Indstillinger for Spark-beregningskonfiguration i Fabric-miljøer
Microsoft Fabric Dataudvikler ing- og Data Science-oplevelser fungerer på en fuldt administreret Spark-beregningsplatform. Denne platform er designet til at levere uovertruffen hastighed og effektivitet. Det omfatter startbassiner og brugerdefinerede puljer.
Et Fabric-miljø indeholder en samling konfigurationer, herunder Egenskaber for Spark-beregning, der giver brugerne mulighed for at konfigurere Spark-sessionen, når de er knyttet til notesbøger og Spark-job. Med et miljø har du en fleksibel måde at tilpasse beregningskonfigurationer til kørsel af dine Spark-job på. I et miljø giver beregningsafsnittet dig mulighed for at konfigurere egenskaberne på Spark-sessionsniveau for at tilpasse hukommelsen og kernerne af eksekveringsprogrammer baseret på arbejdsbelastningskrav.
Administratorer af arbejdsområder kan aktivere eller deaktivere tilpasning af beregning med parameteren Tilpas beregningskonfigurationer for elementer under fanen Pulje i afsnittet Dataudvikler/Videnskab på skærmen Indstillinger for arbejdsområde.
Administratorer af arbejdsområder kan delegere medlemmer og bidragydere for at ændre standardkonfigurationerne for beregning på sessionsniveau i s Fabric-miljø ved at aktivere denne indstilling.
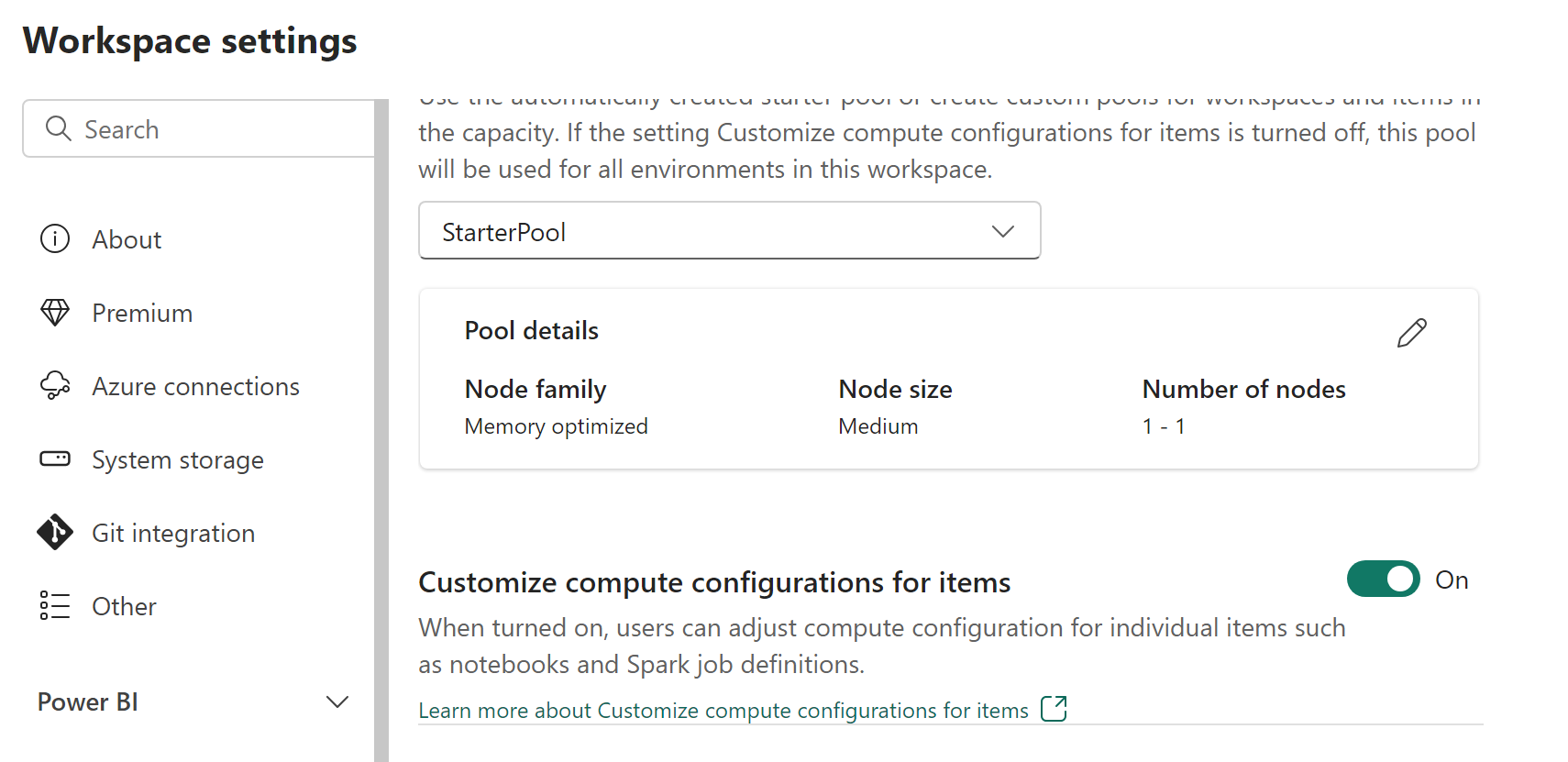
Hvis arbejdsområdeadministratoren deaktiverer denne indstilling i indstillingerne for arbejdsområdet, deaktiveres beregningsafsnittet i miljøet, og standardpuljens beregningskonfigurationer for arbejdsområdet bruges til kørsel af Spark-job.
Tilpasning af beregningsegenskaber på sessionsniveau i et miljø
Som bruger kan du vælge en pulje til miljøet på listen over tilgængelige puljer i Fabric-arbejdsområdet. Administratoren af Fabric-arbejdsområdet opretter standardstartpuljen og brugerdefinerede puljer.
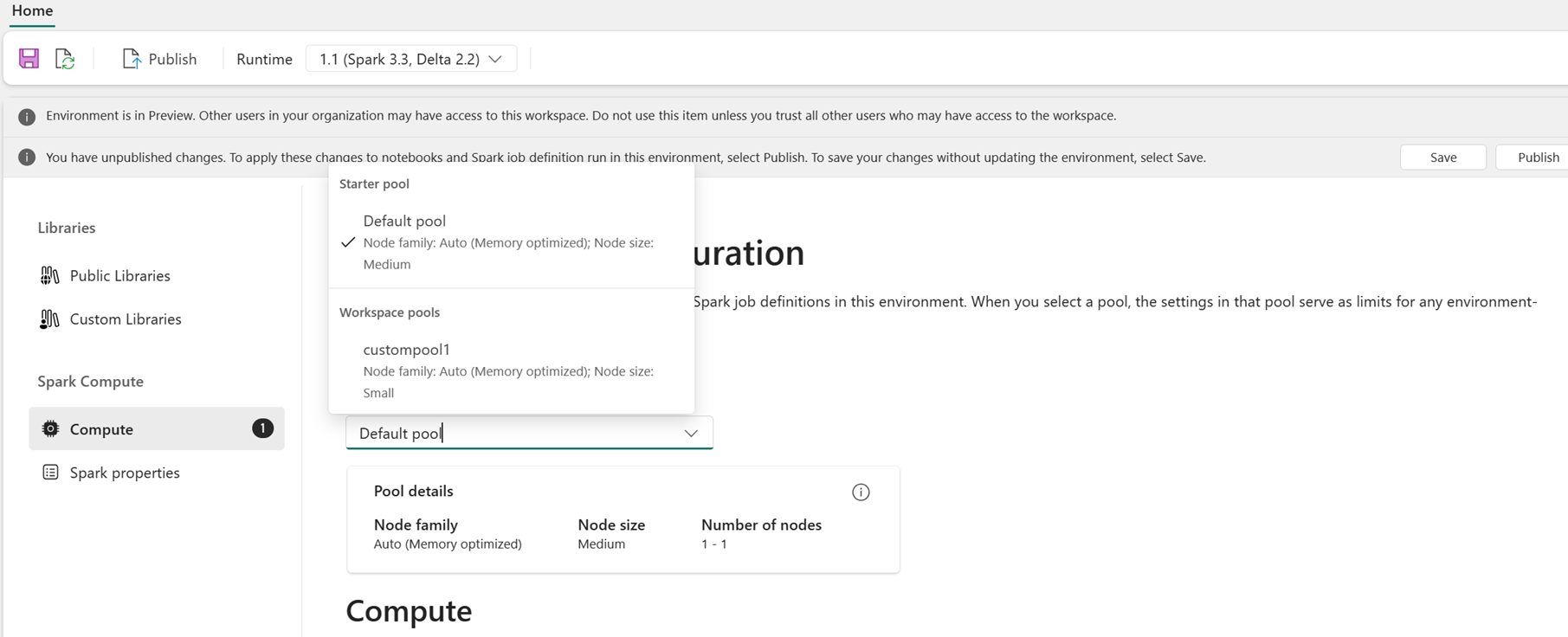
Når du har valgt en pulje i afsnittet Beregning , kan du justere kernerne og hukommelsen for eksekveringerne inden for grænserne for nodestørrelserne og grænserne for den valgte gruppe.
Eksempel: Du vælger en brugerdefineret pulje med en nodestørrelse på stor, som er 16 Spark vCores, som miljøpulje. Du kan derefter vælge den driver/eksekveringskerne, der skal være enten 4, 8 eller 16, baseret på dit krav på jobniveau. For den hukommelse, der er allokeret til driveren og eksekveringsenheden, kan du vælge 28 g, 56 g eller 112 g, som alle er inden for grænserne af en stor nodehukommelsesgrænse.
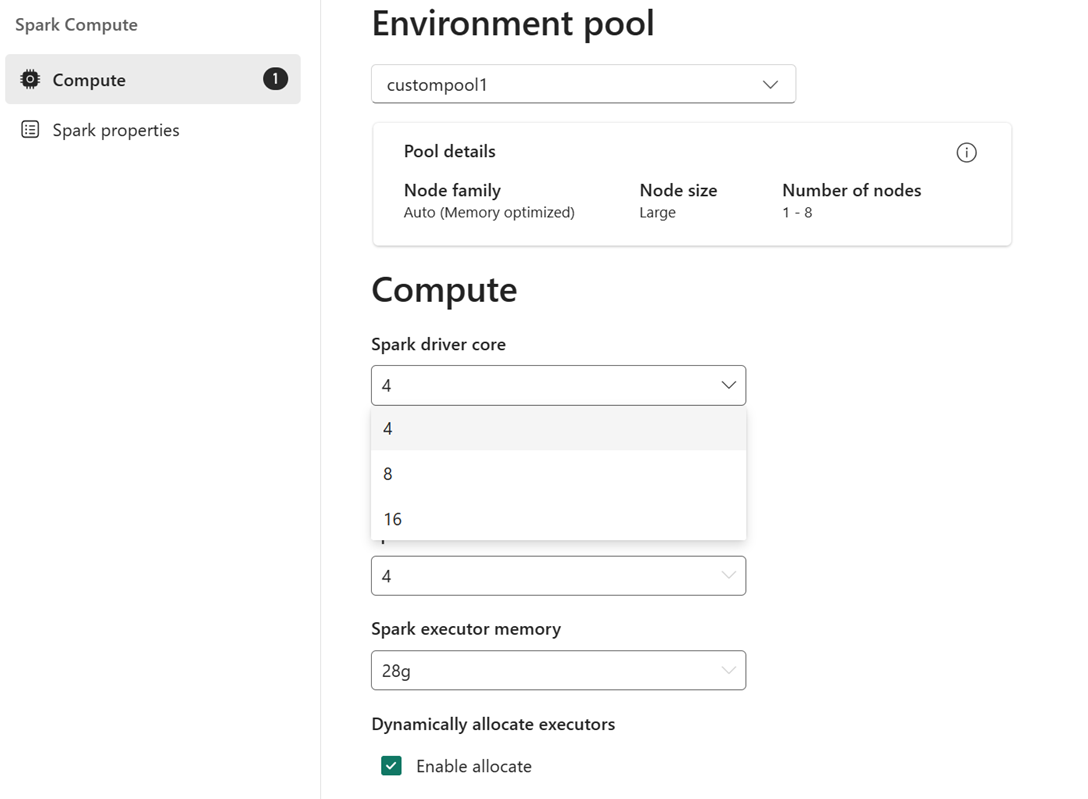
Du kan få flere oplysninger om Spark-beregningsstørrelser og deres kerner eller hukommelsesindstillinger under Hvad er Spark-beregning i Microsoft Fabric?.