Eksperimenter med maskinel indlæring i Microsoft Fabric
En maskinel indlæring eksperiment er den primære enhed i organisationen og styringen for alle relaterede machine learning-kørsler. En kørsel svarer til en enkelt udførelse af modelkoden. I MLflow-er sporing baseret på eksperimenter og kørsler.
Eksperimenter med maskinel indlæring gør det muligt for datateknikere at logføre parametre, kodeversioner, målepunkter og outputfiler, når de kører deres kode til maskinel indlæring. Med eksperimenter kan du også visualisere, søge efter og sammenligne kørsler samt downloade kørselsfiler og metadata til analyse i andre værktøjer.
I denne artikel kan du få mere at vide om, hvordan dataspecialister kan interagere med og bruge eksperimenter med maskinel indlæring til at organisere deres udviklingsproces og til at spore flere kørsler.
Forudsætninger
- Et Power BI Premium-abonnement. Hvis du ikke har en, kan du se Sådan køber du Power BI Premium.
- Et Power BI-arbejdsområde med tildelt Premium-kapacitet.
Opret et eksperiment
Du kan oprette et maskinel indlæringseksperiment direkte fra brugergrænsefladen i stoffet eller ved at skrive kode, der bruger MLflow-API'en.
Opret et eksperiment ved hjælp af brugergrænsefladen
Sådan opretter du et maskinel indlæringseksperiment fra brugergrænsefladen:
- Opret et nyt arbejdsområde, eller vælg et eksisterende arbejdsområde.
- Du kan oprette et nyt element via arbejdsområdet eller ved hjælp af Opret.
- Arbejdsområde:
- Vælg dit arbejdsområde.
- Vælg Nyt element.
- Vælg Eksperimentér under Analysér og oplær data.
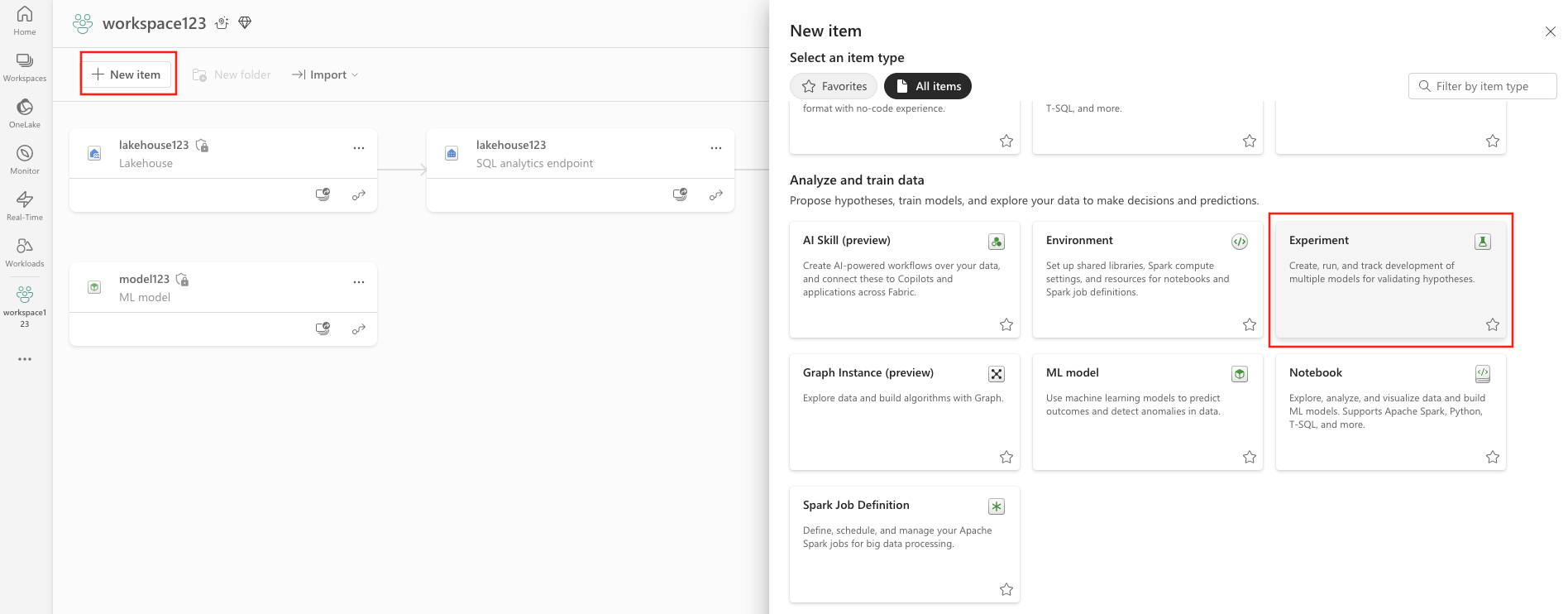
- Knappen Opret:
- Vælg Opret, som findes i ... i den lodrette menu.
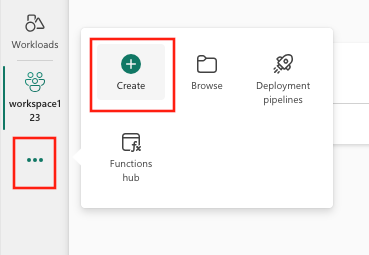
- Vælg Eksperimentér under datavidenskab.
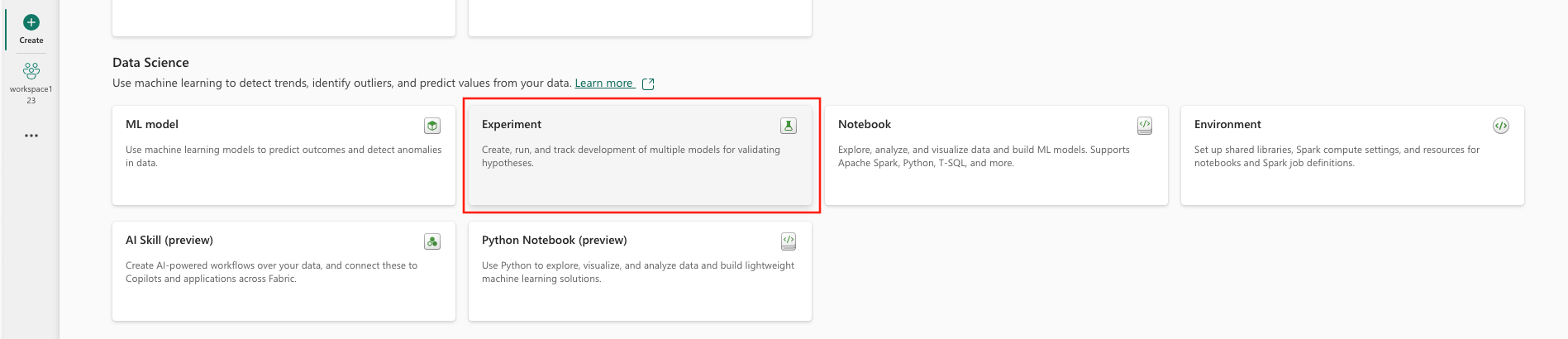
- Vælg Opret, som findes i ... i den lodrette menu.
- Arbejdsområde:
- Angiv et eksperimentnavn, og vælg Opret. Denne handling opretter et tomt eksperiment i dit arbejdsområde.



Når du har oprettet eksperimentet, kan du begynde at tilføje kørsler for at spore kørselsdata og -parametre.
Opret et eksperiment ved hjælp af MLflow-API'en
Du kan også oprette et maskinel indlæringseksperiment direkte fra din oprettelsesoplevelse ved hjælp af API'erne til mlflow.create_experiment() eller mlflow.set_experiment(). I følgende kode skal du erstatte <EXPERIMENT_NAME> med eksperimentets navn.
import mlflow
# This will create a new experiment with the provided name.
mlflow.create_experiment("<EXPERIMENT_NAME>")
# This will set the given experiment as the active experiment.
# If an experiment with this name does not exist, a new experiment with this name is created.
mlflow.set_experiment("<EXPERIMENT_NAME>")
Administrer kørsler i et eksperiment
Et maskinel indlæringseksperiment indeholder en samling kørsler til forenklet sporing og sammenligning. I et eksperiment kan en dataforsker navigere på tværs af forskellige kørsler og udforske de underliggende parametre og målepunkter. Dataspecialister kan også sammenligne kørsler i et maskinel indlæringseksperiment for at identificere, hvilket undersæt af parametre der giver en ønsket modelydeevne.
Spor kørsler
En maskinel indlæringskørsel svarer til en enkelt udførelse af modelkode.

Hver kørsel indeholder følgende oplysninger:
- Kilde: Navnet på den notesbog, der oprettede kørslen.
- Registreret version: Angiver, om kørslen blev gemt som en model til maskinel indlæring.
- Startdato: Starttidspunkt for kørslen.
- Status: Kørselsstatus.
- Hyperparameters: Hyperparameters gemt som nøgleværdipar. Både nøgler og værdier er strenge.
- målepunkter: Kør målepunkter, der er gemt som nøgleværdipar. Værdien er numerisk.
- Outputfiler: Outputfiler i et hvilket som helst format. Du kan f.eks. optage billeder, miljø, modeller og datafiler.
- tags: Metadata som nøgleværdipar til kørsler.
Vis seneste kørsler
Du kan også få vist de seneste kørsler for et eksperiment ved at vælge Kør liste. Denne visning giver dig mulighed for at holde styr på de seneste aktiviteter, hurtigt gå til det relaterede Spark-program og anvende filtre baseret på kørselsstatussen.

Sammenlign og filtrer kørsler
Hvis du vil sammenligne og evaluere kvaliteten af dine kørsler af maskinel indlæring, kan du sammenligne parametre, målepunkter og metadata mellem valgte kørsler i et eksperiment.
Anvend mærker på kørsler
MLflow-mærkning for eksperimentkørsler giver brugerne mulighed for at føje brugerdefinerede metadata i form af nøgleværdipar til deres kørsler. Disse mærker hjælper med at kategorisere, filtrere og søge efter kørsler baseret på bestemte attributter, hvilket gør det nemmere at administrere og analysere eksperimenter på MLflow-platformen. Brugerne kan bruge mærker til at mærke kørsler med oplysninger som modeltyper, parametre eller relevante identifikatorer, hvilket forbedrer den overordnede organisation og sporing af eksperimenter.
Dette kodestykke starter en MLflow-kørsel, logfører nogle parametre og målepunkter og tilføjer mærker for at kategorisere og angive yderligere kontekst for kørslen.
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.datasets import fetch_california_housing
# Autologging
mlflow.autolog()
# Load the California housing dataset
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Start an MLflow run
with mlflow.start_run() as run:
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict and evaluate
y_pred = model.predict(X_test)
# Add tags
mlflow.set_tag("model_type", "Linear Regression")
mlflow.set_tag("dataset", "California Housing")
mlflow.set_tag("developer", "Bob")
Når mærkerne er anvendt, kan du derefter få vist resultaterne direkte fra den indbyggede MLflow-widget eller fra siden med kørselsoplysninger.

Advarsel
advarsel! Begrænsninger for anvendelse af mærker på MLflow Experiment Runs i Fabric
- koder, der ikke er tomme,: Kodenavne eller -værdier må ikke være tomme. Hvis du forsøger at anvende en kode med et tomt navn eller en tom værdi, mislykkes handlingen.
- mærkenavne: Mærkenavne kan være op til 250 tegn lange.
- Mærkeværdier: Mærkeværdier kan være op til 5000 tegn lange.
-
begrænsede kodenavne: Kodenavne, der starter med visse præfikser, understøttes ikke. Kodenavne, der starter med
synapseml,mlflowellertrident, er begrænset og accepteres ikke.
Sammenlign kørsler visuelt
Du kan visuelt sammenligne og filtrere kørsler i et eksisterende eksperiment. Visuel sammenligning giver dig mulighed for nemt at navigere mellem flere kørsler og sortere på tværs af dem.

Sådan sammenligner du kørsler:
- Vælg et eksisterende maskinel indlæringseksperiment, der indeholder flere kørsler.
- Vælg fanen Vis, og gå derefter til listen Kør visning. Du kan også vælge indstillingen for at Visningskørselsliste direkte fra visningen Kør oplysninger.
- Tilpas kolonnerne i tabellen ved at udvide ruden Tilpas kolonner. Her kan du vælge de egenskaber, målepunkter, mærker og hyperparametre, du vil have vist.
- Udvid ruden Filter for at indsnævre resultaterne baseret på visse valgte kriterier.
- Vælg flere kørsler for at sammenligne deres resultater i ruden til sammenligning af målepunkter. I denne rude kan du tilpasse diagrammerne ved at ændre diagramtitlen, visualiseringstypen, X-aksen, Y-aksen og meget mere.
Sammenlign kørsler ved hjælp af MLflow-API'en
Dataspecialister kan også bruge MLflow til at forespørge på og søge blandt kørsler i et eksperiment. Du kan udforske flere MLflow-API'er til søgning, filtrering og sammenligning af kørsler ved at besøge dokumentationen til MLflow.
Hent alle kørsler
Du kan bruge MLflow-søge-API'en mlflow.search_runs() til at få alle kørsler i et eksperiment ved at erstatte <EXPERIMENT_NAME> med dit eksperimentnavn eller <EXPERIMENT_ID> med dit eksperiment-id i følgende kode:
import mlflow
# Get runs by experiment name:
mlflow.search_runs(experiment_names=["<EXPERIMENT_NAME>"])
# Get runs by experiment ID:
mlflow.search_runs(experiment_ids=["<EXPERIMENT_ID>"])
Drikkepenge
Du kan søge på tværs af flere eksperimenter ved at angive en liste over eksperiment-id'er til parameteren experiment_ids. På samme måde gør det muligt for MLflow at søge på tværs af flere eksperimenter ved at angive en liste over eksperimentnavne til parameteren experiment_names. Dette kan være nyttigt, hvis du vil sammenligne på tværs af kørsler i forskellige eksperimenter.
Bestil og begræns kørsler
Brug parameteren max_results fra search_runs til at begrænse antallet af returnerede kørsler. Med parameteren order_by kan du angive kolonner, der skal sorteres efter, og den kan indeholde en valgfri DESC eller ASC værdi. Følgende eksempel returnerer f.eks. den sidste kørsel af et eksperiment.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["start_time DESC"])
Sammenlign kørsler i en Fabric-notesbog
Du kan bruge widgetten OPRETTELSE af MLFlow i Fabric-notesbøger til at spore MLflow-kørsler, der er genereret i hver notesbogcelle. Widgetten giver dig mulighed for at spore dine kørsler, tilknyttede målepunkter, parametre og egenskaber helt ned til det individuelle celleniveau.
Hvis du vil have en visuel sammenligning, kan du også skifte til Kør sammenligning visning. Denne visning viser dataene grafisk og hjælper med hurtigt at identificere mønstre eller afvigelser på tværs af forskellige kørsler.

Gem kørsel som en model til maskinel indlæring
Når en kørsel giver det ønskede resultat, kan du gemme kørslen som en model til forbedret modelsporing og til modelinstallation ved at vælge Gem som en ML-model.

Overvåg ML-eksperimenter (prøveversion)
ML-eksperimenter er integreret direkte i Monitor. Denne funktionalitet er designet til at give mere indsigt i dine Spark-programmer og de ML-eksperimenter, de genererer, hvilket gør det nemmere at administrere og foretage fejlfinding af disse processer.
Spor kørsler fra skærm
Brugerne kan spore eksperimentkørsler direkte fra overvågning, hvilket giver en samlet visning af alle deres aktiviteter. Denne integration omfatter filtreringsindstillinger, så brugerne kan fokusere på eksperimenter eller kørsler, der er oprettet inden for de seneste 30 dage eller andre angivne perioder.

Spor relaterede ML Experiment-kørsler fra dit Spark-program
ML Experiment er integreret direkte i Monitor, hvor du kan vælge et bestemt Spark-program og få adgang til snapshots af elementer. Her finder du en liste over alle de eksperimenter og kørsler, der genereres af det pågældende program.