Leistungstipps für das Azure Cosmos DB-Python SDK
GILT FÜR: ![]() NoSQL
NoSQL
Wichtig
Die Leistungstipps in diesem Artikel gelten nur für das Azure Cosmos DB-Python SDK. Weitere Informationen finden Sie in den Ressourcen für das Azure Cosmos DB Python-SDK: Infodatei, Versionshinweise, Paket (PyPI), Paket (Conda) und Leitfaden zur Problembehandlung.
Azure Cosmos DB ist eine schnelle und flexible verteilte Datenbank mit nahtloser Skalierung, garantierter Latenz und garantiertem Durchsatz. Die Skalierung Ihrer Datenbank mit Azure Cosmos DB erfordert weder aufwendige Änderungen an der Architektur noch das Schreiben von komplexem Code. Zentrales Hoch- und Herunterskalieren ist ebenso problemlos möglich wie das Aufrufen einer einzelnen API oder SDK-Methode. Da der Zugriff auf Azure Cosmos DB jedoch über Netzwerkaufrufe erfolgt, können Sie bei der Verwendung des Azure Cosmos DB-Python SDK clientseitige Optimierungen vornehmen, um eine optimale Leistung zu erzielen.
Wenn Sie also fragen "Wie kann ich meine Datenbankleistung verbessern?" sollten Sie die folgenden Optionen in Betracht ziehen:
Netzwerk
- Platzieren Sie Clients in derselben Azure-Region, um die Leistung zu verbessern.
Platzieren Sie nach Möglichkeit sämtliche Anwendungen, die Azure Cosmos DB aufrufen, in der gleichen Region wie die Azure Cosmos DB-Datenbank. Damit Sie einen ungefähren Vergleich haben: Azure Cosmos DB-Aufrufe aus derselben Region werden normalerweise innerhalb von 1 bis 2 ms abgeschlossen, während die Latenz zwischen West- und Ostküste der USA >50 ms beträgt. Diese Latenz variiert ggf. von Anforderung zu Anforderung und ist abhängig von der Route, die die Anforderung zwischen dem Client und der Grenze des Azure-Datencenters nimmt. Die geringste Latenz erzielen Sie, wenn sich die aufrufende Anwendung in der gleichen Azure-Region wie der bereitgestellte Azure Cosmos DB-Endpunkt befindet. Eine Liste mit den verfügbaren Regionen finden Sie unter Azure-Regionen.
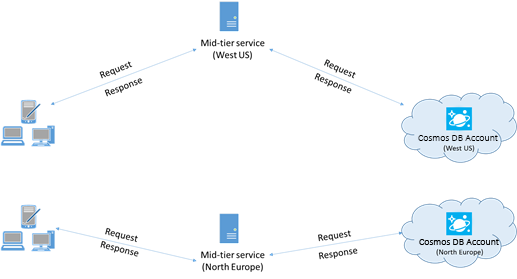
Eine App, die mit einem Azure Cosmos DB-Konto in mehreren Regionen interagiert, muss bevorzugte Regionen konfigurieren, um sicherzustellen, dass Anforderungen in eine angegebene Region weitergeleitet werden.
Aktivieren des beschleunigten Netzwerkbetriebs zur Verringerung von Latenz und CPU-Jitter
Es wird empfohlen, die Anweisungen zum Aktivieren des beschleunigten Netzwerkbetriebs in Ihrer Azure-VM unter Windows oder Linux (für Anweisungen jeweils auswählen) zu befolgen, um die Leistung zu maximieren (und Latenz und CPU-Jitter zu reduzieren).
Ohne den beschleunigten Netzwerkbetrieb könnten E/A-Vorgänge zwischen Ihrer Azure-VM und anderen Azure-Ressourcen unnötigerweise über einen Host und einen virtuellen Switch zwischen der VM und dessen Netzwerkkarte weitergeleitet werden. Wenn sich der Host und der virtuelle Switch inline auf dem Datenpfad befinden, sorgt dies beim Kommunikationskanal nicht nur für eine längere Wartezeit und Jitter, sondern auch die CPU-Zyklen von der VM werden reduziert. Bei beschleunigtem Netzwerkbetrieb erstellt die VM ohne Vermittler direkt Schnittstellen mit der Netzwerkkarte. Alle Netzwerkrichtliniendetails, die zuvor vom Host und dem virtuellen Switch verarbeitet wurden, werden jetzt über die Hardware der Netzwerkkarte verarbeitet, und der Host und der virtuelle Switch werden umgangen. Im Allgemeinen sind eine kürzere und konsistentere Wartezeit, ein höherer Durchsatz und eine geringere CPU-Auslastung zu erwarten, wenn Sie den beschleunigten Netzwerkbetrieb aktivieren.
Einschränkungen: Der beschleunigte Netzwerkbetrieb muss vom Betriebssystem der VM unterstützt werden und kann nur aktiviert werden, wenn die VM beendet und ihre Zuordnung aufgehoben wurde. Die VM kann nicht mit dem Azure Resource Manager bereitgestellt werden. In App Service ist der beschleunigte Netzwerkbetrieb nicht aktiviert.
Weitere Informationen finden Sie in den Anweisungen für Windows bzw. Linux.
SDK-Verwendung
- Installieren des neuesten SDKs
Azure Cosmos DB-SDKs werden ständig verbessert, um eine optimale Leistung zu ermöglichen. Lesen Sie die Versionshinweise zum Azure Cosmos DB-SDK, um das aktuellste SDK zu finden und Verbesserungen zu überprüfen.
- Verwenden eines Singleton-Clients für Azure Cosmos DB für die Lebensdauer der Anwendung
Jede Azure Cosmos DB-Clientinstanz ist threadsicher und verfügt über eine effiziente Verbindungsverwaltung und Adressenzwischenspeicherung. Es empfiehlt sich, für die gesamte Lebensdauer der Anwendung nur eine einzelne Instanz des Azure Cosmos DB-Clients zu verwenden, um eine effiziente Verbindungsverwaltung und bessere Leistung des Azure Cosmos DB-Clients zu ermöglichen.
- Optimieren von Timeout- und Wiederholungskonfigurationen
Timeoutkonfigurationen und Wiederholungsrichtlinien können basierend auf den Anwendungsanforderungen angepasst werden. Lesen Sie das Dokument Timeout- und Wiederholungskonfiguration, um eine vollständige Liste der Konfigurationen zu erhalten, die angepasst werden können.
- Verwenden der niedrigsten für die Anwendung erforderlichen Konsistenzebene
Wenn Sie einen CosmosClient erstellen, wird die Konsistenz auf Kontoebene verwendet, wenn bei der Clienterstellung keine angegeben wird. Weitere Informationen zu Konsistenzebenen finden Sie im Dokument Konsistenzebenen.
- Aufskalieren Ihrer Clientworkload
Wenn Sie auf einem hohen Durchsatzniveau testen, könnte sich die Clientanwendung als Engpass erweisen, da der Computer die CPU- oder Netzwerkauslastung deckelt. Wenn dieser Punkt erreicht wird, können Sie das Azure Cosmos DB-Konto weiter auslasten, indem Sie Ihre Clientanwendungen auf mehrere Server horizontal hochskalieren.
Eine gute Faustregel ist, eine CPU-Auslastung von >50 Prozent auf einem beliebigen Server nicht zu überschreiten, um die Wartezeit gering zu halten.
- Ressourcengrenzwert des Betriebssystems für geöffnete Dateien
Einige Linux-Systeme (z. B. Red Hat) haben eine Obergrenze für die Anzahl von offenen Dateien und damit für die Gesamtanzahl von Verbindungen. Führen Sie den folgenden Befehl aus, um die aktuellen Grenzwerte anzuzeigen:
ulimit -a
Die Anzahl von geöffneten Dateien (nofile) muss groß sein, damit ausreichend Platz für Ihre konfigurierte Verbindungspoolgröße und andere offene Dateien des Betriebssystem vorhanden ist. Sie kann geändert werden, um einen größeren Verbindungspool zu ermöglichen.
Öffnen Sie die Datei „limits.conf“:
vim /etc/security/limits.conf
Ändern Sie die folgenden Zeilen, bzw. fügen Sie sie hinzu:
* - nofile 100000
Abfragevorgänge
Informationen zu Abfragevorgängen finden Sie in den Leistungstipps für Abfragen.
Indizierungsrichtlinie
- Beschleunigen von Schreibvorgängen durch Ausschließen nicht verwendeter Pfade von der Indizierung
Die Indizierungsrichtlinie von Azure Cosmos DB ermöglicht auch die Verwendung von Indizierungspfaden (setIncludedPaths und setExcludedPaths), um anzugeben, welche Dokumentpfade in die Indizierung ein- bzw. von der Indizierung ausgeschlossen werden sollen. Der folgende Code zeigt beispielsweise, wie Sie ganze Abschnitte der Dokumente (auch als Unterstruktur bezeichnet) mit dem Platzhalter „*“ bei der Indizierung ein- und ausschließen.
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
Weitere Informationen finden Sie unter Indizierungsrichtlinien für Azure Cosmos DB.
Throughput
- Messen und Optimieren (Senken) der Anzahl von Anforderungseinheiten pro Sekunde
Azure Cosmos DB bietet vielfältige Datenbankvorgänge (einschließlich relationaler und hierarchischer Abfragen mit UDFs, gespeicherter Prozeduren und Trigger), die alle in den Dokumenten innerhalb einer Datenbanksammlung ausgeführt werden. Die Kosten im Zusammenhang mit diesen Vorgängen variieren basierend auf dem CPU-, E/A- und Speicheraufwand, der für den jeweiligen Vorgang erforderlich ist. Anstelle sich Gedanken über Hardwareressourcen und deren Verwaltung zu machen, können Sie sich eine Anforderungseinheit (RU) als alleinige Maßeinheit für die Ressourcen vorstellen, die für das Durchführen der verschiedenen Datenbankvorgänge und das Ausführen einer Anwendungsanforderung erforderlich sind.
Der Durchsatz wird basierend auf der für jeden Container festgelegten Anzahl von Anforderungseinheiten bereitgestellt. Der Verbrauch von Anforderungseinheiten wird als Rate pro Sekunde bemessen. Anwendungen, die die bereitgestellte Anforderungseinheitenrate für ihre Container überschreiten, werden begrenzt, bis die Rate wieder unter das bereitgestellte Niveau für den Container fällt. Wenn Ihre Anwendung einen höheren Durchsatz erfordert, können Sie ihn durch Bereitstellung zusätzlicher Anforderungseinheiten erhöhen.
Die Komplexität einer Abfrage wirkt sich darauf aus, wie viele Anforderungseinheiten für einen Vorgang verbraucht werden. Die Anzahl von Prädikaten, die Art der Prädikate, die Anzahl von UDFs und die Größe des Quelldatasets beeinflussen die Kosten von Abfragevorgängen.
Untersuchen Sie zum Ermitteln des Indizierungsaufwands für einen beliebigen Vorgang (Erstellen, Aktualisieren oder Löschen) den Header x-ms-request-charge. So ermitteln Sie die Anzahl von Anforderungseinheiten, die von diesen Vorgängen genutzt werden.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
Bei der in diesem Header zurückgegebenen Anforderungsbelastung handelt es sich um einen Bruchteil Ihres bereitgestellten Durchsatzes. Falls Sie beispielsweise 2000 RU/s bereitgestellt und die obige Abfrage 1000 Dokumente mit einer Größe von 1 KB zurückgibt, fallen für den Vorgang Kosten in Höhe von 1000 an. Somit werden vom Server innerhalb einer Sekunde nur zwei solcher Anforderungen berücksichtigt, und für weitere Anforderungen wird die Rate begrenzt. Weitere Informationen finden Sie unter Anforderungseinheiten in DocumentDB sowie unter dem Rechner für Anforderungseinheiten.
- Behandeln von Ratenbeschränkungen/zu hohen Anforderungsraten
Wenn ein Client versucht, den für ein Konto reservierten Durchsatz zu überschreiten, wird die Serverleistung nicht beeinträchtigt, und es wird kein über die reservierte Kapazität hinausgehender Durchsatz in Anspruch genommen. Der Server beendet die Anforderung präemptiv mit „RequestRateTooLarge“ (HTTP-Statuscode 429) und gibt den Header x-ms-retry-after-ms zurück. Darin ist die Zeitspanne (in Millisekunden) angegeben, die der Benutzer warten muss, bis ein neuer Anforderungsversuch unternommen werden kann.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Alle SDKs fangen diese Antwort implizit ab, berücksichtigen den vom Server angegebenen Header vom Typ „retry-after“ und wiederholen die Anforderung. Wenn nicht mehrere Clients gleichzeitig auf Ihr Konto zugreifen, wird die nächste Wiederholung erfolgreich ausgeführt.
Wenn Sie mehrere Clients haben, die kumulativ und kontinuierlich die Anforderungsrate überschreiten, reicht die derzeit vom Client intern festgelegte Standardwiederholungsanzahl von 9 möglicherweise nicht aus. In diesem Fall löst der Client für die Anwendung eine CosmosHttpResponseError mit dem Statuscode 429 aus. Die Standardwiederholungsanzahl kann geändert werden, indem die Konfiguration retry_total an den Client übergeben wird. Der CosmosHttpResponseError mit dem Statuscode 429 wird standardmäßig nach einer kumulierten Wartezeit von 30 Sekunden zurückgegeben, wenn die Anforderung weiterhin die Anforderungsrate übersteigt. Dies gilt auch, wenn die aktuelle Wiederholungsanzahl unter der maximalen Wiederholungsanzahl liegt – ganz gleich, ob es sich dabei um den Standardwert (9) oder um einen benutzerdefinierten Wert handelt.
Das automatisierte Wiederholungsverhalten trägt zwar bei den meisten Anwendungen zur Verbesserung der Resilienz und Nutzbarkeit bei, kann bei Leistungsbenchmarks aber auch hinderlich sein (insbesondere beim Ermitteln der Latenz). Die Wartezeit für den Client nimmt stark zu, wenn das Experiment die Serverdrosselung erreicht und damit die automatische Wiederholung durch das Client-SDK auslöst. Ermitteln Sie zur Vermeidung von Latenzspitzenwerten bei Leistungsexperimenten die von den einzelnen Vorgängen zurückgegebene Belastung, und stellen Sie sicher, dass die Anforderungen die reservierte Anforderungsrate nicht überschreiten. Weitere Informationen finden Sie unter Anforderungseinheiten in DocumentDB.
- Konzipieren für kleinere Dokumente und höheren Durchsatz
Die Anforderungsbelastung (die Kosten für die Anforderungsverarbeitung) eines Vorgangs hängt direkt mit der Größe des Dokuments zusammen. Vorgänge für große Dokumente sind teurer als Vorgänge für kleine Dateien. Im Idealfall sollten Sie Ihre Anwendung und Workflows so entwerfen, dass die Größe der Elemente etwa ein Kilobyte beträgt oder diese eine ähnliche Größe aufweisen. Bei Anwendungen, die hinsichtlich der Wartezeit empfindlich sind, sollten große Elemente vermieden werden. Dokumente mit mehreren Megabyte verlangsamen Ihre Anwendung.
Nächste Schritte
Weitere Informationen zum Entwerfen einer auf Skalierung und hohe Leistung ausgelegten Anwendung finden Sie unter Partitionieren und Skalieren in Azure Cosmos DB.
Versuchen Sie, die Kapazitätsplanung für eine Migration zu Azure Cosmos DB durchzuführen? Sie können Informationen zu Ihrem vorhandenen Datenbankcluster für die Kapazitätsplanung verwenden.
- Wenn Sie lediglich die Anzahl der virtuellen Kerne und Server in Ihrem vorhandenen Datenbankcluster kennen, lesen Sie die Informationen zum Schätzen von Anforderungseinheiten mithilfe von virtuellen Kernen oder virtuellen CPUs.
- Wenn Sie die typischen Anforderungsraten für Ihre aktuelle Datenbankworkload kennen, lesen Sie die Informationen zum Schätzen von Anforderungseinheiten mit dem Azure Cosmos DB-Kapazitätsplaner