Migrering: Azure Synapse Analytics dedikerede SQL-puljer til Fabric
Gælder for:✅ Warehouse i Microsoft Fabric
I denne artikel beskrives strategi, overvejelser og metoder til migrering af datawarehousing i Azure Synapse Analytics dedikerede SQL-puljer til Microsoft Fabric Warehouse.
Introduktion til migrering
Da Microsoft introducerede Microsoft Fabric, en alt-i-en SaaS-analyseløsning til virksomheder, der tilbyder en omfattende pakke af tjenester, herunder Data Factory, Dataudvikler ing, Data Warehousing, Data Science, Real-Time Intelligence og Power BI.
I denne artikel fokuseres der på indstillinger for skemaoverførsel (DDL), DML-overførsel (Database Code) og dataoverførsel. Microsoft tilbyder flere muligheder, og her diskuterer vi hver indstilling i detaljer og giver vejledning i, hvilke af disse indstillinger du skal overveje til dit scenarie. I denne artikel bruges branchebenchmarket for TPC-DS til illustration og test af ydeevne. Dit faktiske resultat kan variere afhængigt af mange faktorer, herunder datatype, datatyper, bredde af tabeller, ventetid for datakilde osv.
Forbered migrering
Planlæg omhyggeligt dit migreringsprojekt, før du kommer i gang, og sørg for, at dit skema, din kode og dine data er kompatible med Fabric Warehouse. Der er nogle begrænsninger , du skal overveje. Kvantificer omstruktureringsarbejdet for de inkompatible elementer samt eventuelle andre ressourcer, der er nødvendige før migreringsleveringen.
Et andet vigtigt mål med planlægning er at justere dit design for at sikre, at din løsning drager fuld fordel af den høje forespørgselsydeevne, som Fabric Warehouse er designet til at levere. Design af data warehouses til skalering introducerer unikke designmønstre, så traditionelle tilgange er ikke altid de bedste. Gennemse retningslinjerne for ydeevnen i Fabric Warehouse, for selvom der kan foretages designjusteringer efter migreringen, sparer du tid og kræfter ved at foretage ændringer tidligere i processen. Overførsel fra én teknologi/et miljø til en anden er altid en stor indsats.
Følgende diagram viser migreringslivscyklussen, der viser de vigtigste søjler, der består af Vurder og evaluer, Planlæg og design, Migrér, Overvåg og styr, Optimer og moderniser søjler med de tilknyttede opgaver i hver søjle for at planlægge og forberede den problemfri migrering.

Runbook til migrering
Overvej følgende aktiviteter som en planlægningskørselsbog for din migrering fra Synapse dedikerede SQL-puljer til Fabric Warehouse.
-
Vurder og evaluer
- Identificer målsætninger og motivationer. Opret tydelige ønskede resultater.
- Registrering, vurdering og grundlinje for den eksisterende arkitektur.
- Identificer vigtige interessenter og sponsorer.
- Definer omfanget af det, der skal migreres.
- Start lille og enkel, forbered dig på flere små migreringer.
- Begynd at overvåge og dokumentere alle faser i processen.
- Opret en oversigt over data og processer til migrering.
- Definer eventuelle ændringer af datamodellen.
- Konfigurer Fabric Workspace.
- Hvad er dine færdigheder/præferencer?
- Automatiser, hvor det er muligt.
- Brug indbyggede Azure-værktøjer og -funktioner til at reducere migreringsindsatsen.
- Oplær personalet tidligt på den nye platform.
- Identificer behov for opkvalificering og oplæringsaktiver, herunder Microsoft Learn.
-
Planlæg og design
- Definer den ønskede arkitektur.
- Vælg metoden /værktøjerne til migreringen for at udføre følgende opgaver:
- Dataudtrækning fra kilden.
- Skemakonvertering (DDL), herunder metadata for tabeller og visninger
- Dataindtagelse, herunder historiske data.
- Om nødvendigt skal du rekonstruere datamodellen ved hjælp af ny platformydeevne og skalerbarhed.
- Overførsel af databasekode (DML).
- Overfør eller refactor lagrede procedurer og forretningsprocesser.
- Opret en oversigt over og udtræk sikkerhedsfunktionerne og objekttilladelserne fra kilden.
- Design og planlæg at erstatte/ændre eksisterende ETL/ELT-processer for trinvis belastning.
- Opret parallelle ETL/ELT-processer til det nye miljø.
- Forbered en detaljeret overførselsplan.
- Knyt den aktuelle tilstand til den nye ønskede tilstand.
-
Overflytte
- Udfør skema, data, kodeoverførsel.
- Dataudtrækning fra kilden.
- Skemakonvertering (DDL)
- Dataindtagelse
- Overførsel af databasekode (DML).
- Skaler om nødvendigt de dedikerede SQL-puljeressourcer midlertidigt for at gøre migreringen hurtigere.
- Anvend sikkerhed og tilladelser.
- Overfør eksisterende ETL/ELT-processer for trinvis belastning.
- Migrer eller refactor ETL/ELT trinvise belastningsprocesser.
- Test og sammenlign belastningsprocesser for parallel trinvis forøgelse.
- Tilpas detaljeret overførselsplan efter behov.
- Udfør skema, data, kodeoverførsel.
-
Overvåg og styr
- Kør parallelt, sammenlign med dit kildemiljø.
- Test programmer, business intelligence-platforme og forespørgselsværktøjer.
- Benchmark og optimer forespørgselsydeevnen.
- Overvåg og administrer omkostninger, sikkerhed og ydeevne.
- Benchmark for styring og vurdering.
- Kør parallelt, sammenlign med dit kildemiljø.
-
Optimer og moderniser
- Når virksomheden er komfortabel, kan du overføre programmer og primære rapporteringsplatforme til Fabric.
- Skaler ressourcer op/ned, efterhånden som arbejdsbelastningen flyttes fra Azure Synapse Analytics til Microsoft Fabric.
- Opret en gentagelig skabelon ud fra den erfaring, der er opnået i forbindelse med fremtidige migreringer. Gentage.
- Identificer muligheder for omkostningsoptimering, sikkerhed, skalerbarhed og driftsmæssig ekspertise
- Identificer muligheder for at modernisere dit dataområde med de nyeste Fabric-funktioner.
- Når virksomheden er komfortabel, kan du overføre programmer og primære rapporteringsplatforme til Fabric.
'Løft og skift' eller modernisere?
Der er generelt to typer migreringsscenarier, uanset formålet med og omfanget af den planlagte migrering: løft og skift, som den er, eller en faseinddelt tilgang, der inkorporerer arkitektoniske ændringer og kodeændringer.
Løft og skift
I forbindelse med migrering af data overflyttes en eksisterende datamodel med mindre ændringer til det nye Fabric Warehouse. Denne fremgangsmåde minimerer risikoen og overførselstiden ved at reducere det nye arbejde, der er nødvendigt for at realisere fordelene ved migrering.
Migrering af løft og skift passer godt til disse scenarier:
- Du har et eksisterende miljø med et lille antal datacentre at overføre.
- Du har et eksisterende miljø med data, der allerede findes i et veldesignet stjerne- eller snefnugskema.
- Du er under tids- og omkostningspres for at flytte til Fabric Warehouse.
Denne fremgangsmåde fungerer kort sagt godt for de arbejdsbelastninger, der er optimeret med dit aktuelle Synapse-dedikerede SQL-puljemiljø og derfor ikke kræver større ændringer i Fabric.
Modernisere i en faseinddelt tilgang med arkitektoniske ændringer
Hvis et ældre data warehouse har udviklet sig over en lang periode, skal du muligvis omteknikere det for at opretholde de påkrævede ydeevneniveauer.
Det kan også være en god idé at omdesigne arkitekturen for at drage fordel af de nye programmer og funktioner, der er tilgængelige i Fabric Workspace.
Designforskelle: Synapse dedikerede SQL-puljer og Fabric Warehouse
Overvej følgende Azure Synapse- og Microsoft Fabric-datawarehousing-forskelle, og sammenlign dedikerede SQL-puljer med Fabric Warehouse.
Tabelovervejelser
Når du overfører tabeller mellem forskellige miljøer, er det typisk kun rådata og metadata, der overføres fysisk. Andre databaseelementer fra kildesystemet, f.eks. indekser, overføres normalt ikke, fordi de kan være unødvendige eller implementeres forskelligt i det nye miljø.
Optimeringer af ydeevnen i kildemiljøet, f.eks. indekser, angiver, hvor du kan tilføje optimering af ydeevnen i et nyt miljø, men nu tager Fabric sig af det automatisk for dig.
T-SQL-overvejelser
Der er flere DML-syntaksforskelle (Data Manipulation Language), du skal være opmærksom på. Se T-SQL-overfladeområdet i Microsoft Fabric. Overvej også en kodevurdering, når du vælger en eller flere metoder til overførsel til databasekoden (DML).
Afhængigt af paritetsforskellene på tidspunktet for migreringen skal du muligvis omskrive dele af din T-SQL DML-kode.
Tilknytningsforskelle for datatyper
Der er flere datatypeforskelle i Fabric Warehouse. Du kan få flere oplysninger under Datatyper i Microsoft Fabric.
Følgende tabel indeholder tilknytningen af understøttede datatyper fra Synapse-dedikerede SQL-puljer til Fabric Warehouse.
| Synapse dedikerede SQL-puljer | Fabric Warehouse |
|---|---|
| penge | decimal(19,4) |
| smallmoney | decimal(10,4) |
| smalldatetime | datetime2 |
| dato/klokkeslæt | datetime2 |
| nchar | Char |
| nvarchar | varchar |
| tinyint | smallint |
| binær | varbinary |
| datetimeoffset* | datetime2 |
* Datetime2 gemmer ikke de ekstra oplysninger om tidszoneforskydning, der er gemt i. Da datatypen datetimeoffset i øjeblikket ikke understøttes i Fabric Warehouse, skal tidszoneforskydningsdataene udtrækkes til en separat kolonne.
Metoder til skema-, kode- og dataoverførsel
Gennemse og identificer, hvilke af disse indstillinger der passer til dit scenarie, dine medarbejderes færdigheder og egenskaberne for dine data. Den eller de valgte indstillinger afhænger af din oplevelse, dine præferencer og fordelene ved hvert af værktøjerne. Vores mål er at fortsætte med at udvikle migreringsværktøjer, der afhjælper friktion og manuel indgriben for at gøre denne migreringsoplevelse problemfri.
Denne tabel opsummerer oplysninger om dataskema (DDL), databasekode (DML) og metoder til dataoverførsel. Vi udvider yderligere i hvert scenarie senere i denne artikel, der er sammenkædet i kolonnen Indstilling .
| Indstillingsnummer | Indstilling | Det gør den | Kompetence/præference | Scenarie |
|---|---|---|---|---|
| 0 | Data Factory | Skemakonvertering (DDL) Udtræk data Dataindtagelse |
ADF/pipeline | Forenklet alt i ét skema (DDL) og dataoverførsel. Anbefales til dimensionstabeller. |
| 2 | Data Factory med partition | Skemakonvertering (DDL) Udtræk data Dataindtagelse |
ADF/pipeline | Brug af partitionsindstillinger til at øge læse-/skrive parallelitet, hvilket giver 10x overførselshastighed vs. mulighed 1, hvilket anbefales til faktatabeller. |
| 3 | Data Factory med accelereret kode | Skemakonvertering (DDL) | ADF/pipeline | Konvertér og overfør først skemaet (DDL), og brug derefter CETAS til at udtrække og KOPIERE/datafabrikken til at indtage data for at opnå optimal samlet ydeevne for indtagelse. |
| 4 | Fremskyndet kode for lagrede procedurer | Skemakonvertering (DDL) Udtræk data Kodevurdering |
T-SQL | SQL-bruger, der bruger IDE med mere detaljeret kontrol over, hvilke opgaver de vil arbejde med. Brug COPY/Data Factory til at hente data. |
| 5 | SQL Database Project-udvidelse til Azure Data Studio | Skemakonvertering (DDL) Udtræk data Kodevurdering |
SQL-projekt | SQL Database Project til installation med integration af mulighed 4. Brug COPY eller Data Factory til at hente data. |
| 6 | OPRET EKSTERN TABEL SOM VÆLG (CETAS) | Udtræk data | T-SQL | Omkostningseffektiv og højtydende dataudtrækning i Azure Data Lake Storage (ADLS) Gen2. Brug COPY/Data Factory til at hente data. |
| 7 | Overfør ved hjælp af dbt | Skemakonvertering (DDL) konvertering af databasekode (DML) |
dbt | Eksisterende dbt-brugere kan bruge dbt Fabric-adapteren til at konvertere deres DDL og DML. Du skal derefter overføre data ved hjælp af andre indstillinger i denne tabel. |
Vælg en arbejdsbelastning til den indledende migrering
Når du beslutter, hvor du vil starte på Synapse-dedikeret SQL-pulje til Fabric Warehouse-migreringsprojekt, skal du vælge et arbejdsbelastningsområde, hvor du kan:
- Bevis levedygtigheden af migrering til Fabric Warehouse ved hurtigt at levere fordelene ved det nye miljø. Start lille og enkel, forbered dig på flere små migreringer.
- Giv dine tekniske medarbejdere i huset tid til at få relevant erfaring med de processer og værktøjer, de bruger, når de migrerer til andre områder.
- Opret en skabelon til yderligere migreringer, der er specifikke for kildens Synapse-miljø, og de værktøjer og processer, der er på plads for at hjælpe.
Tip
Opret en oversigt over objekter, der skal migreres, og dokumenter overførselsprocessen fra start til slut, så den kan gentages for andre dedikerede SQL-puljer eller arbejdsbelastninger.
Mængden af migrerede data i en indledende migrering bør være stor nok til at demonstrere egenskaberne og fordelene ved Fabric Warehouse-miljøet, men ikke for stor til hurtigt at demonstrere værdi. En størrelse i intervallet 1-10 terabyte er typisk.
Migrering med Fabric Data Factory
I dette afsnit gennemgår vi indstillingerne ved hjælp af Data Factory for persona med lav kode/ingen kode, der kender Azure Data Factory og Synapse Pipeline. Denne indstilling for brugergrænsefladen med træk og slip er et simpelt trin til at konvertere DDL'en og overføre dataene.
Fabric Data Factory kan udføre følgende opgaver:
- Konvertér skemaet (DDL) til Fabric Warehouse-syntaksen.
- Opret skemaet (DDL) på Fabric Warehouse.
- Overfør dataene til Fabric Warehouse.
Mulighed 1. Migrering af skema/data – guiden Kopiér og ForHver kopiaktivitet
Denne metode bruger Data Factory Copy-assistenten til at oprette forbindelse til kildens dedikerede SQL-pulje, konvertere den dedikerede SQL-pulje DDL-syntaks til Fabric og kopiere data til Fabric Warehouse. Du kan vælge 1 eller flere destinationstabeller (for TPC-DS-datasæt er der 22 tabeller). Den genererer ForHver for at gennemgå listen over tabeller, der er valgt i brugergrænsefladen, og forgrene 22 parallelle Kopiér aktivitet-tråde.
- 22 SELECT-forespørgsler (én for hver tabel, der er valgt) blev genereret og udført i den dedikerede SQL-gruppe.
- Sørg for, at du har den relevante DWU- og ressourceklasse, så de oprettede forespørgsler kan udføres. I dette tilfælde skal du bruge et minimum af DWU1000 med
staticrc10for at tillade maksimalt 32 forespørgsler at håndtere 22 sendte forespørgsler. - Data Factory-direkte kopiering af data fra den dedikerede SQL-pulje til Fabric Warehouse kræver midlertidig lagring. Indtagelsesprocessen bestod af to faser.
- Den første fase består af at udtrække dataene fra den dedikerede SQL-gruppe til ADLS og kaldes midlertidig.
- Den anden fase består af at hente dataene fra midlertidig lagring til Fabric Warehouse. Det meste af tidspunktet for dataindtagelse er i den midlertidige fase. Kort sagt har midlertidig lagring stor indvirkning på ydeevnen for indtagelse.
Anbefalet brug
Brug af guiden Kopiér til at oprette en ForEach giver en enkel brugergrænseflade til at konvertere DDL og indtage de valgte tabeller fra den dedikerede SQL-pulje til Fabric Warehouse på ét trin.
Det er dog ikke optimalt med det overordnede gennemløb. Kravet om at bruge midlertidig lagring, behovet for at parallelisere læsning og skrivning for trinnet "Kilde til fase" er de vigtigste faktorer for ventetiden for ydeevnen. Det anbefales kun at bruge denne indstilling til dimensionstabeller.
Mulighed 2. DDL/dataoverførsel – Datapipeline ved hjælp af partitionsindstilling
Hvis du vil forbedre gennemløbet for at indlæse større faktatabeller ved hjælp af Fabric-datapipeline, anbefales det at bruge Kopiér aktivitet for hver faktatabel med partitionsindstilling. Dette giver den bedste ydeevne med kopieringsaktivitet.
Du har mulighed for at bruge den fysiske partitionering af kildetabellen, hvis den er tilgængelig. Hvis tabellen ikke har fysisk partitionering, skal du angive partitionskolonnen og angive minimum-/maksimumværdier for at bruge dynamisk partitionering. På følgende skærmbillede angiver indstillingerne for datakilden et dynamisk interval af partitioner, der er baseret på kolonnenws_sold_date_sk.
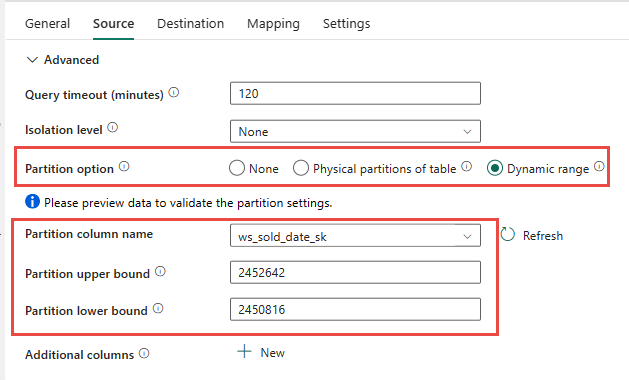
Når du bruger partitionen, kan det øge gennemløbet med den midlertidige fase, men der er overvejelser i forbindelse med at foretage de nødvendige justeringer:
- Afhængigt af dit partitionsområde kan det potentielt bruge alle samtidighedsstik, da det kan generere mere end 128 forespørgsler i den dedikerede SQL-gruppe.
- Du skal skalere til et minimum af DWU6000 for at tillade, at alle forespørgsler udføres.
- For TPC-DS-tabellen
web_salesblev der f.eks. sendt 163 forespørgsler til den dedikerede SQL-gruppe. På DWU6000 blev 128 forespørgsler udført, mens 35 forespørgsler blev sat i kø. - Dynamisk partition vælger automatisk områdepartitionen. I dette tilfælde et 11-dages interval for hver SELECT-forespørgsel, der er sendt til den dedikerede SQL-gruppe. Eksempel:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Anbefalet brug
I forbindelse med faktatabeller anbefaler vi, at du bruger Data Factory med partitioneringsmulighed for at øge dataoverførselshastigheden.
De øgede parallelle læsninger kræver dog, at den dedikerede SQL-pulje skaleres til en højere DWU for at tillade udførelse af udtrækningsforespørgsler. Ved at udnytte partitionering er hastigheden forbedret 10x i forhold til ingen partitionsindstilling. Du kan øge DWU'en for at få yderligere dataoverførselshastighed via beregningsressourcer, men den dedikerede SQL-pulje har maksimalt 128 aktive forespørgsler.
Bemærk
Du kan få flere oplysninger om Synapse DWU til Fabric-tilknytning under Blog: Kortlægning af Azure Synapse dedikerede SQL-puljer til Fabric-data warehouse-beregning.
Mulighed 3. DDL-overførsel – Kopiér guide forHver kopiaktivitet
De to tidligere indstillinger er fantastiske muligheder for dataoverførsel for mindre databaser. Men hvis du har brug for højere gennemløb, anbefaler vi en alternativ indstilling:
- Udtræk dataene fra den dedikerede SQL-pulje til ADLS, og afvis derfor ydeevnen for fasen.
- Brug enten Data Factory eller kommandoen COPY til at overføre dataene til Fabric Warehouse.
Anbefalet brug
Du kan fortsætte med at bruge Data Factory til at konvertere dit skema (DDL). Ved hjælp af guiden Kopiér kan du vælge den specifikke tabel eller Alle tabeller. Dette overfører skemaet og dataene i ét trin og udtrækker skemaet uden nogen rækker ved hjælp af den falske betingelse TOP 0 i forespørgselssætningen.
Følgende kodeeksempel dækker skemaoverførsel (DDL) med Data Factory.
Kodeeksempel: Skemaoverførsel (DDL) med Data Factory
Du kan bruge Fabric Data Pipelines til nemt at migrere over din DDL (skemaer) for tabelobjekter fra alle kilder i Azure SQL Database eller en dedikeret SQL-gruppe. Denne datapipeline migrerer over skemaet (DDL) for kildens dedikerede SQL-puljetabeller til Fabric Warehouse.
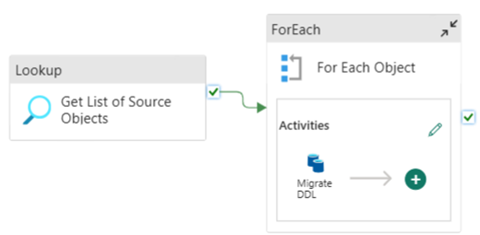
Pipelinedesign: parametre
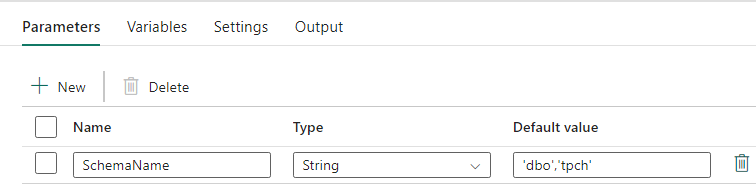
Denne datapipeline accepterer en parameter SchemaName, som giver dig mulighed for at angive, hvilke skemaer der skal overflyttes. Skemaet dbo er standarden.
I feltet Standardværdi skal du angive en kommasepareret liste over tabelskemaer, der angiver, hvilke skemaer der skal migreres: 'dbo','tpch' for at angive to skemaer dbo og tpch.
Pipelinedesign: Opslagsaktivitet
Opret en opslagsaktivitet, og angiv Forbindelsen til at pege på kildedatabasen.
Under fanen Indstillinger:
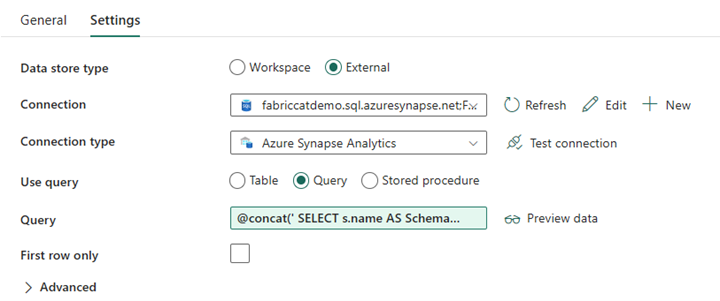
Angiv Datalagertype til Ekstern.
Forbindelse er din Azure Synapse-dedikerede SQL-gruppe. Forbindelsestypen er Azure Synapse Analytics.
Brugsforespørgslen er angivet til Forespørgsel.
Forespørgselsfeltet skal bygges ved hjælp af et dynamisk udtryk, så parameteren SchemaName kan bruges i en forespørgsel, der returnerer en liste over destinationskildetabeller. Vælg Forespørgsel , og vælg derefter Tilføj dynamisk indhold.
Dette udtryk i LookUp Activity genererer en SQL-sætning for at forespørge systemvisninger for at hente en liste over skemaer og tabeller. Refererer til parameteren SchemaName for at tillade filtrering på SQL-skemaer. Outputtet af dette er en matrix af SQL-skemaer og tabeller, der bruges som input i ForEach Activity.
Brug følgende kode til at returnere en liste over alle brugertabeller med skemanavnet.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
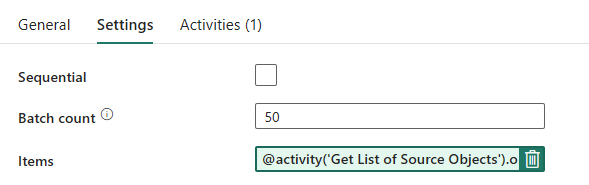
Rørledningsdesign: ForHver løkke
Konfigurer følgende indstillinger under fanen Indstillinger for ForHver løkke:
- Deaktiver Sekventiel for at tillade, at flere gentagelser kører samtidigt.
- Angiv Batchantal til
50, der begrænser det maksimale antal samtidige gentagelser. - Feltet Elementer skal bruge dynamisk indhold til at referere til outputtet fra Opslagsaktivitet. Brug følgende kodestykke:
@activity('Get List of Source Objects').output.value
Pipelinedesign: Kopiér aktivitet i ForHver-løkken
Tilføj en kopiaktivitet i ForHver aktivitet. Denne metode bruger sproget dynamisk udtryk i datapipelines til at oprette en SELECT TOP 0 * FROM <TABLE> til kun at overføre skemaet uden data til et Fabric Warehouse.
Under fanen Kilde:
- Angiv Datalagertype til Ekstern.
- Forbindelse er din Azure Synapse-dedikerede SQL-gruppe. Forbindelsestypen er Azure Synapse Analytics.
- Angiv Brug forespørgsel til forespørgsel.
- I feltet Forespørgsel skal du indsætte den dynamiske indholdsforespørgsel og bruge dette udtryk, som returnerer nul rækker, kun tabelskemaet:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

Under fanen Destination:
- Angiv Datalagertype til Arbejdsområde.
- Datalagertypen Arbejdsområde er Data Warehouse, og Data Warehouse er angivet til Fabric Warehouse.
- Destinationstabellens skema og tabelnavn defineres ved hjælp af dynamisk indhold.
- Skema refererer til feltet for den aktuelle gentagelse, SchemaName med kodestykket:
@item().SchemaName - Table refererer til TableName med kodestykket:
@item().TableName
- Skema refererer til feltet for den aktuelle gentagelse, SchemaName med kodestykket:

Rørledningsdesign: Vask
For Sink skal du pege på lageret og referere til kildeskemaet og tabelnavnet.
Når du kører denne pipeline, kan du se, at dit Data Warehouse er udfyldt med hver tabel i din kilde med det korrekte skema.
Migrering ved hjælp af lagrede procedurer i Synapse-dedikeret SQL-gruppe
Denne indstilling bruger lagrede procedurer til at udføre Fabric Migration.
Du kan få kodeeksempler på microsoft/fabric-migration på GitHub.com. Denne kode deles som åben kildekode, så du er velkommen til at bidrage til at samarbejde og hjælpe community'et.
Hvad lagrede procedurer for migrering kan gøre:
- Konvertér skemaet (DDL) til Fabric Warehouse-syntaksen.
- Opret skemaet (DDL) på Fabric Warehouse.
- Udtræk data fra Synapse-dedikeret SQL-pulje til ADLS.
- Markér ikke-understøttet Fabric-syntaks til T-SQL-koder (lagrede procedurer, funktioner, visninger).
Anbefalet brug
Dette er en fantastisk mulighed for dem, der:
- Kender T-SQL.
- Vil du bruge et integreret udviklingsmiljø, f.eks. SQL Server Management Studio (SSMS).
- Vil have mere detaljeret kontrol over, hvilke opgaver de vil arbejde med.
Du kan udføre den specifikke lagrede procedure for skemakonverteringen (DDL), dataudtrækning eller T-SQL-kodevurdering.
I forbindelse med dataoverførslen skal du enten bruge KOPIÉR TIL eller Data Factory til at hente dataene ind i Fabric Warehouse.
Overfør ved hjælp af SQL-databaseprojekter
Microsoft Fabric Data Warehouse understøttes i udvidelsen SQL Database Projects, der er tilgængelig i Azure Data Studio og Visual Studio Code.
Denne udvidelse er tilgængelig i Azure Data Studio og Visual Studio Code. Denne funktion aktiverer funktioner til kildekontrol, databasetest og skemavalidering.
Du kan få flere oplysninger om kildestyring for lagre i Microsoft Fabric, herunder Git-integrations- og udrulningspipelines, under Kildekontrol med lager.
Anbefalet brug
Dette er en fantastisk mulighed for dem, der foretrækker at bruge SQL Database Project til deres installation. Denne indstilling integrerede i bund og grund de lagrede fabric migration-procedurer i SQL Database Project for at give en problemfri migreringsoplevelse.
Et SQL-databaseprojekt kan:
- Konvertér skemaet (DDL) til Fabric Warehouse-syntaksen.
- Opret skemaet (DDL) på Fabric Warehouse.
- Udtræk data fra Synapse-dedikeret SQL-pulje til ADLS.
- Markér ikke-understøttet syntaks for T-SQL-koder (lagrede procedurer, funktioner, visninger).
I forbindelse med dataoverførslen skal du derefter enten bruge COPY INTO eller Data Factory til at overføre dataene til Fabric Warehouse.
Microsoft Fabric CAT-teamet har tilføjet understøttelsen af Microsoft Fabric i Azure Data Studio og har leveret et sæt PowerShell-scripts til håndtering af udtrækning, oprettelse og udrulning af skema (DDL) og databasekode (DML) via et SQL Database Project. Du kan finde en gennemgang af brugen af SQL Database-projektet med vores nyttige PowerShell-scripts under microsoft/fabric-migration på GitHub.com.
Du kan få flere oplysninger om SQL-databaseprojekter under Introduktion til udvidelsen SQL-databaseprojekter og Opret og udgiv et projekt.
Overførsel af data med CETAS
Kommandoen T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) giver den mest omkostningseffektive og optimale metode til at udtrække data fra Synapse-dedikerede SQL-puljer til Azure Data Lake Storage (ADLS) Gen2.
Hvad CETAS kan gøre:
- Udtræk data til ADLS.
- Denne indstilling kræver, at brugerne opretter skemaet (DDL) på Fabric Warehouse, før dataene indtages. Overvej indstillingerne i denne artikel for at overføre skema (DDL).
Fordelene ved denne indstilling er:
- Der sendes kun en enkelt forespørgsel pr. tabel i forhold til den dedikerede SQL-gruppe Synapse-kilde. Dette bruger ikke alle samtidige slots og blokerer derfor ikke samtidige ETL/forespørgsler til kundeproduktion.
- Skalering til DWU6000 er ikke påkrævet, da der kun bruges et enkelt samtidighedsstik til hver tabel, så kunderne kan bruge lavere DWU'er.
- Udtrækningen køres parallelt på tværs af alle beregningsnoder, og dette er nøglen til forbedring af ydeevnen.
Anbefalet brug
Brug CETAS til at udtrække dataene til ADLS som parquetfiler. Parquet-filer giver fordelen ved effektivt datalager med komprimering af kolonner, der vil tage mindre båndbredde at flytte på tværs af netværket. Da Fabric har gemt dataene som Delta-parquetformat, vil dataindtagelse desuden være 2,5 gange hurtigere sammenlignet med tekstfilformatet, da der ikke er nogen konvertering til deltaformatet under indtagelsen.
Sådan øger du CETAS-gennemløb:
- Tilføj parallelle CETAS-handlinger, hvilket øger brugen af samtidighedsstik, men tillader mere gennemløb.
- Skaler DWU'en på Synapse-dedikeret SQL-pool.
Migrering via dbt
I dette afsnit diskuterer vi dbt-indstillingen for de kunder, der allerede bruger dbt i deres aktuelle Synapse-dedikerede SQL-gruppemiljø.
Hvad dbt kan gøre:
- Konvertér skemaet (DDL) til Fabric Warehouse-syntaksen.
- Opret skemaet (DDL) på Fabric Warehouse.
- Konvertér databasekode (DML) til Fabric-syntaks.
Dbt Framework genererer DDL og DML (SQL-scripts) løbende med hver udførelse. Med modelfiler udtrykt i SELECT-sætninger kan DDL/DML straks oversættes til en hvilken som helst destinationsplatform ved at ændre profilen (forbindelsesstreng) og adaptertypen.
Anbefalet brug
Dbt Framework er code-first-tilgang. Dataene skal overføres ved hjælp af de indstillinger, der er angivet i dette dokument, f.eks . CETAS eller COPY/Data Factory.
Dbt-adapteren til Microsoft Fabric Data Warehouse gør det muligt at migrere eksisterende dbt-projekter, der var målrettet til forskellige platforme, f.eks. Synapse-dedikerede SQL-puljer, Snowflake, Databricks, Google Big Query eller Amazon Redshift, til et Fabric Warehouse med en simpel konfigurationsændring.
Hvis du vil i gang med et dbt-projekt, der er målrettet til Fabric Warehouse, skal du se Selvstudium: Konfigurer dbt til Fabric Data Warehouse. Dette dokument viser også en mulighed for at flytte mellem forskellige lagre/platforme.
Dataindtagelse i Fabric Warehouse
Til indtagelse i Fabric Warehouse skal du bruge COPY INTO eller Fabric Data Factory, afhængigt af dine præferencer. Begge metoder er de anbefalede og mest effektive indstillinger, da de har tilsvarende ydeevneoverførselshastighed, da filerne allerede er udpakket til Azure Data Lake Storage (ADLS) Gen2.
Flere faktorer, du skal være opmærksom på, så du kan designe din proces for at opnå maksimal ydeevne:
- Med Fabric er der ingen ressourcestrid, når du indlæser flere tabeller fra ADLS til Fabric Warehouse samtidigt. Derfor er der ingen forringelse af ydeevnen ved indlæsning af parallelle tråde. Det maksimale gennemløb for indtagelse begrænses kun af beregningskraften for din Fabric-kapacitet.
- Fabric-arbejdsbelastningsstyring giver adskillelse af ressourcer, der er allokeret til belastning og forespørgsel. Der er ingen ressourcestrid, mens forespørgsler og dataindlæsning udføres på samme tid.