ideal für spezifische begriffsorientierte Abfragen – beispielsweise für Produktnamen). | Kombiniert die Vorteile beider Ansätze. |
Verbesserungsmöglichkeiten für den Abrufvorgang
Neben diesen zentralen Abrufstrategien gibt es mehrere zentrale Techniken, mit denen Sie den Abrufprozess noch weiter verbessern können:
- Abfrageerweiterung: Die Erweiterung von Abfragen kann dazu beitragen, mithilfe mehrerer Variationen der Abrufabfrage ein breiteres Spektrum relevanter Dokumente zu erfassen. Hierzu können entweder einzelne Suchvorgänge für jede erweiterte Abfrage durchgeführt oder alle erweiterten Suchabfragen in einer einzelnen Abrufabfrage verkettet werden.
Hinweis
Die Abfrageerweiterung muss in Verbindung mit Änderungen an der Abfrageverständniskomponente (RAG-Chain) durchgeführt werden. Die verschiedenen Variationen einer Abrufabfrage werden üblicherweise in diesem Schritt generiert.
- Neubewertung: Wenden Sie nach dem Abrufen einer anfänglichen Gruppe von Blöcken zusätzliche Bewertungskriterien (z. B. eine Sortierung nach Zeit) oder ein Neubewertungsmodell an, um die Ergebnisse neu zu sortieren. Eine Neubewertung kann bei der Priorisierung der relevantesten Blöcke im Zusammenhang mit einer bestimmten Abrufabfrage hilfreich sein. Eine Neubewertung mit Encoder-übergreifenden Modellen wie mxbai-rerank und ColBERTv2 kann zu einer Verbesserung der Abrufleistung beitragen.
- Metadatenfilterung: Verwenden Sie Metadatenfilter, die aus dem Abfrageverständnisschritt extrahiert wurden, um den Suchbereich basierend auf bestimmten Kriterien einzugrenzen. Metadatenfilter können Attribute wie Dokumenttyp, Erstellungsdatum, Autor oder domänenspezifische Tags enthalten. Durch die Kombination von Metadatenfiltern mit semantischer oder schlüsselwortbasierter Suche können Sie gezieltere und effizientere Abrufe erstellen.
Hinweis
Die Metadatenfilterung muss zusammen mit Änderungen am Abfrageverständnis (RAG-Kette) und an der Metadatenextraktion (Datenpipeline) durchgeführt werden.
Prompt-Erweiterung
Bei der Prompt-Erweiterung wird die Benutzerabfrage mit den abgerufenen Informationen und Anweisungen in einer Prompt-Vorlage kombiniert, um das Sprachmodell bei der Generierung qualitativ hochwertiger Antworten zu unterstützen. Das Durchlaufen dieser Vorlage zur Optimierung des für das LLM bereitgestellten Prompts (Prompt Engineering) ist erforderlich, um sicherzustellen, dass das Modell korrekte, fundierte und schlüssige Antworten generiert.
Es gibt umfangreiche Prompt Engineering-Anleitungen. Hier nur ein paar Aspekte, die beim Durchlaufen der Prompt-Vorlage beachtet werden sollten:
- Bereitstellen von Beispielen
- Schließen Sie Beispiele für wohlgeformte Abfragen und die entsprechenden idealen Antworten in die Prompt-Vorlage ein (Few-Shot Learning). Dies hilft dem Modell, das gewünschte Format, den gewünschten Stil und den gewünschten Inhalt der Antworten zu verstehen.
- Gute Beispiele erhalten Sie, indem Sie Arten von Abfragen identifizieren, die ihrer Kette Probleme bereiten. Erstellen Sie optimale Antworten für diese Abfragen, und fügen Sie sie als Beispiele in den Prompt ein.
- Stellen Sie sicher, dass die von Ihnen bereitgestellten Beispiele repräsentativ für Benutzerabfragen sind, die Sie zur Rückschlusszeit erwarten. Versuchen Sie, ein breites Spektrum an erwarteten Abfragen abzudecken, um die Generalisierung des Modells zu verbessern.
- Parametrisieren der Prompt-Vorlage
- Gestalten Sie Ihre Prompt-Vorlage flexibel, indem Sie sie parametrisieren, um zusätzliche Informationen zu integrieren, die über die abgerufenen Daten und die Benutzerabfrage hinausgehen. Das können beispielsweise Variablen wie das aktuelle Datum, der Benutzerkontext oder andere relevante Metadaten sein.
- Das Einfügen dieser Variablen in den Prompt zur Rückschlusszeit ermöglicht stärker personalisierte oder kontextbezogene Antworten.
- Erwägen der Verwendung einer Prompt-Gedankenkette
- Bei komplexen Abfragen, bei denen direkte Antworten nicht ohne Weiteres erkennbar sind, empfiehlt sich ggf. die Verwendung einer Prompt-Gedankenkette. Bei dieser Prompt Engineering-Strategie werden komplizierte Fragen in einfachere, sequenzielle Schritte aufgeteilt, die das LLM durch einen logischen Denkprozess leiten.
- Indem Sie das Modell dazu bringen, das Problem Schritt für Schritt zu „durchdenken“, kann es detailliertere und fundiertere Antworten liefern. Dies kann insbesondere bei der Behandlung mehrstufiger oder offener Abfragen effektiv sein.
- Prompts sind unter Umständen nicht auf andere Modelle übertragbar.
- Bedenken Sie, dass Prompts häufig nicht nahtlos auf verschiedene Sprachmodelle übertragbar sind. Jedes Modell hat seine Eigenheiten. Das führt dazu, dass ein Prompt, der für ein bestimmtes Modell gut geeignet ist, bei einem anderen Modell möglicherweise nicht so effektiv ist.
- Experimentieren Sie mit verschiedenen Eingabeaufforderungsformaten und Längen, lesen Sie Onlinehandbücher (z. B. OpenAI Cookbook oder Anthropic Cookbook), und bereiten Sie sich darauf vor, Ihre Eingabeaufforderungen beim Wechseln zwischen Modellen anzupassen und zu verfeinern.
LLM
Die Generierungskomponente der RAG-Kette übergibt die erweiterte Prompt-Vorlage aus dem vorherigen Schritt an ein LLM. Berücksichtigen Sie bei der Wahl und Optimierung eines LLM für die Generierungskomponente einer RAG-Kette die folgenden Faktoren, die gleichermaßen für alle anderen Schritte gelten, die LLM-Aufrufe beinhalten:
- Experimentieren Sie mit verschiedenen Standardmodellen.
- Jedes Modell hat individuelle Eigenschaften, Stärken und Schwächen. Einige Modelle bieten möglicherweise ein besseres Verständnis in bestimmten Bereichen oder sind für bestimmte Aufgaben besser geeignet.
- Denken Sie wie bereits erwähnt daran, dass die Wahl des Modells auch den Prompt Engineering-Prozess beeinflussen kann, da unterschiedliche Modelle auf die gleichen Prompts möglicherweise unterschiedlich reagieren.
- Wenn mehrere Schritte in Ihrer Kette ein LLM erfordern (z. B. Aufrufe zum Abfrageverständnis zusätzlich zum Generierungsschritt), empfiehlt es sich gegebenenfalls, unterschiedliche Modelle für unterschiedliche Schritte verwenden. Teurere, universellere Modelle sind für Aufgaben wie etwa die Bestimmung der Absicht einer Benutzerabfrage ggf. übertrieben.
- Fangen Sie klein an, und skalieren Sie nach Bedarf.
- Es kann zwar verlockend sein, sofort zu den leistungsstärksten und fähigsten Modellen wie GPT-4 oder Claude zu greifen, häufig ist es jedoch effizienter, mit kleineren, einfacheren Modellen zu beginnen.
- In vielen Fällen können kleinere Open-Source-Alternativen wie Llama 3 oder DBRX zufriedenstellende Ergebnisse zu geringeren Kosten und mit schnelleren Rückschlüssen liefern. Diese Modelle können besonders bei Aufgaben effektiv sein, die keine hochkomplexen Denkvorgänge und kein umfassendes Weltwissen erfordern.
- Bewerten Sie im Zuge der Entwicklung und Optimierung Ihrer RAG-Kette kontinuierlich die Leistung und Einschränkungen Ihres gewählten Modells. Sollten Sie feststellen, dass das Modell mit bestimmten Arten von Abfragen Probleme hat oder Antworten liefert, die nicht detailliert oder präzise genug sind, erwägen Sie die Skalierung auf ein leistungsfähigeres Modell.
- Überwachen Sie die Auswirkungen von Modellwechseln auf wichtige Metriken wie Antwortqualität, Wartezeit und Kosten, um sicherzustellen, dass Sie die richtige Balance für die Anforderungen Ihres spezifischen Anwendungsfalls erzielen.
- Optimieren von Modellparametern
- Experimentieren Sie mit verschiedenen Parametereinstellungen, um das optimale Gleichgewicht zwischen Antwortqualität, Vielfalt und Kohärenz zu finden. Beispielsweise kann eine Anpassung der Temperatur die Zufälligkeit des generierten Texts steuern, während „max_tokens“ die Antwortlänge einschränken kann.
- Beachten Sie, dass die optimalen Parametereinstellungen abhängig vom spezifischen Vorgang sowie abhängig vom Prompt und vom gewünschten Ausgabestil variieren können. Testen und optimieren Sie diese Einstellungen basierend auf der Auswertung der generierten Antworten.
- Aufgabenspezifische Optimierung
- Bei der Leistungsoptimierung empfiehlt es sich gegebenenfalls, kleinere Modelle für bestimmte Unteraufgaben innerhalb Ihrer RAG-Kette zu optimieren – etwa das Abfrageverständnis.
- Indem Sie spezielle Modelle für einzelne Aufgaben mit der RAG-Kette trainieren, können Sie potenziell die Gesamtleistung verbessern, die Wartezeit verkürzen und die Rückschlusskosten senken (verglichen mit der Verwendung eines einzelnen großen Modells für alle Aufgaben).
- Fortlaufendes Vorabtraining
- Wenn Ihre RAG-Anwendung mit einem spezialisierten Bereich zu tun hat oder Kenntnisse erfordert, die in dem vorab trainierten LLM nicht angemessen dargestellt sind, empfiehlt es sich gegebenenfalls, ein fortlaufendes Vorabtraining (Continued Pre-Training, CPT) für bereichsspezifische Daten durchzuführen.
- Fortlaufendes Vorabtraining kann dazu beitragen, das Verständnis spezifischer Terminologie oder spezifischer Konzepte für Ihren Bereich zu verbessern. Dies kann wiederum dazu führen, dass kein umfangreiches Prompt Engineering erforderlich ist oder weniger Few-Shot-Beispiele benötigt werden.
Nachbearbeitung und Schutzmaßnahmen
Nachdem das LLM eine Antwort generiert hat, ist es häufig erforderlich, Nachbearbeitungstechniken oder Schutzmaßnahmen anzuwenden, um sicherzustellen, dass die Ausgabe die gewünschten Format-, Stil- und Inhaltsanforderungen erfüllt. Dieser letzte Schritt in der Kette, der auch mehrere Einzelschritte umfassen kann, kann dazu beitragen, die Konsistenz und Qualität der generierten Antworten zu gewährleisten. Wenn Sie eine Nachbearbeitung und Schutzmaßnahmen implementieren, sollten Sie einige der folgenden Punkte berücksichtigen:
- Erzwingen eines Ausgabeformats
- Je nach Anwendungsfall müssen die generierten Antworten unter Umständen einem bestimmten Format entsprechen – etwa einer strukturierten Vorlage oder einem bestimmten Dateityp (z. B. JSON, HTML, Markdown usw.).
- Wenn eine strukturierte Ausgabe erforderlich ist, stellen Bibliotheken wie Instructor oder Outlines einen guten Ausgangspunkt dar, um diese Art von Überprüfungsschritt zu implementieren.
- Nehmen Sie sich bei der Entwicklung genug Zeit, um sicherzustellen, dass der Nachbearbeitungsschritt flexibel genug ist, um Variationen in den generierten Antworten zu behandeln und dabei das erforderliche Format beizubehalten.
- Sicherstellen eines konsistenten Stils
- Wenn Ihre RAG-Anwendung spezifische Stilrichtlinien oder Tonanforderungen hat (z. B. formal oder ungezwungen, knapp oder ausführlich), kann ein Nachbearbeitungsschritt diese Stilattribute über generierte Antworten hinweg sowohl überprüfen als auch erzwingen.
- Inhaltsfilter und Sicherheitsmaßnahmen
- Je nach Art Ihrer RAG-Anwendung und den potenziellen Risiken, die mit den generierten Inhalten verbunden sind, kann es wichtig sein, Inhaltsfilter oder Sicherheitsmaßnahmen zu implementieren, um die Ausgabe unangemessener, anstößiger oder schädlicher Informationen zu verhindern.
- Erwägen Sie die Verwendung von Modellen wie Llama Guard oder von APIs, die speziell für die Inhaltsmoderation und -sicherheit entwickelt wurden (z. B. die Moderations-API von OpenAI), um Sicherheitsmaßnahmen zu implementieren.
- Behandeln von Halluzinationen
- Der Schutz vor Halluzinationen kann ebenfalls als Nachbearbeitungsschritt implementiert werden. Hierzu können die generierten Ausgaben mit abgerufenen Dokumenten abgeglichen oder zusätzliche LLMs verwendet werden, um die sachliche Genauigkeit der Antworten zu überprüfen.
- Entwickeln Sie Fallbackmechanismen, um Fälle zu behandeln, in denen die generierte Antwort die Anforderungen an die sachliche Genauigkeit nicht erfüllt – z. B. die Generierung alternativer Antworten oder die Bereitstellung von Haftungsausschlüssen für den Benutzer.
- Fehlerbehandlung
- Implementieren Sie bei allen Nachbearbeitungsschritten Mechanismen für den ordnungsgemäßen Umgang mit Fällen, in denen ein Problem auftritt oder keine zufriedenstellende Antwort generiert wird. Beispiele wären etwa die Generierung einer Standardantwort oder eine Eskalation des Problems zur manuellen Überprüfung durch einen menschlichen Operator.