Sådan opretter du brugerdefinerede Spark-puljer i Microsoft Fabric
I dette dokument forklarer vi, hvordan du opretter brugerdefinerede Apache Spark-puljer i Microsoft Fabric til dine analysearbejdsbelastninger. Apache Spark-puljer gør det muligt for brugerne at oprette skræddersyede beregningsmiljøer baseret på deres specifikke krav og sikre optimal ydeevne og ressourceudnyttelse.
Du angiver minimum- og maksimumnoder for automatisk skalering. Baseret på disse værdier henter og udfaser systemet dynamisk noder, når jobbets beregningskrav ændres, hvilket resulterer i effektiv skalering og forbedret ydeevne. Den dynamiske allokering af eksekutorer i Spark-puljer afhjælper også behovet for manuel konfiguration af eksekvering. I stedet justerer systemet antallet af eksekveringsmaskiner afhængigt af datamængden og beregningsbehovene på jobniveau. Denne proces giver dig mulighed for at fokusere på dine arbejdsbelastninger uden at bekymre dig om optimering af ydeevnen og ressourcestyring.
Seddel
Hvis du vil oprette en brugerdefineret Spark-gruppe, skal du have administratoradgang til arbejdsområdet. Kapacitetsadministratoren skal aktivere indstillingen
Opret brugerdefinerede Spark-puljer
Sådan opretter eller administrerer du den Spark-gruppe, der er knyttet til dit arbejdsområde:
Gå til dit arbejdsområde, og vælg Indstillinger for arbejdsområde.
Vælg indstillingen
Data Engineering/Science for at udvide menuen, og vælg derefter Spark-indstillinger .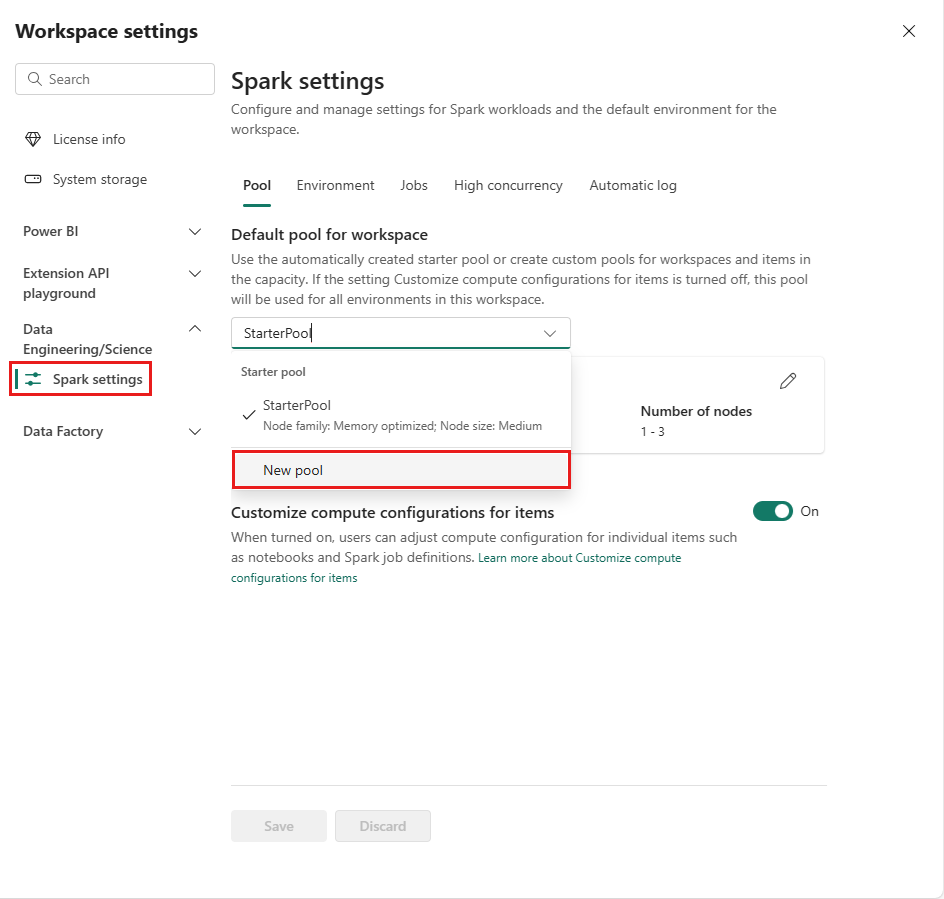
Vælg indstillingen
Ny pulje. På skærmen Opret gruppe skal du navngive din Spark-pulje. Vælg også Node-serien, og vælg en Nodestørrelse blandt de tilgængelige størrelser (Lille, Mellem, Stor, X-Storog XX-Stor) baseret på beregningskrav til dine arbejdsbelastninger. 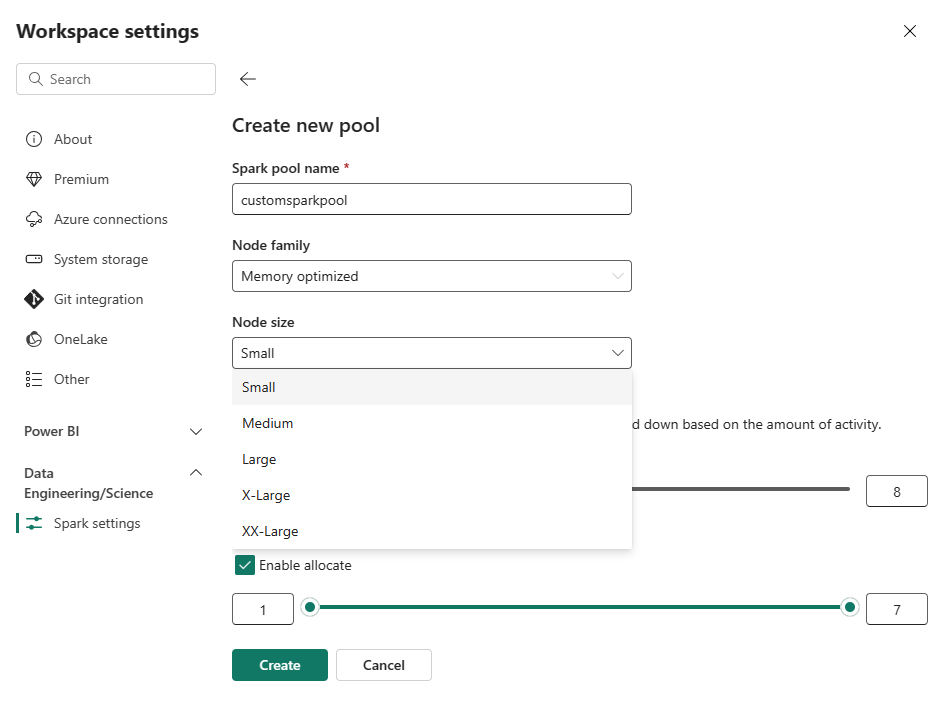
Du kan angive den mindste nodekonfiguration for dine brugerdefinerede puljer til 1. Da Fabric Spark giver restorable tilgængelighed for klynger med en enkelt node, behøver du ikke at bekymre dig om jobfejl, tab af session under fejl eller over betaling af beregning for mindre Spark-job.
Du kan aktivere eller deaktivere automatisk skalering for dine brugerdefinerede Spark-puljer. Når automatisk skalering er aktiveret, henter gruppen dynamisk nye noder op til den maksimale nodegrænse, der er angivet af brugeren, og trækker dem derefter tilbage efter udførelse af jobbet. Denne funktion sikrer bedre ydeevne ved at justere ressourcer baseret på jobkravene. Du har tilladelse til at tilpasse størrelsen på de noder, der passer til de kapacitetsenheder, der er købt som en del af Fabric-kapacitets-SKU'en.
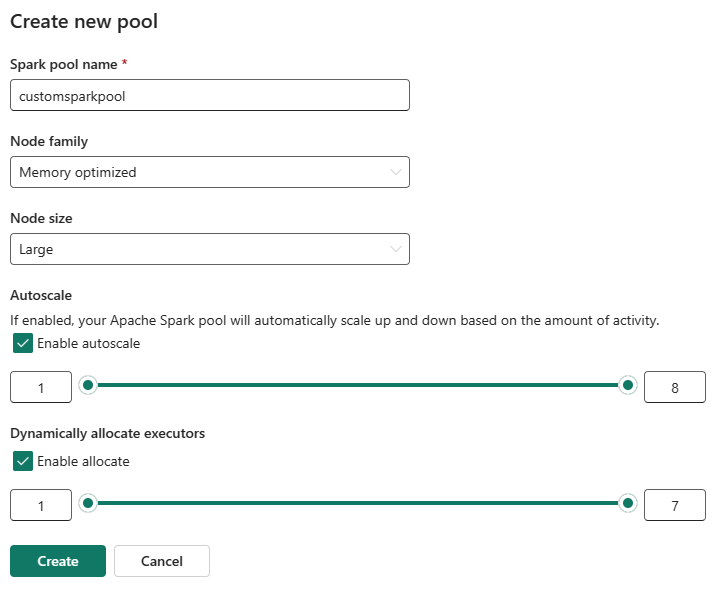
Du kan også vælge at aktivere dynamisk eksekvering af eksekvering for din Spark-gruppe, hvilket automatisk bestemmer det optimale antal eksekveringsfiler inden for den brugerdefinerede maksimale grænse. Denne funktion justerer antallet af eksekveringsprogrammer baseret på datamængde, hvilket resulterer i forbedret ydeevne og ressourceudnyttelse.

Disse brugerdefinerede grupper har en standardvarighed for autopause på 2 minutter. Når varigheden af autopausen er nået, udløber sessionen, og klyngerne er ikke allokeret. Du faktureres på baggrund af antallet af noder og den varighed, som de brugerdefinerede Spark-puljer bruges til.
Relateret indhold
- Få mere at vide i den offentlige dokumentation til Apache Spark .
- Kom i gang med administrationsindstillinger for Spark-arbejdsområde i Microsoft Fabric.