Leistungstipps für das Sync Java SDK v2 von Azure Cosmos DB
GILT FÜR: ![]() NoSQL
NoSQL
Wichtig
Dies ist nicht das neueste Java SDK für Azure Cosmos DB! Sie sollten ein Upgrade Ihres Projekts auf das Azure Cosmos DB Java SDK v4 durchführen und dann die Leistungstipps für das Azure Cosmos DB Java SDK v4 lesen. Befolgen Sie für ein Upgrade die Anweisungen in den Anleitungen Migrieren zum Azure Cosmos DB Java SDK v4 und Reactor vs RxJava.
Die folgenden Leistungstipps gelten ausschließlich für das Sync Java SDK v2 von Azure Cosmos DB. Weitere Informationen finden Sie im Maven-Repository.
Wichtig
Am 29. Februar 2024 wird das Sync Java SDK v2.x von Azure Cosmos DB eingestellt. Das SDK und alle Anwendungen, die es verwenden, sind weiterhin funktionsfähig. Azure Cosmos DB stellt jedoch keine weitere Wartung und Unterstützung für dieses SDK bereit. Es wird empfohlen, die obigen Anweisungen zur Migration zum Azure Cosmos DB Java SDK v4 zu befolgen.
Azure Cosmos DB ist eine schnelle und flexible verteilte Datenbank mit nahtloser Skalierung, garantierter Latenz und garantiertem Durchsatz. Die Skalierung Ihrer Datenbank mit Azure Cosmos DB erfordert weder aufwendige Änderungen an der Architektur noch das Schreiben von komplexem Code. Zentrales Hoch- und Herunterskalieren ist ebenso problemlos möglich wie ein einzelner API-Aufruf. Weitere Informationen finden Sie unter Bereitstellen von Containerdurchsatz und Bereitstellen von Datenbankdurchsatz. Da der Zugriff auf Azure Cosmos DB jedoch über Netzwerkaufrufe erfolgt, können Sie bei der Verwendung des Sync Java SDK v2 von Azure Cosmos DB clientseitige Optimierungen vornehmen, um eine optimale Leistung zu erzielen.
Wenn Sie also fragen "Wie kann ich meine Datenbankleistung verbessern?" sollten Sie die folgenden Optionen in Betracht ziehen:
Netzwerk
Verbindungsmodus: Verwenden von DirectHttps
Die Art der Verbindungsherstellung zwischen einem Client und Azure Cosmos DB hat erhebliche Auswirkungen auf die Leistung, insbesondere im Hinblick auf die clientseitige Latenz. Für die Konfiguration des Clients ConnectionPolicy ist eine wichtige Konfigurationseinstellung verfügbar: ConnectionMode. Die zwei verfügbaren ConnectionModes lauten wie folgt:
-
Der Gatewaymodus wird auf allen SDK-Plattformen unterstützt und ist als Standardoption konfiguriert. Wenn Ihre Anwendung in einem Unternehmensnetzwerk mit strengen Firewalleinschränkungen ausgeführt wird, ist das Gateway die beste Wahl, da er den HTTPS-Standardport und einen einzelnen Endpunkt verwendet. Im Gatewaymodus ist jedoch jeweils ein zusätzlicher Netzwerkhop erforderlich, wenn Daten in Azure Cosmos DB geschrieben oder daraus gelesen werden, was sich negativ auf die Leistung auswirkt. Aus diesem Grund bietet der DirectHttps-Modus die bessere Leistung, da weniger Netzwerkhops erforderlich sind.
Das Sync Java SDK v2 von Azure Cosmos DB verwendet HTTPS als Transportprotokoll. HTTPS nutzt TLS für die erste Authentifizierung und Verschlüsselung des Datenverkehrs. Wenn Sie das Sync Java SDK v2 von Azure Cosmos DB verwenden, muss nur HTTPS-Port 443 geöffnet sein.
ConnectionMode wird im Zuge der Erstellung der DocumentClient-Instanz mit dem ConnectionPolicy-Parameter konfiguriert.
Sync Java SDK v2 (Maven com.microsoft.azure::azure-documentdb)
public ConnectionPolicy getConnectionPolicy() { ConnectionPolicy policy = new ConnectionPolicy(); policy.setConnectionMode(ConnectionMode.DirectHttps); policy.setMaxPoolSize(1000); return policy; } ConnectionPolicy connectionPolicy = new ConnectionPolicy(); DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);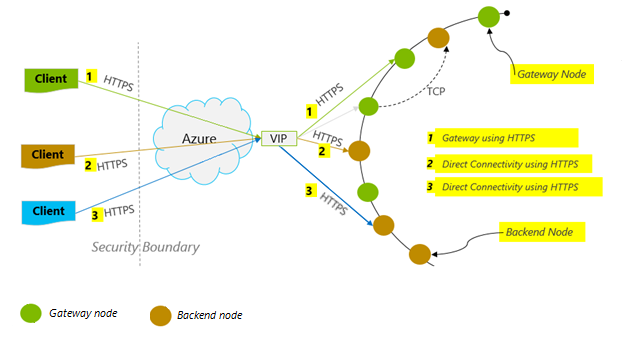
Platzieren der Clients in der gleichen Azure-Region
Platzieren Sie nach Möglichkeit sämtliche Anwendungen, die Azure Cosmos DB aufrufen, in der gleichen Region wie die Azure Cosmos DB-Datenbank. Damit Sie einen ungefähren Vergleich haben: Azure Cosmos DB-Aufrufe aus derselben Region werden normalerweise innerhalb von 1 bis 2 ms abgeschlossen, während die Latenz zwischen West- und Ostküste der USA >50 ms beträgt. Diese Latenz variiert ggf. von Anforderung zu Anforderung und ist abhängig von der Route, die die Anforderung zwischen dem Client und der Grenze des Azure-Datencenters nimmt. Die geringste Latenz erzielen Sie, wenn sich die aufrufende Anwendung in der gleichen Azure-Region wie der bereitgestellte Azure Cosmos DB-Endpunkt befindet. Eine Liste mit den verfügbaren Regionen finden Sie unter Azure-Regionen.
SDK-Verwendung
Installieren des neuesten SDKs
Azure Cosmos DB-SDKs werden ständig verbessert, um eine optimale Leistung zu ermöglichen. Informationen zu den neuesten SDK-Verbesserungen finden Sie unter Azure Cosmos DB-SDK.
Verwenden eines Singleton-Azure Cosmos DB-Clients für die Lebensdauer der Anwendung
Bei Verwendung des direkten Modus ist jede DocumentClient-Instanz threadsicher und verfügt über eine effiziente Verbindungsverwaltung und Adressenzwischenspeicherung. Zur Ermöglichung einer effizienten Verbindungsverwaltung und einer besseren DocumentClient-Leistung empfiehlt es sich, für die Lebensdauer der Anwendung pro Anwendungsdomäne eine einzelne DocumentClient-Instanz zu verwenden.
Erhöhen von MaxPoolSize pro Host im Gatewaymodus
Anforderungen an Azure Cosmos DB erfolgen bei Verwendung des Gatewaymodus über HTTPS/REST und unterliegen dem Standardverbindungslimit pro Hostname oder IP-Adresse. Unter Umständen müssen Sie einen höheren MaxPoolSize-Wert festlegen (200 – 1000), damit die Clientbibliothek mehrere Verbindungen mit Azure Cosmos DB gleichzeitig nutzen kann. Im Sync Java SDK v2 von Azure Cosmos DB hat ConnectionPolicy.getMaxPoolSize den Standardwert „100“. Verwenden Sie setMaxPoolSize, um den Wert zu ändern.
Optimieren von parallelen Abfragen für partitionierte Sammlungen
Ab Version 1.9.0 des Sync Java SDK von Azure Cosmos DB werden parallele Abfragen unterstützt, mit denen Sie eine partitionierte Sammlung parallel abfragen können. Weitere Informationen finden Sie in den Codebeispielen für die Arbeit mit den SDKs. Parallele Abfragen sind darauf ausgelegt, Latenz und Durchsatz im Vergleich mit seriellen Abfragen zu verbessern.
(a) Optimieren von setMaxDegreeOfParallelism: Bei paparallelen Abfragen werden mehrere Partitionen parallel abgefragt. Die Daten einer individuell partitionierten Sammlung werden in Bezug auf die Abfrage aber seriell abgerufen. Legen Sie also setMaxDegreeOfParallelism auf die Anzahl von Partitionen fest, bei der die Wahrscheinlichkeit, dass die bestmögliche Leistung für die Abfrage erzielt wird, am höchsten ist (vorausgesetzt, alle anderen Systembedingungen bleiben unverändert). Falls Ihnen die Anzahl von Partitionen nicht bekannt ist, können Sie setMaxDegreeOfParallelism auf einen hohen Wert festlegen. Das System wählt für den maximalen Grad an Parallelität dann den minimalen Wert aus (Anzahl von Partitionen, Benutzereingabe).
Es ist wichtig zu beachten, dass sich für parallele Abfragen die größten Vorteile ergeben, wenn die Daten in Bezug auf die Abfrage gleichmäßig auf alle Partitionen verteilt werden. Wenn die partitionierte Auflistung so partitioniert ist, dass sich alle Daten bzw. die meisten Daten, die von einer Abfrage zurückgegeben werden, auf einigen wenigen Partitionen befinden (schlimmstenfalls nur auf einer Partition), können aufgrund dieser Partitionierung Engpässe bei der Leistung auftreten.
(b) Optimieren von setMaxBufferedItemCount: Die parallele Abfrage ist so konzipiert, dass Ergebnisse vorab abgerufen werden, während der Client den aktuellen Batch mit Ergebnissen verarbeitet. Das Vorabrufen führt zu einer allgemeinen Verbesserung der Latenz einer Abfrage. setMaxBufferedItemCount begrenzt die Anzahl von vorab abgerufenen Ergebnissen. Wenn Sie setMaxBufferedItemCount auf die erwartete Anzahl von zurückgegebenen Ergebnissen (oder eine höhere Anzahl) festlegen, ist der Vorteil durch das Vorabrufen für die Abfrage am größten.
Das Vorabrufen funktioniert unabhängig von MaxDegreeOfParallelism auf die gleiche Weise, und es ist nur ein Puffer für die Daten aller Partitionen vorhanden.
Implementieren von Backoff in getRetryAfterInMilliseconds-Intervallen
Es empfiehlt sich, die Last während Leistungstests so lange erhöhen, bis eine geringe Menge von Anforderungen gedrosselt wird. Wenn es sich um eine gedrosselte Anwendung handelt, sollte die Clientanwendung diese Drosselung für das vom Server angegebene Wiederholungsintervall aussetzen. Durch das Aussetzen wird die geringstmögliche Wartezeit zwischen den Wiederholungsversuchen gewährleistet. Unterstützung für Wiederholungsrichtlinien wird ab Version 1.8.0 des Sync Java SDK von Azure Cosmos DB bereitgestellt. Weitere Informationen finden Sie unter getRetryAfterInMilliseconds.
Aufskalieren Ihrer Clientworkload
Wenn Sie auf einem hohen Durchsatzniveau testen (>50.000 RU/s), kann sich die Clientanwendung als Engpass erweisen, da der Computer die CPU- oder Netzwerkauslastung deckelt. Wenn dieser Punkt erreicht wird, können Sie das Azure Cosmos DB-Konto weiter auslasten, indem Sie Ihre Clientanwendungen auf mehrere Server horizontal hochskalieren.
Verwenden von namensbasierter Adressierung
Verwenden Sie anstelle von SelfLinks (_self) mit dem Format
dbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>die namensbasierte Adressierung mit Links im Formatdbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId, damit nicht die Ressourcen-IDs aller Ressourcen zum Erstellen der Verknüpfung abgerufen werden. Da diese Ressourcen zudem (möglicherweise mit demselben Namen) neu erstellt werden, ist ein Zwischenspeichern in diesem Fall eventuell wirkungslos.Optimieren der Seitengröße für Abfragen/Lesefeeds, um die Leistung zu verbessern
Wenn mehrere Dokumente mithilfe der Lesefeedfunktion (z.B. readDocuments) gleichzeitig gelesen werden oder eine SQL-Abfrage ausgegeben wird, werden die Ergebnisse bei der Rückgabe segmentiert, falls das Resultset zu groß ist. Ergebnisse werden standardmäßig in Blöcken mit je 100 Elementen oder 1 MB zurückgegeben (je nachdem, welcher Grenzwert zuerst erreicht wird).
Mithilfe des Anforderungsheaders x-ms-max-item-count können Sie die Seitengröße auf bis zu 1000 erhöhen und so die Anzahl von Netzwerkroundtrips verringern, die zum Abrufen aller entsprechenden Ergebnisse erforderlich sind. Falls nur einige wenige Ergebnisse angezeigt werden müssen (etwa, wenn von der Benutzeroberfläche oder Anwendungs-API lediglich zehn Ergebnisse zurückgegeben werden), können Sie die Seitengröße auch auf 10 verringern, um den durch Lese- und Abfragevorgänge beanspruchten Durchsatz zu reduzieren.
Die Seitengröße kann auch mithilfe der setPageSize-Methode festgelegt werden.
Indizierungsrichtlinien
Beschleunigen von Schreibvorgängen durch Ausschließen nicht verwendeter Pfade von der Indizierung
Mit der Indizierungsrichtlinie von Azure Cosmos DB können Sie angeben, welche Dokumentpfade mithilfe der Indizierungspfade (setIncludedPaths und setExcludedPaths) in die Indizierung eingeschlossen bzw. von ihr ausgeschlossen werden sollen. von der Indizierung ausgeschlossen werden sollen. Der folgenden Code zeigt beispielsweise, wie Sie einen gesamten Abschnitt der Dokumente (Unterstruktur) mit dem Platzhalter „*“ von der Indizierung ausschließen.
Sync Java SDK v2 (Maven com.microsoft.azure::azure-documentdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Weitere Informationen finden Sie unter Indizierungsrichtlinien für Azure Cosmos DB.
Throughput
Messen und Optimieren (Senken) der Anzahl von Anforderungseinheiten pro Sekunde
Azure Cosmos DB bietet vielfältige Datenbankvorgänge (einschließlich relationaler und hierarchischer Abfragen mit UDFs, gespeicherter Prozeduren und Trigger), die alle in den Dokumenten innerhalb einer Datenbanksammlung ausgeführt werden. Die Kosten im Zusammenhang mit diesen Vorgängen variieren basierend auf dem CPU-, E/A- und Speicheraufwand, der für den jeweiligen Vorgang erforderlich ist. Anstelle sich Gedanken über Hardwareressourcen und deren Verwaltung zu machen, können Sie sich eine Anforderungseinheit (RU) als alleinige Maßeinheit für die Ressourcen vorstellen, die für das Durchführen der verschiedenen Datenbankvorgänge und das Ausführen einer Anwendungsanforderung erforderlich sind.
Der Durchsatz wird basierend auf der für jeden Container festgelegten Anzahl von Anforderungseinheiten bereitgestellt. Der Verbrauch von Anforderungseinheiten wird als Rate pro Sekunde bemessen. Anwendungen, die die bereitgestellte Anforderungseinheitenrate für ihre Container überschreiten, werden begrenzt, bis die Rate wieder unter das bereitgestellte Niveau für den Container fällt. Wenn Ihre Anwendung einen höheren Durchsatz erfordert, können Sie ihn durch Bereitstellung zusätzlicher Anforderungseinheiten erhöhen.
Die Komplexität einer Abfrage wirkt sich darauf aus, wie viele Anforderungseinheiten für einen Vorgang verbraucht werden. Die Anzahl von Prädikaten, die Art der Prädikate, die Anzahl von UDFs und die Größe des Quelldatasets beeinflussen die Kosten von Abfragevorgängen.
Um den Aufwand einer beliebigen Operation (Erstellen, Aktualisieren oder Löschen) zu messen, untersuchen Sie den x-ms-request-charge-Header (oder die entsprechende RequestCharge-Eigenschaft in ResourceResponse<T> oder FeedResponse<T>, um die Anzahl der von diesen Operationen verbrauchten Anfrageeinheiten zu messen.
Sync Java SDK v2 (Maven com.microsoft.azure::azure-documentdb)
ResourceResponse<Document> response = client.createDocument(collectionLink, documentDefinition, null, false); response.getRequestCharge();Bei der in diesem Header zurückgegebenen Anforderungsbelastung handelt es sich um einen Bruchteil Ihres bereitgestellten Durchsatzes. Falls Sie beispielsweise 2.000 RU/s bereitgestellt haben und die vorherige Abfrage 1.000 Dokumente mit einer Größe von 1 KB zurückgibt, fallen für den Vorgang Kosten in Höhe von 1.000 an. Somit werden vom Server innerhalb einer Sekunde nur zwei solcher Anforderungen berücksichtigt, und für weitere Anforderungen wird die Rate begrenzt. Weitere Informationen finden Sie unter Anforderungseinheiten in DocumentDB sowie unter dem Rechner für Anforderungseinheiten.
Behandeln von Ratenbeschränkungen/zu hohen Anforderungsraten
Wenn ein Client versucht, den für ein Konto reservierten Durchsatz zu überschreiten, wird die Serverleistung nicht beeinträchtigt, und es wird kein über die reservierte Kapazität hinausgehender Durchsatz in Anspruch genommen. Der Server beendet die Anforderung präemptiv mit „RequestRateTooLarge“ (HTTP-Statuscode 429) und gibt den Header x-ms-retry-after-ms zurück. Darin ist die Zeitspanne (in Millisekunden) angegeben, die der Benutzer warten muss, bis ein neuer Anforderungsversuch unternommen werden kann.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100Alle SDKs fangen diese Antwort implizit ab, berücksichtigen den vom Server angegebenen Header vom Typ „retry-after“ und wiederholen die Anforderung. Wenn nicht mehrere Clients gleichzeitig auf Ihr Konto zugreifen, wird die nächste Wiederholung erfolgreich ausgeführt.
Falls mehrere Clients kumulativ und kontinuierlich die Anforderungsrate überschreiten, reicht die intern vom Client festgelegte Standardanzahl von neun Wiederholungen unter Umständen nicht aus. In diesem Fall löst der Client für die Anwendung eine DocumentClientException mit dem Statuscode 429 aus. Die standardmäßige Wiederholungsanzahl kann durch Verwendung von setRetryOptions für die ConnectionPolicy-Instanz geändert werden. Die DocumentClientException mit dem Statuscode 429 wird standardmäßig nach einer kumulierten Wartezeit von 30 Sekunden zurückgegeben, wenn die Anforderung weiterhin die Anforderungsrate übersteigt. Dies gilt auch, wenn die aktuelle Wiederholungsanzahl unter der maximalen Wiederholungsanzahl liegt – ganz gleich, ob es sich dabei um den Standardwert (9) oder um einen benutzerdefinierten Wert handelt.
Das automatisierte Wiederholungsverhalten trägt zwar bei den meisten Anwendungen zur Verbesserung der Resilienz und Nutzbarkeit bei, kann bei Leistungsbenchmarks aber auch hinderlich sein (insbesondere beim Ermitteln der Latenz). Die Wartezeit für den Client nimmt stark zu, wenn das Experiment die Serverdrosselung erreicht und damit die automatische Wiederholung durch das Client-SDK auslöst. Ermitteln Sie zur Vermeidung von Latenzspitzenwerten bei Leistungsexperimenten die von den einzelnen Vorgängen zurückgegebene Belastung, und stellen Sie sicher, dass die Anforderungen die reservierte Anforderungsrate nicht überschreiten. Weitere Informationen finden Sie unter Anforderungseinheiten in DocumentDB.
Konzipieren für kleinere Dokumente und höheren Durchsatz
Die Anforderungsbelastung (die Kosten für die Anforderungsverarbeitung) eines Vorgangs hängt direkt mit der Größe des Dokuments zusammen. Vorgänge für große Dokumente sind teurer als Vorgänge für kleine Dateien.
Nächste Schritte
Weitere Informationen zum Entwerfen einer auf Skalierung und hohe Leistung ausgelegten Anwendung finden Sie unter Partitionieren und Skalieren in Azure Cosmos DB.