Voraussetzung: Ermitteln von Anforderungen
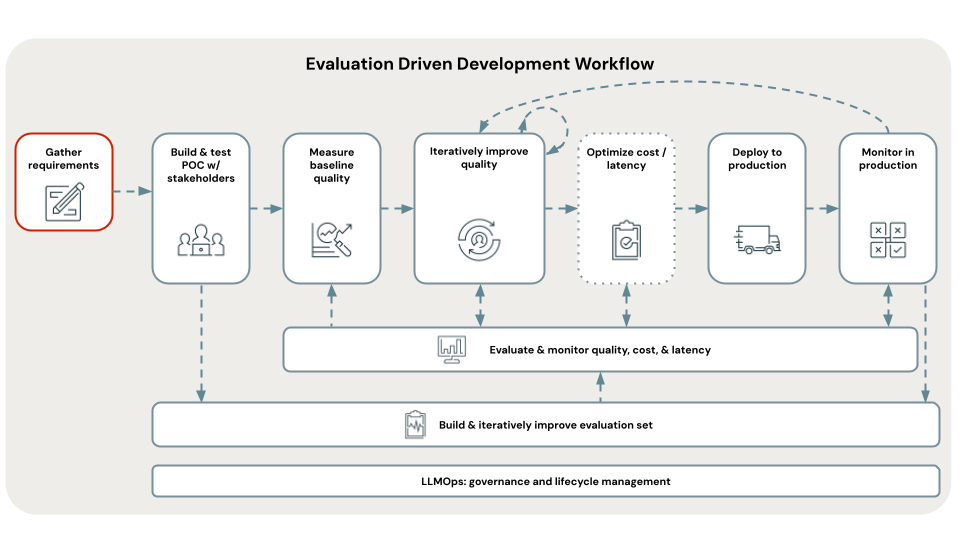
Das Definieren klarer und umfassender Anforderungen für einen Anwendungsfall ist ein wichtiger erster Schritt für die Entwicklung einer erfolgreichen RAG-Anwendung. Diese Anforderungen haben in erster Linie zwei Zwecke: Sie helfen dabei, zu ermitteln, ob RAG der am besten geeignete Ansatz für den jeweiligen Anwendungsfall ist. Ist dies der Fall, dienen diese Anforderungen als Grundlage für Entscheidungen rund um den Lösungsentwurf, die Implementierung und die Auswertung. Durch die Investition von Zeit zu Beginn eines Projekts, um detaillierte Anforderungen zu ermitteln, können Sie größere Herausforderungen und Rückschläge im weiteren Verlauf des Entwicklungsprozesses vermeiden und sicherstellen, dass die resultierende Lösung den Anforderungen von Endbenutzern und Projektbeteiligten entspricht. Gut definierte Anforderungen bilden die Grundlage für die nachfolgenden Phasen des Entwicklungslebenszyklus, die wir hier durchlaufen.
Den Beispielcode aus diesem Abschnitt finden Sie in diesem GitHub-Repository. Sie können den Repositorycode auch als Vorlage verwenden, mit der Sie eigene KI-Anwendungen erstellen können.
Eignet sich der Anwendungsfall gut für RAG?
Ermitteln Sie zunächst, ob RAG der richtige Ansatz für Ihren Anwendungsfall ist. Angesichts des RAG-Hypes ist man versucht, RAG als mögliche Lösung für jedes Problem zu betrachten. Ob RAG geeignet ist, hängt jedoch von gewissen Nuancen ab.
RAG ist in folgenden Fällen gut geeignet:
- Wenn abgerufene Informationen (ob strukturiert oder unstrukturiert) untersucht werden, die nicht vollständig in das Kontextfenster des LLM passen
- Wenn Informationen aus mehreren Quellen synthetisiert werden (beispielsweise beim Generieren einer Zusammenfassung der wichtigsten Punkte aus verschiedenen Artikeln zu einem Thema)
- Wenn Daten dynamisch auf der Grundlage einer Benutzerabfrage abgerufen werden (z. B., um auf der Grundlage einer Benutzerabfrage zu bestimmen, aus welcher Datenquelle Daten abgerufen werden sollen)
- Wenn der Anwendungsfall die Generierung neuer Inhalte auf der Grundlage abgerufener Informationen erfordert (z. B. zur Beantwortung von Fragen oder zur Bereitstellung von Erklärungen oder Empfehlungen)
In folgenden Fällen ist RAG unter Umständen keine optimale Lösung:
- Wenn für die Aufgabe kein abfragespezifischer Abruf erforderlich ist. Beispiel: Generieren von Zusammenfassungen für Anrufaufzeichnungen. Selbst wenn einzelne Transkripte im LLM-Prompt als Kontext bereitgestellt werden, bleiben die abgerufenen Informationen bei jeder Zusammenfassung gleich.
- Wenn die gesamten abzurufenden Informationen in das Kontextfenster des LLM passen
- Wenn Antworten mit besonders kurzer Wartezeit erforderlich sind (etwa, wenn Antworten in Millisekunden benötigt werden)
- Wenn einfache regel- oder vorlagenbasierte Antworten ausreichen (z. B. ein Kundensupport-Chatbot, der vordefinierte Antworten basierend auf Schlüsselwörtern bereitstellt)
Zu ermittelnde Anforderungen
Wenn Sie zu dem Schluss gekommen sind, dass RAG für Ihren Anwendungsfall geeignet ist, sollten Sie die folgenden Fragen berücksichtigen, um konkrete Anforderungen zu erfassen. Die Anforderungen werden wie folgt priorisiert:
🟢 P0: Diese Anforderung muss vor POC-Beginn definiert werden.
🟡 P1: Diese Anforderung muss vor Beginn der Produktion definiert werden, kann aber während der POC-Phase nach und nach optimiert werden.
⚪ P2: Optionale Anforderung.
Diese Liste mit Fragen ist nicht vollständig. Sie soll jedoch eine solide Grundlage für die Erfassung der wichtigsten Anforderungen für Ihre RAG-Lösung bieten.
Benutzerfreundlichkeit
Definieren Sie, wie Benutzer mit dem RAG-System interagieren und welche Art von Antworten erwartet werden.
🟢 [P0] Wie sieht eine typische Anforderung an die RAG-Kette aus? Bitten Sie Projektbeteiligte um Beispiele für potenzielle Benutzerabfragen.
🟢 [P0] Welche Art von Antworten erwarten Benutzer (kurze Antworten, ausführliche Erklärungen, eine Kombination aus beidem oder etwas anderes)?
🟡 [P1] Wie interagieren Benutzer mit dem System? Über eine Chatoberfläche, über eine Suchleiste oder auf andere Weise?
🟡 [P1] Welchen Ton oder Stil sollen die generierten Antworten haben (formal, interaktiv, technisch)?
🟡 [P1] Wie soll die Anwendung mit mehrdeutigen, unvollständigen oder irrelevanten Abfragen verfahren? Soll in solchen Fällen eine Art von Feedback oder Anleitung bereitgestellt werden?
⚪ [P2] Gibt es spezifische Formatierungs- oder Präsentationsanforderungen für die generierte Ausgabe? Soll die Ausgabe neben der Antwort der Kette noch irgendwelche Metadaten enthalten?
Daten
Bestimmen Sie die Art, die Quellen und die Qualität der Daten, die in der RAG-Lösung verwendet werden.
🟢 [P0] Welche verfügbaren Quellen sollen verwendet werden?
Bestimmen Sie für jede Datenquelle Folgendes:
- 🟢 [P0] Sind die Daten strukturiert oder unstrukturiert?
- 🟢 [P0] Welches Quellformat haben die Abrufdaten (z. B. PDFs, Dokumentation mit Bildern/Tabellen, strukturierte API-Antworten)?
- 🟢 [P0] Wo befinden sich diese Daten?
- 🟢 [P0] Wie viele Daten sind verfügbar?
- 🟡 [P1] Wie häufig werden die Daten aktualisiert? Wie sollen diese Aktualisierungen behandelt werden?
- 🟡 [P1] Gibt es bekannte Probleme mit der Datenqualität oder Inkonsistenzen für die jeweilige Datenquelle?
Erwägen Sie die Erstellung einer Bestandstabelle, um diese Informationen zu konsolidieren. Beispiel:
| Datenquelle | Quelle | Dateitypen | Size | Aktualisierungshäufigkeit |
|---|---|---|---|---|
| Datenquelle 1 | Unity Catalog-Volume | JSON | 10GB | Täglich |
| Datenquelle 2 | Öffentliche API | XML | -- (API) | Echtzeit |
| Datenquelle 3 | SharePoint | PDF, DOCX | 500 MB | Monatlich |
Leistungseinschränkungen
Erfassen Sie die Leistungs- und Ressourcenanforderungen für die RAG-Anwendung.
🟡 [P1] Was ist die maximal akzeptable Wartezeit für die Antwortgenerierung?
🟡 [P1] Was ist die maximal zulässige Zeit bis zum ersten Token?
🟡 [P1] Ist eine höhere Gesamtwartezeit akzeptabel, wenn die Ausgabe gestreamt wird?
🟡 [P1] Gibt es Kostenbeschränkungen für Computeressourcen, die für Rückschlüsse verfügbar sind?
🟡 [P1] Was sind die erwarteten Nutzungsmuster und Spitzenlasten?
🟡 [P1] Wie viele gleichzeitige Benutzer oder Anforderungen muss das System bewältigen können? Databricks kann solche Skalierbarkeitsanforderungen dank automatischer Skalierung mit der Modellbereitstellung nativ bewältigen.
Auswertung
Legen Sie fest, wie die RAG-Lösung im Laufe der Zeit ausgewertet und verbessert wird.
🟢 [P0] Welches Geschäftsziel bzw. welchen KPI möchten Sie beeinflussen? Was ist der Ausgangs- und was der Zielwert?
🟢 [P0] Welche Benutzer oder Projektbeteiligten geben anfängliches und fortlaufendes Feedback?
🟢 [P0] Welche Metriken sollen verwendet werden, um die Qualität der generierten Antworten zu bewerten? Auswertung von Mosaic AI Agents stellt einen empfohlenen Satz von Metriken bereit.
🟡 [P1] Mit welchen Fragen muss die RAG-App gut zurechtkommen, um für die Produktion bereit zu sein?
🟡 [P1] Ist ein [Auswertungssatz] vorhanden? Ist es möglich, einen Auswertungssatz mit Benutzerabfragen zusammen mit Grundwahrheitsantworten und (optional) mit den korrekten unterstützenden Dokumenten zu erhalten, die abgerufen werden sollen?
🟡 [P1] Wie wird Benutzerfeedback gesammelt und in das System integriert?
Sicherheit
Identifizieren Sie ggf. Überlegungen zu Sicherheit und Datenschutz.
🟢 [P0] Gibt es sensible/vertrauliche Daten, die mit besonderer Vorsicht behandelt werden müssen?
🟡 [P1] Müssen in der Lösung Zugriffssteuerungen implementiert werden, sodass beispielsweise ein bestimmter Benutzer nur Daten aus einer eingeschränkten Gruppe von Dokumenten abrufen kann?
Bereitstellung
Ermitteln Sie, wie die RAG-Lösung integriert, bereitgestellt und verwaltet wird.
🟡 Wie soll die RAG-Lösung in vorhandene Systeme und Workflows integriert werden?
🟡 Wie soll das Modell bereitgestellt, skaliert und versioniert werden? In diesem Tutorial erfahren Sie, wie der End-to-End-Lebenszyklus in Databricks mithilfe von MLflow, Unity Catalog, Agent SDK und Modellbereitstellung behandelt werden kann.
Beispiel
Das folgende Beispiel veranschaulicht diese Fragen anhand einer RAG-Beispielanwendung, die von einem Databricks-Kundensupportteam verwendet wird:
| Bereich | Überlegungen | Anforderungen |
|---|---|---|
| Benutzerfreundlichkeit | – Interaktionsmodalität. – Beispiele für typische Benutzerabfragen. – Erwartetes Antwortformat und erwarteter Stil. – Umgang mit mehrdeutigen oder irrelevanten Abfragen. |
– In Slack integrierte Chatoberfläche. – Beispielabfragen: „Wie kann ich den Start des Clusters beschleunigen?“ „Welche Art von Supportplan habe ich?“ – Klare, technische Antworten mit Codeschnipseln und ggf. Links zu relevanten Dokumentationen. – Bereitstellung kontextbezogener Vorschläge und bei Bedarf Eskalation an Supporttechniker. |
| Daten | – Anzahl und Typ der Datenquellen. – Datenformat und Speicherort. – Datengröße und Aktualisierungshäufigkeit. – Datenqualität und -konsistenz. |
– Drei Datenquellen. – Unternehmensdokumentation (HTML, PDF). – Gelöste Supporttickets (JSON). – Beiträge im Communityforum (Delta-Tabelle). – In Unity Catalog gespeicherte und wöchentlich aktualisierte Daten. – Gesamtgröße der Daten: 5 GB. – Konsistente Datenstruktur und Gewährleistung der Qualität durch engagierte Dokumentations- und Supportteams. |
| Leistung | – Maximal akzeptable Wartezeit. – Kosteneinschränkungen. – Erwartete Nutzung und Parallelität. |
– Maximale Wartezeitanforderung. – Kosteneinschränkungen. – Erwartete Spitzenlast. |
| Auswertung | – Dataset-Verfügbarkeit für Auswertung. – Qualitätsmetriken. – Sammlung von Benutzerfeedback. |
– Fachliche Ansprechpartner aus jedem Produktbereich helfen bei der Überprüfung der Ausgaben und passen falsche Antworten an, um das Auswertungsdatenset zu erstellen. – Geschäftliche KPIs. – Erhöhung der Rate gelöster Supporttickets. – Verringerung des Benutzerzeitaufwands pro Supportticket. – Qualitätsmetriken. – Vom LLM bewertete Korrektheit und Relevanz der Antworten. – Einschätzung der Abrufgenauigkeit durch das LLM. – Benutzerseitige Zustimmung oder Ablehnung. – Sammlung von Feedback. – Instrumentierung von Slack, um eine positive oder negative Bewertung bereitzustellen. |
| Sicherheit | – Behandlung vertraulicher Daten. – Voraussetzungen für die Zugriffssteuerung. |
– Die Abrufquelle darf keine vertraulichen Kundendaten enthalten. – Benutzerauthentifizierung über Databricks Community-SSO. |
| Bereitstellung | – Integration in bereits vorhandene Systeme. – Bereitstellung und Versionsverwaltung. |
– Integration in das Supportticketsystem. – Bereitstellung der Kette als Endpunkt für die Databricks-Modellbereitstellung. |
Nächster Schritt
Beginnen Sie mit Schritt 1. Klonen des Coderepositorys und Erstellen von Compute.
< Zurück: Auswertungsgesteuerte Entwicklung
Weiter: Schritt 1. Klonen von Repositorys und Erstellen von Compute >