Selvstudium: Opret, evaluer og scor et anbefalingssystem
I dette selvstudium præsenteres et helt til slut-eksempel på en Synapse Data Science-arbejdsproces i Microsoft Fabric. Scenariet bygger en model til anbefalinger til onlinebøger.
I dette selvstudium beskrives disse trin:
- Upload dataene til et lakehouse
- Udfør udforskningsanalyse af dataene
- Oplær en model, og logfør den med MLflow
- Indlæs modellen, og foretag forudsigelser
Vi har mange tilgængelige typer anbefalingsalgoritmer. I dette selvstudium bruges ALS-matrixfaktoralgoritmen (Alternating Least Squares). ALS er en modelbaseret samarbejdsbaseret filtreringsalgoritme.

ALS forsøger at anslå bedømmelsesmatrixen R som produktet af to matrixer med lavere rangering, dig og V. Her, R = U * Vt. Disse tilnærmelser kaldes typisk faktor matrixer.
ALS-algoritmen er iterativ. Hver gentagelse har en af faktormatrets konstant, mens den løser den anden ved hjælp af metoden med mindst kvadrater. Den holder derefter fast i den nyligt løste faktormatrix, mens den løser den anden faktormatrix.

Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Microsoft Fabric-prøveversion.
Log på Microsoft Fabric.
Brug oplevelsesskifteren nederst til venstre på startsiden til at skifte til Fabric.

- Opret om nødvendigt et Microsoft Fabric lakehouse som beskrevet i Opret et lakehouse i Microsoft Fabric.
Følg med i en notesbog
Du kan vælge en af disse indstillinger for at følge med i en notesbog:
- Åbn og kør den indbyggede notesbog.
- Upload din notesbog fra GitHub.
Åbn den indbyggede notesbog
Eksemplet Book-anbefaling notesbog følger med dette selvstudium.
Hvis du vil åbne eksempelnotesbogen til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Importér notesbogen fra GitHub
AIsample – Book Recommendation.ipynb notesbog følger med dette selvstudium.
Hvis du vil åbne den medfølgende notesbog til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab importere notesbogen til dit arbejdsområde.
Hvis du hellere vil kopiere og indsætte koden fra denne side, kan du oprette en ny notesbog.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Trin 1: Indlæs dataene
Datasættet med bogens anbefaling i dette scenarie består af tre separate datasæt:
Books.csv: Et internationalt standardbogsnummer (ISBN) identificerer hver bog, hvor ugyldige datoer allerede er fjernet. Datasættet indeholder også titlen, forfatteren og udgiveren. I forbindelse med en bog med flere forfattere viser Books.csv-filen kun den første forfatter. URL-adresser peger på Amazon-webstedsressourcer for forsidebillederne i tre størrelser.
ISBN Book-Title Book-Author År-Of-Publication Forlægger Billede -URL-S Billede -URL-M Image-URL-l 0195153448 Klassisk mytologi Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Canada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: Bedømmelser for hver bog er enten eksplicitte (angivet af brugerne på en skala fra 1 til 10) eller implicitte (observeret uden brugerinput og angivet med 0).
User-ID ISBN Book-Rating 276725 034545104X 0 276726 0155061224 5 Users.csv: Bruger-id'er anonymiseres og knyttes til heltal. Demografiske data – f.eks. placering og alder – angives, hvis de er tilgængelige. Hvis disse data ikke er tilgængelige, er disse værdier
null.User-ID Sted Alder 1 "nyc New York USA" 2 "Stockton California USA" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Definer disse parametre, så du kan bruge denne notesbog med forskellige datasæt:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Download og gem dataene i et lakehouse
Denne kode downloader datasættet og gemmer det derefter i lakehouse.
Vigtig
Sørg for at føje en lakehouse- til notesbogen, før du kører den. Ellers får du vist en fejl.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Konfigurer sporing af MLflow-eksperiment
Brug denne kode til at konfigurere sporingen af MLflow-eksperimentet. I dette eksempel deaktiveres automatisk logning. Du kan få flere oplysninger i artiklen Autologging i Microsoft Fabric.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Læs data fra lakehouse
Når de korrekte data er placeret i lakehouse, kan du læse de tre datasæt i separate Spark DataFrames i notesbogen. Filstierne i denne kode bruger de parametre, der er defineret tidligere.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Trin 2: Udfør udforskning af dataanalyse
Vis rådata
Udforsk DataFrames med kommandoen display. Med denne kommando kan du få vist dataframestatistik på højt niveau og forstå, hvordan forskellige datasætkolonner er relateret til hinanden. Før du udforsker datasættene, skal du bruge denne kode til at importere de påkrævede biblioteker:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Brug denne kode til at se på den DataFrame, der indeholder bogdataene:
display(df_items, summary=True)
Tilføj en _item_id kolonne til senere brug. Værdien _item_id skal være et heltal for anbefalingsmodeller. Denne kode bruger StringIndexer til at transformere ITEM_ID_COL til indeks:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Vis DataFrame, og kontrollér, om den _item_id værdi stiger monotont og efter hinanden som forventet:
display(df_items.sort(F.col("_item_id").desc()))
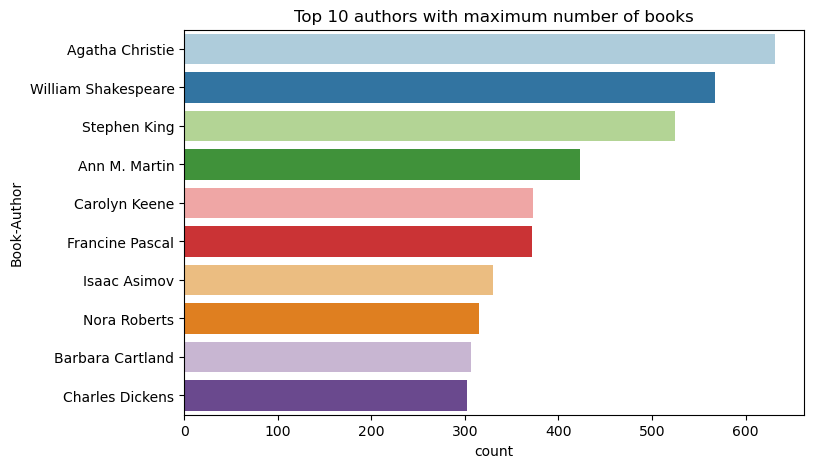
Brug denne kode til at afbilde de ti øverste forfattere efter antal bøger skrevet i faldende rækkefølge. Agatha Christie er den førende forfatter med mere end 600 bøger, efterfulgt af William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Derefter skal du vise den DataFrame, der indeholder brugerdataene:
display(df_users, summary=True)
Hvis en række mangler en User-ID værdi, skal du slippe den pågældende række. Manglende værdier i et brugerdefineret datasæt forårsager ikke problemer.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Tilføj en _user_id kolonne til senere brug. For anbefalingsmodeller skal den _user_id værdi være et heltal. I følgende kodeeksempel bruges StringIndexer til at transformere USER_ID_COL til indeks.
Bogdatasættet har allerede et heltal User-ID kolonne. Hvis du tilføjer en _user_id kolonne for kompatibilitet med forskellige datasæt, bliver dette eksempel dog mere robust. Brug denne kode til at tilføje kolonnen _user_id:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Brug denne kode til at få vist bedømmelsesdata:
display(df_ratings, summary=True)
Hent de entydige bedømmelser, og gem dem til senere brug på en liste med navnet ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
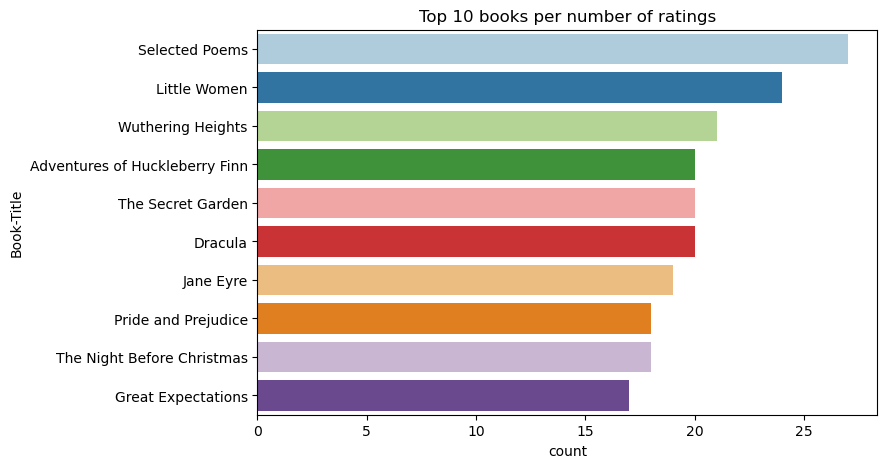
Brug denne kode til at få vist de ti mest populære bøger med de højeste bedømmelser:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Ifølge bedømmelserne er Selected Poems den mest populære bog. Adventures of Huckleberry Finn, The Secret Garden, og Dracula har samme bedømmelse.
Flet data
Flet de tre DataFrames til én DataFrame for at få en mere omfattende analyse:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Brug denne kode til at få vist en optælling af de forskellige brugere, bøger og interaktioner:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Udregn og afbild de mest populære elementer
Brug denne kode til at beregne og vise de ti mest populære bøger:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Drikkepenge
Brug værdien <topn> for sektionerne Populære eller Mest købte anbefalinger.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Forbered oplærings- og testdatasæt
ALS-matrixen kræver noget dataforberedelse før oplæring. Brug dette kodeeksempel til at forberede dataene. Koden udfører disse handlinger:
- Angiv bedømmelseskolonnen til den korrekte type
- Eksempel på oplæringsdata med brugerklassifikationer
- Opdel dataene i oplærings- og testdatasæt
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Sparsity refererer til sparsomme feedbackdata, som ikke kan identificere ligheder i brugernes interesser. Hvis du vil have en bedre forståelse af både dataene og det aktuelle problem, skal du bruge denne kode til at beregne sparsomme datasæt:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Trin 3: Udvikl og oplær modellen
Oplær en ALS-model for at give brugerne tilpassede anbefalinger.
Definer modellen
Spark ML indeholder en praktisk API til oprettelse af ALS-modellen. Modellen håndterer dog ikke pålideligt problemer som f.eks. datas sparsitet og kold start (giver anbefalinger, når brugerne eller elementerne er nye). Hvis du vil forbedre modellens ydeevne, skal du kombinere krydsvalidering og automatisk justering af hyperparametre.
Brug denne kode til at importere de biblioteker, der kræves til modeltræning og -evaluering:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Juster model hyperparametre
Det næste kodeeksempel konstruerer et parametergitter for at hjælpe med at søge efter hyperparametrene. Koden opretter også en regressions evaluator, der bruger rod-middelvejsfejlen (RMSE) som evalueringsmetrik:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
I det næste kodeeksempel startes forskellige modeljusteringsmetoder baseret på forudkonfigurerede parametre. Du kan få flere oplysninger om modeljustering under ML Tuning: modelvalg og hyperparameterjustering på Apache Spark-webstedet.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Evaluer modellen
Du bør evaluere moduler i forhold til testdataene. En veluddannet model skal have høje målepunkter for datasættet.
En overlejret model kan kræve en forøgelse af træningsdataenes størrelse eller en reduktion af nogle af de redundante funktioner. Modelarkitekturen skal muligvis ændres, eller dens parametre skal muligvis finjusteres.
Seddel
En negativ R-kvadreret metrikværdi angiver, at den oplærte model klarer sig dårligere end en vandret lige linje. Denne konstatering antyder, at den oplærte model ikke forklarer dataene.
Hvis du vil definere en evalueringsfunktion, skal du bruge denne kode:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Spor eksperimentet ved hjælp af MLflow
Brug MLflow til at spore alle eksperimenter og til at logføre parametre, målepunkter og modeller. Hvis du vil starte modeltræning og -evaluering, skal du bruge denne kode:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Vælg eksperimentet med navnet aisample-recommendation fra dit arbejdsområde for at få vist de logførte oplysninger om oplæringskørslen. Hvis du har ændret eksperimentnavnet, skal du vælge det eksperiment, der har det nye navn. De logførte oplysninger ligner dette billede:

Trin 4: Indlæs den endelige model til scoring, og foretag forudsigelser
Når du er færdig med modeltræningen og derefter vælger den bedste model, skal du indlæse modellen til scoring (også kaldet udledning). Denne kode indlæser modellen og bruger forudsigelser til at anbefale de ti øverste bøger for hver bruger:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
Outputtet ligner denne tabel:
| _item_id | _user_id | Rating | Book-Title |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Liv ... |
| 786 | 7 | 6.2255826 | Klavermandens D... |
| 45330 | 7 | 4.980466 | Sindstilstand |
| 38960 | 7 | 4.980466 | Alt, hvad han nogensinde har ønsket |
| 125415 | 7 | 4.505084 | Harry Potter og ... |
| 44939 | 7 | 4.3579073 | Taltos: Liv ... |
| 175247 | 7 | 4.3579073 | Knoglerne er ... |
| 170183 | 7 | 4.228735 | At leve det enkle... |
| 88503 | 7 | 4.221206 | Øen Blu... |
| 32894 | 7 | 3.9031885 | Vintersolhverv |
Gem forudsigelserne i lakehouse
Brug denne kode til at skrive anbefalingerne tilbage til lakehouse:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)