Udvikl, evaluer og scor en prognosemodel for salg i supermarkedet
I dette selvstudium præsenteres et helt til slut-eksempel på en Synapse Data Science-arbejdsproces i Microsoft Fabric. Scenariet bygger en prognosemodel, der bruger historiske salgsdata til at forudsige salg af produktkategorier i en supermarked.
Prognoser er et vigtigt aktiv i salget. Den kombinerer historiske data og forudsigende metoder for at give indsigt i fremtidige tendenser. Prognoser kan analysere tidligere salg for at identificere mønstre og lære af forbrugeradfærd for at optimere lager-, produktions- og marketingstrategier. Denne proaktive tilgang forbedrer virksomhedernes tilpasningsevne, svartid og overordnede ydeevne på en dynamisk markedsplads.
I dette selvstudium beskrives disse trin:
- Indlæs dataene
- Brug udforskende dataanalyse til at forstå og behandle dataene
- Oplær en model til maskinel indlæring med en softwarepakke med åben kildekode, og spor eksperimenter med MLflow og funktionen Til automatisk registrering af Fabric
- Gem den endelige model til maskinel indlæring, og foretag forudsigelser
- Vis modellens ydeevne med Power BI-visualiseringer
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Microsoft Fabric-prøveversion.
Log på Microsoft Fabric.
Brug oplevelsesskifteren nederst til venstre på startsiden til at skifte til Fabric.

- Opret om nødvendigt et Microsoft Fabric lakehouse som beskrevet i Opret et lakehouse i Microsoft Fabric.
Følg med i en notesbog
Du kan vælge en af disse indstillinger for at følge med i en notesbog:
- Åbn og kør den indbyggede notesbog i Synapse Data Science-oplevelsen
- Upload din notesbog fra GitHub til Synapse Data Science-oplevelsen
Åbn den indbyggede notesbog
Eksemplet Sales-prognoser notesbog følger med dette selvstudium.
Hvis du vil åbne eksempelnotesbogen til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Importér notesbogen fra GitHub
Den AIsample – Superstore Forecast.ipynb notesbog følger med dette selvstudium.
Hvis du vil åbne den medfølgende notesbog til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab importere notesbogen til dit arbejdsområde.
Hvis du hellere vil kopiere og indsætte koden fra denne side, kan du oprette en ny notesbog.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Trin 1: Indlæs dataene
Datasættet indeholder 9.995 forekomster af salg af forskellige produkter. Den indeholder også 21 attributter. Denne tabel er fra den Superstore.xlsx fil, der bruges i denne notesbog:
| Række-id | Ordre-id | Ordredato | Afsendelsesdato | Leveringstilstand | Kunde-id | Kundenavn | Afsnit | Land | By | Stat | Postnummer | Region | Produkt-id | Kategori | Sub-Category | Produktnavn | Salg | Kvantitet | Rabat | Overskud |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Standardklasse | SO-20335 | Sean O'Donnell | Forbruger | USA | Fort Lauderdale | Florida | 33311 | Syd | FUR-TA-10000577 | Møbler | Tabeller | Bretford CR4500 Series Slim Rektangulær tabel | 957.5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Standardklasse | Standardklasse | Brosina Hoffman | Forbruger | USA | Los Angeles | Californien | 90032 | Vest | FUR-TA-10001539 | Møbler | Tabeller | Rektangulære chromcraft-konferencetabeller | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Standardklasse | TB-21520 | Tracy Blumstein | Forbruger | USA | Philadelphia | Pennsylvania | 19140 | Øst | OFF-DA-10001509 | Kontorartikler | Konvolutter | Poly String Tie Konvolutter | 3.264 | 2 | 0.2 | 1.1016 |
Definer disse parametre, så du kan bruge denne notesbog med forskellige datasæt:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Download datasættet, og upload det til lakehouse
Denne kode downloader en offentligt tilgængelig version af datasættet og gemmer den derefter i et Fabric lakehouse:
Vigtig
Sørg for at føje en lakehouse- til notesbogen, før du kører den. Ellers får du vist en fejl.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Konfigurer sporing af MLflow-eksperiment
Microsoft Fabric registrerer automatisk værdierne for inputparametre og outputmetrik for en model til maskinel indlæring, når du oplærer den. Dette udvider funktionerne til automatisk logning af MLflow. Oplysningerne logføres derefter i arbejdsområdet, hvor du kan få adgang til og visualisere dem med MLflow-API'erne eller det tilsvarende eksperiment i arbejdsområdet. Hvis du vil vide mere om automatisk logning, skal du se Autologging i Microsoft Fabric.
Hvis du vil slå automatisk microsoft Fabric-logging fra i en notesbogsession, skal du ringe til mlflow.autolog() og angive disable=True:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Læs rådata fra lakehouse
Læs rådata fra afsnittet Filer i lakehouse. Tilføj flere kolonner for forskellige datodele. De samme oplysninger bruges til at oprette en partitioneret deltatabel. Da rådata gemmes som en Excel-fil, skal du bruge pandas til at læse dem:
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Trin 2: Udfør udforskning af dataanalyse
Importér biblioteker
Før du foretager en analyse, skal du importere de påkrævede biblioteker:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Vis rådata
Gennemse manuelt et undersæt af dataene for bedre at forstå selve datasættet og bruge funktionen display til at udskrive DataFrame. Desuden kan de Chart visninger nemt visualisere undersæt af datasættet.
display(df)
Denne notesbog fokuserer primært på at forudsige Furniture kategorisalg. Dette fremskynder beregningen og hjælper med at vise modellens ydeevne. Denne notesbog bruger dog tilpassede teknikker. Du kan udvide disse teknikker til at forudsige salget af andre produktkategorier.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Forbehandler dataene
Forretningsscenarier i den virkelige verden skal ofte forudsige salg i tre forskellige kategorier:
- En bestemt produktkategori
- En bestemt kundekategori
- En bestemt kombination af produktkategori og kundekategori
Først skal du slippe unødvendige kolonner for at forbehandle dataene. Nogle af kolonnerne (Row ID, Order ID,Customer IDog Customer Name) er unødvendige, fordi de ikke har nogen indvirkning. Vi vil gerne forudsige det samlede salg på tværs af stat og område for en bestemt produktkategori (Furniture), så vi kan slippe kolonnerne State, Region, Country, Cityog Postal Code. Hvis du vil forudsige salg for en bestemt placering eller kategori, skal du muligvis justere forbehandlingstrinnet i overensstemmelse hermed.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Datasættet er struktureret dagligt. Vi skal omsample kolonnen Order Date, da vi vil udvikle en model til at forudsige salget på månedsbasis.
Gruppér først kategorien Furniture efter Order Date. Beregn derefter summen af kolonnen Sales for hver gruppe for at bestemme det samlede salg for hver entydige Order Date værdi. Gensaml kolonnen Sales med den MS hyppighed for at aggregere dataene efter måned. Til sidst skal du beregne den gennemsnitlige salgsværdi for hver måned.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Demonstrer Order Date indvirkning på Sales for kategorien Furniture:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Før du foretager en statistisk analyse, skal du importere statsmodels Python-modulet. Den indeholder klasser og funktioner til estimering af mange statistiske modeller. Den indeholder også klasser og funktioner til udførelse af statistiske test og udforskning af statistiske data.
import statsmodels.api as sm
Udfør statistisk analyse
En tidsserie sporer disse dataelementer med faste intervaller for at bestemme variationen af disse elementer i tidsseriemønsteret:
niveau: Den grundlæggende komponent, der repræsenterer den gennemsnitlige værdi for en bestemt tidsperiode
tendens: Beskriver, om tidsserierne falder, forbliver konstante eller stiger over tid
seasonality: Beskriver det periodiske signal i tidsserien og søger efter cykliske forekomster, der påvirker mønstrene for stigende eller faldende tidsserier
Støj/Rest: Refererer til de tilfældige udsving og variabilitet i tidsseriedataene, som modellen ikke kan forklare.
I denne kode kan du se disse elementer for dit datasæt efter forbehandlingen:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
Afbildningerne beskriver sæsonudsving, tendenser og støj i prognoserne. Du kan registrere de underliggende mønstre og udvikle modeller, der gør nøjagtige forudsigelser, der er modstandsdygtige over for tilfældige udsving.
Trin 3: Oplær og spor modellen
Nu, hvor du har de tilgængelige data, skal du definere prognosemodellen. I denne notesbog skal du anvende den prognosemodel, der kaldes sæsonbestemt autoregressivt integreret glidende gennemsnit med eksogene faktorer (SARIMAX). SARIMAX kombinerer komponenter af typen autoregressiv (AR) og glidende gennemsnit (MA), sæsonafvigelse og eksterne forudsigelser for at gøre nøjagtige og fleksible prognoser for tidsseriedata.
Du kan også bruge automatisk MLflow og Fabric-logning til at spore eksperimenterne. Her skal du indlæse delta-tabellen fra lakehouse. Du kan bruge andre deltatabeller, der betragter lakehouse som kilden.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Juster hyperparametre
SARIMAX tager højde for de parametre, der er involveret i almindelig AIMA-tilstand (integrated moving average) (p, d, q), og tilføjer sæsonudsvingsparametrene (P, D, Q, s). Disse SARIMAX-modelargumenter kaldes henholdsvis order (p, d, q) og sæsonbestemte ordre (P, D, Q, s). Derfor skal vi først finjustere syv parametre for at oplære modellen.
Ordreparametrene:
p: Rækkefølgen af AR-komponenten, der repræsenterer antallet af tidligere observationer i den tidsserie, der bruges til at forudsige den aktuelle værdi.Denne parameter skal typisk være et heltal, der ikke er negativt. Almindelige værdier er inden for området
0til3, selvom højere værdier er mulige, afhængigt af de specifikke dataegenskaber. En højerepværdi angiver en længere hukommelse med tidligere værdier i modellen.d: Den forskellige rækkefølge, der repræsenterer det antal gange, tidsserien skal være forskellig, for at opnå stationaritet.Denne parameter skal være et heltal, der ikke er negativt. Almindelige værdier er inden for området
0til2. Endværdi af0betyder, at tidsserien allerede er stationær. Højere værdier angiver antallet af forskellige handlinger, der kræves for at gøre det stationært.q: Rækkefølgen af ma-komponenten, der repræsenterer antallet af tidligere fejlord for hvidstøj, der blev brugt til at forudsige den aktuelle værdi.Denne parameter skal være et heltal, der ikke er negativt. Almindelige værdier er inden for området
0til3, men højere værdier kan være nødvendige for visse tidsserier. En højereqværdi angiver en større afhængighed af tidligere fejlord for at foretage forudsigelser.
Parametrene for sæsonbestemt rækkefølge:
-
P: Ar-komponentens sæsonrækkefølge svarer tilp, men for den sæsonbestemte del -
D: Sæsonudsvingene svarer tild, men for den sæsonbestemte del -
Q: Ma-komponentens sæsonbestemte rækkefølge, svarende tilq, men for sæsonbestemt del -
s: Antallet af tidstrin pr. sæsoncyklus (f.eks. 12 for månedlige data med en årlig sæsonudsving)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX har andre parametre:
enforce_stationarity: Hvorvidt modellen skal gennemtvinge stationaritet på tidsseriedataene, før SARIMAX-modellen monteres.Hvis
enforce_stationarityer angivet tilTrue(standard), angiver det, at SARIMAX-modellen skal gennemtvinge stationaritet på tidsseriedataene. SARIMAX-modellen anvender derefter automatisk differencing på dataene for at gøre dem stationære, som angivet idogDordrer, før modellen monteres. Dette er en almindelig praksis, fordi mange tidsseriemodeller, herunder SARIMAX, antager, at dataene er stationære.For en ikke-stationær tidsserie (f.eks. udviser den tendenser eller sæsonudsving), er det god praksis at angive
enforce_stationaritytilTrueog lade SARIMAX-modellen håndtere forskellen for at opnå stationaritet. I forbindelse med en stationær tidsserie (f.eks. en uden tendenser eller sæsonudsving) skal du indstilleenforce_stationaritytil atFalsefor at undgå unødvendig afvigelse.enforce_invertibility: Styrer, om modellen skal gennemtvinge invertabilitet på de anslåede parametre under optimeringsprocessen.Hvis
enforce_invertibilityer angivet tilTrue(standard), angiver det, at SARIMAX-modellen skal gennemtvinge invertabilitet på de anslåede parametre. Invertabilitet sikrer, at modellen er veldefineret, og at de anslåede AR- og MA-koefficienter lander inden for stationaritetsintervallet.Håndhævelse af invertabilitet hjælper med at sikre, at SARIMAX-modellen overholder de teoretiske krav til en stabil tidsseriemodel. Det hjælper også med at forhindre problemer med modelestimering og stabilitet.
Standarden er en AR(1) model. Dette refererer til (1, 0, 0). Det er dog almindelig praksis at prøve forskellige kombinationer af ordreparametre og sæsonbestemte ordreparametre og evaluere modellens ydeevne for et datasæt. De relevante værdier kan variere fra én tidsserie til en anden.
Bestemmelse af de optimale værdier omfatter ofte analyse af funktionen autocorrelation (ACF) og en delvis autocorrelationsfunktion (PACF) for tidsseriedataene. Det omfatter også ofte brug af kriterier for modelvalg – f.eks. Akaike-oplysningskriteriet (AIC) eller Bayesian-oplysningskriteriet (BIC).
Juster hyperparametrene:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Når du har evalueret de foregående resultater, kan du bestemme værdierne for både ordreparametrene og sæsonbestemte ordreparametre. Valget er order=(0, 1, 1) og seasonal_order=(0, 1, 1, 12), som tilbyder det laveste AIC (f.eks. 279,58). Brug disse værdier til at oplære modellen.
Oplær modellen
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Denne kode visualiserer en tidsserieprognose for salgsdata for møbler. De afbildede resultater viser både de observerede data og prognosen med ét trin foran med et skyggelagt område for konfidensinterval.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Brug predictions til at vurdere modellens ydeevne ved at kontrastere den med de faktiske værdier. Værdien predictions_future angiver fremtidig prognose.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Trin 4: Scor modellen, og gem forudsigelser
Integrer de faktiske værdier med de budgetterede værdier for at oprette en Power BI-rapport. Gem disse resultater i en tabel i lakehouse.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Trin 5: Visualiser i Power BI
Power BI-rapporten viser en fejl i den gennemsnitlige absolutte procentdel (MAPE) på 16,58. MAPE-metrikværdien definerer nøjagtigheden af en prognosemetode. Den repræsenterer nøjagtigheden af de forventede mængder i forhold til de faktiske mængder.
MAPE er en enkel metrikværdi. En 10-% MAPE repræsenterer, at den gennemsnitlige afvigelse mellem de budgetterede værdier og de faktiske værdier er 10%, uanset om afvigelsen var positiv eller negativ. Standarderne for de ønskede MAPE-værdier varierer fra branche til branche.
Den lyseblå linje i denne graf repræsenterer de faktiske salgsværdier. Den mørkeblå linje repræsenterer de budgetterede salgsværdier. Sammenligning af faktisk og forventet salg viser, at modellen effektivt forudsiger salg for den Furniture kategori i løbet af de første seks måneder af 2023.
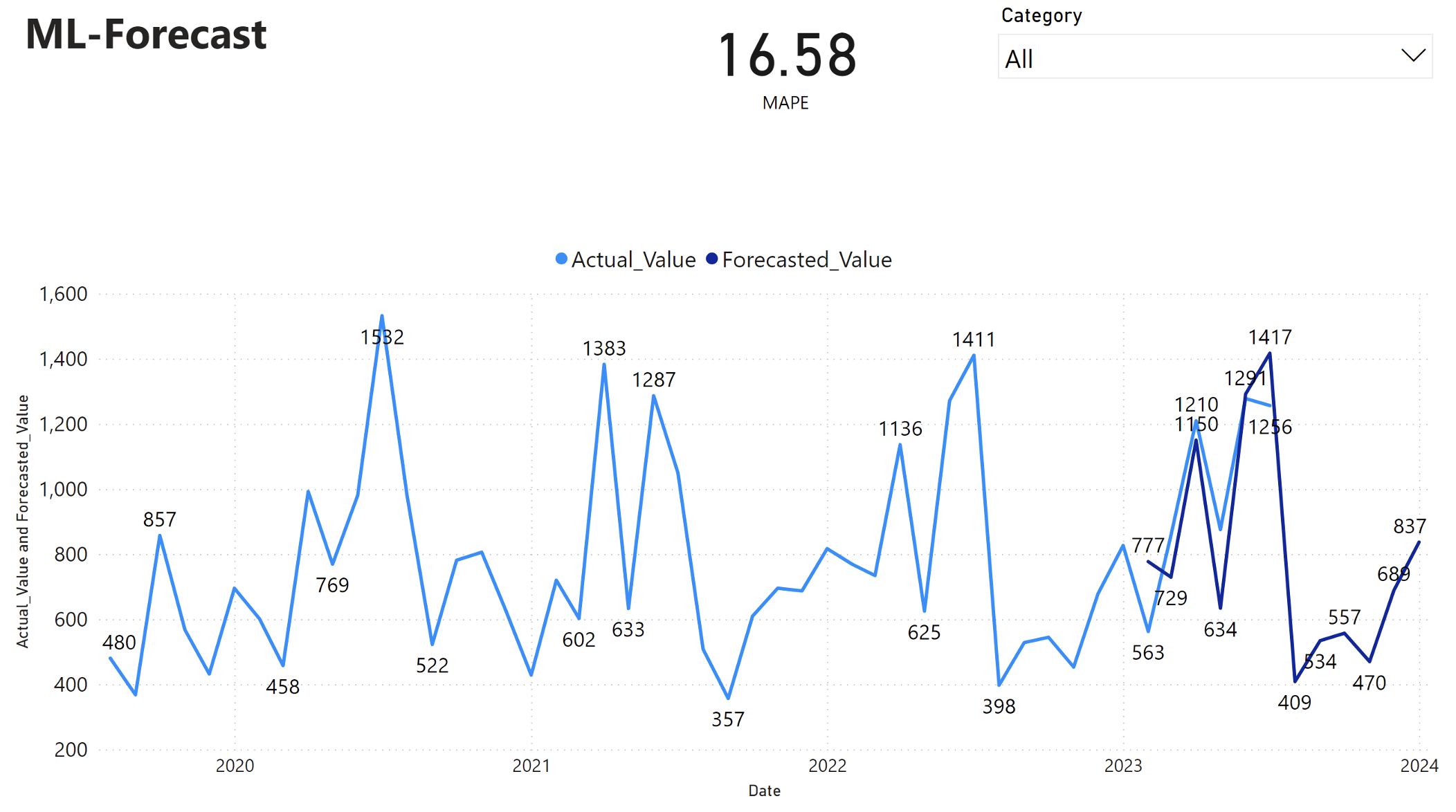
På baggrund af denne observation kan vi have tillid til modellens prognoser for det samlede salg i de sidste seks måneder af 2023 og udvide til 2024. Denne tillid kan informere strategiske beslutninger om lagerstyring, indkøb af råmaterialer og andre forretningsrelaterede overvejelser.